






目录
1.什么是urllib库
2. 快速使用urllib爬取网页
3. 使用urllib实现数据传输
4. 添加特定Headers-请求伪装
5. 代理服务器
6. 超时设置和常见的网络异常
1.什么是urllib库
urllib是Python标准库之一,用于与互联网上的资源进行交互,例如访问网页、处理URL参数、传输数据等。
| 模块名称 | 描述 |
| urllib.request | 请求模块 |
| urllib.error | 异常处理 |
| urllib.parse | url解析模块 |
| urllib.robotparser | robots.txt解析模块 |
安装urllib库的命令如下:
pip install urllib2. 快速使用urllib爬取网页
Python3出现后,之前Python2中的urllib2库被移到了urllib.request模块中,之前urllib2中很多函数的路径也发生了变化,希望大家在使用的时候多加注意。
使用urllib.request模块来实现简单的网页爬取。
以下是一个示例:
# 导入urllib库的request模块,该模块提供了发送HTTP请求的功能。
import urllib.request
# 使用urlopen函数发送GET请求到"https://www.baidu.com",并返回响应对象。
response = urllib.request.urlopen("https://www.baidu.com")
# 从响应对象中读取返回的数据,这里假设返回的是UTF-8编码的字节流。
html = response.read().decode('UTF-8')
# 打印获取到的HTML内容。
print(html)运行结果:
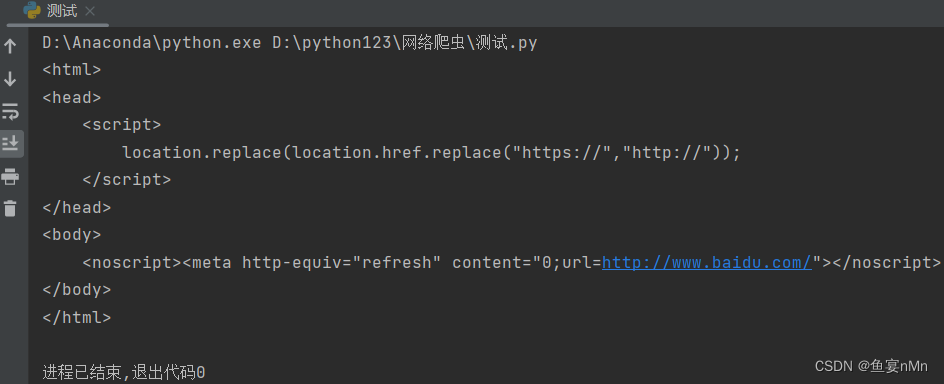
需要注意的是,由于网络请求可能受到各种因素的影响,如网络连接、服务器响应等,因此这段代码的实际运行结果可能会因网络状况的不同而有所差异。
分析urlopen方法:
前面在爬取网页时,有一句核心的爬虫代码:
response = urllib.rresponse = urllib.request.urlopen("https://www.baidu.com")这段代码调用的是urllib.request模块中的urlopen方法,它传入了一个百度首页的URL,使用的协议是HTTP,这是urlopen方法最简单的用法。
urlopen方法可以接收多个参数:
url一表示目标资源在网站中的位置。
data一用来指明向服务器发送请求的额外信息。
timeout一该参数用于设置超时时间,单位是秒。
context一实现SSL加密传输,这个参数很少使用。
3. 使用urllib实现数据传输
在爬取网页时,通过URl传递数据的方式主要分为GET和POST两种。这两种方式最大的区别在于:GET方式是直接使用URl访问,在URL中包含了所有的参数;POST方式则不会在URL中显示所有的参数。这里只介绍URL编码转换。
URL编码转换:
当传递的URL中包含中文或者其它特殊字符(例如:空格或者/等)时,需要使用urllib.parse库中的urlencode()的方法将URL进行编码,它可以将"key:value"这样的键值对转换成" key=value"这样的字符串。
示例代码如下:
import urllib.parse
data={
'a':'传智播客',
'b':'黑马程序员'
}
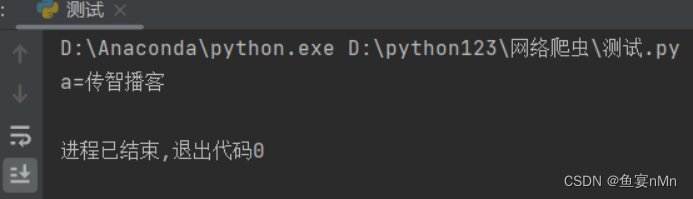
result=urllib.parse.urlencode(data)
print(result)运行结果:

解码使用的是url.parse库的unquote方法,示例代码如下:
import urllib.parse
result=urllib.parse.unquote('a=%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2')
print(result)运行结果:
4. 添加特定Headers-请求伪装
如果不是从浏览器发出的请求,我们是不能获得响应内容的。针对这种情况,我们需要将爬虫程序发出的请求伪装成一个从浏览器发出的请求。
添加特定Headers—请求伪装
运行结果:
#导入urllib库的request模块,用于发送HTTP请求
import urllib.request
# 定义要请求的URL
url = "https://www.baidu.com" #这里只是用百度做一个示范
# 定义请求头,User-Agent表示模拟的浏览器信息
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"
}
# 使用Request类创建一个请求对象,并传入URL和请求头
request = urllib.request.Request(url, headers=headers)
# 使用urlopen函数发送HTTP请求,并获取响应对象
response = urllib.request.urlopen(request)
# 从响应对象中读取HTML内容
html = response.read()
# 打印HTML内容
print(html)运行结果:

5. 代理服务器
很多网站会检测某一段时间某个IP的访问次数,如果同一IP访问过于频繁,那么该网站会禁止来自该IP的访问。这时我们可以使用代理服务器,每隔一段时间换一个代理。如果某个IP被禁止,那么就可以换成其他IP继续爬取数据,从而可以有效解决被网站禁止访问的情况。
示例代码:
# 导入urllib库的request模块,该模块提供了发送HTTP请求的功能。
import urllib.request
# 创建一个代理处理器,设置代理服务器的信息。
proxy_handler = urllib.request.ProxyHandler({"http": "http://124.88.67.81:80"})
# 使用build_opener函数创建一个opener对象,这个对象可以用来发送HTTP请求。
# 在这里,我们通过传入刚刚创建的代理处理器给build_opener,使得创建的opener对象会通过代理服务器发送HTTP请求。
opener = urllib.request.build_opener(proxy_handler)
# 使用opener对象发送一个GET请求到指定的URL。
# 这里请求的是"https://www.baidu.com",即百度的首页。
response = opener.open("https://www.baidu.com")
# 读取响应的内容,并打印出来。
print(response.read())运行结果:

当然如果你的代理IP足够多,就可以像随机获取User-Agent样,随机选择一个代理去访问网站。
6. 超时设置和常见的网络异常
当我们在访问网页时,可能会遇到服务器超时或其他网络异常。为了避免程序长时间等待,可以设置超时时间。
示例代码:
# 导入urllib库的request模块,这个模块提供了很多用于处理URL和HTTP请求的功能
import urllib.request
# 定义一个字符串变量,存储我们想要请求的URL
url = "https://jump2.bdimg.com/" #这以一个百度贴吧的吧为例子
# 使用try-except结构来处理可能出现的异常情况
try:
# 使用urllib.request.urlopen函数发送一个HTTP GET请求到上面定义的URL,并获取服务器的响应
# timeout参数设置为5,这意味着如果服务器在5秒内没有响应,urlopen函数将会抛出一个异常
response = urllib.request.urlopen(url, timeout=5)
# 从响应对象中读取返回的数据,这个数据通常是一个字节流,我们这里假设服务器返回的是HTML内容
html = response.read()
# 打印获取到的HTML内容
print(html)
# 如果在尝试打开URL或读取响应数据时出现了任何错误,那么urllib.error.URLError异常将会被抛出
except urllib.error.URLError as e:
# 打印出异常信息,这样我们可以知道出现了什么错误
print(e)运行结果:

总结:
本次介绍了使用urllib库来抓取网页数据的基本方法,通过学习这些内容,您将了解urllib库的一些功能和用法,掌握转换URL编码、添加特定Headers、使用代理服务器以及处理超时和常见网络异常的方法。希望对您有所帮助!















 6235
6235











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









