






目录
其实我们在C语言就学过文件操作,但是从语言的角度,我们只是说会用了关于文件的一些操作和函数,但其实它究竟是怎么回事我们其实并不明白,那么当我们学习到Linux操作系统的时候,我们才能更加深入的去了解这文件究竟是怎么回事
那么我们需要首先明确一些概念:文件=内容+属性,不能说我这个文件是空,那么就不占空间;访问文件都得先打开,然后通过执行代码的方式去修改文件内容,也就是文件要被加载到内存中;是进程打开的文件并且一个进程可以打开多个文件;一个时间段内,可能有多个进程,操作系统要管理这些进程,同时也可能有多个被打开的文件,操作系统也要管理这些文件,那么如何管理呢?先描述,再组织,就是说,操作系统要给每个文件创建一个结构体对象,对文件的管理就变成了对于结构体的管理。
C语言关于文件操作的函数
下面只是介绍了一小部分,如果想详细了解,可以去我的另一篇博客:
那么下面先回忆一下之前C语言用的一些函数:
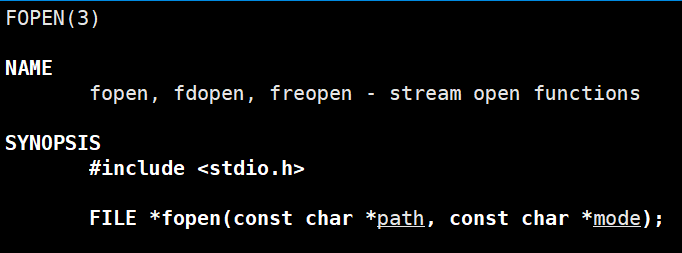

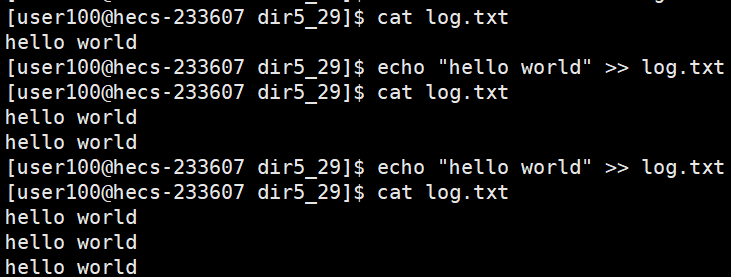
首先就是fopen,并且我记得当时选项w最为奇怪,因为每一个用,那么之前的数据都会不见了,这不是跟我们的输出重定向(>)很像吗,因为它们都是每次使用之前的内容就会被清空
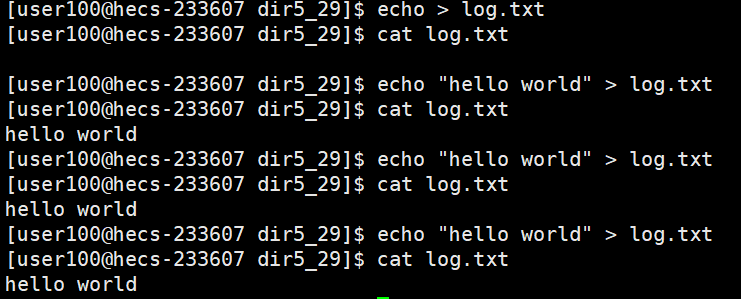

这段话的意思是:截断文件到长度0或者如果没有那么创建新文件
我们原来都是这么用的:
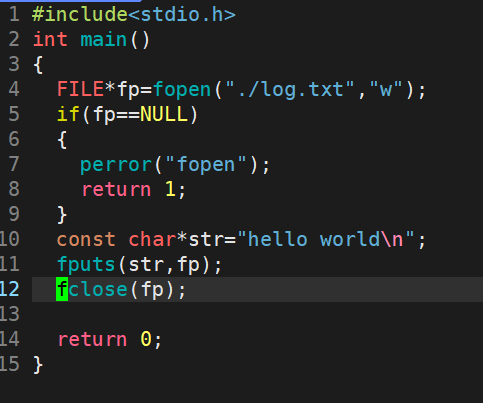
我们说如果w选项,当前路径下没有这个文件,那么就会在当前路径下去创建,那么进程怎么知道当前在那个路径下呢?我们说过进程启动时,会记录下自己的路径
所以进程就会在这个路径下创建新文件
并且我们还有一个选项a,叫做append(附加),这不是跟追加重定向(>>)很像吗
下面我们再看一下fwrite这个函数





基本的使用就是这样
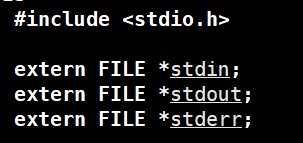
我们可以确定的是,输入或输出一些东西必须要指定文件,就连键盘和显示器也不例外,因为Linux下一切皆文件,那么平时用printf/scanf的时候也没打开键盘和显示器文件并且也没有指定文件啊(我们这么想是因为把键盘和显示器看成和普通文件一样了),那是因为首先stdout,stdin和stderror是进程默认打开的,不用手动打开,可以直接使用
其次为什么printf不用指定文件呢?因为它为了方便使用,是不用指定文件的,但是底层实现是封装了fprintf
fprintf是要加stdout的,所以printf就是这么实现的
Linux关于文件操作的系统调用
我们知道,对硬件进行修改只能通过操作系统,所以操作系统就必须提供系统调用接口,像fopen这样的库函数是语言层面的概念,为了实现语言的跨平台性和可移植性,所以它要封装系统调用,并且在不同的操作系统要封装各自的系统调用。所以我们下面就介绍一下Linux操作系统关于文件操作的系统调用open和close
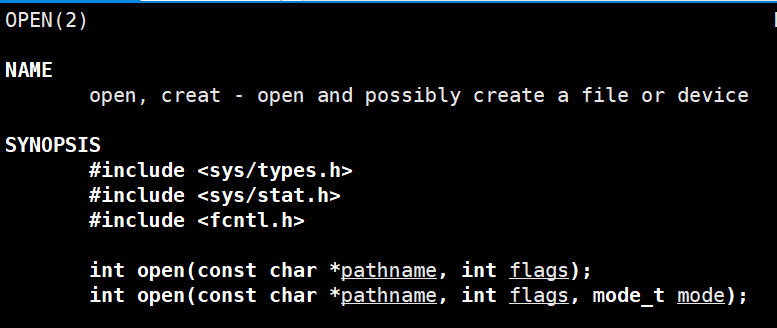


open的第一个参数就是文件所处的路径,第二个参数就是之前说的类似于“w“、“a”的一些选项,常见的打开标志有:
O_RDONLY:以只读方式打开文件
O_WRONLY:以只写方式打开文件
O_CREAT:没有这个文件就创建
O_TRUNC:打开文件前会清空文件
O_APPEND:在文件尾追加数据
第三个参数就是我刚创建好一个文件,此时要给文件设置的权限,返回值就是文件描述符,其实就是一个整数,通过这个整数,就可以确定这个文件,具体是怎么确定的,这就跟底层实现有关了,我们后面会介绍一下
当我们用第一个open时,并且路径中没有,它需要创建,这时我们可以看到文件的权限是乱码
![]()
![]()
所以我们一般使用第二个,权限计算还是给定的权限减去权限掩码,我们把它们当成八进制数,比如:
666-002=664
![]()
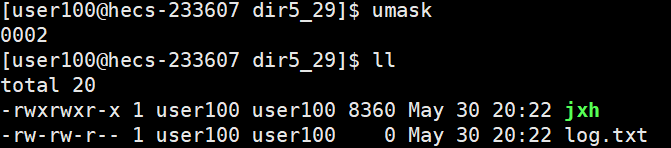
并且通过umask()函数我们还可以在当前程序中设置权限掩码,并且这个权限掩码只在当前程序下生效
666-666=000

![]()
我们上面介绍了第二个参数,第二个参数要给一个整数,其实下面的一些“选项”就是一些宏,这些宏可以通过位运算决定整数的比特位,其实就是位图,从而达到不同的下面的选项,知道了这些宏的意义,我们就可以和之前fopen的不同选项的功能对应上了,其实“w”选项不就是这三个选项的叠加吗
其实如果只有前两个的话原始文件中的内容并不会清空,而新内容就从头开始进行覆盖,就是这样一种现象
选项“a”不就是这三个选项的叠加吗
并且追加内容时会在下一行追加
所以我们说fopen底层就是封装了open,并且不同的选项底层就对应了不同的宏,我们上面说stdin、stdout、stderr每个进程都会默认打开,并且它们的类型是FILE*,这是C语言层面的类型,本质就是一个结构体,既然Linux要通过文件描述符来确定一个文件,C语言要通过FILE*的对象,所以FILE结构体中肯定有文件描述符
为了探究文件描述符到底是什么,我们可以连续创建一些文件看看它们的文件描述符之间有什么规律
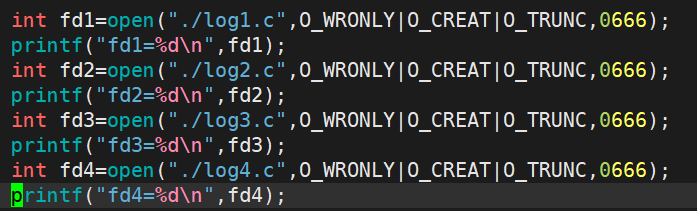
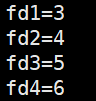
文件描述符是从3开始依次增长,那0,1,2呢?其实0,1,2就分别是程序默认打开的stdin,stdout和stderr,并且这个数字其实就是数组下标,什么意思呢?
我们知道,操作系统不仅要进行进程管理,还要进行文件管理,对于进程的管理我们知道是通过PCB,就是一个结构体对象;同样,对于打开的文件(不管以什么样的方式打开),操作系统也是要创建一个结构体对象(比如我们叫做struct file)进行管理的,我们可以把它们之间的关系大致理解为这样:
就是说:一个进程的PCB中存着此进程打开的文件列表的指针,通过这个指针可以找到打开的文件列表,而这个文件列表中也是存着每个文件管理的指针,通过这个指针就可以找到操作系统对文件进行管理的结构体了
这就是为什么我们可以通过文件描述符(一个整数),来确定唯一一个文件了
并且要注意,我们图中的缓冲区是操作系统给每个打开的文件提供的,和下面说的C语言库函数提供的缓冲区不是一个概念

既然stdout等是自动打开的,我们可以关闭stdout试一试,还不能关这个,因为一旦关了就打印不出东西来了,我们可以关掉stdin,于是新打开的文件的文件描述符就会从最小的没用到的0开始
这个_fileno就是FILE*结构体中文件描述符变量的名字

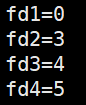
所以我们就可以利用上面的规则实现重定向,比如printf默认向stdout中打印,其实它认识的是文件描述符为1,所以我们就可以这样,将想打印的内容打印到一个文件中而不是显示器


这样也确实比较麻烦,并且还要了解文件描述符的分配规则,其实也不知可以这么做,系统还提供了系统调用来供我们使用,这个就是通过拷贝指针来实现目的,就是上面图中中间那个图里边的指针
于是我们就可以这么用:
就是让数组下标为1的里边的内容变成数组下标为fd的里边的内容,这样printf打印肯定还是向数组下标为1的里边的指针指向的文件打印,这时文件就变成log.txt


完善myshell
既然已经明白了重定向的原理:就是通过文件描述符实现向任意一个文件中写入,本质上就是改变文件指针数组中的指针就可以实现向指定的文件中写入,于是我们就可以完善一下我们之前写的myshell
可以移步到下面这篇博客中:自定义bash进程
C语言缓冲区
我们这里说的缓冲区其实就是C语言库中提供的一个缓冲区,这么说可能有点抽象,其实就是在我们调用文件相关函数的时候,需要用到FILE这个类型,这个类型其实就是一个结构体,里边就存着缓冲区。
也就是说:不管是log.txt这样的普通文件的文件指针,又或者是stdout这样的进程自动打开的文件指针,它们都是一个结构体对象,这个对象中就存着缓冲区,那么这样好处是什么呢?
1.首先我们要知道,调用系统调用是有成本的,所以我们需要尽可能的少的调用,那么我先暂时把数据写到C语言的缓冲区中,最后统一的调用系统调用把数据给操作系统,这样系统调用的次数就减少了
2.其次在写代码的人看来,执行完这句代码,数据就好像已经写入到了文件中,但实际上是写入到了缓冲区中,这种在内存中的拷贝可比把数据写入到磁盘当中快多了,这样表现出来的就是C语言的速度很快,可以提高写代码的人的体验
我刚才说缓冲区就在FILE的结构体对象中,那么它跟我们之前说的进程地址空间是什么关系呢?
其实你得看FILE对象在哪,FILE对象可以在调用fopen函数时在函数内部去堆上申请,所以缓冲区就在堆上,我们下边也会模拟实现一下缓冲区的工作原理。而堆不就是进程地址空间的一部分嘛。
我们在语言层面上有这么几种处理不同文件的缓冲区的策略
1.无缓冲区,不用刷新
2.行刷新,比如要写入到显示器中
3.全缓冲,全部刷新,就是一般文件只有当缓冲区写满时才刷新
当然我们也可以主动刷新,比如调用fflush函数,或者进程结束时,缓冲区会自动刷新
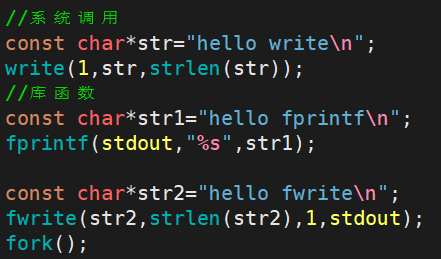
那么,上面说的缓冲区的位置,处理不同文件的缓冲区的策略你怎么证明呢?下面我们就来写一个代码验证一下

我们运行这个代码,无论是直接运行,或者是打印到一个文件中,都是正常的:
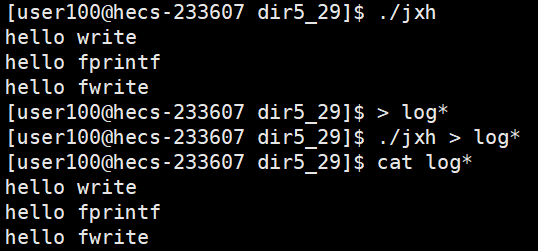
但是当我们仅在代码尾部加了一个fork后,结果就变了
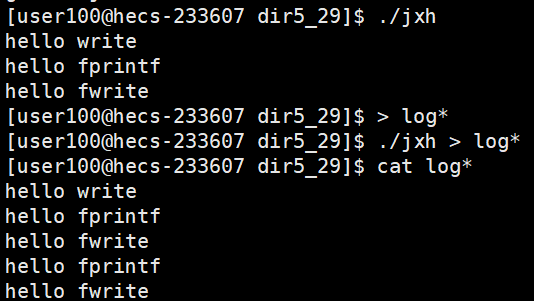
可以看到,打印到显示器上是正常的,但是打印到文件中,系统调用打印了一回,库函数打印了两回。这是因为系统调用没有缓冲区,直接写到操作系统中;而库函数因为是写入到文件中,所以不是行刷新,程序结束才会刷新,而在程序没结束时,子进程被创建,父子进程共享进程地址空间,而进程地址空间中就存着缓冲区,缓冲区中有内容,程序结束时,父子进程缓冲区中的内容都要被刷新出来,刷新缓冲区也是一种修改数据,所以发生写时拷贝。
知道了上面的理论,我们可以自己创建一个源代码文件来实现FILE结构体并且实现相关函数,我们实现的大体思路是首先用法要和库中的保持一致,我们内部实现要加上缓冲区,并且对于不同种类的文件要有不同的刷新方式,我们只要是通过自己实现知道C语言的缓冲区具体在哪里就可以
//myFILE.h
#pragma once
#include<string.h>
#include<unistd.h>
#include<stdlib.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<sys/types.h>
enum MODEBUFF
{
NO_BUFF,
ROW_BUFF,
FULL_BUFF,
};
typedef struct MYFILE
{
int fileno;
char buffer[64];
int pos;
int mode;
}MYFILE;
MYFILE* fopen(const char*path,const char*option);
int mywrite(const char*str,int size,int n,MYFILE*fp);
int fclose(MYFILE*fp);
//myFILE.c
#include"myFILE.h"
MYFILE* fopen(const char*path,const char*option)
{
MYFILE* tmp=(MYFILE*)malloc(sizeof(MYFILE));
tmp->pos=0;
tmp->mode=FULL_BUFF;
if(option[0]=='w')
{
tmp->fileno=open(path,O_WRONLY|O_CREAT|O_TRUNC,0666);
}
else if(option[0]=='a')
{
tmp->fileno=open(path,O_WRONLY|O_CREAT|O_APPEND|0666);
}
else if(option[0]=='r')
{
tmp->fileno=open(path,O_RDONLY);
}
else return NULL;
return tmp;
}
int mywrite(const char*str,int size,int n,MYFILE*fp)
{
while(n--)
{
if(fp->mode==FULL_BUFF)
{
strncpy(fp->buffer+fp->pos,str,size);
fp->pos=strlen(fp->buffer);
}
else
{
write(fp->fileno,str,size);
}
}
return size;
}
int fclose(MYFILE*fp)
{
if(fp->pos!=0)write(fp->fileno,fp->buffer,fp->pos);
close(fp->fileno);
free(fp);
fp=NULL;
return 0;
}
//test.c
#include"myFILE.h"
int main()
{
MYFILE* fp=fopen("./tmp1","w");
mywrite("abcbcbbc",5,1,fp);
fork();
fclose(fp);
return 0;
}
//makefile
myFILE:myFILE.c test.c
gcc -o $@ $^
.PHONY:clean
clean:
rm myFILE 














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









