







知识点
- 聚类的指标
- 聚类常见算法:kmeans聚类、dbscan聚类、层次聚类
- 三种算法对应的流程
实际在论文中聚类的策略不一定是针对所有特征,可以针对其中几个可以解释的特征进行聚类,得到聚类后的类别,这样后续进行解释也更加符合逻辑。
聚类的流程
1.标准化数据
2.选择合适的算法,根据评估指标调参( )
指定k值,不指定k值
KMeans 和层次聚类的参数是K值,选完k指标就确定
DBSCAN 的参数是 eps 和min_samples,选完他们出现k和评估指标
以及层次聚类的 linkage准则等都需要仔细调优。
除了经典的评估指标,还需要关注聚类出来每个簇对应的样本个数,避免太少没有意义。
3.将聚类后的特征添加到原数据中
4.原则t-sne或者pca进行2D或3D可视化
作业: 对心脏病数据集进行聚类。
1.前期准备:
(1)导入必要的库,读取数据
import pandas as pd #用于数据处理和分析,可处理表格数据。
import numpy as np #用于数值计算,提供了高效的数组操作。
import matplotlib.pyplot as plt #用于绘制各种类型的图表
import seaborn as sns #基于matplotlib的高级绘图库,能绘制更美观的统计图形。
import warnings
warnings.filterwarnings("ignore")
# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
data = pd.read_csv(r'E:\cjx\2.【打卡】python训练营\python60-days-challenge-master\heart.csv') #读取数据
data.head()
data.info()该数据集没有缺失值,全是数值型信息
(2)聚类前要标准化
# 获取数值型变量列、也是连续特征列
continuous_features = data.select_dtypes(include=['int64', 'float64']).columns.tolist()
from sklearn.model_selection import train_test_split
X = data.drop(['target'], axis=1) # 特征,axis=1表示按列删除
y = data['target'] # 标签
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans, DBSCAN, AgglomerativeClustering
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import seaborn as sns
# 标准化数据(聚类前通常需要标准化)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X) # X是划分数据集的特征集2.KMeans聚类
k_range = range(2, 11)
这里只给出聚类后的结果
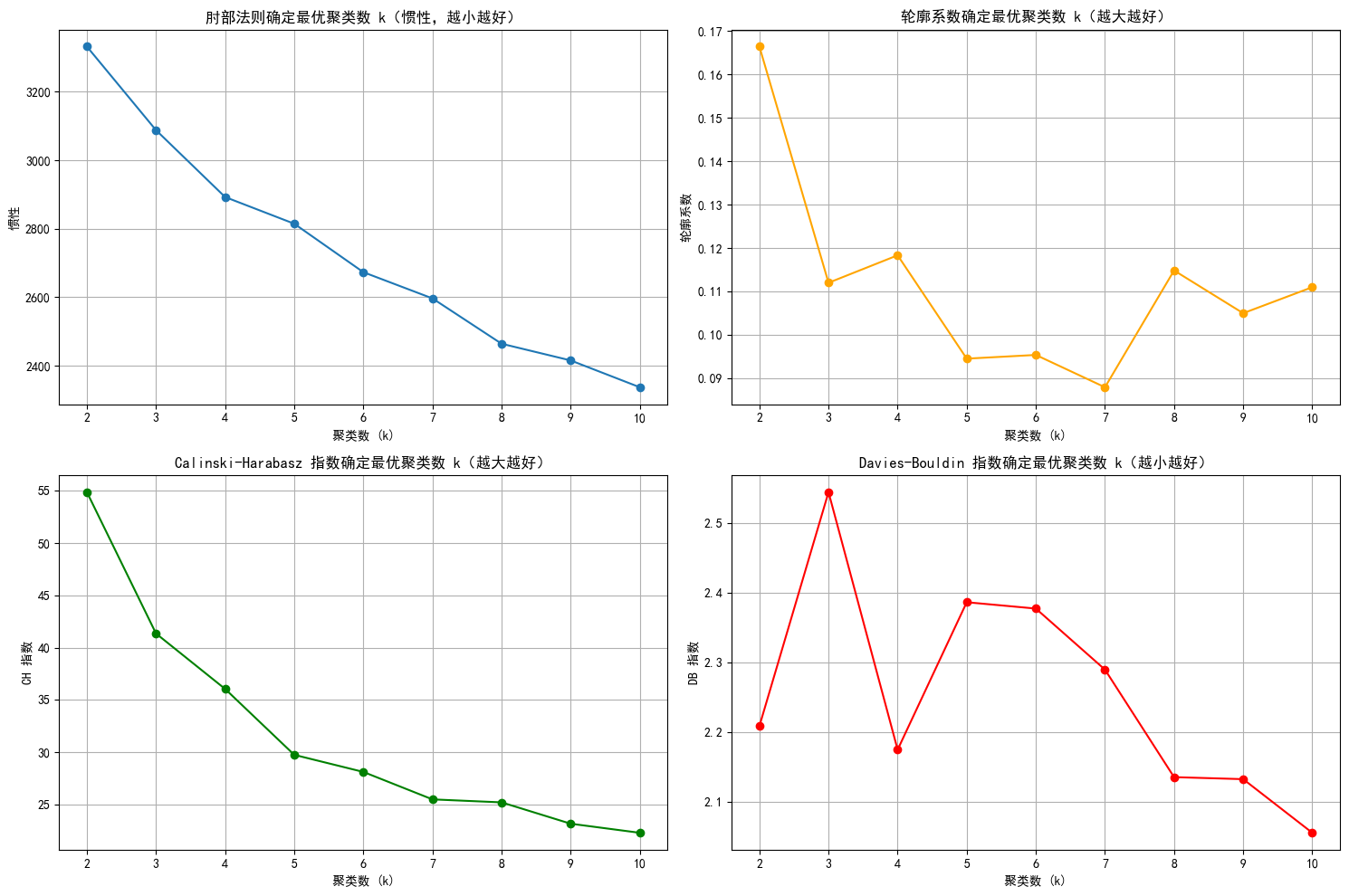
由图像选择最佳参数
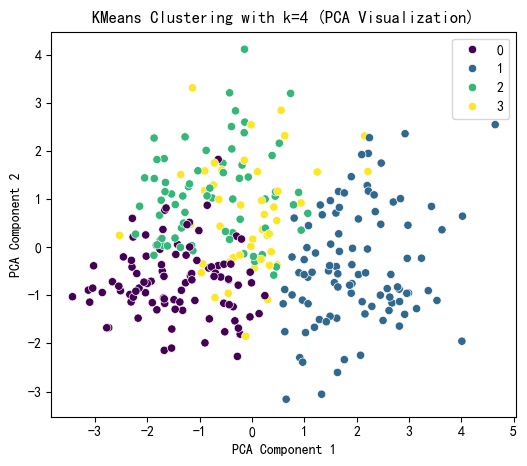
selected_k = 4
3.DBScan聚类
需要修改的参数
eps_range = np.arange(0.1, 1, 0.1) # 测试 eps 从 0.1 到 0.9
min_samples_range = range(1, 8)
这里只给出运行结果
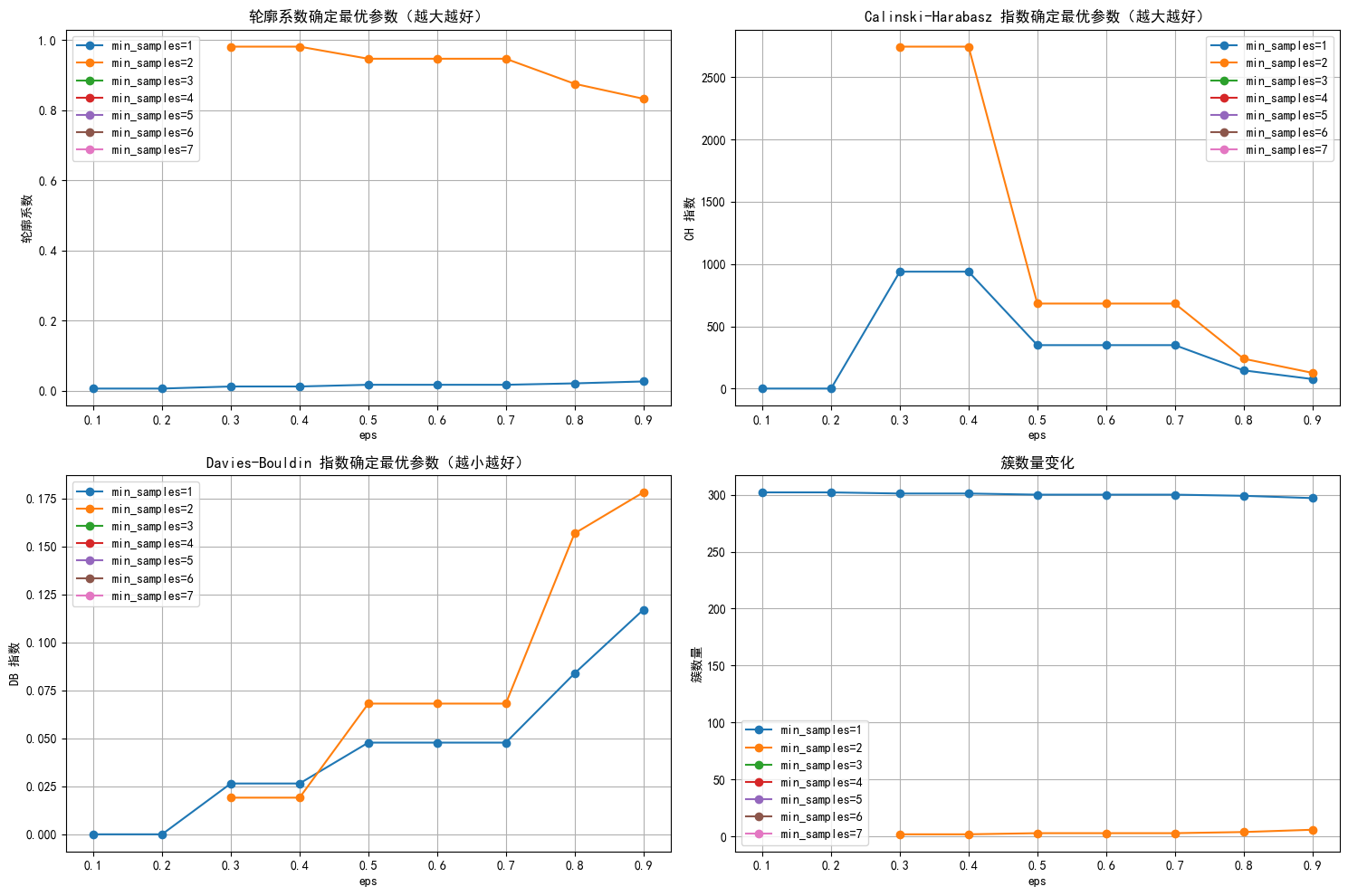
根据图标选择 eps 和 min_samples最佳参数值
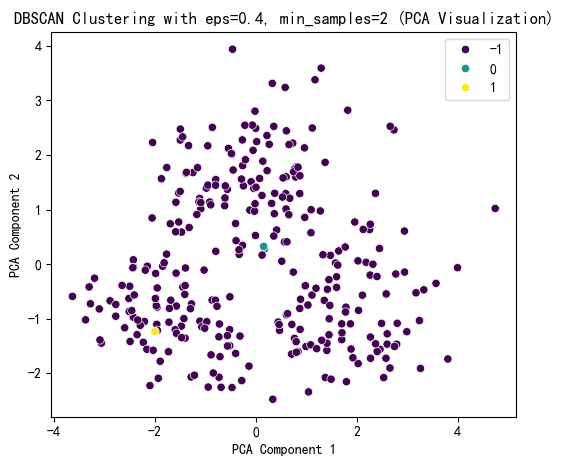
selected_eps = 0.4
selected_min_samples = 2
4.层次聚类
可能需要修改的参数
n_clusters_range = range(2, 11) # 指定簇数量,测试簇数量从 2 到 10
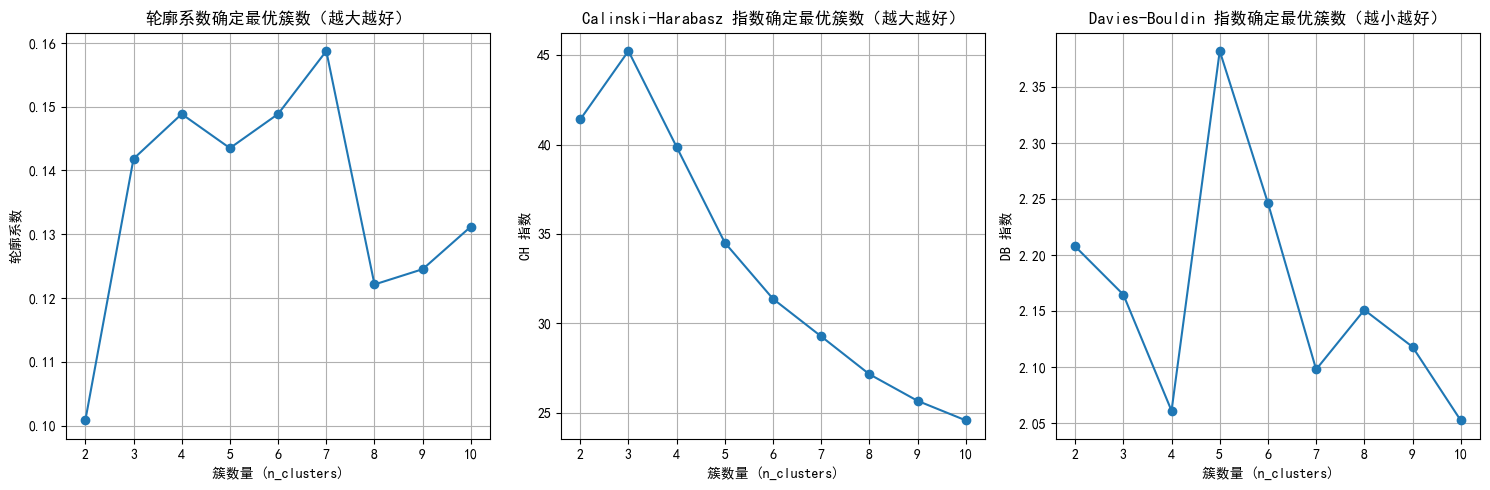
根据图表选择最佳参数
selected_n_clusters = 7
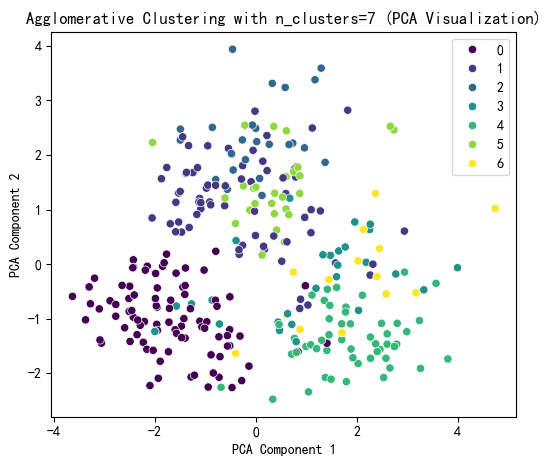
无监督聚类总结:
数据预处理:在进行聚类分析之前,需要对数据进行预处理:
- 数据清洗,去除缺失值、异常值等;
- 特征选择和提取,选择与聚类目标相关的特征,避免无关或冗余特征对聚类结果的干扰;
- 数据标准化或归一化,将不同尺度的特征转换到相同的尺度,以避免特征尺度对聚类结果的影响。
评估指标选择:无监督聚类没有标记的真实类别信息,常用的评估指标有轮廓系数、Calinski - Harabasz 指数、Davies-Bouldin 指数等。
- 轮廓系数综合考虑了样本与同簇内其他样本的相似度以及与其他簇中样本的相似度,其值越接近 1,表示聚类效果越好;
- Calinski - Harabasz 指数越大,说明聚类结果的类内紧凑性和类间分离度越好。
算法参数调整:不同的聚类算法有不同的参数,需要根据数据特点和聚类目标进行合理调整。例如,KMeans 算法和层次聚类要提前指定簇的数量、DBscan 算法要指定邻域半径eps和最小点数min_samples等。通过多次实验和对比不同参数下的聚类结果,选择最优的参数组合。
from sklearn.cluster import KMeans
# 示例代码展示参数使用
kmeans = KMeans(n_clusters=3, init='k-means++', n_init=10, max_iter=300, tol=1e-4, random_state=42)
n_clusters:必需的整数参数,代表要形成的簇的数量,也就是K值。init:用于指定初始化聚类中心的方法,有以下几种取值:'k-means++':默认值,该方法能智能地选择初始聚类中心,从而加快收敛速度。'random':随机选取初始聚类中心。- 也可以传入一个数组,直接指定初始聚类中心。
n_init:整数类型,默认值为 10。它表示使用不同的初始聚类中心运行算法的次数。算法会选取聚类结果最好(也就是惯性值最小)的那次作为最终结果。max_iter:整数类型,默认值为 300。它代表算法单次运行时的最大迭代次数。若达到这个次数,即便聚类中心还未完全收敛,算法也会停止。tol:浮点数类型,默认值为1e-4。这是判断算法收敛的阈值,当聚类中心的变化小于该阈值时,算法会认为已经收敛并停止迭代。random_state:整数、RandomState实例或者None(默认值)。它用于设定随机数种子,保证每次运行算法时的初始聚类中心是相同的,从而让结果具有可重复性。
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps=0.3, min_samples=5, metric='euclidean')
eps:浮点数类型,默认值为 0.5。它代表邻域的半径,用于确定一个点的邻域范围。min_samples:整数类型,默认值为 5。表示一个点成为核心点所需的最小邻域点数。metric:字符串或者可调用对象,默认值为'euclidean'。用于计算点之间距离的度量方法,常见的取值有'euclidean'(欧氏距离)、'manhattan'(曼哈顿距离)等。
from sklearn.cluster import AgglomerativeClustering
agg_clustering = AgglomerativeClustering(n_clusters=3, affinity='euclidean', linkage='ward')
n_clusters:整数类型,默认值为 2。表示要形成的簇的数量。affinity:字符串或者可调用对象,默认值为'euclidean'。用于计算样本或簇之间的相似度的度量方法,常见的取值有'euclidean'(欧氏距离)、'manhattan'(曼哈顿距离)等。linkage:字符串类型,有以下几种取值:'ward':默认值,采用沃德方差最小化算法,试图使合并后簇内的方差最小。'complete':使用最大距离,即两个簇中最远样本之间的距离。'average':使用平均距离,即两个簇中所有样本对之间的平均距离。'single':使用最小距离,即两个簇中最近样本之间的距离。
结果的稳定性和可解释性:在实际应用中,需要考虑聚类结果的稳定性:对于相同或相似的数据,聚类结果应该具有一定的一致性。同时,聚类结果应该具有可解释性,能够为实际问题提供有价值的信息和决策依据。如果聚类结果难以解释或不稳定,需要进一步分析原因,调整算法或参数。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









