







前言
前端开发中处理对象和数组时,我们经常会碰到拷贝的情景,如果出现一些不恰当的拷贝就会导致一些难以预料的错误,难以排查与维护。拷贝又常常分为深拷贝和浅拷贝,弄清楚两者的概念及区别尤为重要。
举个简单例子:
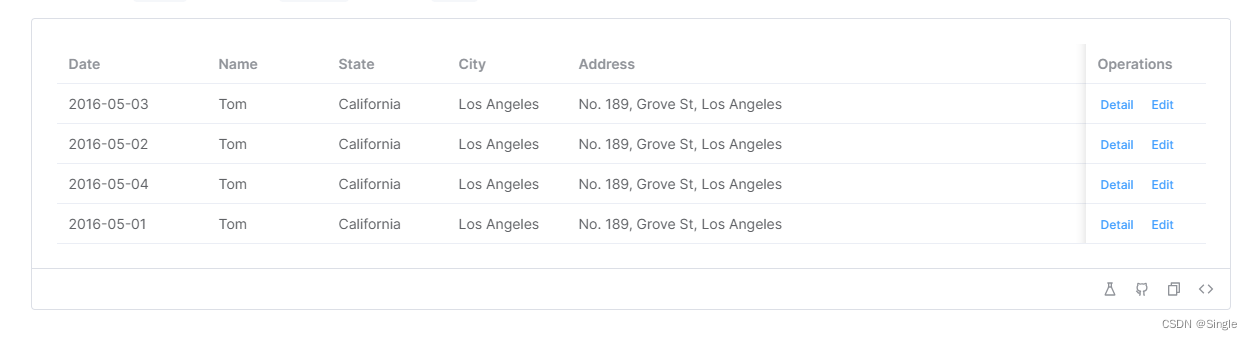
相信大家对于这种表格并不陌生,在操作栏会有一个显示详细数据的功能,这需要实现一个数据回显的功能用于显示详细数据。
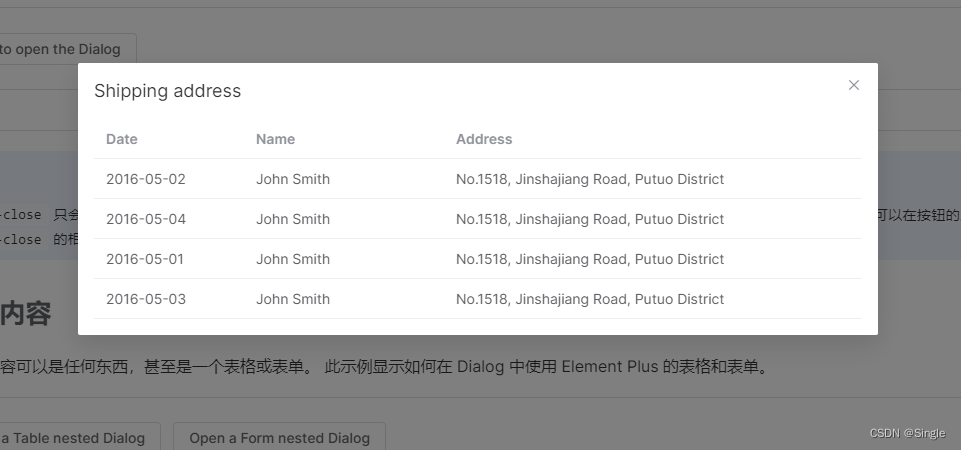
如果这里通过回显数据 = 表格数据 直接赋值就会出现一个问题,当我在回显数据上使用了修改功能后,哪怕没有选择确定或者保存,外面表格的数据都会发生变化。
这种就是典型的浅拷贝带来的问题,对拷贝数组做出的更改有时会影响到源数组。注意这里的有时,后文会介绍为什么。
引言
- 我们先来看个最简单的拷贝:
const a = 10;
cosnt b = a;
console.log(b);
毫无疑问,输出结果是10。
为了深入理解拷贝这一过程,我们需要研究数据在内存中的存储方式。

对于上面的基本数据类型(number)的存储,js会采用值类型栈存储的方式,把a的值直接拷贝给b。
值类型栈存储: 主要针对(Number、String、Boolean)三种基本数据类型。直接存储在栈(stack)中,占据空间小、大小固定,属于被频繁使用数据,所以放入栈中存储。
- 再看个例子:
const arr = [0,1,2]
const arr_copy = arr

对于上面的引用数据类型(number)的存储,js会采用引用类型堆栈存储的方式,在栈中存储变量名和引用(地址),在堆中存储实际数据。拷贝的过程发生在栈中,js会将a的引用直接拷贝给b,这样就导致了两个变量同时指向一个位置,所以之后无论是对a操作还是对b操作实际上操作的都是同一处地方,所以也就发生源对象和拷贝对象互相影响的情况了。
引用类型堆栈存储: 主要针对Object、Array这两种引用数据, 同时存储在栈(stack)和堆(heap)中,占据空间大、大小不固定。引用数据类型在栈中存储了指针,该指针指向堆中该实体的起始地址。当解释器寻找引用值时,会首先检索其在栈中的地址,取得地址后从堆中获得实体。
-
我们再看一种情况:
大家思考一下输出结果是什么
const a = [1,2,[3,4]];
const b = [...arr];
b[0] = 2;
b[2] = 1;
console.log(a);
console.log(b);
答案是:[1,2,[3,4]] 和 [2,2,1]
那如果我修改一下呢
const a = [1,2,[3,4]];
const b = [...arr];
b[0] = 2;
b[2][0] = 1;
console.log(a);
console.log(b);
答案是: [1,2,[1,4]] 和 [2,2,[1,4]]
看到这里我相信真正理解深浅拷贝的同学都能做对,但如果有做错的说明还没有真正理解深浅拷贝。
实际上在堆中,嵌套的引用类型仍然是通过存储引用实现的,而并非直接存储它本身。

当我们给将a使用展开运算符或者其它标准的内置对象复制操作方法拷贝给b时,会开辟一个新的内存空间用于存放b的数据,但是对于a存放的数据,它会原封不动的复制过去,包括存放的引用,这也就导致了b中的引用数据类型属性会与a共享引用。
我们看一下图解:
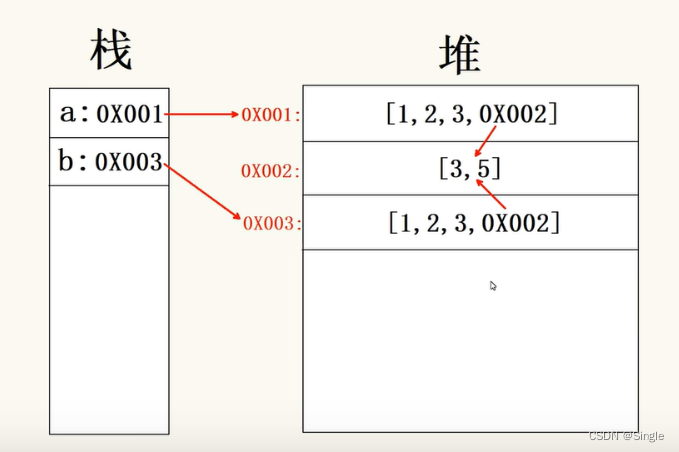
那这时候有同学就有疑问了,我明明将b[0]修改了a[0]没有变,为啥这个还是浅拷贝呢?不是说浅拷贝之后源对象和拷贝对象更改会互相影响吗?
一、深浅拷贝的定义
这里我们引出浅拷贝的定义,这里参考的是MDN上的定义。
浅拷贝
对象的浅拷贝是其属性与拷贝源对象的属性共享相同引用(指向相同的底层值)的副本。
注意这里所说的是共享相同引用,对于不是引用类型的数据,自然就不会影响浅拷贝的判定了。
实际上,对于在 JavaScript 中,所有标准的内置对象复制操作(展开语法、Array.prototype.concat()、Array.prototype.slice()、Array.from()、Object.assign() 和 Object.create())创建的都是浅拷贝而不是深拷贝。
各位可以自己实践一遍,这里就不再赘述了。
深拷贝
那么如何才算是深拷贝呢?继续使用上面提到的数据例子,如果我们实现了源对象和拷贝对象完全独立,就实现了深拷贝。

这里引出MDN上关于深拷贝的定义如下:
对象的深拷贝是指其属性与其拷贝的源对象的属性不共享相同的引用(指向相同的底层值)的副本。
实际上,MDN上的这句话在我看来是有一些歧义的,比如说源对象和拷贝对象的第一层的属性不共享相同引用,但是第一层属性的嵌套属性却共享引用,这种情况实际上并不属于我们常说的深拷贝,它们并没有完全独立。
深拷贝应确保整个对象及其嵌套属性都不共享相同的引用,而不仅仅是第一层属性。至于这句话是否有歧义,欢迎各位小伙伴在评论区留下自己的看法,我们共同探讨。
二、如何实现深拷贝
1. 使用JSON序列化
const a = [1,2,[3,4]];
const b = JSON.parse(JSON.stringify(a));
但是这种方法也有弊端,采用这种方法的前提是数据允许被序列化。
于是对于一些无法序列化的数据自然不能采用这种方法
例如:函数、Symbol、正则表达式、在 HTML DOM API 中表示 HTML 元素的对象、递归数据以及许多其他情况。
const obj = {
a:{
foo:'bar'
},
}
obj.b = obj
console.log(JSON.parse(JSON.stringify(obj)))
function say() {
console.log("圣诞快乐!");
}
const reg = new RegExp()
console.log(JSON.stringify(say));// undefined
console.log(JSON.stringify(reg));// {}
/*
1. ERROR:Converting circular structure to JSON 将循环结构转换为JSON
2. 对函数使用JSON.stringify会转换成undefined
3. 对正则使用JSON.stringify会转换成{}
4. Symbol 的特点包括不可枚举性、唯一性(每个 Symbol() 调用返回一个新的不同的 Symbol 值),常用于对象属性的键,JSON.stringify()、 for...in 循环和Object.keys() 都会忽略Symbol属性。
*/
2. 使用structClone方法
该方法与JSON序列化类型,但常用于操作定型数组,但是它们也有几个不同点:
- 复杂数据类型支持:
structuredClone()支持复制包括 DOM 节点、Blob、File、ArrayBuffer 等复杂数据类型,而 JSON 序列化只支持基本的 JavaScript 数据类型。 - 用途不同:
structuredClone()主要用于在 Web Workers、postMessage() 等场景中复制包含复杂数据的对象,而 JSON 序列化主要用于简单数据的转换和传输。 - 兼容性:
structuredClone()可能不适用于所有 JavaScript 环境,而 JSON 序列化是一种通用且普遍支持的数据序列化方式。
3. 使用外部库,如Lodash的_.cloneDeep(value)方法
npm i --save ladash
// main.js
import _ from 'lodash'
// example.js
var objects = [{ 'a': 1 }, { 'b': 2 }];
var deep = _.cloneDeep(objects);
console.log(deep[0] === objects[0]);
// false
4. 自己手写一个
const myDeepClone = function (resource) {
// 简单数据类型直接返回
if (typeof resource !== 'object' || resource === null) {
return resource
}
const copy = Array.isArray(resource) ? [] : {}
for (const key in resource) {
if (resource.hasOwnProperty(key)) {
// 如果是简单数据类型会直接返回结果,如果是复杂数据类型则继续递归
copy[key] = myDeepClone(resource[key])
}
}
return copy
}
let symbol = Symbol()
const obj = {
name: '张三',
age: 18,
hobbies: ['篮球', '足球', '乒乓球',{foo:'bar'}],
fun: ()=>{
console.log('hello')
},
[symbol]:'bar'
}
const copy = myDeepClone(obj)
copy.fun() // hello
console.log(copy.hobbies !== obj.hobbies)// true
console.log(copy.hobbies[3] !== obj)// true
console.log(copy[symbol]); // undefined
这个实现了嵌套的深层深拷贝,以及对函数的拷贝,但是并不能解决循环引用(会发生栈溢出)的问题
实现对循环引用的拷贝:
const myDeepClone = function (resource) {
const cache = new WeakMap()// 使用缓存,避免栈溢出,使用闭包,避免全局变量污染
const _deepClone = function (resource) {
// 简单数据类型直接返回
if (typeof resource !== 'object' || resource === null) {
return resource
}
if(cache.has(resource)) {
return cache.get(resource)
}
const copy = Array.isArray(resource) ? [] : {}
cache.set(resource, copy)
for (const key in resource) {
// 不处理原型上的属性
if (resource.hasOwnProperty(key)) {
// 如果是简单数据类型会直接返回结果,果是复杂数据类型则继续递归
copy[key] = _deepClone(resource[key])
}
}
return copy
}
return _deepClone(resource)
}
let symbol = Symbol()
const obj = {
name: '张三',
age: 18,
hobbies: ['篮球', '足球', '乒乓球',{foo:'bar'}],
fun: ()=>{
console.log('hello')
},
[symbol]:'bar'
}
obj.itself = obj // 自身引用
obj.hobbies.push(obj) // 自身引用
const copy = myDeepClone(obj)
copy.fun = function(){
console.log('world');
}
obj.fun()
copy.fun()
console.log(copy.fun === obj.fun) // true 虽然相等,但是修改copy并不会影响到obj
console.log(copy.hobbies !== obj.hobbies) //true
console.log(copy.itself !== obj.itself) //true
console.log(copy.hobbies[3] !== obj)//true
console.log(copy.hobbies[3] === copy)//false
console.log(copy[symbol]); // undefined
改良之后的深拷贝能够实现循环引用的拷贝,但是对于symbol等还是不支持,除此以外还需要考虑原型上的内容是否实现深拷贝,还有对Map、Set、定型数组等等的考虑,所以最好的办法还是根据自己的需求选择最合适的方式,这里锻炼的是一个递归的思想。














 478
478











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









