









这一个栏目,我会给出我从零开始学习爬虫的全过程。感兴趣的小伙伴可以关注一波,用于复习和新学都是不错的选择。
那么废话不多说,就让我们开始吧。
请跟我念口号:
爬虫,爽!

requests模块的作用:
一句话概括:用于发送和接受网站的响应。
Tips: 你给谁发请求,接收到的就是哪个网页传回来的响应。所以想学好爬虫,第一步就是向正确的网址发送响应。
实例引入:
- 比如说我们拿京东网站来举例。里面有非常多的数据,包括一切动态加载的数据。那如果我要只想要当前网页的静态数据,该怎么获取呢?

2.打开网页检查

这里面最重要的两个按钮就是:元素和网络。
其中,元素是整个网页的html代码。
而网络是我们爬虫的重点。
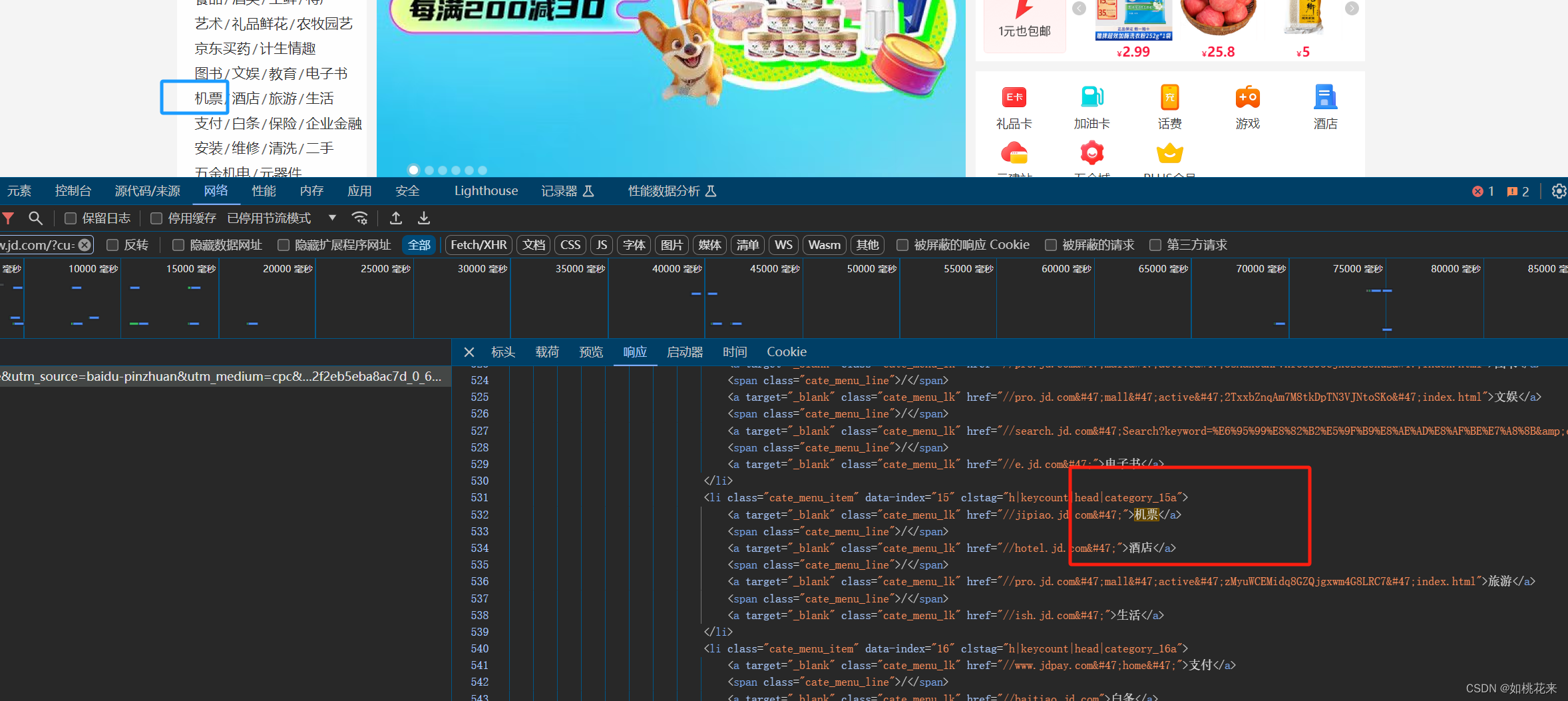
3.进入到网络界面后,找到对应的url
记得要刷新一下,这里面有各种各样的数据,包括动态的。我们需要将当前网页的网址复制到搜索框里进行检索。

那么跳出来的响应,就是我们要的当前网页返回的数据
4.检查url是否正确
从响应里面的response查看、搜索里面是否有我们需要的数据
特殊情况:
我们在实际使用爬虫的过程中,经常会遇到内容不在该页面或者压根找不到的情况。非常麻烦,那该怎么办呢?
莫慌,吾有良计!
锦囊1:
利用search按钮,对全页面的response数据进行总检索。
例子展示:
我们首先要拿出最经典的豆瓣电影网来做参考:
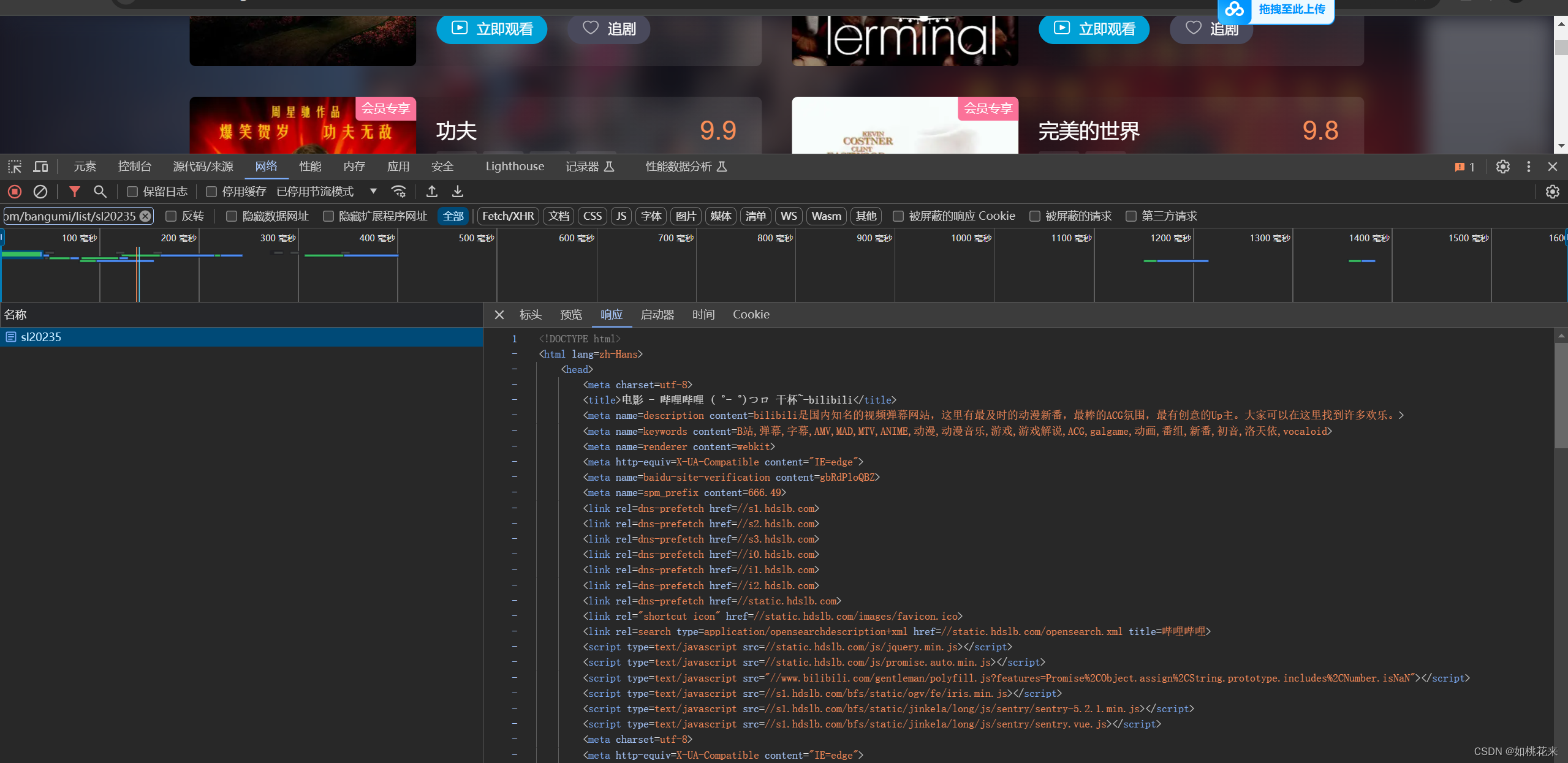
功夫是一个相当经典的电影。看上述图片,我们用本文开篇提到的搜索方法,发现功夫这个词条根本就不存在当前网页的response中。这时候我们就需要用到search按钮。
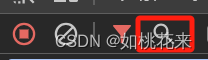
控制台中左上角的这个小放大镜,就是我们提到的search按钮。它的功能是在所有的response中检索相应的词条。

这下我们就能找到相应的url了,是不是非常简便呢。
锦囊2:
利用翻页的异步请求方式。如果锦囊1依旧找不到对应的url的话,我们就需要使用异步请求来查看对应的url。
1.首先清空网页内容,点击红框按钮即可。
2.我们都知道前端页面的设计具有规律性,网页中第2页获取请求的方式,跟第一页是一样的。所以我们会通过查看第二页的方式来获取对应的url。
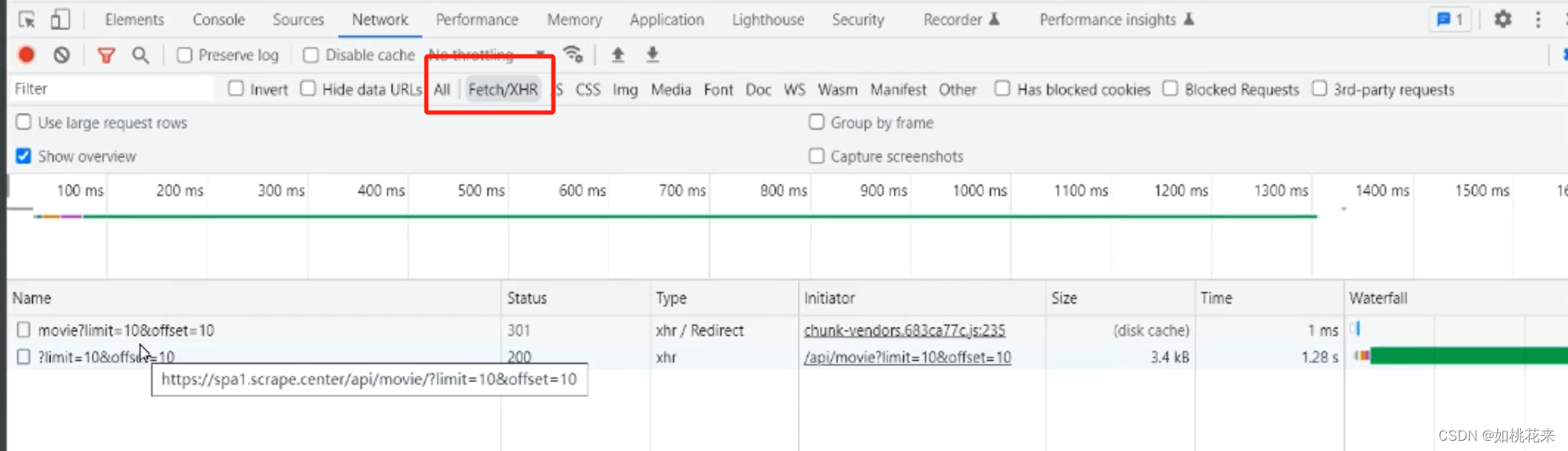
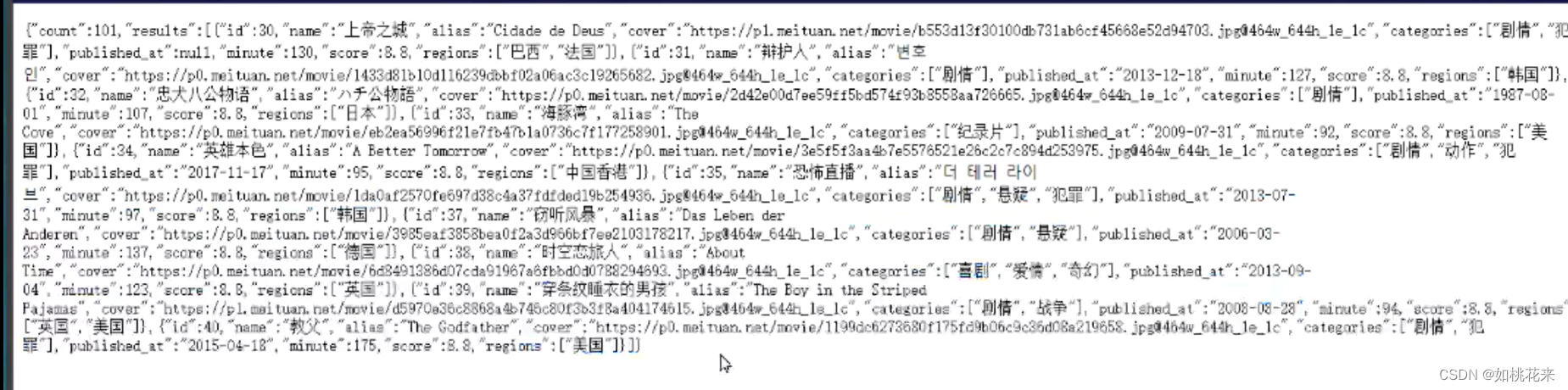
3.寻找页码规律就可以找出对应的url了。最后,我们会得到一个json格式的数据。
















 268
268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











