






Python第八章作业
第一关统计字母数量
1.1 任务描述
读取附件是一篇英文短文,请编写程序统计这篇短文前 n 行中每一个英文字母出现的次数,结果按次数降序排列,次数相同时,按字母表顺序输出。若 n 值大于短文行数,输出整篇文章中每一个英文字母出现的次数(大写字母按小写字母统计)
1.2 设计思路
因为我们要统计.txt文件的信息 所以我们就要对它进行文件操作,打开读取关闭等。题目要求
前n行每个英文字符的出现的次数,我们就想到输入一个变量n来控制读取的行数
def openFile(fileName, n):
ls = []
mystr=""
with open(fileName, 'r', encoding='utf-8') as data:
for i in range(n):
# ls.append(data.readline().lower())
mystr +=data.readline().lower()
# ls = [data.readline().lower() for i in range(n)]
# return ls
return mystr
with open 的用法 with open(文件路径,模式,编码格式)as 文件名,它与f = open(文件路径,模式,编码格式)的区别 前者当走出with open 代码块时可以自动close掉文件,而f = open()要自己写close。
文件的读取就三个函数 一个是f.read() 不指定参数就是读完,指定参数就是读多少个字符

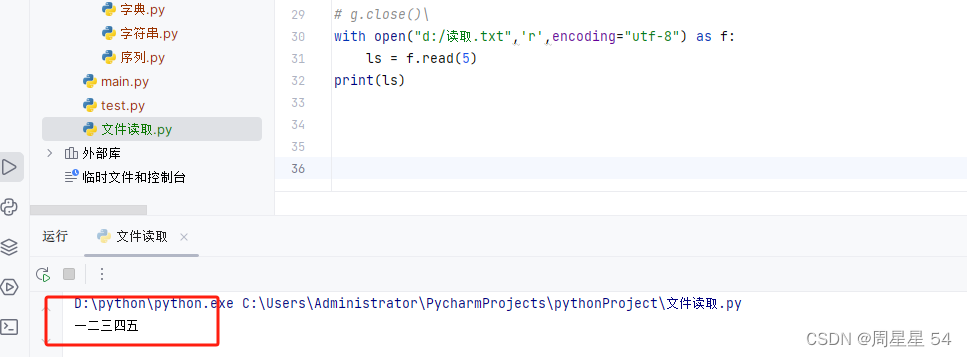
另外一个是f.readline() 和 f.readlines(), f.readlines() 是读完所有行,他们的返回值都是字符串哦。
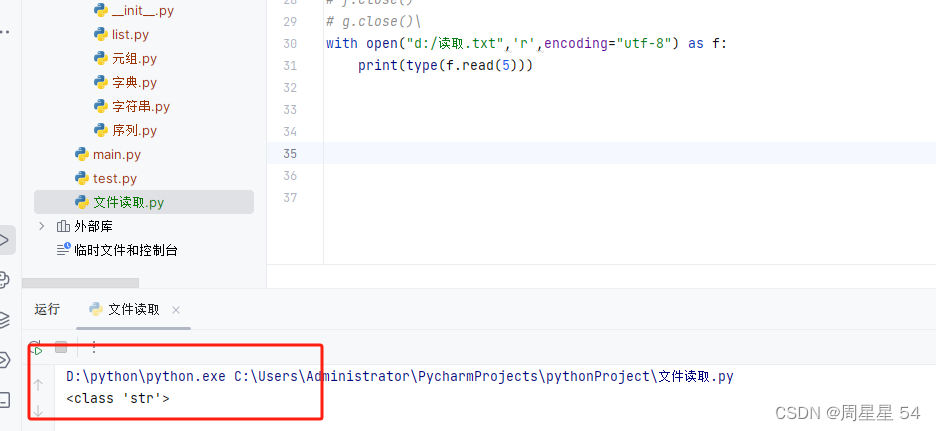
f.readline() 每调用一次读一行,那么我们是不是可以调用n次这个函数就可以读取n行了
def openFile(fileName, n):
mystr=""
with open(fileName, 'r', encoding='utf-8') as data:
for i in range(n):
mystr +=data.readline().lower()
return mystr
因为题目说都当成小写字母统计所以用了f.readline()。lower方法 把这些字符串拼接起来
def statistics(txt,s):
# dic = {}
# for x in mystr:
# if x in s:
# dic[x] = dic.get(x,0) + 1
dic ={x: mystr.count(x) for x in s}
return dic
定义一个 空字典,和字母表如果 x(mystr的元素在字母表中)对应建的值加一 返回字典 dic[x] = dic.get(x,0) + 1 dic。get(a,b)方法 a是键 b是默认值
def sort(dic):
ls = sorted(dic.items(), key = lambda item : (-item[1],item[0]))
return ls
dic.items()得到所有的键和值,因为是值的逆序所以是-item[1],同时要满足当次数一样是字母小的在前面所以lamba 表达式是key = lambda item : (-item[1],item[0]
1.4 总的代码实现
def openFile(fileName, n):
ls =[]
with open(fileName, 'r', encoding = 'utf-8') as data:
# for i in range(n):
# ls.append(data.readline().lower())
ls =[data.readline().lower() for i in range(n)]
return ls
def statistics(txt,s):
mystr = ' '.join(txt)
# dic = {}
# for x in mystr:
# if x in s:
# dic[x] = dic.get(x,0) + 1
dic ={x: mystr.count(x) for x in s}
return dic
def sort(dic):
ls = sorted(dic.items(), key = lambda item : (-item[1],item[0]))
return ls
fileName ="step2/The Old Man and the Sea.txt"
s = 'qwertyuiopasdfghjklzxcvbnm'
n = int(input())
txt = openFile(fileName, n)
dic = statistics(txt,s)
ls = sort(dic)
for x in ls:
# print(f'{x[0]}的数量是{x[1]:>3}个')
print('{} 的数量是 {:>3} 个'.format(x[0],x[1]))















 5313
5313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









