






修改配置文件
第一步:切换到conf配置文件夹下

第二步:重命名workers.template

第三步:编辑workers配置文件
1.编辑workers,

2.将原本的localhost更换为三台虚拟机名字后退出保存

第四步:
1.重命名spark-env.sh 并编辑(切换到conf路径下更改)

2.进入之后删除所用行,保存空白文件,插入以下内容
#设置JAVA安装目录
JAVA_HOME=/export/server/jdk1.8.0_65
#设置python安装目录
PYSPARK_PYTHON=/export/server/anaconda3/bin/python
#读取hadoop软件配置目录
HADOOP_CONF_DIR=/export/server/hadoop-3.3.0/etc/hadoop
#指定spark中的master的ip
SPARK_MASTER_HOST=shuju201
#代码访问master的端口
SPARK_MASTER_WEBUI_POST=7077
#浏览器访问master的端口
SPARK_MASTER_WEBUI_POST=8080
#worker的配置
SPARK_WORKER_CORES=1
SPARK_WORKER_MEMORY=1g
#代码访问worker的端口
SPARK_WORKER_WEBUI_POST=7078
#浏览器访问worker的端口
SPARK_WORKER_WEBUI_POST=8081
JAVA安装目录以及python安装目录、Hadoop软件配置目录位置如何查找
JAVA的安装目录在vim /etc/profile下
![]()
Hadoop软件配置目录如图
找到计算机的如下路径,之后查看当前路径
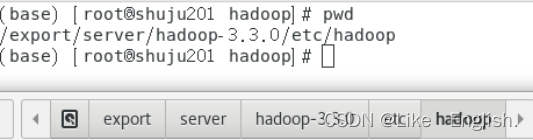
第五步:将配置好的所有内容传送给其他虚拟机
scp -r /export/server/spark shuju202:/export/server
scp -r /etc/bashrc shuju202:/etc
scp -r /etc/profile shuju202:/etc
第六步:决对路径启动spark集群
/export/server/spark/sbin/start-all.sh
pyspark --master spark://shuju201:7077
第七步:重命名Hadoop和spark的启动脚本命令
- 先切换到sbin目录下

2.重命名spark启动和停止命令

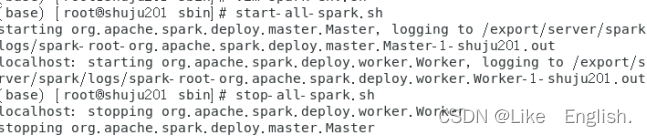
3.使用命令查看能否成功
所用到的全部指令
cd /export/server/spark/conf
mv workers.template wokers
vim wokers
mv spark-env.sh.template spark-env.sh
vim spark-env.sh
vim etc/profile
pwd
vim spark-env.sh
scp -r /export/server/spark shuju202:/export/server
scp -r /export/server/spark shuju203:/export/server
scp -r /etc/profile shuju202:/etc
scp -r /etc/profile shuju203:/etc
scp -r /etc/bashrc shuju203:/etc
scp -r /etc/bashrc shuju202:/etc
/export/server/spark/sbin/start-all.sh
pyspark --master spark://shujuu201:7077
cd /export/server/spark/sbin
mv start-all.sh start-all-spark.sh
mv stop-all.sh stop-all-spark.sh
start-all-spark.sh
stop-all-spark.sh














 4609
4609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









