







具体限流需要限制在多少
上面只是讲了怎么将分区副本设置为需要限流, 但是并没有设置限流多少鸭!就算上面你设置了,这里没有设置限流多少,那么默认的限流值就是 Long.MAXVALUE 约等于没有限流。
那么如何设置限流的流速呢?
请看下面代码, 这个是 在修改了Broker的动态配置之后就会调用的方法, 关于动态配置可以看我之前的文章 [Kafka中的动态配置源码分析
]( )
BrokerConfigHandler#processConfigChanges
class BrokerConfigHandler(private val brokerConfig: KafkaConfig,
private val quotaManagers: QuotaManagers) extends ConfigHandler with Logging {
def processConfigChanges(brokerId: String, properties: Properties): Unit = {
def getOrDefault(prop: String): Long = {
if (properties.containsKey(prop))
properties.getProperty(prop).toLong
else
DefaultReplicationThrottledRate
}
if (brokerId == ConfigEntityName.Default)
brokerConfig.dynamicConfig.updateDefaultConfig(properties)
else if (brokerConfig.brokerId == brokerId.trim.toInt) {
brokerConfig.dynamicConfig.updateBrokerConfig(brokerConfig.brokerId, properties)
quotaManagers.leader.updateQuota(upperBound(getOrDefault(LeaderReplicationThrottledRateProp)))
quotaManagers.follower.updateQuota(upperBound(getOrDefault(FollowerReplicationThrottledRateProp)))
quotaManagers.alterLogDirs.updateQuota(upperBound(getOrDefault(ReplicaAlterLogDirsIoMaxBytesPerSecondProp)))
}
}
}
=================================================================================
副本不在ISR中&&副本在限流副本列表中&&超出了限流阈值
private def shouldFollowerThrottle(quota: ReplicaQuota, fetchState: PartitionFetchState, topicPartition: TopicPartition): Boolean = {
!fetchState.isReplicaInSync && quota.isThrottled(topicPartition) && quota.isQuotaExceeded
}
判断的时机在 副本发起 Fetch请求的时候。
遍历所有分区, 构造Fetch请求。如果被限流了,则会被过滤。这一次不会请求对应分区副本的数据。
partitionMap.foreach { case (topicPartition, fetchState) =>
// We will not include a replica in the fetch request if it should be throttled.
if (fetchState.isReadyForFetch && !shouldFollowerThrottle(quota, fetchState, topicPartition)) {
}
}
===============================================================================
分区副本必须在ISR中&&分区副本在限流副本列表中 && 超过了限流阈值
def shouldLeaderThrottle(quota: ReplicaQuota, topicPartition: TopicPartition, replicaId: Int): Boolean = {
val isReplicaInSync = nonOfflinePartition(topicPartition).exists(_.inSyncReplicaIds.contains(replicaId))
!isReplicaInSync && quota.isThrottled(topicPartition) && quota.isQuotaExceeded
}
调用时机
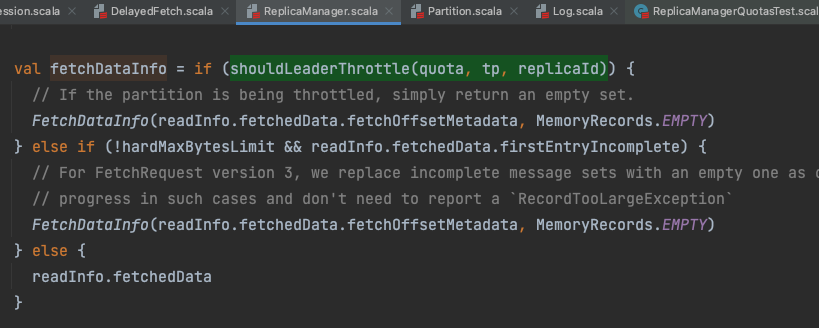
在读取副本本地Log数据的时候, ReplicaManager#readFromLocalLog , 读取完了然后判断这个分区副本是否已经被限流了,如果被限流了则返回的数据为Empty。
虽然上面设置了哪些分区需要被限流,但是没有设置具体限流多少,就算上面设置了,如果没有设置限流值那么默认的限流值就是Long.MaxValue, 也就是相当于不限流。
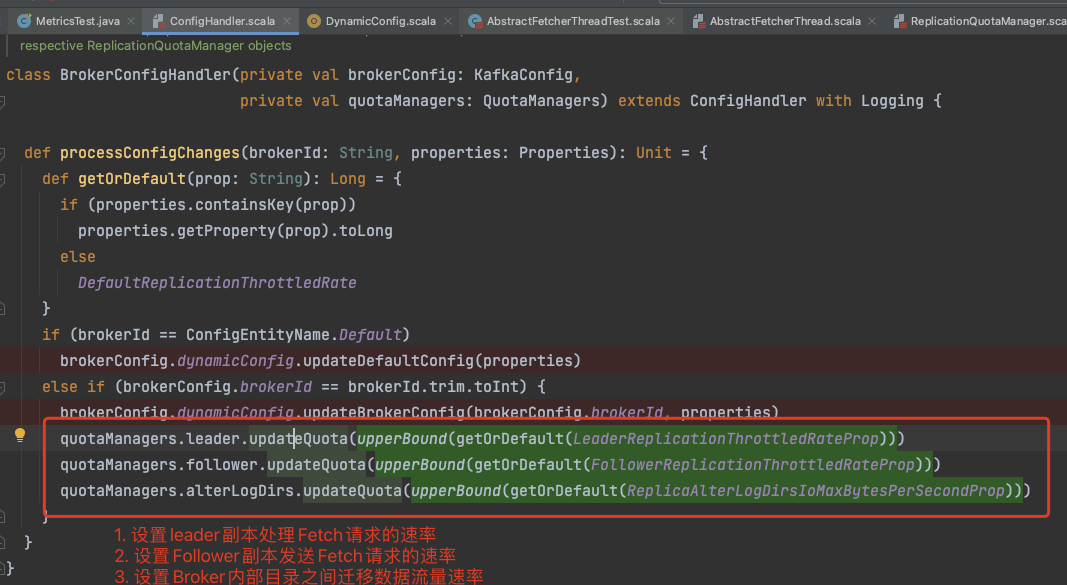
上面设置了3个跟限流相关的配置
leader.replication.throttled.rate Leader副本的限流阈值
follower.replication.throttled.rate Follower副本的限流阈值
replica.alter.log.dirs.io.max.bytes.per.second 同一个Broker多个目录直接的副本同步限流阈值
可以看到上面得到的阈值分别被保存在对象 Quota中.
Quota: 限流对象, 他可以设置是 上限 还是 下限 , 并保存着流量阈值
特别需要注意的是: 只要跟当前这台BrokerId相关的才会被加载
/是否是上限/
private final boolean upper;
/绑定的阈值/
private final double bound;
判断是否超过阈值
/**传入的值 是否超过阈值 **/
public boolean acceptable(double value) {
return (upper && value <= bound) || (!upper && value >= bound);
}
======================================================================
想要限流,则需要计算准备的值 才能做好限流
如何计算准备的值,我在 Kafka中的数据采集和统计机制 里面已经说的非常清楚了, 所以这里我们看看 记录数据的地方在哪里
这里是所有需要被限流的副本的列表的所有流量数据, 统计在一起的。对应的配置
follower.replication.throttled.replicas
ReplicaFetcherThread#processPartitionData
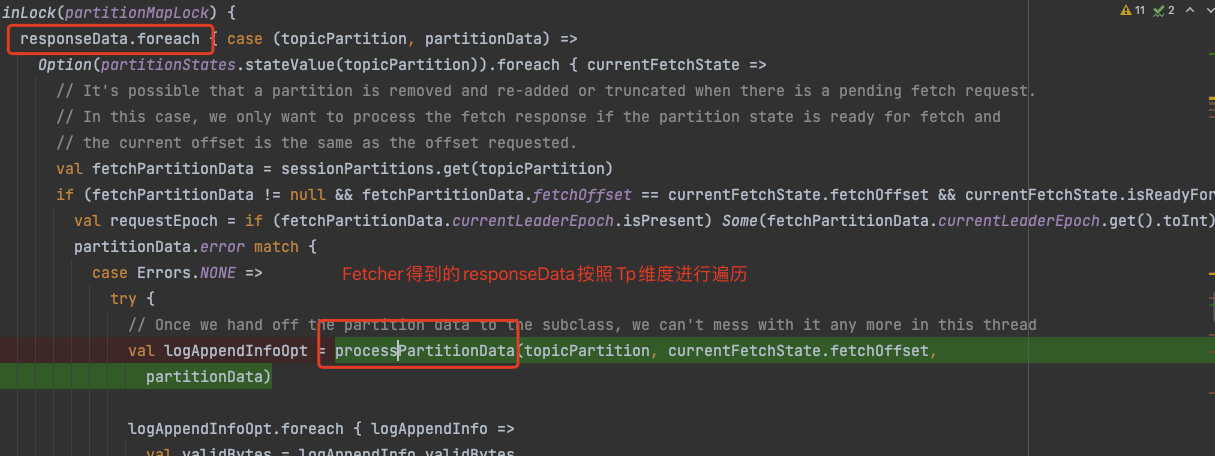

具体的记录的地方是, ReplicalFetcherThread 线程在Fetch数据之后进行处理的时候,进行记录
当然这里会先判断是否需要限流, 如果不需要限流那么记录也没有意义.
这记录的也是 需要被限流的所有副本的所有流量。对应的配置是
leader.replication.throttled.replicas
KafkaApis#processResponseCallback
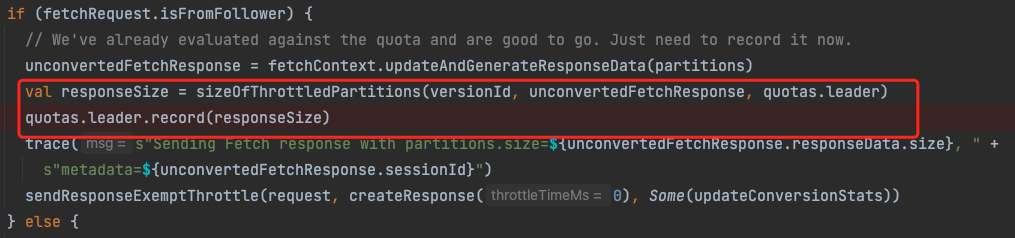
-
统计所有需要被限流的副本的总数据大小(将不需要限流的副本过滤掉了)
-
记录总数据大小
调用时机, 上面这个方法是一个 回调函数, 在读取本地副本数据完成的时候就会调用这个数据, 然后记录。
ReplicaAlterLogDirsThread#processPartitionData
// process fetched data
override def processPartitionData(topicPartition: TopicPartition,
fetchOffset: Long,
partitionData: PartitionData[Records]): Option[LogAppendInfo] = {
//— 省略-----
quota.record(records.sizeInBytes)
println(new SimpleDateFormat(“yyyy-MM-dd-HH:mm:ss”).format(new Date())+"LogDir 记录Follower Fetch 流量 size: "+ records.sizeInBytes())
logAppendInfo
}
======================================================================
Topic1 单分区 2 副本
{“version”:2,“partitions”:{“0”:[0,1]},“adding_replicas”:{},“removing_replicas”:{}}
-
把Follower副本先停机 , Follower副本在 Broker-1 上, 我们停机避免一会他会同步数据
-
给Topic1 发送100M的数据
sh bin/kafka-producer-perf-test.sh --topic Topic1 --num-records 1024 --throughput 100000 --producer-props bootstrap.servers=xxxx:9090 --record-size 102400

- 设置Leader端的限流值为1M/s ; 0号分区 Leader 在Broker-0 上,则最终的配置应该是
leader.replication.throttled.replicas: 0:0
leader.replication.throttled.rate: 524288 (512kb)
给Topic的分区添加到 限流副本列表中
sh bin/kafka-configs.sh --bootstrap-server xxxx:9092 --alter --entity-type topics --entity-name Topic1 --add-config leader.replication.throttled.replicas=0:0
下面是Broker设置动态配置, 因为我们是要在Broker-2 上面做限流, 所以这里的 entity-name 设置为 2
sh bin/kafka-configs.sh --bootstrap-server xxxx:9092 --alter --entity-type brokers --entity-name 2 --add-config leader.replication.throttled.rate=524288
- 启动Broker-1 , 让它自动拉取Leader的数据, 看看多久同步完成, 预计应该是200s左右
测试结果:
先说是否符合预期: 符合
我们先看看整个同步过程
本次最大Fetch数据大小:1048576
20211119162219 TP=Topic1-0 isReplicaInSync=false isThrottled=true isQuotaExceeded = false
本次最大Fetch数据大小:1048576
20211119162219 TP=Topic1-0 isReplicaInSync=false isThrottled=true isQuotaExceeded = true
20211119162219 这次Fetch获取的需要限流的数据大小为:18
本次最大Fetch数据大小:1048576
20211119162220 TP=Topic1-0 isReplicaInSync=false isThrottled=true isQuotaExceeded = true
20211119162220 这次Fetch获取的需要限流的数据大小为:18
本次最大Fetch数据大小:1048576
20211119162220 TP=Topic1-0 isReplicaInSync=false isThrottled=true isQuotaExceeded = true
20211119162220 这次Fetch获取的需要限流的数据大小为:18
本次最大Fetch数据大小:1048576
20211119162221 TP=Topic1-0 isReplicaInSync=false isThrottled=true isQuotaExceeded = false
20211119162221 这次Fetch获取的需要限流的数据大小为:1048648
… 省略…
完成的时候
20211119162528 TP=Topic1-0 isReplicaInSync=false isThrottled=true isQuotaExceeded = false
20211119162528 这次Fetch获取的需要限流的数据大小为:409960
本次最大Fetch数据大小:1048576
20211119162528 TP=Topic1-0 isReplicaInSync=false isThrottled=true isQuotaExceeded = true
[2021-11-19 16:25:28,220][INFO][kafka-dp-request-handler-5]: [Partition Topic1-0 broker=0] Expanding ISR from 0 to 0,1
[2021-11-19 16:25:28,264][INFO][kafka-dp-request-handler-5]: [Partition Topic1-0 broker=0] ISR updated to [0,1] and zkVersion updated to [6]
本次最大Fetch数据大小:1048576
20211119162528 TP=Topic1-0 isReplicaInSync=true isThrottled=true isQuotaExceeded = true
20211119162528 这次Fetch获取的需要限流的数据大小为:18
上面是同步过程我加的一些日志, 我们来分析一下
-
启动Broker-1的时候开始第一次同步, 这个时候 Leader去读取本地Log日志文件,第一次读取肯定不会被限流,但是一次读取多少数据是根据 Fetch请求还有一个
fetch.max.bytes配置来确定,比如我们这里一次最大Fetch的数据是1048576b (1M), 我们限流是阈值是512kb, 完事之后就会被采集到限流的SampleStat中 -
第二次Fetch请求过来的时候,去获取数据才发现超出限流阈值了, 那么这个时候就不读取数据了,但是可以看到还是有
18b的数据,平时没有数据同步的时候这个18b都是固定的。是一些元数据的大小。可忽略 -
经过时间的流逝,流量计算出来就变低了(可以看我之前写的数据采集和统计),那么又可以开始处理下一个Fetch请求了, 当然还是尽量一次读到最多的数据返回。
-
等到最后同步成功,赶上了ISR了, 就不会再限流了。当然你也可以看到最后一次获取的数据大小
1048576,之所以不是最大的1048648, 因为Log已经没有那么多数据了。
本次最大Fetch数据大小:1048576
20211119162219 TP=Topic1-0 isReplicaInSync=false isThrottled=true isQuotaExceeded = false
20211119162219 这次Fetch获取的需要限流的数据大小为:1048648
从开始到结束 :2021-11-19-16:25:28 - 2021-11-19-16:22:19 = 3分钟左右 约等于 200s
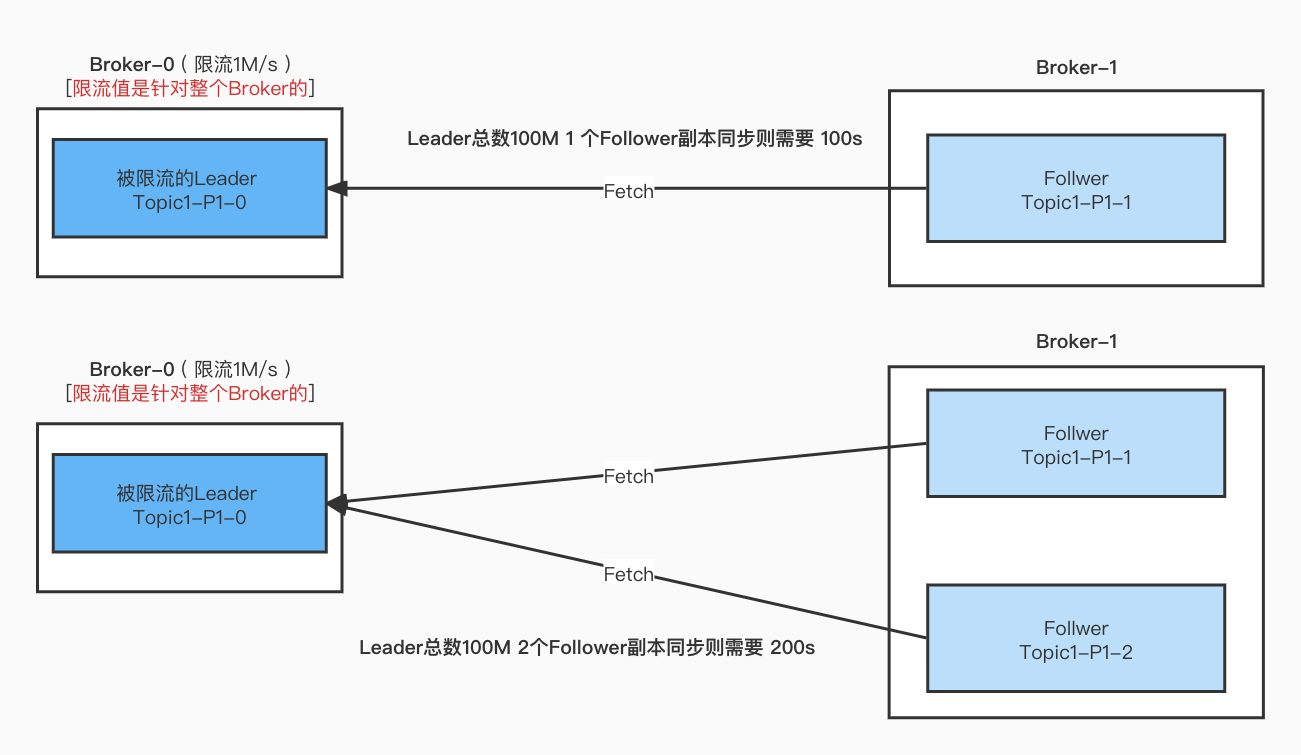
Topic1 单分区 3 副本
为了测试 多个副本同时同步会不会造成更久的同步时间, 我们在上面的基础上,再加一个副本, 也就是同时有两个Follower副本 去跟Leader副本同步数据
那么 是同步完成时间跟上面差不多呢? 还是会用double的时间呢?
按照上面的测试方法同步再测试一次发现 最终的结果是
2021-11-19-17:23:09 - 2021-11-19-17:16:46 = 6分钟左右 基本上就是 上面的一倍左右。
结论: 如果有多个副本进行同步的话,会同步占用Leader的限流阈值。
-
Leader端的限流只会计算需要被限流的分区流量值。
-
如果多个副本向Leader端Fetch数据,那么都会被算进限流阈值, 基本上多一个副本就多一倍的时间。
如下图所示
如果有多个Leader分区都限流呢?
按照最终有多少个副本在Fetch数据.
经过理论上的值和
测试结果 2021-11-19-19:01:49 - 2021-11-19 18: 55: 27 = 6分钟左右 相符
对应的配置有
follower.replication.throttled.replicas:Follower分区副本的限流配置
follower.replication.throttled.rateFollower分区副本限流阈值 b/s
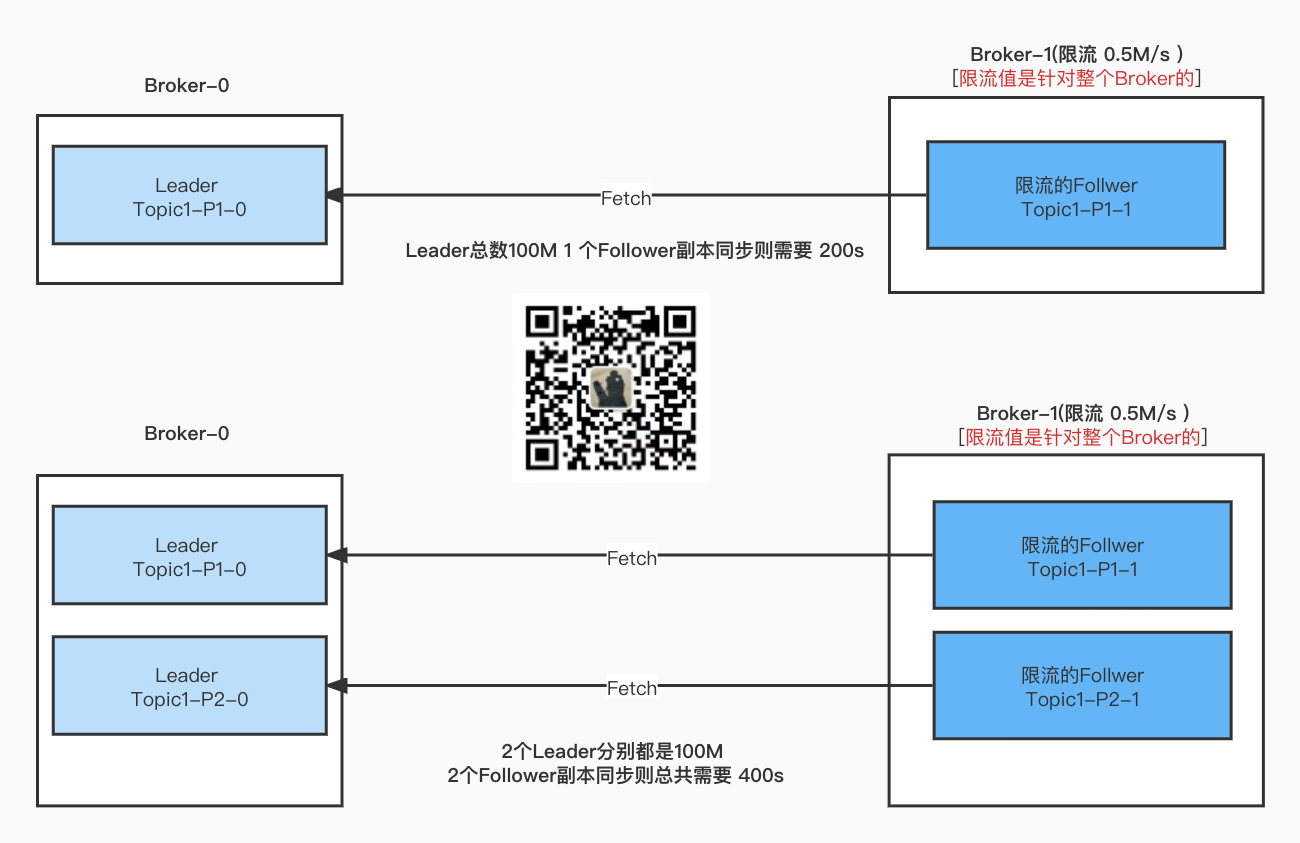
Topic1 单分区 2副本
测试 一个Follower Fetch Leader的数据的限流情况
限流阈值设置为
524288(512kb/s)
当前Topic1 的分配情况如下
{“version”:2,“partitions”:{“0”:[1,0]},“adding_replicas”:{},“removing_replicas”:{}}
设置Follower 限流的话,因为 Follower 在Broker-0 上。则配置如下,
把Topic1 的0号分区 设置为 在Broker-0 上进行 Fetch 限流
sh bin/kafka-configs.sh --bootstrap-server xxx:9090 --alter --entity-type topics --entity-name Topic1 --add-config follower.replication.throttled.replicas=0:0
设置Broker-0 这台机器上的 Follower Fetch 限流阈值
sh bin/kafka-configs.sh --bootstrap-server xxxx:9090 --alter --entity-type brokers --entity-name 0 --add-config follower.replication.throttled.rate=524288
当然测试方法还是跟之前一样, 先把Follower副本下线, 再给Topic1生产100M的数据, 代码里面加点日志观察Fetch情况
启动Follower副本开始进行同步, 部分Log日志如下
[2021-11-22 12:25:59,246][INFO][kafka-dp-request-handler-7]: [ReplicaFetcherManager on broker 0] Added fetcher to broker 1 for partitions Map(Topic1-0 -> (offset=5120, leaderEpoch=9))
2021-11-22-12:25:59 TP:Topic1-0 是否可Fetch=false isReadyForFetch=false Follower是否限流=false !isReplicaInSync=true quota.isThrottled=true quota.isQuotaExceeded=false
[2021-11-22 12:26:00,274][INFO][ReplicaFetcherThread-0-1]: [Log partition=Topic1-0, dir=/Users/shirenchuang/work/IdeaPj/didi_source/kafka/kafka-logs-0] Truncating to 5120 has no effect as the largest offset in the log is 5119
2021-11-22-12:26:00 TP:Topic1-0 是否可Fetch=true isReadyForFetch=true Follower是否限流=false !isReplicaInSync=true quota.isThrottled=true quota.isQuotaExceeded=false
2021-11-22-12:26:00记录Follower Fetch 流量 size: 1048576
2021-11-22-12:26:00 TP:Topic1-0 是否可Fetch=false isReadyForFetch=true Follower是否限流=true !isReplicaInSync=true quota.isThrottled=true quota.isQuotaExceeded=true
2021-11-22-12:26:00 TP:Topic1-0 是否可Fetch=false isReadyForFetch=true Follower是否限流=true !isReplicaInSync=true quota.isThrottled=true quota.isQuotaExceeded=true
2021-11-22-12:26:01 TP:Topic1-0 是否可Fetch=true isReadyForFetch=true Follower是否限流=false !isReplicaInSync=true quota.isThrottled=true quota.isQuotaExceeded=false
2021-11-22-12:26:01记录Follower Fetch 流量 size: 1048576
2021-11-22-12:26:01 TP:Topic1-0 是否可Fetch=false isReadyForFetch=true Follower是否限流=true !isReplicaInSync=true
---- 省略部分-------
2021-11-22-12:26:51 TP:Topic1-0 是否可Fetch=true isReadyForFetch=true Follower是否限流=false !isReplicaInSync=true quota.isThrottled=true quota.isQuotaExceeded=false
2021-11-22-12:26:51记录Follower Fetch 流量 size: 1048576
2021-11-22-12:26:51 TP:Topic1-0 是否可Fetch=false isReadyForFetch=true Follower是否限流=true !isReplicaInSync=true quota.isThrottled=true quota.isQuotaExceeded=true
2021-11-22-12:26:51 TP:Topic1-0 是否可Fetch=false isReadyForFetch=true Follower是否限流=true !isReplicaInSync=true quota.isThrottled=true quota.isQuotaExceeded=true
2021-11-22-12:26:52 TP:Topic1-0 是否可Fetch=false isReadyForFetch=true Follower是否限流=true !isReplicaInSync=true quota.isThrottled=true quota.isQuotaExceeded=true
2021-11-22-12:26:53 TP:Topic1-0 是否可Fetch=true isReadyForFetch=true Follower是否限流=false !isReplicaInSync=true quota.isThrottled=true quota.isQuotaExceeded=false
2021-11-22-12:26:53记录Follower Fetch 流量 size: 1048576
2021-11-22-12:29:13 TP:Topic1-0 是否可Fetch=false isReadyForFetch=true Follower是否限流=true !isReplicaInSync=true quota.isThrottled=true quota.isQuotaExceeded=true
2021-11-22-12:29:13 TP:Topic1-0 是否可Fetch=false isReadyForFetch=true Follower是否限流=true !isReplicaInSync=true quota.isThrottled=true quota.isQuotaExceeded=true
2021-11-22-12:29:14 TP:Topic1-0 是否可Fetch=false isReadyForFetch=true Follower是否限流=true !isReplicaInSync=true quota.isThrottled=true quota.isQuotaExceeded=true
— 最后一次Fetch就 同步完成了
2021-11-22-12:29:15 TP:Topic1-0 是否可Fetch=true isReadyForFetch=true Follower是否限流=false !isReplicaInSync=true quota.isThrottled=true quota.isQuotaExceeded=false
2021-11-22-12:29:15记录Follower Fetch 流量 size: 409888
2021-11-22-12:29:15 TP:Topic1-0 是否可Fetch=true isReadyForFetch=true Follower是否限流=false !isReplicaInSync=false quota.isThrottled=true quota.isQuotaExceeded=true
2021-11-22-12:29:16 TP:Topic1-0 是否可Fetch=true isReadyForFetch=true Follower是否限流=false !isReplicaInSync=false quota.isThrottled=true quota.isQuotaExceeded=true
可以看到日志, 开始同步之后,第一次Fetch同步了1048576(1MB) 这个数值是可以配置的,单次fetch的最大值。 Fetch之后超过了 限流阈值,则后面就开始限流了, 等过了几秒,低于阈值了又开始Fetch。最后一次Fetch成功后, Follower就跟上了ISR了,就不会再进行限流了。
最终耗时:2021-11-22-12:29:15 - 2021-11-22 12:25:59 = 196 S 约等于我们的预期 200S (100MB/0.5M/s = 200s)。
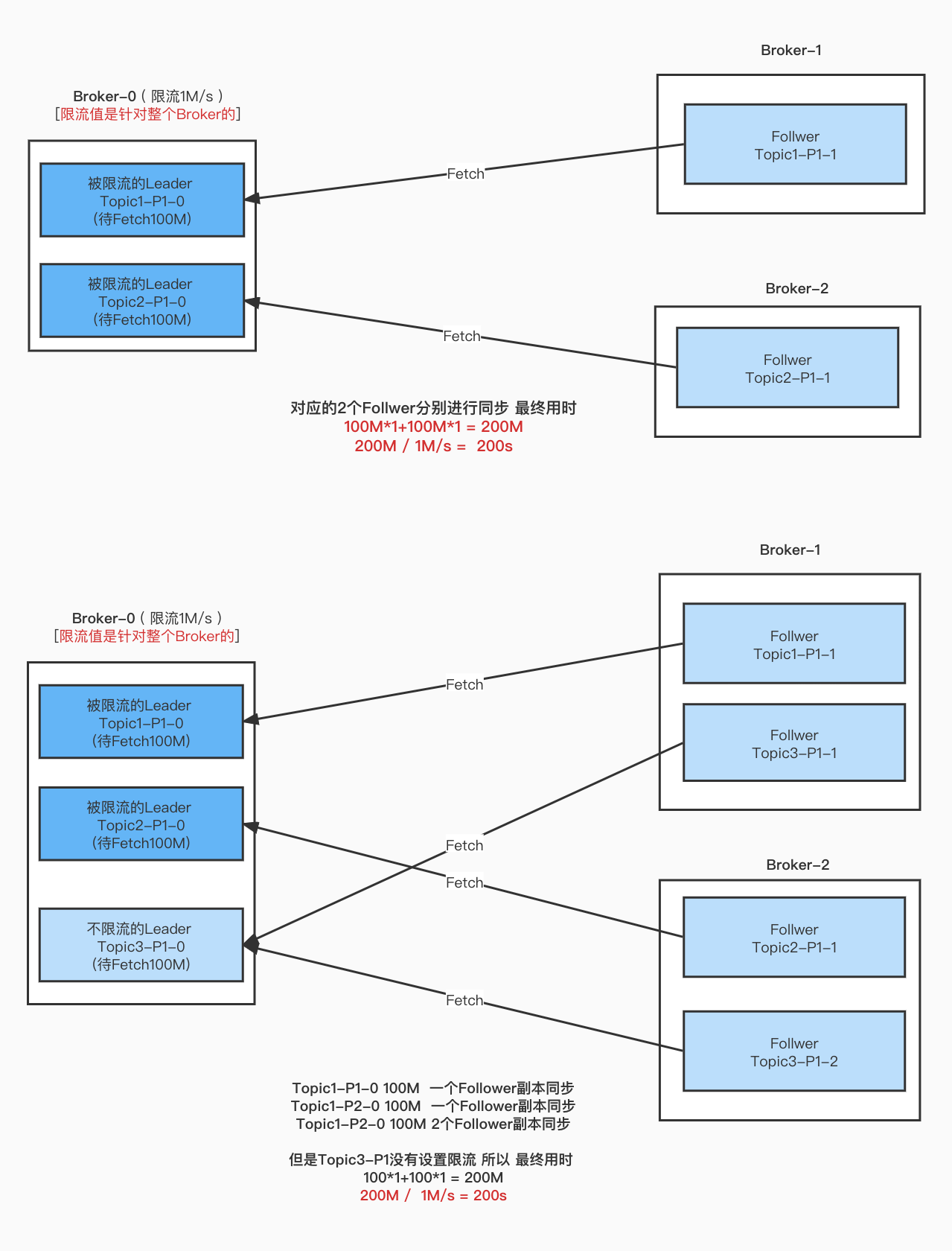
Topic1 2分区 2 副本
2个分区 对应的副本都在同一个Broker上 进行测试。
最终结果 是在一台Broker上, 有多少个Follower的副本被限流, 那么这些副本所Fetch的数据流量都会被遗弃算入到限流中。
Topic1 多分区 多 副本
多个分区 多个副本 在不同的Broker上, 不同的Broker的流量只会算在当台Broker。
上图中的2个Leader 都是100M。
如果你之前看过我写的 分区副本重分配源码原理分析(附配套教学视频) 的,你肯定有印象, 在执行副本重分配的时候我们会设置一个限流值 --throttle xxxx
你是否会疑问
这个限流,到底设置的是什么限流呢?
应该怎么合理的设置限流呢?
想了解更详细的内容可以 看看我那篇文章 , 这里我写2个例子来说明一下:
无副本新增
例如我有个 Topic2 单分区 3副本 分配情况如下
{“version”:2,“partitions”:{“0”:[0,1,2]},“adding_replicas”:{},“removing_replicas”:{}}
我对其做一个分区副本重分配的操作
最终想让它的分配方式为如下
{“version”:2,“partitions”:{“0”:[2,0,1]},“adding_replicas”:{},“removing_replicas”:{}}
迁移过程让它的限流值为 1 b/s
我们看下限流配置写入了什么
三个Broker配置都新增了
{
“version” : 1,
“config” : {
“leader.replication.throttled.rate” : “1”,
“follower.replication.throttled.rate” : “1”
}
}
还有Topic配置 如下
{
“version” : 1,
“config” : {
“leader.replication.throttled.replicas” : “”,
“follower.replication.throttled.replicas” : “”
}
}
可以看到 这个Topic配置好像并没有设置要给哪个分区进行限流。
那是因为这个迁移 并没有新增
PS: 假如原本就有这个配置, 那么经过这样一次操作之后会被重写为空
有副本新增
Topic3 单分区 单副本 扩副本
{“version”:1,“partitions”:[{“topic”:“Topic3”,“partition”:0,“replicas”:[0]}]}
重分配至 (新增了2个副本)
{“version”:1,“partitions”:[{“topic”:“Topic3”,“partition”:0,“replicas”:[0,1,2]}]}
Broker [0,1,2] 都新增配置
{
“version” : 1,
“config” : {
“leader.replication.throttled.rate” : “1”,
“follower.replication.throttled.rate” : “1”
}
}
Topic3配置新增
{
“version” : 1,
“config” : {
“leader.replication.throttled.replicas” : “0:0”,
“follower.replication.throttled.replicas” : “0:1,0:2”
}
}
可以看到 Topic配置, Leader 和 Follower 都有需要限流的
解释一下配置含义:
"leader.replication.throttled.replicas" : "0:0": 该Topic下的 0号分区 Leader副本 在Broker-0 上需要 进行Leader副本限流
"follower.replication.throttled.replicas" : "0:1,0:2"该Topic下的0号分区Follower副本在 Broker-0、Broker-1 上需要进行Follower副本限流。
限流值都是 1b/s (上面设置的)
扩副本之前就有多个副本
{“version”:1,“partitions”:[{“topic”:“Topic4”,“partition”:0,“replicas”:[2,0]}]}
重分配成如下
{“version”:1,“partitions”:[{“topic”:“Topic4”,“partition”:0,“replicas”:[0,1,2]}]}
最终可以看到的Topic配置如下:
{
“version” : 1,
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

最后希望可以帮助到大家!
千千万万要记得:多刷题!!多刷题!!
之前算法是我的硬伤,后面硬啃了好长一段时间才补回来,算法才是程序员的灵魂!!!!
篇幅有限,以下只能截图分享部分的资源!!
(1)多线程(这里以多线程为代表,其实整理了一本JAVA核心架构笔记集)

(2)刷的算法题(还有左神的算法笔记)

(3)面经+真题解析+对应的相关笔记(很全面)

(4)视频学习(部分)
ps:当你觉得学不进或者累了的时候,视频是个不错的选择
在这里,最后只一句话:祝大家offer拿到手软!!
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!**
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。[外链图片转存中…(img-6saHdK6F-1713599116085)]
[外链图片转存中…(img-6mCiJevA-1713599116085)]
[外链图片转存中…(img-rQY97mVO-1713599116086)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)
最后希望可以帮助到大家!
千千万万要记得:多刷题!!多刷题!!
之前算法是我的硬伤,后面硬啃了好长一段时间才补回来,算法才是程序员的灵魂!!!!
篇幅有限,以下只能截图分享部分的资源!!
(1)多线程(这里以多线程为代表,其实整理了一本JAVA核心架构笔记集)
[外链图片转存中…(img-36sUQcrN-1713599116086)]
(2)刷的算法题(还有左神的算法笔记)
[外链图片转存中…(img-7Kr4KBH7-1713599116086)]
(3)面经+真题解析+对应的相关笔记(很全面)
[外链图片转存中…(img-7mgZ7FYm-1713599116086)]
(4)视频学习(部分)
ps:当你觉得学不进或者累了的时候,视频是个不错的选择
在这里,最后只一句话:祝大家offer拿到手软!!
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!















 5753
5753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









