







目录索引
获取元素信息:
获取单个文本和属性:
获取文本:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
import time
browser = webdriver.Chrome()
url = "https://www.bilibili.com/"
browser.get(url)
find_input = browser.find_element(By.XPATH,'//*[@id="i_cecream"]/div[2]/div[1]/div[3]') #获取哔哩哔哩上面的分类框
print(find_input.text)
呈现效果: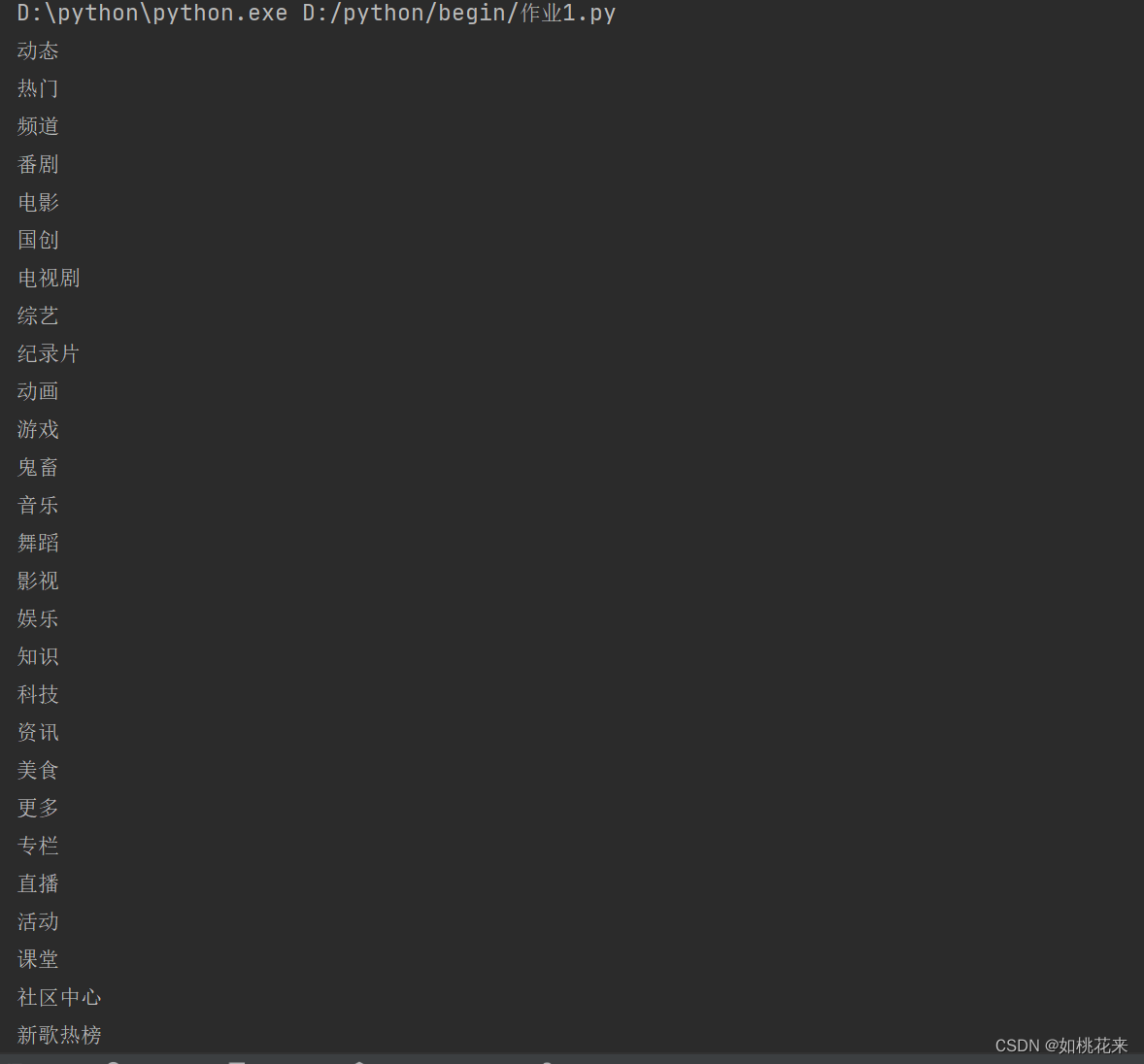
获取属性:
语法:
get_attribute("属性名")
#代码继承上方
print(find_input.get_attribute("class"))
呈现效果:
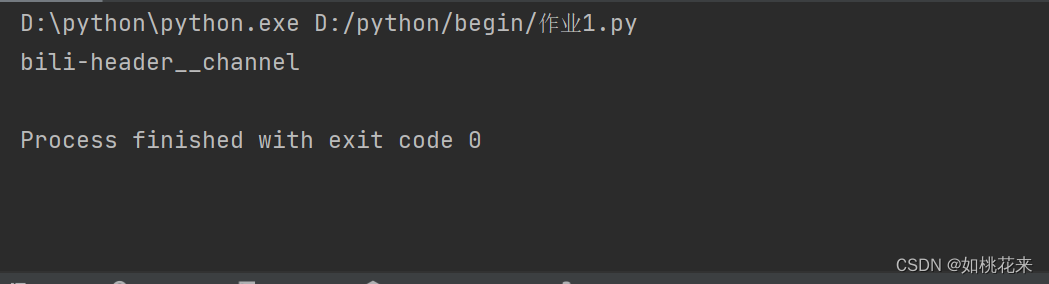
获取多个文本和属性值:
browser = webdriver.Chrome()
url = "https://www.bilibili.com/"
browser.get(url)
find_inputs = browser.find_elements(By.XPATH,'//*[@id="i_cecream"]/div[2]/div[1]/div[3]/div[1]/a') #获取哔哩哔哩上面的分类框
for i in find_inputs:
print(i.text)
print(i.get_attribute("href"))
呈现效果:
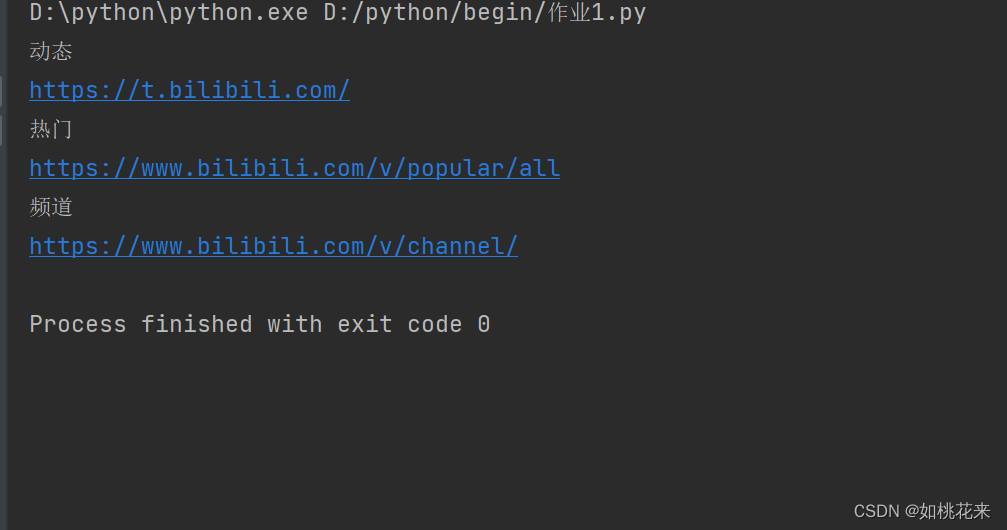
等待:
- 等待特定元素出现后做某事
- 通常用于等待某个页面元素加载完毕后进行后续操作,避免出现异常
- 等待的先后常常会影响你最后能否爬取到正确的数据
显示等待:
明确要等待某个元素出现,等不到就一直等。如果在规定的时间内都没找到,那么报错
browser = webdriver.Chrome()
url = "https://www.bilibili.com/"
browser.get(url)
# wait = WebDriverWait(browser,2)
wait = WebDriverWait(browser,0.001)
result = wait.until(EC.presence_of_element_located((By.XPATH,'//*[@id="i_cecream"]/div[2]/main/div[2]/div/div[1]/div[5]/div/div[2]/a/div/div[1]/picture/img'))) #传入的是一个元组
find_inputs = browser.find_elements(By.XPATH,'//*[@id="i_cecream"]/div[2]/div[1]/div[3]/div[1]/a') #获取哔哩哔哩上面的分类框
print(result)
time等待:
直接使用time模块睡眠即可,简单又方便
EC:
导包:from selenium.webdriver.support import expected_conditions as EC
常见方法:
- title_is 标题是某内容
- title_contains 标题包含某内容
- presence_of_element_located 元素加载出,传入定位元组,如(By.ID, 'p')
- visibility_of_element_located 元素可见,传入定位元组
- visibility_of 可见,传入元素对象
- presence_of_all_elements_located 所有元素加载出
- text_to_be_present_in_element 某个元素文本包含某文字
- text_to_be_present_in_element_value 某个元素值包含某文字
- frame_to_be_available_and_switch_to_it frame加载并切换
- invisibility_of_element_located 元素不可见
- element_to_be_clickable 元素可点击
- staleness_of 判断一个元素是否仍在DOM,可判断页面是否已经刷新
- element_to_be_selected 元素可选择,传元素对象
- element_located_to_be_selected 元素可选择,传入定位元组
- element_selection_state_to_be 传入元素对象以及状态,相等返回True,否则返回False
- element_located_selection_state_to_be 传入定位元组以及状态,相等返回True,否则返回False
alert_is_present 是否出现Alert
前进后退:
控制浏览器前进页面或者后退界面,效果跟这两个箭头差不多
语法:
browser.back() #后退页面
browser.forward() #前进页面
#举个例子:
browser = webdriver.Chrome()
url1 = "https://www.bilibili.com/"
url2 = "https://www.zhihu.com/signin?next=%2F"
url3 = "https://www.baidu.com/s?ie=UTF-8&wd=%E7%99%BE%E5%BA%A6"
browser.get(url1)
browser.get(url2)
browser.get(url3)
browser.back() #后退页面
time.sleep(2)
browser.forward() #前进页面
time.sleep(2)
browser.close()
选项卡管理:
- 只有切换到当前窗口时,才能操作当前窗口(比如翻页、获取源代码等等)
- 番外:execute_script()函数常常用来运行js代码,浏览器的交互
- 除了第一个打开的窗口id为0,其他都是不按顺序打开窗口的。
打开窗口:
语法:
window.open()
窗口切换:
语法:
switch_to_window(窗口id)
查看所有窗口id:
语法:
window_handles
实例演示:
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com') # 选项卡0 窗口0
time.sleep(1)
browser.execute_script('window.open()') # 选项卡1 窗口1
time.sleep(1)
browser.execute_script('window.open()') # 选项卡2 窗口2
time.sleep(1)
browser.execute_script("window.open()") #选项卡3 窗口3
IDS = browser.window_handles # 查看当前浏览器所有窗口ID
browser.switch_to.window(browser.window_handles[1]) # 浏览器对象加载选项卡1 切换到窗口1
browser.get('https://www.taobao.com') # 窗口1 打开淘宝
time.sleep(2)
browser.switch_to.window(browser.window_handles[0]) # 浏览器对象加载选项卡0 切换到窗口0
browser.get('https://www.mi.com/') # 窗口0 打开小米官网
time.sleep(2)
browser.switch_to.window(browser.window_handles[2]) # 浏览器对象加载选项卡2 切换到窗口2
browser.get('https://jd.com')
time.sleep(2)
#再新开一个选项卡,然后获取新选项卡的源代码
browser.switch_to.window(browser.window_handles[3]) #空白页面
browser.get('https://www.baidu.com')
print(browser.page_source)
print("*"*80)
browser.switch_to.window(browser.window_handles[0])
print(browser.page_source)
- 通过windows.open()打开的网页一开始都是空白的,注意这个时候我们打开的选项卡尽管是无序的,但是我们通过给指定的选项卡请求对应网址,其实就相当于绑定了他的窗口id,实际上显示的id顺序是混乱的。但是我们设定给选项卡1一个请求网址,给选项卡2一个请求网址,到时候我们对网址的操作只要转换1、2就可以了,不用再管网页的顺序。
Cookies:
获取服务器设置在本地的cookies:
cookies = browser.get_cookies()
print(cookies)
设置cookies:
# 设置 cookies 请求站点时携带的cookie信息
browser.add_cookie({'name': 'zhangsan', 'domain': 'abcd123', 'value': 'hellozhang'})
print(browser.get_cookies()) # 查看设置成功的cookies信息
清除cookies:
# 清除cookies
browser.delete_all_cookies() # 删除所有cookie
print(browser.get_cookies())
iframe:
selenium-iframe
网页中嵌套了网页,相当于在总网页之中,放了一些小网页。要对小网页进行操作的话。先切换到iframe,然后再执行其他操作
-
切换到要处理的Frame
browser.switch_to.frame(frame节点对象) -
在Frame中定位页面元素并进行操作
















 4248
4248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











