







-
This class is a member of the
-
Java Collections Framework.
-
@author Josh Bloch
-
@see List
-
@see ArrayList
-
@since 1.2
-
@param the type of elements held in this collection
*/
public class LinkedList
extends AbstractSequentialList
implements List, Deque, Cloneable, java.io.Serializable
{
…
}
1.2 翻译
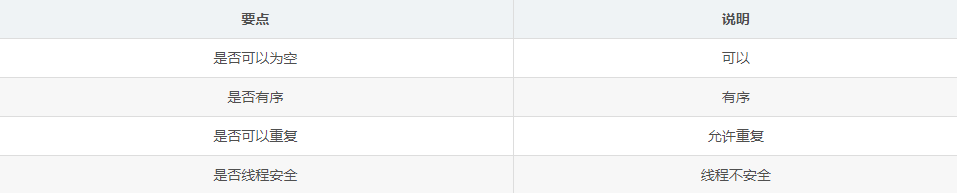
双向链表是实现了List和Deque接口。实现了所有List的操作和允许值为Null。
所有的操作执行都与双向链表相似。操作索引将遍历整个链表,至于是从头开始遍历还是从尾部开始遍历取决于索引的下标距离哪个比较近。
需要注意的是这个方法不是同步的方法,需要同步的应用(ConcurrentLinkedDeque高效的队列),如果多个线程同时操作LinkedList实例和至少有一个线程修改list的结构,必须在外部加同步操作。关于结构性操作可以看前面的HashMap的介绍。这个同步操作通常是压缩在某些对象头上面。(synchronized就是存储在对象头上面。)
如果对象头不存在这样的对象,这个列表应该使用{@link Collections#synchronizedList Collections.synchronizedList}工具来封装,这个操作最好是在创建List之前完成,防止非同步的操作。List list = Collections.synchronizedList(new ArrayList(…));但是一般不用这个方法,而是用JUC包下的ConcurrentLinkedDeque更加高效,(因为这个底层采用的是CAS操作)
快速失败机制(…好像在集合容器下面都有这个机制来抛出异常…)
当一个list被多个线程成同时修改的时候会抛出异常。但是不能用来保证线程安全。
所以在多线程环境下,还是要自己加锁或者采用JUC包下面的方法来保证线程安全, 而不能依靠fail-fast机制抛出异常,这个方法只是用来检测bug。
整个说明文档其实是跟ArrayList差不多,只不过是他们的底层实现的数据结构不一样而已,可以参考对比ArrayList。【【手撕源码系列】ArrayList源码解读—Java8版本】
1.3 一语中的
1.4 LinkedList和ArrayList的区别
顺序插入的速度ArrayList会快些,LinkedList的速度会稍慢一些。因为ArrarList只是在指定的位置上赋值即可,而LinkedList则需要创建Node对象,并且需要建立前后关联,如果对象较大的话,速度会慢一些。
LinkedList的占用的内存空间要大一些。
数组遍历的方式ArrayList推荐使用for循环,而LinkedList则推荐使用foreach,如果使用for循环,效率将会很慢。
一般我们这样认为:ArrarList查询和获取快,修改和删除慢;LinkedList修改和删除快,查询和获取慢。其实这样说不准确的。
LinkedList做插入、删除的时候,慢在寻址,快在只需要改变前后Entry的引用地址;
ArrayList做插入、删除的时候,慢在数组元素的批量copy,快在寻址。
所以,如果待插入、删除的元素是在数据结构的前半段尤其是非常靠前的位置的时候,LinkedList的效率将大大快过ArrayList,因为ArrayList将批量copy大量的元素;越往后,对于LinkedList来说,因为它是双向链表,所以在第2个元素后面插入一个数据和在倒数第2个元素后面插入一个元素在效率上基本没有差别,但是ArrayList由于要批量copy的元素越来越少,操作速度必然追上乃至超过LinkedList。
1.5 如何选择?
1、如果你十分确定你插入、删除的元素是在前半段,使用LinkedList
2、如果你十分确定你删除、删除的元素后半段,使用ArrayList
3、如果你上面的两点不确定,建议你使用LinkedList
说明:
其一、LinkedList整体插入、删除的执行效率比较稳定,没有ArrayList这种越往后越快的情况;
其二、插入元素的时候,弄得不好ArrayList就要进行一次扩容,而ArrayList底层数组扩容是一个既消耗时间又消耗空间的操作,所以综合来看就知道选择哪个类型的list
我们先来看看LinkedList的定义:
public class LinkedList
extends AbstractSequentialList
implements List, Deque, Cloneable, java.io.Serializable
LinkedList的类结构图:

如何查看类的完整结构图可以参考如下文章:
从图中,我们可以看出:
继承了AbstractSequentialList抽象类:在遍历LinkedList的时候,官方更推荐使用顺序访问,也就是使用我们的迭代器。(因为LinkedList底层是通过一个链表来实现的)(虽然LinkedList也提供了get(int index)方法,但是底层的实现是:每次调用get(int index)方法的时候,都需要从链表的头部或者尾部进行遍历,每一的遍历时间复杂度是O(index),而相对比ArrayList的底层实现,每次遍历的时间复杂度都是O(1)。所以不推荐通过get(int index)遍历LinkedList。至于上面的说从链表的头部后尾部进行遍历:官方源码对遍历进行了优化:通过判断索引index更靠近链表的头部还是尾部来选择遍历的方向)(所以这里遍历LinkedList推荐使用迭代器)。
实现了List接口。(提供List接口中所有方法的实现)
实现了Cloneable接口,它支持克隆(浅克隆),底层实现:LinkedList节点并没有被克隆,只是通过Object的clone()方法得到的Object对象强制转化为了LinkedList,然后把它内部的实例域都置空,然后把被拷贝的LinkedList节点中的每一个值都拷贝到clone中。(后面有源码解析)
实现了Deque接口。实现了Deque所有的可选的操作。
实现了Serializable接口。表明它支持序列化。(和ArrayList一样,底层都提供了两个方法:readObject(ObjectInputStreamo)、writeObject(ObjectOutputStream o),用于实现序列化,底层只序列化节点的个数和节点的值)。

如图所示,LinkedList底层通过数链表实现。
// LinkedList节点个数
transient int size = 0;
/**
-
Pointer to first node. 指向头结点
-
Invariant: (first == null && last == null) ||
-
(first.prev == null && first.item != null)
*/
transient Node first;
/**
-
Pointer to last node. 指向尾节点
-
Invariant: (first == null && last == null) ||
-
(last.next == null && last.item != null)
*/
transient Node last;
LinkedList内部有两个引用,一个first,一个last,分别用于指向链表的头和尾,另外有一个size,用于标识这个链表的长度,而它的接的引用类型是Node,这是他的一个内部类:
private static class Node {
E item;
Node next;
Node prev;
Node(Node prev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
Node 类是LinkedList中的私有内部类,LinkedList中就是通过Node来存储集合中的元素。
E :节点的值。
Node next:当前节点的后一个节点的引用(可以理解为指向当前节点的后一个节点的指针)
Node prev:当前节点的前一个节点的引用(可以理解为指向当前节点的前一个节点的指针)
LinkedList提供了两个构造器,ArrayList比它多提供了一个通过设置初始化容量来初始化类。
LinkedList不提供该方法的原因:因为LinkedList底层是通过链表实现的,每当有新元素添加进来的时候,都是通过链接新的节点实现的,也就是说它的容量是随着元素的个数的变化而动态变化的。而ArrayList底层是通过数组来存储新添加的元素的,所以我们可以为ArrayList设置初始容量(实际设置的数组的大小)。
5.1 空参构造函数
/**
- Constructs an empty list.
*/
public LinkedList() {
}
5.2 collection参数构造函数
public LinkedList(Collection<? extends E> c) {
this();
// 将集合添加到链表中去
addAll©;
}
public boolean addAll(Collection<? extends E> c) {
// 从链表尾巴开始集合中元素
return addAll(size, c);
}
public boolean addAll(int index, Collection<? extends E> c) {
// 1.添加位置的下标的合理性检查
checkPositionIndex(index);
// 2.将集合转换为Object[]数组对象
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
// 3.得到插入位置的前继节点和后继节点
Node pred, succ;
if (index == size) {
// 从尾部添加的情况:前继节点是原来的last节点;后继节点是null
succ = null;
pred = last;
} else {
// 从指定位置(非尾部)添加的情况:前继节点就是index位置的节点,后继节点是index位置的节点的前一个节点
succ = node(index);
pred = succ.prev;
}
// 4.遍历数据,将数据插入
for (Object o : a) {
@SuppressWarnings(“unchecked”) E e = (E) o;
// 创建节点
Node newNode = new Node<>(pred, e, null);
if (pred == null)
// 空链表插入情况:
first = newNode;
else
// 非空链表插入情况:
pred.next = newNode;
// 更新前置节点为最新插入的节点(的地址)
pred = newNode;
}
if (succ == null) {
// 如果是从尾部开始插入的,则把last置为最后一个插入的元素
last = pred;
} else {
// 如果不是从尾部插入的,则把尾部的数据和之前的节点连起来
pred.next = succ;
succ.prev = pred;
}
size += numNew; // 链表大小+num
modCount++; // 修改次数加1
return true;
}
6.1 List接口
6.1.1 add(E e)方法
// 作用:将元素添加到链表尾部
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node l = last; // 获取尾部元素
final Node newNode = new Node<>(l, e, null); // 以尾部元素为前继节点创建一个新节点
last = newNode; // 更新尾部节点为需要插入的节点
if (l == null)
// 如果空链表的情况:同时更新first节点也为需要插入的节点。(也就是说:该节点既是头节点first也是尾节点last)
first = newNode;
else
// 不是空链表的情况:将原来的尾部节点(现在是倒数第二个节点)的next指向需要插入的节点
l.next = newNode;
size++; // 更新链表大小和修改次数,插入完毕
modCount++;
}
6.1.2 add(int index, E element)方法
// 作用:在指定位置添加元素
public void add(int index, E element) {
// 检查插入位置的索引的合理性
checkPositionIndex(index);
if (index == size)
// 插入的情况是尾部插入的情况:调用linkLast()解释如上。
linkLast(element);
else
// 插入的情况是非尾部插入的情况(中间插入):linkBefore()见下面。
linkBefore(element, node(index));
}
private void checkPositionIndex(int index) {
if (!isPositionIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
private boolean isPositionIndex(int index) {
return index >= 0 && index <= size;
}
void linkBefore(E e, Node succ) {
// assert succ != null;
final Node pred = succ.prev; // 得到插入位置元素的前继节点
final Node newNode = new Node<>(pred, e, succ); // 创建新节点,其前继节点是succ的前节点,后接点是succ节点
succ.prev = newNode; // 更新插入位置(succ)的前置节点为新节点
if (pred == null)
// 如果pred为null,说明该节点插入在头节点之前,要重置first头节点
first = newNode;
else
// 如果pred不为null,那么直接将pred的后继指针指向newNode即可
pred.next = newNode;
size++;
modCount++;
}
6.1.3 get(int index)方法
public E get(int index) {
// 元素下表的合理性检查
checkElementIndex(index);
// node(index)真正查询匹配元素并返回
return node(index).item;
}
// 作用:查询指定位置元素并返回
Node node(int index) {
// assert isElementIndex(index);
// 如果索引位置靠链表前半部分,从头开始遍历
if (index < (size >> 1)) {
Node x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
// 如果索引位置靠链表后半部分,从尾开始遍历
Node x = last;
for (int i = size - 1; i > index; i–)
x = x.prev;
return x;
}
6.1.4 remove(int index)方法
// 作用:移除指定位置的元素
public E remove(int index) {
// 移除元素索引的合理性检查
checkElementIndex(index);
// 将节点删除
return unlink(node(index));
}
E unlink(Node x) {
// assert x != null;
final E element = x.item; // 得到指定节点的值
final Node next = x.next; // 得到指定节点的后继节点
final Node prev = x.prev; // 得到指定节点的前继节点
// 如果prev为null表示删除是头节点,否则就不是头节点
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null; // 置空需删除的指定节点的前置节点(null)
}
// 如果next为null,则表示删除的是尾部节点,否则就不是尾部节点
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null; // 置空需删除的指定节点的后置节点
}
// 置空需删除的指定节点的值
x.item = null;
size–; // 数量减1
modCount++;
return element;
}
6.1.5 clear()方法
// 清空链表
public void clear() {
// Clearing all of the links between nodes is “unnecessary”, but:
// - helps a generational GC if the discarded nodes inhabit
// more than one generation
// - is sure to free memory even if there is a reachable Iterator
// 进行for循环,进行逐条置空;直到最后一个元素
for (Node x = first; x != null; ) {
Node next = x.next;
x.item = null;
x.next = null;
x.prev = null;
x = next;
}
// 置空头和尾为null
first = last = null;
size = 0;
modCount++;
}
6.1.6 indexOf(Object o)
// 返回元素在链表中的索引,如果不存在则返回-1
public int indexOf(Object o) {
int index = 0;
// 如果元素为null,进行如下循环判断
if (o == null) {
for (Node x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
// 元素不为null.进行如下循环判断
for (Node x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}
6.2 Duque接口
6.2.1 addFirst(E e)方法
// 作用:在链表头插入指定元素
public void addFirst(E e) {
linkFirst(e);
}
private void linkFirst(E e) {
final Node f = first; // 获取头部元素
final Node newNode = new Node<>(null, e, f); // 创建新的头部元素(原来的头部元素变成了第二个)
first = newNode;
// 链表头部为空,(也就是链表为空)
if (f == null)
last = newNode; // 头尾元素都是e
else
f.prev = newNode; // 否则就更新原来的头元素的prev为新元素的地址引用
size++;
modCount++;
}
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

最后
本人也收藏了一份Java面试核心知识点来应付面试,借着这次机会可以送给我的读者朋友们:
目录:

Java面试核心知识点
一共有30个专题,足够读者朋友们应付面试啦,也节省朋友们去到处搜刮资料自己整理的时间!

Java面试核心知识点
《一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码》,点击传送门即可获取!
,也去过华为、OPPO等大厂,18年进入阿里一直到现在。**
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。[外链图片转存中…(img-ZUlwKvxU-1711790458000)]
[外链图片转存中…(img-RCiMVzPu-1711790458001)]
[外链图片转存中…(img-gNOTIHPe-1711790458001)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)
最后
本人也收藏了一份Java面试核心知识点来应付面试,借着这次机会可以送给我的读者朋友们:
目录:
[外链图片转存中…(img-0vvBSzqY-1711790458002)]
Java面试核心知识点
一共有30个专题,足够读者朋友们应付面试啦,也节省朋友们去到处搜刮资料自己整理的时间!
[外链图片转存中…(img-pXomUFi9-1711790458002)]
Java面试核心知识点
《一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码》,点击传送门即可获取!















 488
488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









