






这一章我们介绍能自主浏览操作网页的WebAgent们和相关的评估数据集,包含初级任务MiniWoB++,高级任务MIND2WEB,可交互任务WEBARENA,多模态WebVoyager,多轮对话WebLINX,和复杂任务AutoWebGLM。
MiniWoB++数据集
- Reinforcement Learning on Web Interfaces using Workflow-Guided Exploration
- miniwob.farama.org/
这两年webagent的论文里几乎都能看到这个评测集的影子,但这篇论文其实是2018年就发表了。所以这里我们只介绍下数据集的信息~
MiniWoB++是基于gymnasium的模拟web环境,它在OpenAI的MiniWoB数据集上补充了更多复杂交互,可变页面等网页交互行为,最终得到的100个网页交互的评测集。一些组件的Demo示例如下
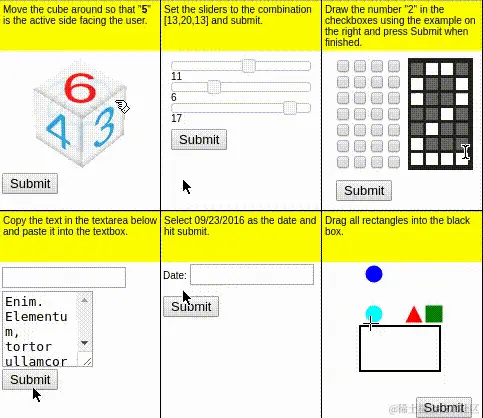
MiniWoB++数据集的局限性
- 非实际web页面而而是模拟web页面
- 页面被极大程度简化成了单独的交互组件,复杂程度低
- 指令是低级指令,直接描述如何和网页交互,例如下图的指令"选择下拉列表中的United Arab Emirates并点击提交"。而高级任务指令应该是"选择United Arab Emirates"
MIND2WEB
- MIND2WEB: Towards a Generalist Agent for the Web
- osu-nlp-group.github.io/Mind2Web/
数据集
MIND2WEB数据集在MiniWoB++数据集上做了以下几点改良
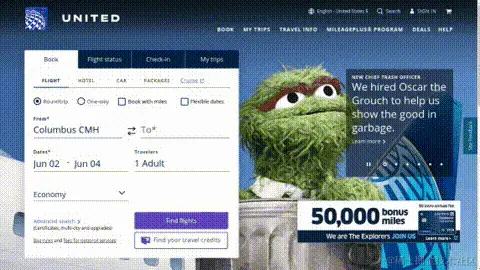
- 真实网页而非模拟组件,如下是美联航的首页
- 高级任务指令而非低级指令:例如"Search for all alternative concerts taking place in New York"
- 网页数据全面:包含了HTML代码,DOM文件和HAR日志,snapshot截图和TRACE
- 多领域任务:5大类31个小类,总共137个网站,并基于种子人工构造了2350个指令样本,5大类分别包括旅游,信息,娱乐,购物,通用服务类
让我们来具体看一个样本,任务指令=Check for pickup restaurant available in Boston, NY on March 18, 5pm with just one guest,Label是完成该指令的行为序列,每一步行为由(Target Element, Operation)构成,这里支持三种最常用的OPCLICK, TYPE,SELECT,行为序列如下

MIND2WEB采用了4个评估指标
- Element Accuracy:评估操作元素例如Botton的正确率
- Operation F1:评估对元素的操作准召,这里是token-level的F1计算因为有键入数据等操作
- Step Success Rate: 单步操作正确需要Element和Operation同时正确
- Task Success Rate:任务正确需要每一步都正确
Mind2WEB数据集主要局限性是只有数据采集时的网页静态页面HTML,没有后续行为的动态交互数据
MindAct
MINDAct框架因为是单一文本模态,因此使用HTML代码和DOM文件来作为网页的观测数据,框架比较简单由两个部分组成:元素排序生成候选,基于候选的多项选择生成行为
- Candidate Ranking 候选生成部分是一个二分类的打分模型。输入是任务指令+历点史Action+DOM元素,输出是每个DOM元素的候选概率。这里DOM元素的文本表征除了元素本身的信息,还从DOM文件树里面获取了parent和child节点的信息,拼接作为每个节元素的表征。如下

这里论文是通过随机负样本采样,训练了DeBERTa模型作为排序模型,测试集Top50召回在85%+。
- Action Prediction 基于上面元素排序返回的Top-K候选Element,会先对整个HTML进行裁剪,只保留候选元素前后的HTML文档。这样可以有效降低大模型的输入长度和复杂度,但对上面排序模型的召回要求较高。
之后会基于Top-K 候选,裁剪HTML,和历史的Action,选择下一步的的Action和Value。于是基于复杂HTML直接生成Action和Value的复杂任务,被简化成了多项选择的QA任务。这里论文是微调了Flan-T5来完成多项选择任务,也同时对比了直接使用GPT3.5和GPT4。

WEBARENA数据集
- WEBARENA: A REALISTIC WEB ENVIRONMENT FOR BUILDING AUTONOMOUS AGENS
- webarena.dev/
针对Mind2WEB只和静态网站状态交互的问题,WEBARENA通过构建仿真网站,构建了真实,动态,并且可复现的网络环境来和智能体进行交互。论文选择了电商,论坛,github,CMS等四类网站类型,并使用网站真实数据来构建模拟环境。
并且对比Mind2WEB的3种常见交互,支持更多的交互操作,并且因为是动态页面因此支持多tab切换的操作,支持的opeeration类型如下

数据集构成
- High Level 任务指令:包含数据查询,网站导航,内容创建等3个主要任务意图
- 812个测试样本:人工+chatgpt构建,从241个任务模板中创建出来,模板例如"create a {{site1}} account identical to my {{site2}} one"
- 网页数据:HTML + DOM + screenshot + Accessibility Tree(DOM的有效子集)

评估指标上相比Mind2WEB,WEBARENA同样使用task success rate作为评估指标,把token-level的F1计算进行了优化,加入了operation是否正确的检测方案。核心就是部分操作需要键入内容,而这部分内容不能直接和标注做精准匹配,因此WEBARENA分成了需要精准匹配的答案(exact match),只要包括核心信息即可(must include)和基于大模型做语义相似判断的(fuzzy match)这三类评估类型,对不同的样本进行评估。

WebVoyager
- WebVoyager: Building an End-to-end Web Agent with Large Multimodal Models
- github.com/MinorJerry/…
数据集
同样是动态网页交互,WebVoyager没有采用模拟网页数据,而是使用Selenium直接操控web浏览器行为和真实网页进行交互。于是同时满足了动态交互和真实网络环境的要求。
论文选取了15个有代表性的网站:Allrecipes, Amazon, Apple,ArXiv, BBC News, Booking, Cambridge Dictionary,Coursera, ESPN, GitHub, Google Flights,Google Map, Google Search, Huggingface, and Wolfram Alpha。
指令样本是基于Mind2Web的数据集作为种子,然后基于GPT4使用Self-Instruct来生成新的任务指令,最后使用人工校验和筛选。最终得到了每个网站40+的指令,总共643个评估任务。
评估指标和webARENA保持一致,都是采用任务成功率作为评估指标。
Agent
这里简单说下agent实现,WebVoyager和前面数据集的主要差异是加入了多模态模型GPT4—V的尝试。不再使用accessibility Tree的文本输入,而是直接和网页的snapshot进行交互。
这里论文采用了set-of-Mark Prompting的技术,来解决GPT4-V模型visual grounding的问题(模型对图片中细粒度物体的区分度有限,当输出是图片中局部物体例如按钮时准确率不高的问题)。SOM是先用SAM等分割模型对图片进行分割,这里主要是识别出图片上可交互的按钮和区域,使用bounding box进行圈选,并使用序号对区域进行标记。通过标记来帮助GPT4-V更精准的识别可交互区域。
这里论文使用了GPT-4V-ACT,JS DOM auto-labeler来识别网页中的所有可交互元素并进行标记,来作为GPT4-V的输入,如下

然后基于上面的标记图片输入,和以下ReACT的prompt指令,让GPT4V生成每一步的交互操作。基于模型推理结果会直接操作网页,并获取新的网页snapshot作为下一步的输入。

WebLINX
- WebLINX: Real-World Website Navigation with Multi-Turn Dialogue
- github.com/McGill-NLP/…
对比前面的MIND2WEB,WebArena和webVoyager,webLLINX加入了和用户的多轮对话交互,也就是从自主智能体向可交互智能体的转变。虽然放弃了自主,但有了人类的监督,可能可以达到更高的任务完成度。
WebLINX的数据集,包括8大类,50个小类总共155个真实网页,总共构建了2337个指令样本。 因为是对话式交互,所以指令类型会和以上的几个数据集存在明显的差异,不再是任务型指令而是步骤操作型的指令,如下图


agent部分论文更多是对比了文本模态vs多模态,微调vsprompt的效果,实现细节不太多这里就不细说了
AutoWebGLM
- AutoWebGLM: Bootstrap And Reinforce A Large Language Model-basedWeb Navigating Agent
- github.com/THUDM/AutoW…
AutoWebGLM是智谱最近才发布的webagent论文,包括比较全面的微调数据集构建和微调方案,并发布了新的评测集。论文提出AutowebGLM的数据集有三个主要优点
- 更高质量的web交互训练数据:人标很难构架大规模训练数据,这里使用模型标注并通过技巧提高模型标注准确率
- 统一10类交互行为:其实和WEBARENA基本一致
- HTML简化裁剪方案:构建可交互元素树
数据集
AutoWebGLM的微调数据集包含由易到难的三种任务:web recognition,single-step task,multi-step task。这里也是纯HTML文本模态的数据集。除了以下全新的三类样本,论文还合并了MiniWoB++和Mind2Web的训练集。

web Recognition
网页识别样本构建,是直接从HTML中提取可交互元素,然后基于元素构建简化的HTML输入。然后Input是网页元素功能的相关提问,输出是GPT的回答,例如"Search Bar是用来干什么的",模型回答“它是用来帮助用户搜索产品的”。这部分样本用来帮助模型理解HTML。
Single-step task(Simple)
简单任务是单步操作的网页交互。这里论文的构建比较巧妙,考虑到之前的论文已经论证了即便是GPT4在webagent这个任务上的执行准确率也有限,那直接使用GPT4来构建样本肯定是不可行的。因此论文采用了反向标注,既基于HTML中抽取出的可交互元素例如“scroll_page(‘down’)”,让GPT4来方向生成对应的意图和用户指令,例如我需要向下滑网页浏览更多。 这样可以得到准确率更高的样本,模型生成意图和指令的prompt如下

Multi-Step task(Complex)
复杂任务涉及和网页的多步交互。这里论文使用了Evol-Instruct来构建复杂任务指令(不熟悉的同学看这里解密Prompt系列17.LLM对齐方案再升级), 每个网页模型生成50个指令,再人工筛选20个。
考虑模型生成准确率不高,这里得多步交互,论文使用人工执行,并用浏览器插件捕捉用户交互行为的方案。这里为了在行为链路之外,同时获得模型COT思考链路,用来提高后面的模型训练效果。论文使用以下prompt,让大模型基于人工完整的行为链路,生成每一步的执行意图。

最终的AutoWebBench评测集只使用了多步任务的子集,也就是复杂指令来评测模型效果。
微调

基于以上的训练数据,论文采用了多阶段训练微调ChatGLM3
- SFT:第一步是指令微调,使用以上训练集,采用Curriculum Leanring的训练策略,既模仿人类学习,由易到难的训练样本进行逐步训练。先使用网页识别和单步任务训练,再使用多步任务数据训练。
- RL:第二步是强化学习,用来降低SFT部分模型学习的过度模仿和幻觉。这里论文采用了Self-Sampling来构建DPO需要的正负样本对,既使用正确答案作为正样本,使用模型预测错误的作为负样本,使用DPO和SFT的混合loss进行进一步的训练。
- RFT: 第三步是基于MiniWoB++和WebARENA虚拟环境,使用以上训练好的DPO模型构建了额外的训练样本。这里采用拒绝采样,既使用模型尝试N次,选取成功(规则标注或环境自带识别)的执行路径作为训练样本进行训练。相当于是把Rejection-Sampling的效果再训练进模型中。
效果上在AutoWebBench上,微调后的6B模型可以显著超过GPT4,和更大的LLAMA2基座模型,拥有更高的任务单步执行成功率。

同时论文做了消融实验来验证以上多阶段微调和三种训练样本的效果。实验显示,由易到难的训练数据对模型有较大提升,RFT在进一步训练的miniWob++和WebArena上有显著提升,但RL-DPO的效果不太明显。

如何学习大模型 AGI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
-END-
👉AGI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉AGI大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉AGI大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









