






实训1 读取无人售货机数据
1、训练要点
(1)掌握数据的读取方法。
(2)掌握数据合并方法。
(3)掌握数据的校验方法。
(4)掌握数据的清洗方法。
2、需求说明

(1)使用pandas中的read_csv函数分别读取数据。
import pandas as pd
# 使用read_csv函数读取CSV文件
df1 = pd.read_csv('G:/第2章/data/数据1.csv', encoding='gb18030',low_memory=False)
df1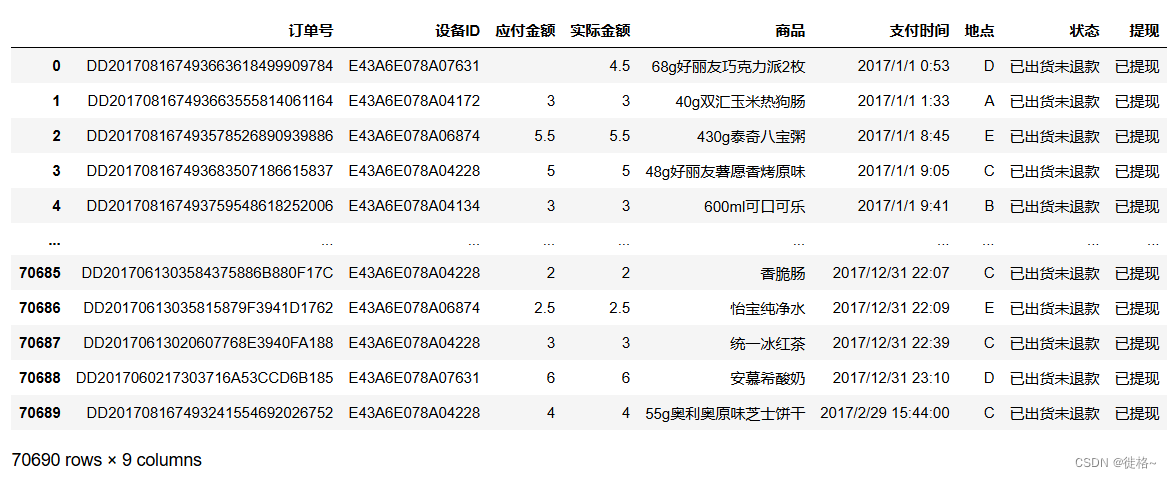
import pandas as pd
# 使用read_csv函数读取CSV文件
df2 = pd.read_csv('G:/第2章/data/数据1.csv', encoding='gb18030',low_memory=False)
df2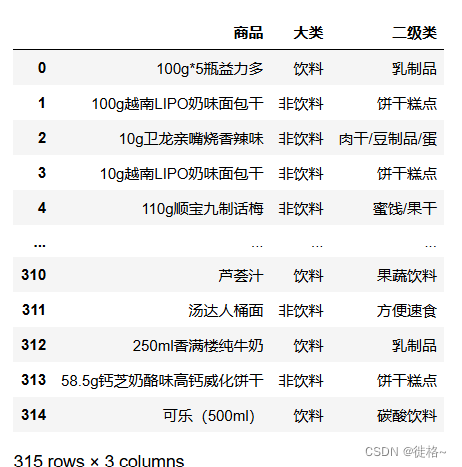
(2)使用pandas中的merge函数或join()方法进行数据合并。
import pandas as pd
# 使用read_csv函数读取CSV文件
df1 = pd.read_csv('G:/第2章/data/数据1.csv', encoding='gb18030',low_memory=False)
print('数据1原始数据:',df1.shape)
df2 = pd.read_csv('G:/第2章/data/数据2.csv', encoding='gb18030',low_memory=False)
print('数据2原始数据:',df2.shape)
# 假设df1和df2都有一个共同的列名'key',我们将基于这个列进行合并
# 使用merge函数合并DataFrame
merged_df = pd.merge(df1, df2, on='商品')
print('合并后的数据:',merged_df.shape)
# 打印合并后的DataFrame
print(merged_df)
merged_df.to_csv('G:/第2章/data/merged_file.csv', index=False)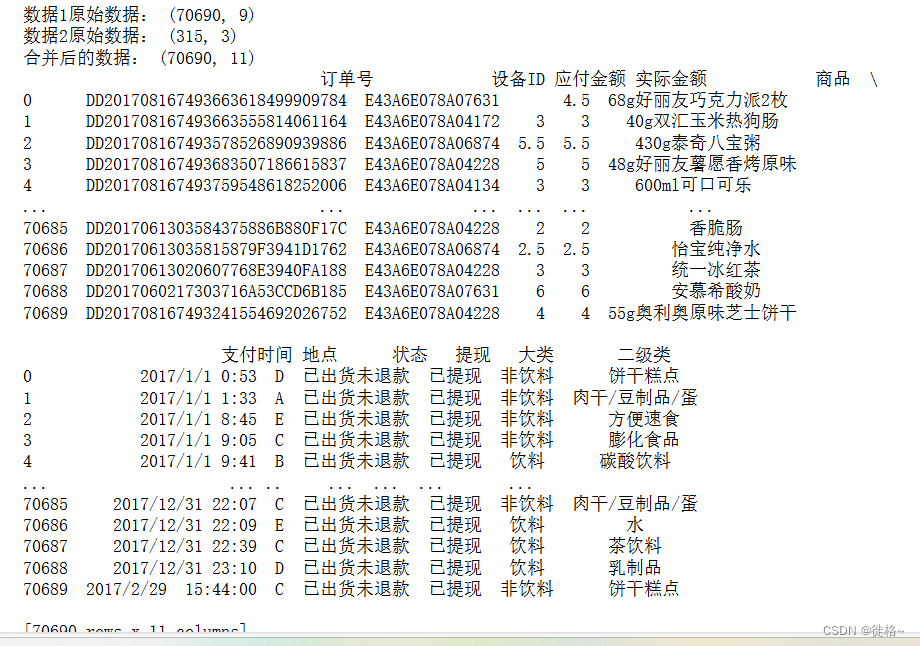
(3)查找重复记录并进行删除。
import pandas as pd
# 读取CSV文件
data1 = pd.read_csv('G:/第2章/data/merged_file.csv', low_memory=False)
# 定义去重函数
def delRep(list1):
return list(dict.fromkeys(list1))
# 假设sku_name是data1中的一个列名
sku_name_column = '商品' # 这里需要替换成实际的列名
# 查找重复值并删除
data1_drop_duplicates = data1.drop_duplicates(subset=[sku_name_column])
print('删除重复项后的数据行数:', len(data1_drop_duplicates))
# 保存处理后的数据到新的CSV文件
data_dropna.to_csv('G:/data/重复值.csv') ![]()
(4)查找异常数据并进行删除。
import pandas as pd
# 读取CSV文件
data = pd.read_csv('G:/第2章/data/merged_file.csv', low_memory=False)
# 删除'应付金额'或'实际金额'列为空的行
data_dropna = data.dropna(subset=['应付金额', '实际金额'])
print('删除异常值:',len(data_dropna))
# 保存处理后的数据到新的CSV文件
data_dropna.to_csv('G:/第2章/data/异常值.csv')![]()
(5)查找缺失值并进行处理(删除、填充等)。
import pandas as pd
import numpy as np
# 读取CSV文件
data = pd.read_csv('G:/第2章/data/merged_file.csv', low_memory=False)
# 删除含有缺失值的行
data_dropna = data.dropna() # 这将删除任何含有至少一个缺失值的行
print('异删除填充值:',len(data_dropna))
# 保存处理后的数据到新的CSV文件
data_dropna.to_csv('G:/第2章/data/删除缺失值.csv')
# 使用0填充缺失值
data_filled = data.fillna({'应付金额': 0, '实际金额': 0})
print('填充值:',len(data_filled))
# 保存处理后的数据到新的CSV文件
data_filled.to_csv('G:/第2章/data/处理好的数据.csv')

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











