







目录
前言
今天是插入排序的最后一个了,希尔排序。
哈哈,这可不意味着数据结构结束了,明天将开启新的篇章:交换排序。
学习算法的过程,并不总是坦坦大路,只要友友们喜欢,喵喵我呀,一定会分享每天所得,每天的点点滴滴,以及喵喵与代码的情仇恩怨。
概述
利用(http://数据结构第一天(生成1000以内的随机数自动填充数组)中的代码自动生成五个随机整数,并自动储存在数组中:
其实,直接插入排序的效率在某些时候是很高的,比如, 我们的记录本身就是基本有序的,我仍只需要少量的插入操作,就可以完成整个记录 集的排序工作,此时直接插入很高效。还有就是记录数比较少时,直接插入的优势也 比较明显。可问题在于,两个条件本身就过于苛刻,现实中记录少或者基本有序都属 于特殊情况 。
有条件当然是好,条件不存在,我们创造条件也是可以去做的。
我们可以想到,将原本有大量记录数的记录 进行分组。分割成若干个子序列,此时每个子序列待排序的记录个数就比较少了,然 后在这些子序列内分别进行直接插入排序,当整个序列都基本有序时,注意只是基本 有序时,再对全体记录进行一次直接插入排序。
因此,我们可以采取跳跃分割的策略 :将相距某个‘增量'的记录组成 个子 序列,这样就能保证在子序列内分别进行直接插入排序后得到的结果是基本有序的。
需要补充说明的是:这个增量必须是互质的,比如增量选择为7,5,3,1这样的一系列分组,同时,最后一个增量必须为1;这一系列增量我们可以通过来获取。
下面就以增量为3,1举例: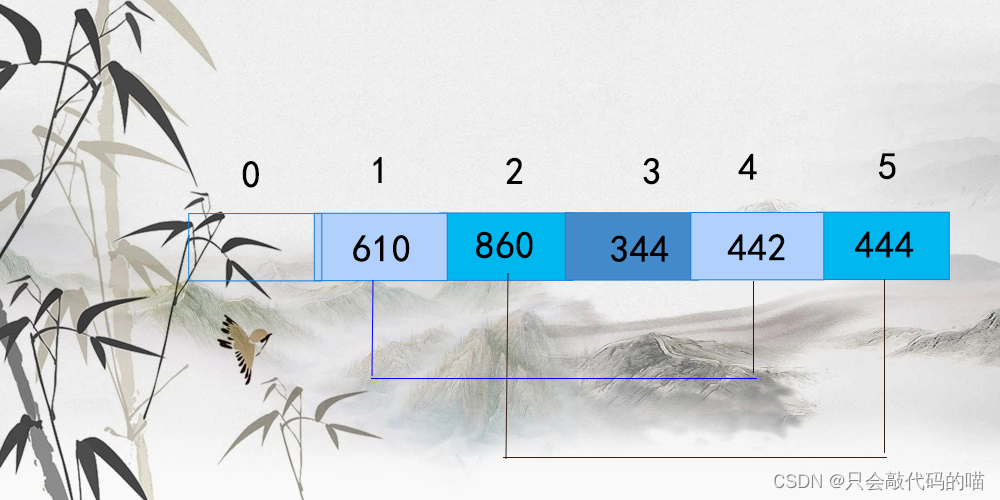
增量为3时,1和4为一组,2 和5为一组, 排序结果:
经过上一轮分组排序之后,基本变成有序的了 ,最后增量为1分组,数组中所有元素都会参加排序:
最终排序结果如下:
源码:
void sort(int* dest, const unsigned int dataCnt, int interval)
{
int minNum = *dest;
int circleTime = 0;
(dataCnt%interval > 0) ? circleTime = dataCnt / interval + 1 : circleTime = dataCnt / interval;
for (int k = 0; k <= interval; ++k)
{
for (int i = 0; i < circleTime; ++i)
{
for (int j = 0; j <circleTime; ++j)
{
if (*(dest + k + (j + 1)*interval)<*(dest + k + j*interval) && (j + 1)*interval + k+1<= dataCnt)
{
swap(*(dest + k + (j + 1)*interval), *(dest + k + j*interval));
}
}
}
}
}
void sortByShellInsert(int* dest, const unsigned int dataCnt, const unsigned int circleTime )
{
for (int i = circleTime; i > 0; --i)
{
int interval = pow(2, i) - 1;
sort(dest, dataCnt, interval);
}
}主函数:
int main()
{int array[16] = { 0 };
numberProducer.getFilledArray(array,16);
cout << " 原 始 数 据 :";
numberProducer.showArray(array,16);sortByShellInsert(array, 16, 5);
cout << "希尔插入排序后 :";
numberProducer.showArray(array, 16);sortByBinarySearchInsert(array, 16);
cout << "折半插入排序后 :";
numberProducer.showArray(array, 16);sortByDirectInsert(array, 16);
cout << "直接插入排序后 :";
numberProducer.showArray(array, 16);
system("pause");
return 0;
}
运行结果:















 744
744











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









