






一、大模型能力来源解析
(一)预训练:知识记忆与语义表示的基石
预训练是大模型能力的基础,通过对海量语料的统计分析,模型能够记忆知识并学习语义分布表示。例如,直接依据训练语料的统计,可计算出知识记忆概率,且模型准确率与语义互信息(SMI)呈高度正相关(R²>0.85)。这表明预训练使模型具备了知识存储的能力,为后续能力的发展奠定了基础。
(二)监督微调(SFT):激活预训练能力的关键
监督微调阶段仅需少量数据(如60条),就能使模型在特定领域的问答任务中表现提升。此阶段通过对模型参数的微小调整,激活预训练阶段所存储的知识。不过,不同模型对数据的需求存在显著差异,像Qwen - 2 - 7B在使用高质量数据时,测试准确率可达58.38%,而LLaMA - 2 - 7B仅为50.46%。并且,若使用记忆水平较低的数据进行微调,会大幅改变模型参数,所以使用记忆水平较高的数据进行SFT是更有效的策略。
(三)强化学习(RL):推理能力提升的助力
强化学习对大模型推理能力的提升有一定作用,但效果因模型而异。以“Countdown”游戏测试为例,Qwen模型通过RL训练后表现显著进步,而Llama模型却几乎停滞不前。进一步研究发现,高效思考的关键行为(验证、回溯、子目标设定、逆向链式推理)是提升推理能力的核心。当对Llama模型进行行为启发或优化预训练数据后,其推理能力也能得到显著改善,这表明推理能力并非完全依赖RL,认知行为的引导同样重要。
(四)数据多样性:影响模型性能的重要因素
数据多样性对SFT训练效果影响显著。通过多种指标(如熵、半径等)衡量数据多样性,发现多样化的数据选择策略(如NovelSelect)能有效提升模型性能。在二维空间模拟数据选择的实验中,同时考虑距离和密度的选择策略(选择C)相比具有冗余的数据集(选择A),能使模型在MT - bench等任务上的表现提升约3% - 5%。
二、大模型能力边界探索
(一)数学推理能力的局限性
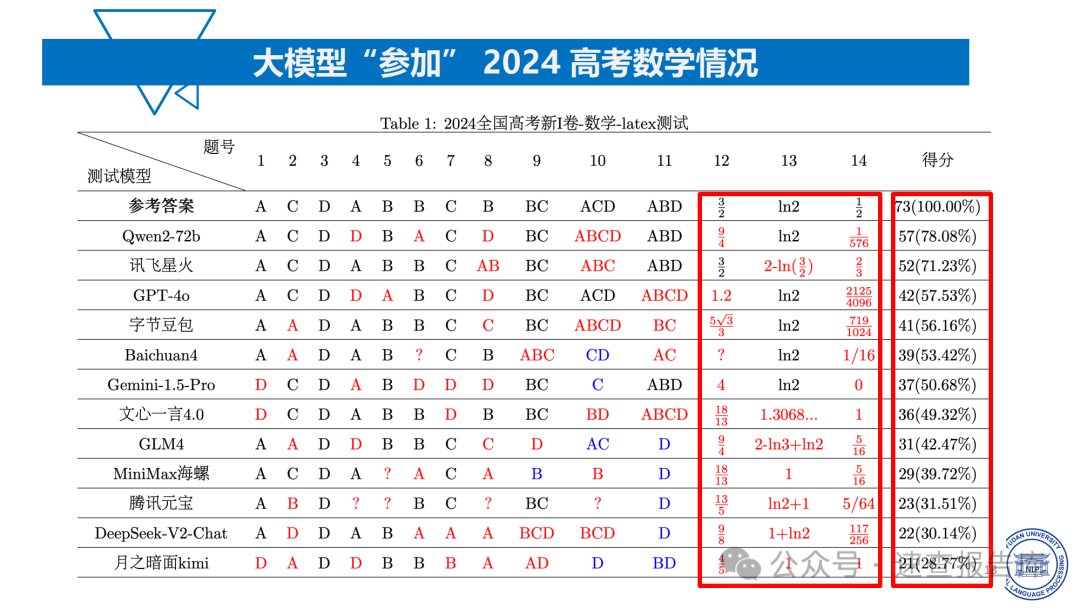
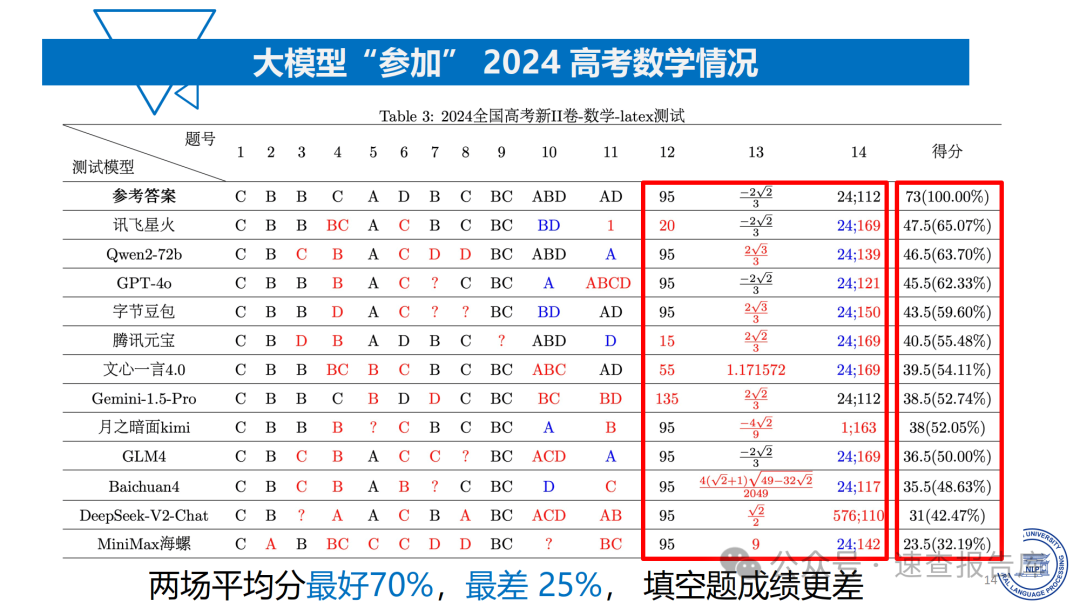
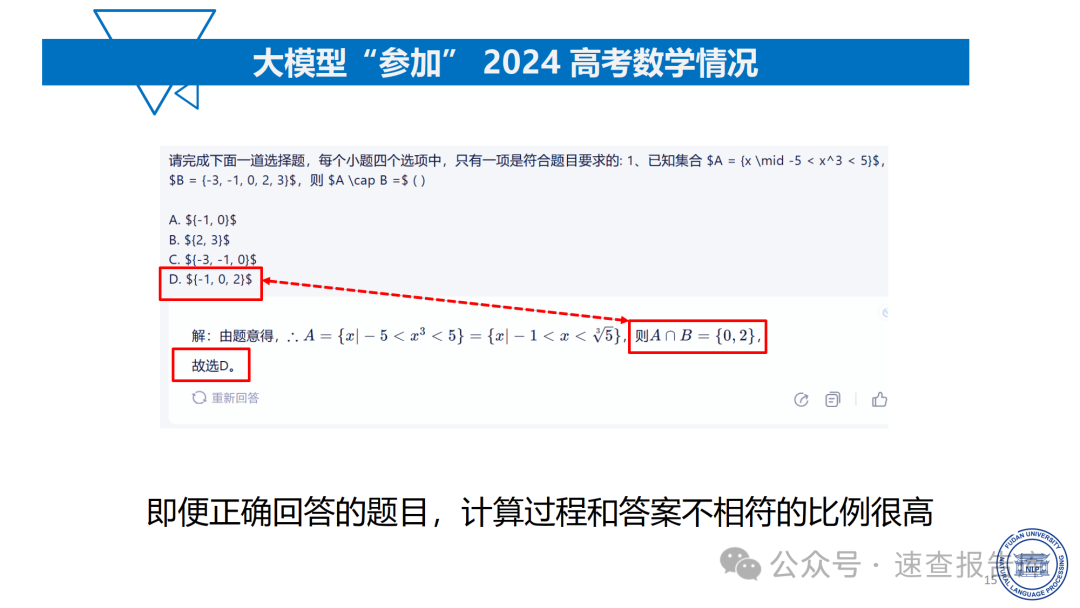
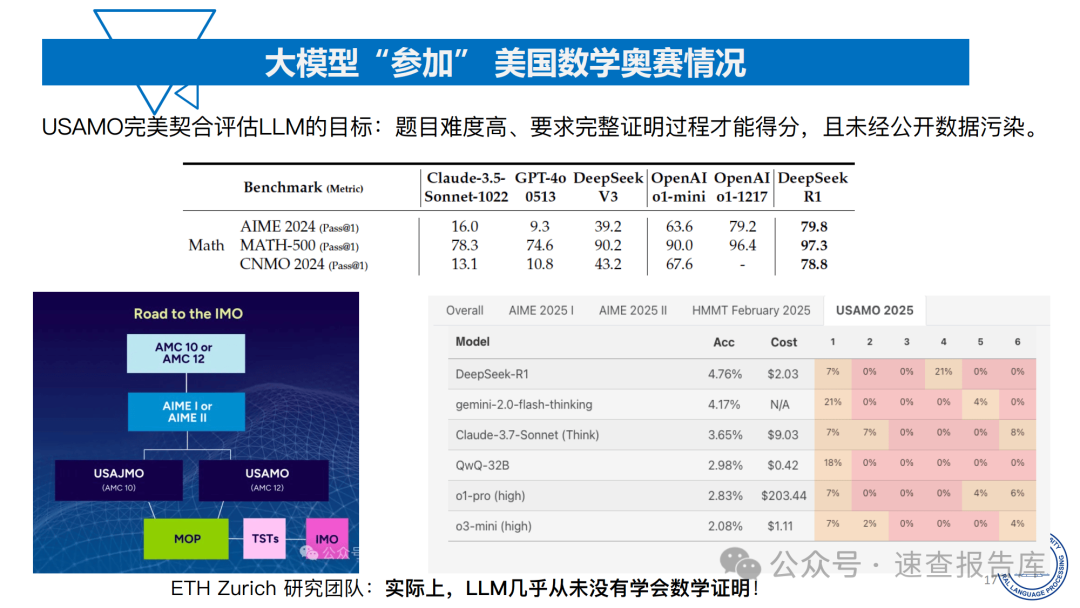
大模型在数学推理任务中表现出明显的局限性。以2024年高考数学测试为例,即便表现最好的Qwen2 - 72b在新I卷中得分仅为57分(78.08%),且存在计算过程与答案不符的情况。在更复杂的美国数学奥赛(USAMO)中,模型准确率普遍低于20%,当任务复杂程度增大时,模型准确率甚至接近为0。这说明大模型在逻辑推理和复杂问题解决方面与人类水平相差甚远。
(二)语言理解与生成的脆弱性
大模型的语言理解和生成能力存在脆弱性。修改模型语言核心区的1个参数,就会使模型输出完全混乱(如PPL从5.877骤升至376079936)。在跨语言任务中,破坏特定语言区域(如阿拉伯语、越南语)会导致该语言任务性能大幅下降(阿拉伯语MMLU得分从25.6降至1.5)。此外,输入形式的微小变化(如数学题中的额外描述)会导致模型答案错误,表明其对语义的理解不够稳健。
(三)工具调用与复杂任务的挑战
在工具调用任务中,大模型的表现受数据干扰影响显著。面对变形数据,即便像GPT - 4这样的模型,工具选择准确率也会从80%降至60%。在图表理解任务中,模型容易因识别错误或推理偏差给出错误答案,例如将图表中代表美国的深绿色误判为法国。这反映出大模型在处理结构化数据和多模态信息时能力有限。
三、总结与启示
(一)能力本质:统计学习而非真正智能
大模型的能力本质上是统计学习的结果,而非人类意义上的“理解”与“推理”。其知识来源于预训练数据的记忆,推理依赖于模式匹配,缺乏对物理世界的认知和因果理解能力。例如,模型可能知道“苹果总部在库比蒂诺”,但不理解“总部”的实际含义和地理关联。
(二)发展现状与未来方向
当前大模型在简单任务上可快速达到70分水平,但在复杂任务上难以突破90分瓶颈。未来研究需聚焦于增强模型的可解释性、因果推理能力和多模态理解能力,同时避免对其进行神话和拟人化。在应用层面,应注重场景选择,优先在数据丰富、任务规则明确的领域发挥大模型的价值,如信息检索、文本生成等,而在需要深度推理和专业判断的领域(如医疗诊断、复杂决策),需谨慎评估其可靠性。




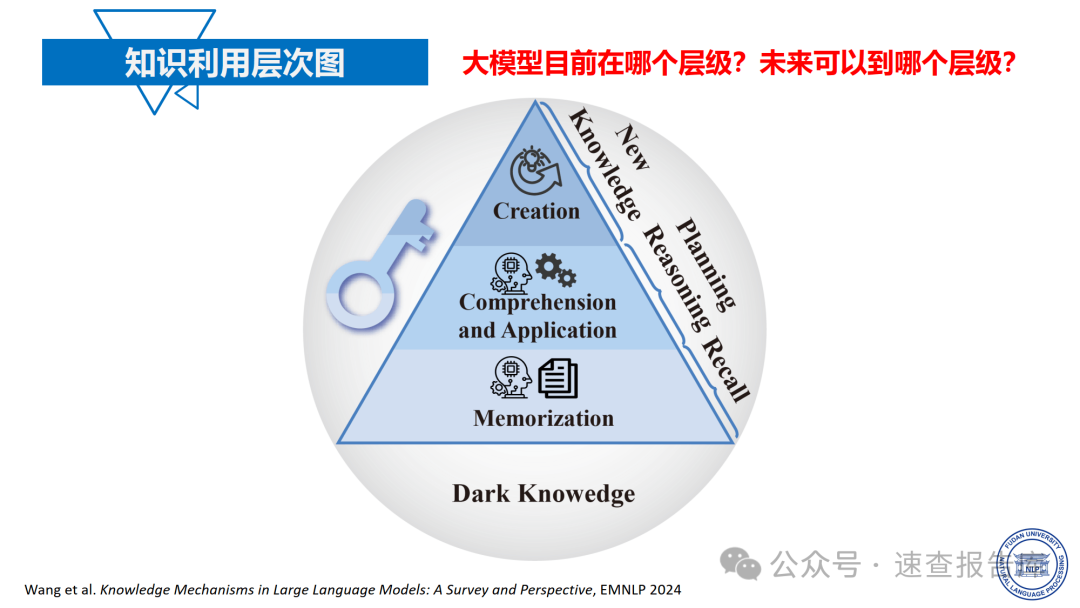
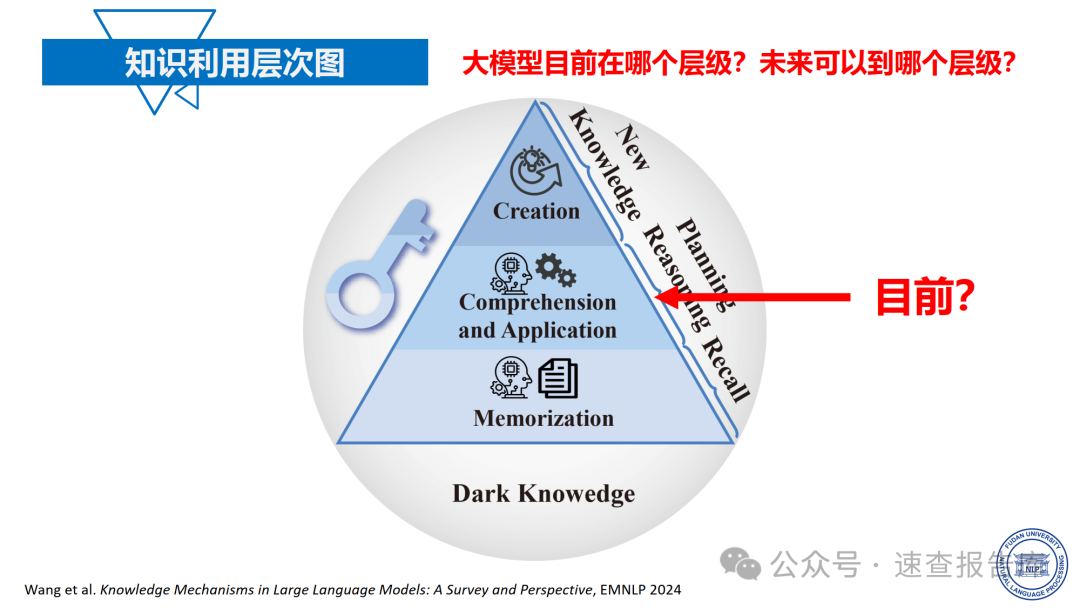
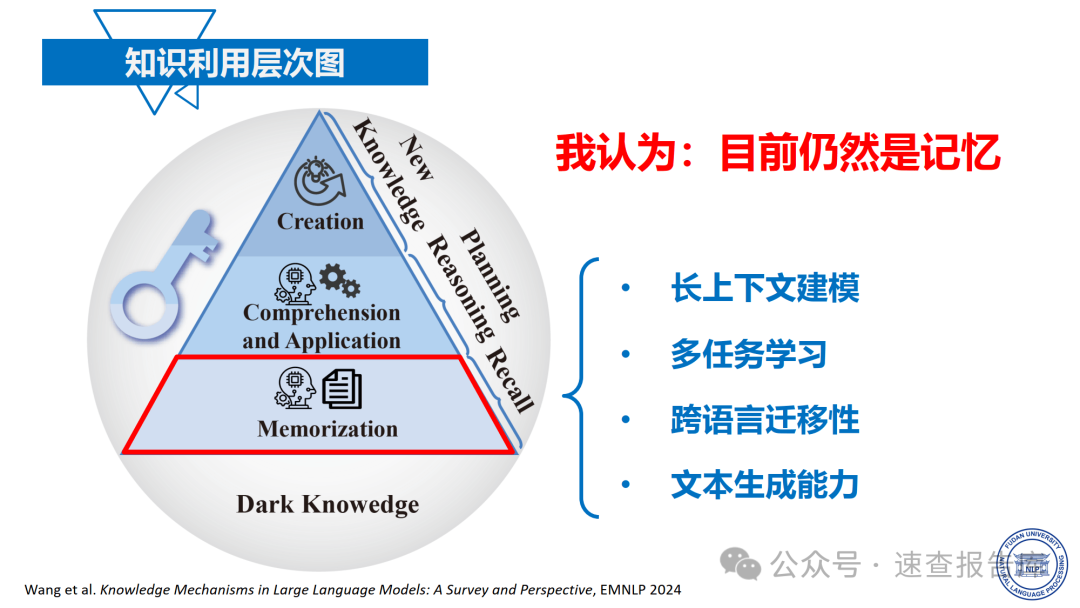
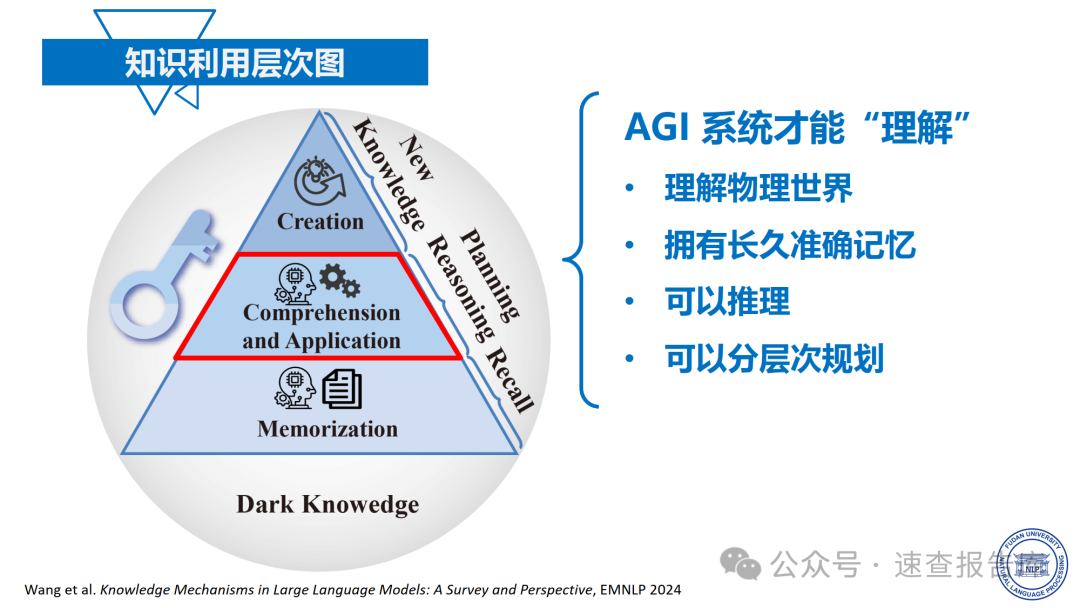



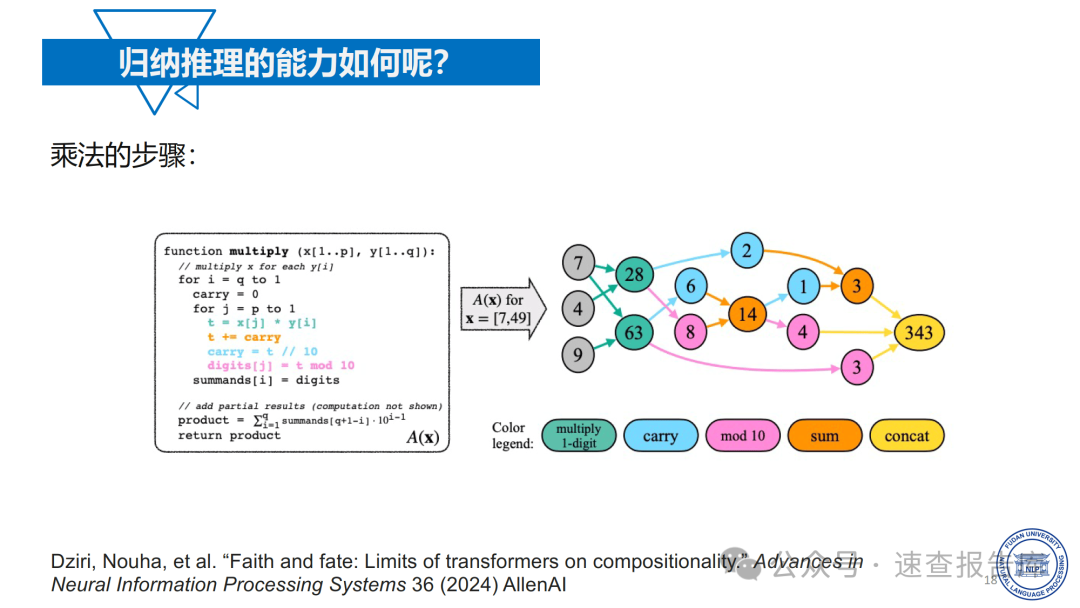
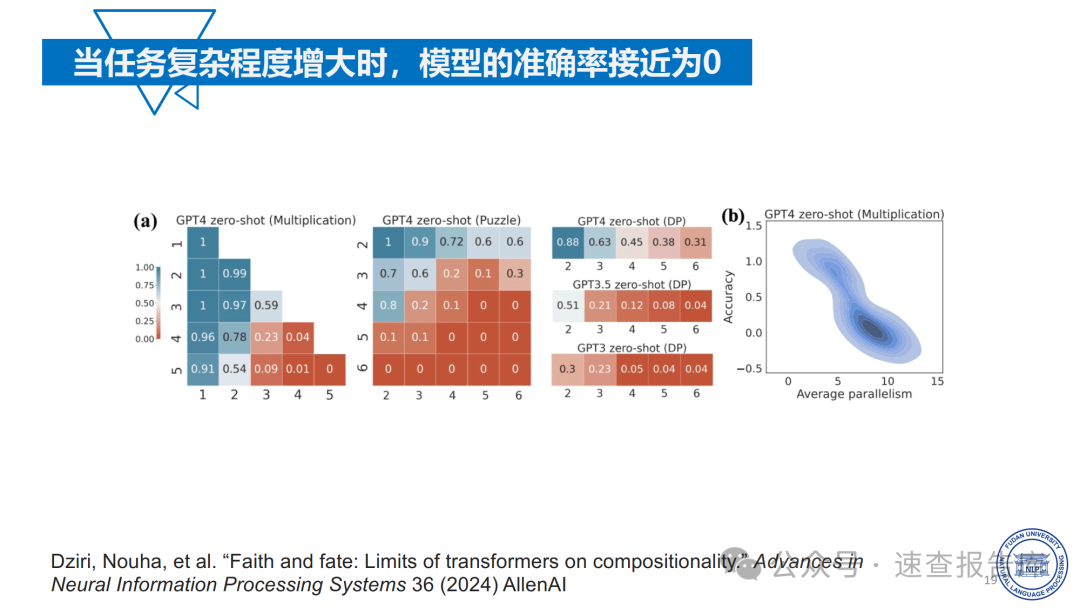


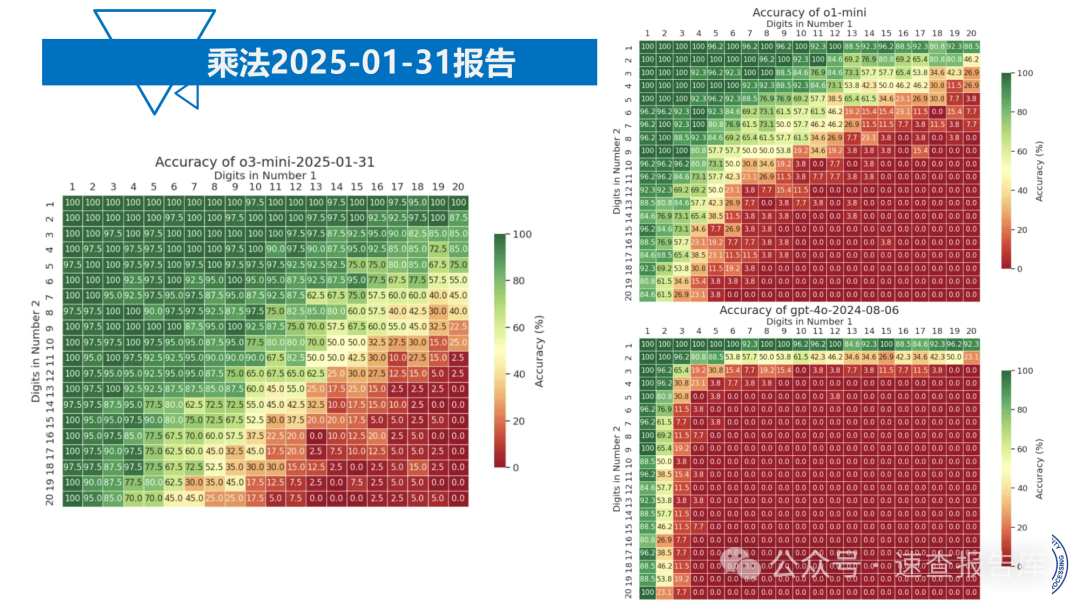
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~

👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。


👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。

👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。

👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。

👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









