







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前在阿里
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。


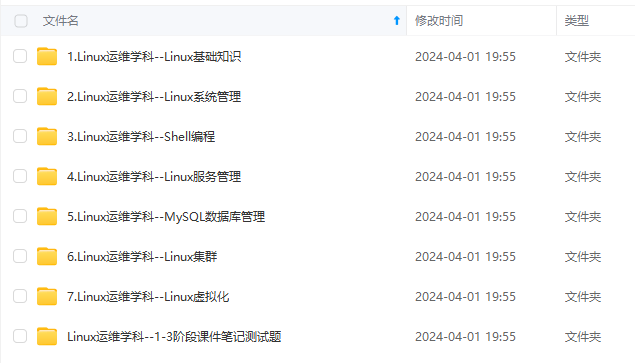
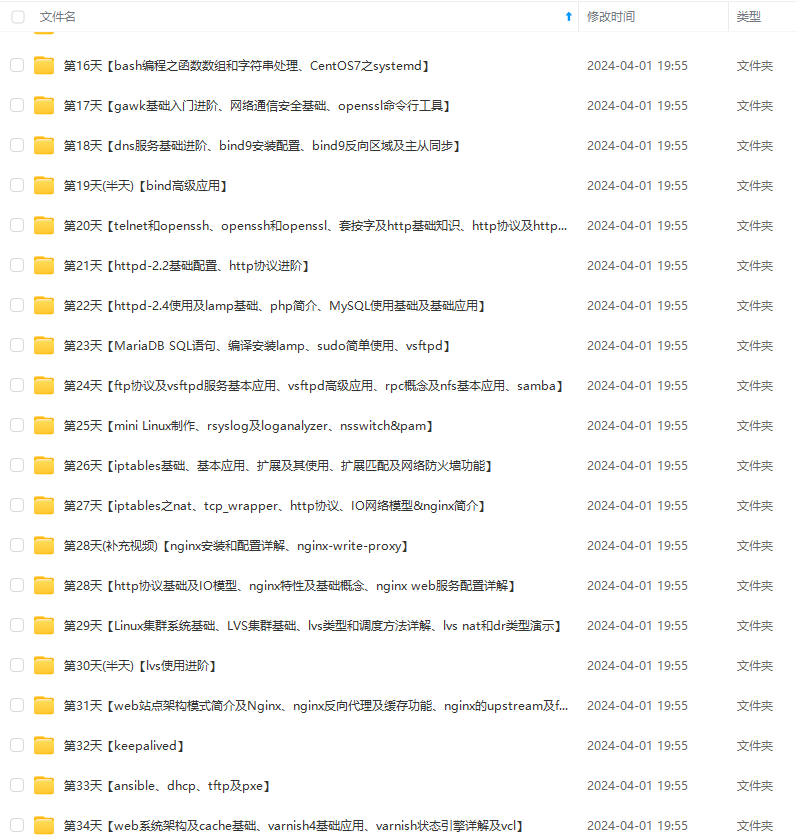
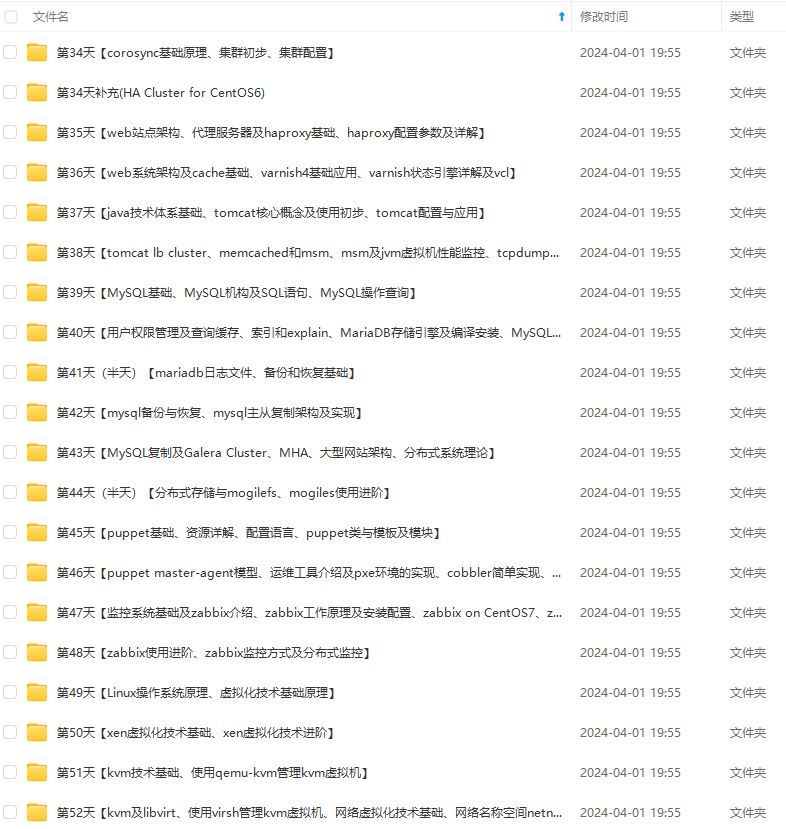
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
二级负载均衡器配置
我们发现,解决以上问题的更好办法,是在Kubernetes集群前配置负载均衡器,例如HAProxy或者NGINX。于是我们开始在AWS上的VPN中运行Kubernetes集群,并使用AWS ELB将外部web流量路由到内部HAProxy集群。HAProxy为每个Kubernetes服务配置了“后端”,以便将流量交换到各个pods。
这种“二级负载均衡器配置”主要也是为了适应AWS ELB相当有限的配置选项。其中一个限制是,它不能处理多个vhosts。这也是我们同时使用HAProxy的原因。只使用HAProxy(不用ELB)也能工作,只不过需要你在DNS级别解决动态AWS IP地址问题。

图1:我们的“二级负载均衡器配置流程“
在任何情况下,创建新的Kubernetes服务,我们都需要一种机制动态重新配置负载均衡器(在我们的例子中是HAProxy)。
Kubernetes社区目前正在开发一个名为ingress的功能,用来直接从Kubernetes配置外部负载均衡器。可惜的是,目前开发工作还未完成。过去一年,我们采用的是API配合一个小的开源工具来配置负载均衡。
配置负载均衡
首先,我们需要一个地方存储负载均衡器配置。负载均衡器配置可以存储在任何地方,不过因为我们已经有etcd可用,就把这些配置放在了etcd里。我们使用一个名为“confd”的工具观察etcd中的配置变动,并用模板生成了一个新的HAProxy配置文件。当一个新的服务添加到Kubernetes,我们向etcd中添加一个新的配置,一个新的HAProxy配置文件也就此产生。
不断完善的Kubernetes
Kubernetes中仍然存在众多待解决的问题,很多开发者在社区上、设计文档中讨论解决这些问题的新功能,但开发适用于每一个人的解决方案是需要时间的。不过从长远来看,这也是一件好事,用shortcut的方式设计新功能很多时候会适得其反。
当然,问题的存在并不意味着我们现在所使用的Kubernetes功能有限。配合API,Kubernetes几乎可以完成你想要的一切。等Kubernetes增加新功能后,我们再用标准方案替代自己的解决方案不迟。
话说回来,在我们开发了用于负载均衡的解决方案后,另一项挑战接踵而至:蓝绿部署(Blue-green deployments)。
Kubernetes上的蓝绿部署
蓝绿部署是一种不中断服务的部署。与滚动更新不同,蓝绿部署在旧版本仍然正常工作的情况下,通过启用一个运行着新版本的副本集群来实现更新。当新版本的副本集群完全启动并运行时,负载均衡器配置才会更改并将负载切换到新版本上。这种方式的好处是,永远保持至少一个版本的应用正常运行,减少了处理多个并发版本带来的复杂性。蓝绿部署在副本数量很少时也能很好的工作。

图2:Kubernetes下的蓝绿部署
图2展示了“Deployer“如何编排部署。基于Apache License,并作为Amdatu umbrella project的一部分,我们开源了这个组件的实现,供大家参考使用。另外,这个组件带web UI,可以用来配置部署。
这种机制的一个要点是在重新配置负载均衡器之前,执行在pods上的运行状态检查。我们希望每部署的每一个组件都能提供状态检查。目前的做法通常是为每个组件添加一个通过HTTP访问的状态检查。
实现部署自动化
有了Deployer,我们就可以把部署集成到构建流程中了。我们的构建服务器可以在构建成功之后,将新的镜像推送到registry(如Git Hub),而后构建服务器可以调用新版本应用并自动部署至测试环境中。同一个镜像也可以通过触发生产环境中的Deployer被推送上生产。

图3:容器化自动部署流程
资源限制
使用Kubernetes时,搞清楚资源限制很重要。你可以在每个pod上配置资源请求和CPU/内存限制,也可以控制资源保证和bursting limits。
这些设置对于高效运行多个容器极为重要,防止容器因分配内存不足而意外停止。
建议尽早设置和测试资源限制。没有限制时,看起来运行良好,不代表把重要负载放到容器中不会出现问题。
Kubernetes监控
当我们快要搭建好Kubernetes时,我们意识到监控和日志在这个新的动态环境中非常重要。当我们面对大规模服务和节点时,进入服务器查看日志文件是不现实的,建一个中心化的日志和监控系统需要尽快提上议程。
日志
有很多用于日志记录的开源工具,我们使用的是Graylog和Apache Kafka(从容器收集摘录日志的消息传递系统)。容器将日志发送给Kafka,Kafka交给Graylog进行索引。我们让应用组件将日志打给Kafka,方便将日志流式化,成为易于索引的格式。也有一些工具可以从容器外收集日志,然后发送给日志系统。
监控
Kubernetes具备超强的故障恢复机制,Kubernetes会重启意外停止的pod。我们曾遇到过因内存泄露,导致容器在一天内宕机多次的情况,然而令人惊讶的是,甚至我们自己都没有察觉到。
Kubernetes在这一点上做得非常好,不过一旦问题出现,即使被及时处理了,我们还是想要知道。因此我们使用了一个自定义的运行状况检查仪表盘来监控Kubernetes节点和pod,以及包括数据存储在内的一些服务。可以说在监控方面,Kubernetes API再次证明了其价值所在。
检测负载、吞吐量、应用错误等状态也是同样重要的,有很多开源软件可以满足这一需求。我们的应用组件将指标发布到InfluxDB,并用Heapster去收集Kubernetes的指标。我们还通过Grafana(一款开源仪表盘工具)使存储在InfluxDB中的指标可视化。有很多InfluxDB/Grafana堆栈的替代方案,无论你才用哪一种,对于运行情况的跟踪和监控都是非常有价值的。
数据存储和Kubernetes
很多Kubernetes新用户都有一个问题:我该如何使用Kubernetes处理数据?
运行数据存储时(如MangoDB或MySQL),我们很可能会有持久化数据储存的需求。不过容器一但重启,所有数据都会丢失,这对于无状态组件没什么影响,但对持久化数据储存显然行不通。好在,Kubernetes具有Volume机制。
Volume可以通过多种方式备份,包括主机文件系统、EBS(AWS的Elastic Block Store)和nfs等。当我们研究持久数据问题是,这是一个很好的方案,但不是我们运行数据存储的答案。
副本问题
在大多数部署中,数据存储也是有副本的。Mongo通常在副本集中运行,而MySQL可以在主/副模式下运行。我们都知道数据储存集群中的每个节点应该备份在不同的volume中,写入相同volume会导致数据损坏。另外,大多数数据存储需要明确配置才能使集群启动并运行,自动发现和配置节点并不常见。
同时,运行着数据存储的机器通常会针对某项工作负载进行调整,例如更高的IOPS。扩展(添加/删除节点)对于数据存储来说,也是一个昂贵的操作,这些都和Kubernetes部署的动态本质不相符。
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前在阿里
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

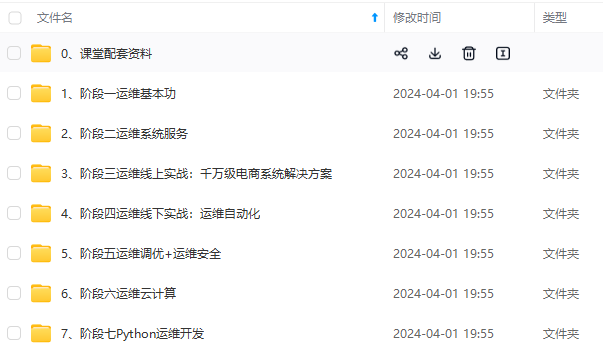

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**















 543
543











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









