







联系数计加油站获取论文和代码等资源。
邮箱:MathComputerSharing@outlook.com
微信公众号:数计加油站
致谢:清风数学建模

要么同舟共济,要么背道而驰😒
数据与数据之间,可能有很复杂的关系。作为一名观测者,我们往往在乎它们之间是否具有线性关系。
看到线性这个词,我们总会联想到直线。没错,理想的线性关系,就是一条斜率为正或斜率为负的直线。一组数据上升,能观测到另一组数据随之上升或下降。这称为完全正相关或完全负相关。
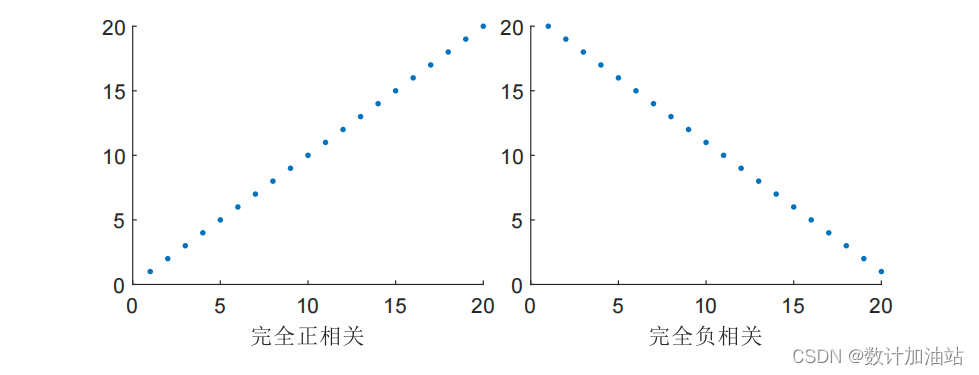
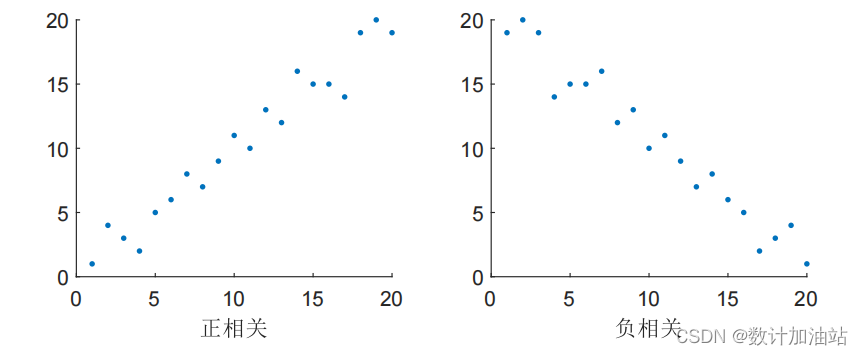
但是现实中的数据的关系不可能这么完美。它们最多只会整体上呈现“同舟共济”或“背道而驰”的效果。称为正相关或负相关。
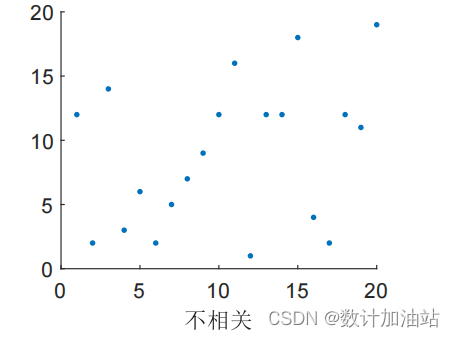
甚至更糟,两组数据互相背刺,一下子这样,一下子那样,完全没有要“线性”一回的想法。这称为不相关。
要么他,要么他,要么他😅
为了丈量线性相关性的大小,我们引进两组数据之间的相关系数的概念。
相关系数是这样一个数:它在-1到1之间;它的绝对值越接近于0,说明相关性越小;它的绝对值越接近于1,说明相关性越大;它正,说明正相关;它负,说明负相关。
有三个人男人给你带来了满足这些条件的相关系数。他们分别是Pearson、Spearman、Kendall。
Pearson相关系数最为常用,它最为针对连续数据,并且要求这些连续数据服从最为常见的一种分布——正态分布。
Spearsman相关系数主要针对定序的数据,也就是数值的大小有意义的数据。而且他对数据的分布没有要求。
Kendall相关系数也是针对定序数据,和Spearman相关系数属于算是一对孪生兄弟。
要么是0,要么是1😎
相关系数当然是绝对值越大越好。但常常事与愿违。由于数据体量太大,相关系数往往算得很小。
这种时候,我们只在意一件事:相关系数这么小,两组数据到底相不相关啊?
其实,问题已经转变成了:我的相关系数到底是不是显著地不等于0啊?换句话说,只要不是0,它就对我有意义,它就相当于1!!!
统计学中的假设检验可以解决这个问题。
作出假设:相关系数 r r r等于0。再构造一个和 r r r相关的统计量。这个统计量的分布应该已知。对此,我们就可以对我们计算出的 r ∗ r^* r∗去计算它出现的概率。如果概率很小,小于我们选定的置信水平,但我们确实又算出了这么个相关系数 r ∗ r^* r∗,我们就可以在统计意义上否定原假设:即 r r r显著不等于0。虽然两组数据的相关系数较小,但它还是显著地有一点相关性的嘛💗
一篇简短的小论文














Matlab代码
描述性统计
function result = DescriptiveStat(data)
% 描述性统计
% 各行分别为最大值,最小值,中位数,平均值,标准差,峰度,偏度
Max = max(data);
Min = min(data);
Median = median(data);
Mean = mean(data);
Std = std(data);
Kurt = kurtosis(data)-3;
Skew = skewness(data);
result = [Max;Min;Median;Mean;Std;Kurt;Skew];
end
相关系数分析示例
clc,clear
%% 描述性统计
data = readmatrix("data\相关系数示例.csv","NumHeaderLines",1);
n = size(data,2);
result = DescriptiveStat(data);
disp(result);
%% 绘制散点图矩阵
figure(1);
MatrixScatter(data);
%% 绘制Q-Q图
figure(2)
for i=1:n
subplot(2,4,i);
qqplot(data(:,i));
xlabel("");
ylabel("");
title("");
end
%% 正态性检验
% Jarque-Bera 检验
% jb_H = ones([n,1]);
% jb_P = ones([n,1]);
% for i=1:n
% [jb_h,jb_p] = jbtest(data(:,i),0.1);
% jb_H(i,1)=jb_h;
% jb_P(i,1)=jb_p;
% end
% disp([jb_H,jb_P]);
% Shapiro-wilk 检验
sw_H = ones([n,1]);
sw_P = ones([n,1]);
for i=1:n
[sw_h,sw_p] = swtest(data(:,i),0.1);
sw_H(i,1)=sw_h;
sw_P(i,1)=sw_p;
end
disp([sw_H,sw_P]);
%% 计算Pearson相关系数
[Rp,Pp] = corrcoef(data);
disp(Rp);
disp(Pp);
% 绘制相关系数热力图
figure(3);
names = ["语文","数学","英语","生物","历史","地理","政治"];
heatmap(names,names,Rp);
colormap("jet");
%% 计算Spearman相关系数
[Rs,Ps] = corr(data,"type","Spearman");
disp(Rs);
disp(Ps);
% 绘制相关系数热力图
figure(4);
names = ["语文","数学","英语","生物","历史","地理","政治"];
heatmap(names,names,Rs);
colormap("jet");
%% 计算Kendall相关系数
[Rk,Pk] = corr(data,"type","Kendall");
disp(Rk);
disp(Pk);
% 绘制相关系数热力图
figure(5);
names = ["语文","数学","英语","生物","历史","地理","政治"];
heatmap(names,names,Rk);
colormap("jet");
Python代码
初始化
## 导包
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from scipy import stats
import statsmodels.api as sm
np.set_printoptions(suppress=True)
plt.rcParams["font.sans-serif"] = ["SimHei"] #设置字体
plt.rcParams["axes.unicode_minus"] = False # 解决图像中的“-”负号的乱码问题
## 数据初始化
data = pd.read_csv("../data/相关系数示例.csv", encoding="gbk")
n = data.shape[1]
D = data.to_numpy()
display(data)
相关系数分析示例
## 矩阵散点图
for i in range(n):
for j in range(n):
plt.subplot(n, n, n * i + j + 1)
plt.xticks([])
plt.yticks([])
if i != j:
plt.scatter(D[:, i], D[:, j], 2)
## 描述性统计
result0 = stats.describe(data)
result = [result0.minmax[1], result0.minmax[0], data.median(), result0.mean, data.std(), result0.kurtosis,
result0.skewness]
result = pd.DataFrame(result, columns=data.columns,
index=["最大值", "最小值", "中位数", "平均值", "标准差", "峰度", "偏度"])
display(result)
## Pearson相关系数
# Q-Q图
plt.figure(figsize=(10, 5))
for i in range(n):
sub_ax = plt.subplot(2, 4, i + 1)
sm.qqplot(D[:, i], ax=sub_ax, line='45', fit=True, markersize=4, marker="x")
sub_ax.set_xlabel(None)
sub_ax.set_ylabel(None)
sub_ax.set_xticks([])
sub_ax.set_yticks([])
plt.subplots_adjust(wspace=0.1, hspace=0.1)
# 正态性检验
#jbtest_result = []
#for i in range(n):
#jb, jb_p = stats.jarque_bera(D[:, i])
#jbtest_result.append([jb, jb_p])
#jbtest_result = pd.DataFrame(jbtest_result, columns=["jb值", "p值"], index=data.columns)
#display(jbtest_result)
swtest_result = []
for i in range(n):
W, sw_p = stats.shapiro(D[:, i])
swtest_result.append([W, sw_p])
swtest_result = pd.DataFrame(swtest_result, columns=["W值", "p值"], index=data.columns)
display(swtest_result)
# 相关系数计算
Rp = np.ones((n, n))
Pp = np.ones((n, n))
for i in range(n):
for j in range(n):
rp, pp = stats.pearsonr(D[:, i], D[:, j])
Rp[i, j] = rp
Pp[i, j] = pp
Rp = pd.DataFrame(Rp, columns=data.columns, index=data.columns)
Pp = pd.DataFrame(Pp, columns=data.columns, index=data.columns)
display(Rp)
display(Pp)
# 热力图
sns.heatmap(Rp, xticklabels=data.columns, yticklabels=data.columns, annot=True, cmap="jet", fmt=".4f")
plt.show()
## Spearman相关系数
# 相关系数计算
Rs = np.ones((n, n))
Ps = np.ones((n, n))
for i in range(n):
for j in range(n):
rs, ps = stats.spearmanr(D[:, i], D[:, j])
Rs[i, j] = rs
Ps[i, j] = ps
Rs = pd.DataFrame(Rs, columns=data.columns, index=data.columns)
Ps = pd.DataFrame(Ps, columns=data.columns, index=data.columns)
display(Rs)
display(Ps)
# 热力图
sns.heatmap(Rs, xticklabels=data.columns, yticklabels=data.columns, annot=True, cmap="jet", fmt=".4f")
plt.show()
## Kendall 相关系数
# 相关系数计算
Rk = np.ones((n, n))
Pk = np.ones((n, n))
for i in range(n):
for j in range(n):
rk, pk = stats.kendalltau(D[:, i], D[:, j])
Rk[i, j] = rk
Pk[i, j] = pk
Rk = pd.DataFrame(Rk, columns=data.columns, index=data.columns)
Pk = pd.DataFrame(Pk, columns=data.columns, index=data.columns)
display(Rk)
display(Pk)
# 热力图
sns.heatmap(Rk, xticklabels=data.columns, yticklabels=data.columns, annot=True, cmap="jet", fmt=".4f")
plt.show()

















 1881
1881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









