







总结一下 平衡二叉树的优点
-
a 不错的查找性能(O(logn)), 不存在极端的低效查找的情况。
-
b 可以实现范围查找、数据排序。
看起来 AVL 树作为数据查找的数据结构确实很不错,但是 AVL 树并不适合做 Mysql 数据库的索引数据结构,因为考虑一下这个问题:
数据库查询数据的瓶颈在于磁盘 IO,如果使用的是 AVL 树,我们每一个树节点只存储了一个数据,我们一次磁盘 IO 只能取出来一个节点上的数据加载到内存里,那比如查询 id=8 这个数据我们就要进行磁盘 IO 三次,这是多么消耗时间的。所以我们设计数据库索引时需要首先考虑怎么尽可能减少磁盘 IO 的次数。
磁盘 IO 有个有个特点,就是从磁盘读取 1B 数据和 1KB 数据所消耗的时间是基本一样的,我们就可以根据这个思路,我们可以在一个树节点上尽可能多地存储数据,一次磁盘 IO 就多加载点数据到内存,这就是 B 树,B+树的的设计原理了。
B-树
===
B树的特点:
-
所有健值分布在整棵树中
-
搜索有可能在非叶子节点结束
-
根节点至少有2个子树
-
所有叶子节点都在同一层
-
分叉数(路数)永远比关键字数多 1
-
节点存储key和value
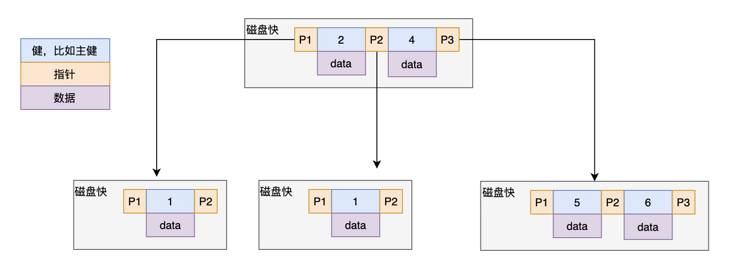
演示 B树索引分裂合并
===========
比如 Max Degree(路数)是 3 的时候,我们插入数据 1、2、3,在插入 3 的时候, 本来应该在第一个磁盘块,但是如果一个节点有三个关键字的时候,意味着有 4 个指针, 子节点会变成 4 路,所以这个时候必须进行分裂。把中间的数据 2 提上去,把 1 和 3 变 成 2 的子节点。
如果删除节点,会有相反的合并的操作。 注意这里是分裂和合并,跟 AVL 树的左旋和右旋是不一样的。 我们继续插入 4 和 5,B Tree 又会出现分裂和合并的操作。
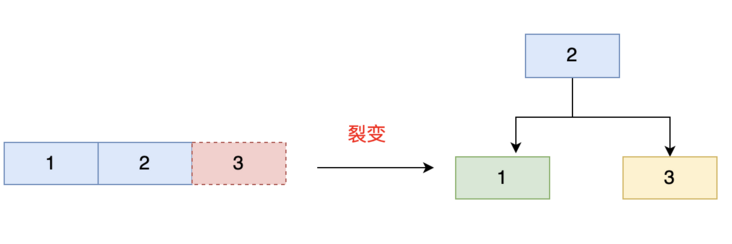
从这个里面我们也能看到,在更新索引的时候会有大量的索引的结构的调整,节点的分裂和合并,其实就是 InnoDB 页的分裂和合并。
B+树
===
B+树是在B树上做的一个优化工作
-
B+树每个节点可以包含更多的节点内容,为什么这么做呢?第一:降低树的高度 第二:将数据范围变为多个区间,区间越多 检索速度就越快
-
非叶子节点存的是key, 叶子节点存的是key和数据
-
叶子节点指针相连,顺序查找速度更快
B 树和 B+树有什么不同呢?
===============
第一,B 树一个节点里存的是key和数据,而 B+树存储的是索引(地址),所以 B 树里一个节点存不了很多个数据,但是 B+树一个节点能存很多索引,B+树叶子节点存所有的数据。
第二,B+树的叶子节点是数据阶段用了一个链表串联起来,便于范围查找。
通过 B 树和 B+树的对比我们看出,B+树节点存储的是索引,在单个节点存储容量有限的情况下,单节点也能存储大量索引,使得整个 B+树高度降低,减少了磁盘 IO。其次,B+树的叶子节点是真正数据存储的地方,叶子节点用了链表连接起来,这个链表本身就是有序的,在数据范围查找时,更具备效率。因此 Mysql 的索引用的就是 B+树,B+树在查找效率、范围查找中都有着非常不错的性能。
综上所述mysql innodb 索引选择了B+树。
思考问题
====
1、B+树叶子节点存的诗所有数据,如果1000万数据,那这个链表太大 ,不会影响性能吗?
可以利用数据页,下面有重点分析
2、InnoDB一棵B+树可以存放多少行数据?
B+Tree 的根节点和枝节点中都不会存储数据,只有叶子节点才存储数据。搜索 到关键字不会直接返回,会到最后一层的叶子节点。比如我们搜索 id=3,虽然在第一 层直接命中了,但是全部的数据在叶子节点上面,所以我还要继续往下搜索,一直到叶 子节点。
举个例子:假设一条记录是 1K,一个叶子节点(一页)可以存储 16 条记录。非叶 子节点可以存储多少个指针?
假设索引字段是 bigint 类型,长度为 8 字节。指针大小在 InnoDB 源码中设置为 6 字节,这样一共 14 字节。非叶子节点(一页)可以存储 1024*16 / 14 = 1170 个这样的 单元(键值+指针),代表有 1170 个指针。
树深度为 2 的时候, 有 1170^2 个叶子节点 ,可以存储的数据为:
1170 * 1170 * 16 = 21902400 2000万
在查找数据时一次页的查找代表一次 IO,也就是说,一张 2000 万左右的表,查询数据最多需要访问 3 次磁盘。 所以在 InnoDB 中 B+ 树深度一般为 1-3 层,它就能满足千万级的数据存储。
二、innodb的索引分析
=============
在 InnoDB 中,表都是根据主键顺序以索引的形式存放的,这种存储方式的表称为索引组织表。
上述中我们从不同维度分析了最终InnoDB 使用了 B+ 树索引模型,所以数据都是存储在 B+ 树中的。
每一个索引在 InnoDB 里面对应一棵 B+ 树。假设,我们有一个主键列为 ID 的表,表中有字段 k,并且在 k 上有普通索引。
这个表的建表语句是:
create table user(
id int primary key,
k int not null,
name varchar(16),
index (k))engine=InnoDB;
表中 第一行到第五行 的 (ID,k) 值分别为 (100,1)、(200,2)、(300,3)、(500,5) 和 (600,6),两棵树的示例示意图如下。
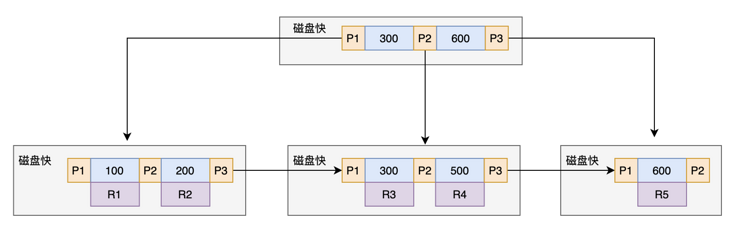
上图为:主健索引
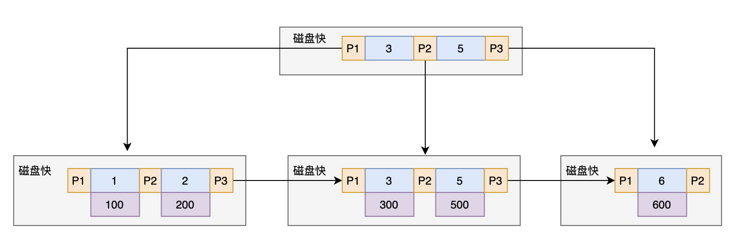
上图为:普通索引
根据上面的索引结构说明,我们来讨论一个问题:基于主键索引和普通索引的查询有什么区别?
如果语句是 select * from T where ID=500,即主键查询方式,则只需要搜索 ID 这棵 B+ 树;
如果语句是 select * from T where k=5,即普通索引查询方式,则需要先搜索 k 索引树,得到 ID 的值为 500,再到 ID 索引树搜索一次。这个过程称为回表。也就是说,基于非主键索引的查询需要多扫描一棵索引树。因此,我们在应用中应该尽量使用主键查询。
B+ 树为了维护索引有序性,在插入新值的时候需要做必要的维护。以上面这个图为例,如果插入新的行 ID 值为 700,则只需要在 R5 的记录后面插入一个新记录。如图

如果新插入的 ID 值为 400,就相对麻烦了,需要逻辑上挪动后面的数据,空出位置,如图。
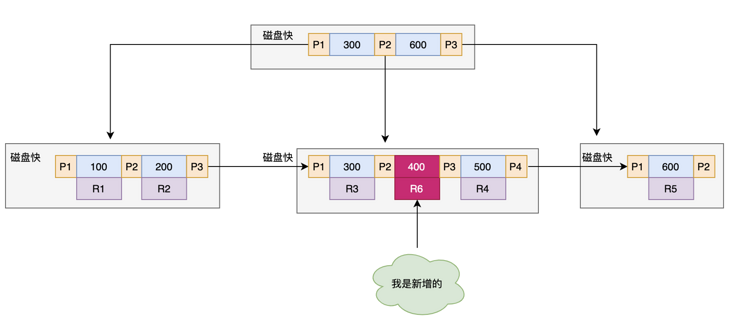
而更糟的情况是,如果 R5 所在的数据页已经满了,根据 B+ 树的算法,这时候需要申请一个新的数据页,然后挪动部分数据过去。这个过程称为页分裂。在这种情况下,性能自然会受影响。
除了性能外,页分裂操作还影响数据页的利用率。原本放在一个页的数据,现在分到两个页中,整体空间利用率降低大约 50%。当然有分裂就有合并。
当相邻两个页由于删除了数据,利用率很低之后,会将数据页做合并。合并的过程,可以认为是分裂过程的逆过程。
三、innodb 数据页
============
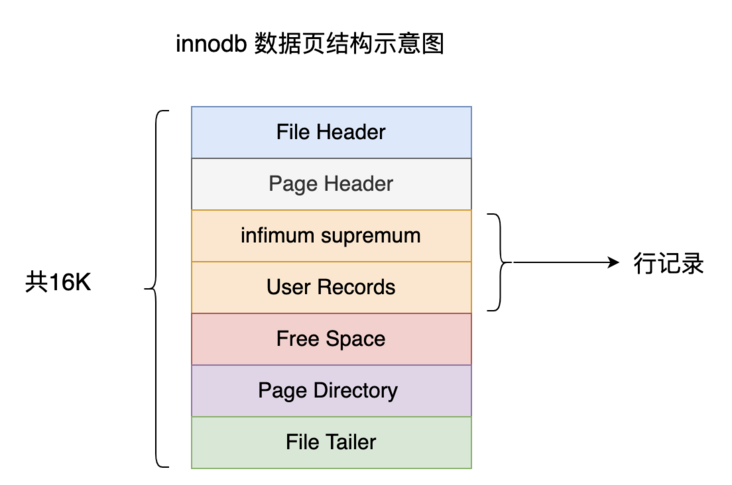
在上述中我们提到数据页,数据页的概念,它是MySQL管理存储空间的基本单位,一个页的大小一般是16KB,并且我们知道了记录其实是被存放在页中的,如果记录占用的空间太大还可能造成行溢出现象,这会导致一条记录被分散存储在多个页中。
页的本质就是一块16KB大小的存储空间,InnoDB为了不同的目的而把页分为不同的类型,其中用于存放记录的页也称为数据页,我们先看看这个用于存放记录的页长什么样。数据页代表的这块16KB大小的存储空间可以被划分为多个部分,不同部分有不同的功能,各个部分如图所示:
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

读者福利
分享一份自己整理好的Java面试手册,还有一些面试题pdf
不要停下自己学习的脚步


《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
“zoom: 33%;” />
读者福利
分享一份自己整理好的Java面试手册,还有一些面试题pdf
不要停下自己学习的脚步
[外链图片转存中…(img-RbfoBxzh-1713644894038)]
[外链图片转存中…(img-JpSGFhec-1713644894038)]
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!















 468
468











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









