







<name>dfs.namenode.rpc-address.master.nn1</name> #标识符nn1的RPC服务地址
<value>spark01:9000</value>
5. 修改mapred-site.xml文件
在虚拟机Spark01中,进入Hadoop安装包的/etc/hadoop/目录,执行“`cp mapred-site.xml.template mapred-site.xml`”命令,通过复制模板文件方式创建MapReduce
的核心配置文件mapred-site.xml,执行“`vi mapred-site.xml`”命令编辑配置文件
mapred-site.xml ,指定MapReduce运行时框架。如下:
6. 修改yarn-site.xml文件
在虚拟机Spark01中,进入Hadoop安装包的/etc/hadoop/目录,执行“cp yarn-site.xml”命令,编辑YARN的核心配置文件yarn-site.xml。如下:
7. 修改slaves文件
在虚拟机Spark01中,进入Hadoop安装包的/etc/hadoop/目录,执行“`vi slaves`”命令,编辑记录Hadoop集群所有DataNode节点和NodeManager节点主机名的文件slaves。如下:
spark01
spark02
spark03
8. 配置Hadoop环境变量
在虚拟机Spark01中,执行“`vi /etc/profile`”命令编辑系统环境变量文件profile,
配置Hadoop系统环境变量。如下:
export HADOOP_HOME=/export/servers/hadoop-2.7.4
export PATH=
H
A
D
O
O
P
H
O
M
E
/
b
i
n
:
HADOOP_HOME/bin:
HADOOPHOME/bin:HADOOP_HOME/sbin:$PATH
系统环境变量文件profile配置完成后保存并退出即可,随后执行“`source /etc/profile`”命令初始化系统环境变量使配置内容生效。
9. 分发文件
为了便于快速配置Hadoop集群中其他服务器,将虚拟机Spark01中的Hadoop安装目录和系统环境变量文件分发到虚拟机Spark02和Spark03。如下:
#将Hadoop安装目录分发到虚拟机Spark02和Spark03
$ scp -r /export/servers/hadoop-2.7.4/ root@spark02:/export/servers/
$ scp -r /export/servers/hadoop-2.7.4/ root@spark03:/export/servers/
#将系统环境变量文件分发到虚拟机Spark02和Spark03
$ scp /etc/profile root@spark02:/etc/
$ scp /etc/profile root@spark03:/etc/
完成分发操作,分别在虚拟机Spark02和Spark03中执行“`source /etc/profile`”命令初始化系统环境变量。
10. 验证Hadoop环境
在虚拟机Spark01中,执行“`hadoop version`”命令查看当前系统环境的Hadoop版本。如下图所示:

## 三、启动Hadoop高可用集群配置
1. 启动ZooKeeper
分别在虚拟机Spark01、Spark02和Spark03中执行“`zkServer.sh start`”命令启动每台虚拟机的ZooKeeper服务。
2. 启动JournalNode
分别在虚拟机Spark01、Spark02和Spark03中执行“`hadoop-daemon.sh start journalnode`”命令启动每台虚拟机的JournalNode服务。如下图所示:



3. 初始化NameNode(仅初次启动执行)
在Hadoop集群主节点虚拟机Spark01执行“`hdfs namenode -format`”命令初始化NameNode操作。如下图所示:

4. 初始化ZooKeeper(仅初次启动执行)
在NameNode主节点虚拟机Spark01,执行“`hdfs zkfc -formatZK`”命令初始化ZooKeeper 中的 HA 状态。

5. NameNode同步(仅初次启动执行)
在虚拟机Spark01中的NameNode主节点执行初始化命令后,需要将元数据目录的内容复制到其他未格式化的 NameNode备用节点(虚拟机Spark02)上,确保主节点和备用节点的NameNode数据一致。命令如下:
`scp -r /export/data/hadoop/namenode/ root@spark02:/export/data/hadoop/`
6. 启动HDFS
在虚拟机Spark01中通过执行一键启动脚本命令“`start-dfs.sh`”,启动Hadoop集群的HDFS,此时虚拟机Spark01和Spark02上的NameNode和ZKFC以及虚拟机Spark01、Spark02和Spark03上的DataNode都会被启动。
7. 启动YARN
在虚拟机Spark01中通过执行一键启动脚本命令“`start-yarn.sh`”,启动Hadoop集群的YARN,此时虚拟机Spark01上的ResourceManager以及虚拟机Spark01、Spark02和Spark03上的NodeManager都会被启动,不过虚拟机Spark02上的ResourceManager备用节点需要在虚拟机Spark02上执行“`yarn-daemon.sh start resourcemanager`”命令单独启动。
8. 查看集群
分别在三台虚拟机Spark01、Spark02和Spark03上执行“`jps`”命令查看Hadoop高可用集群相关进程是否成功启动。


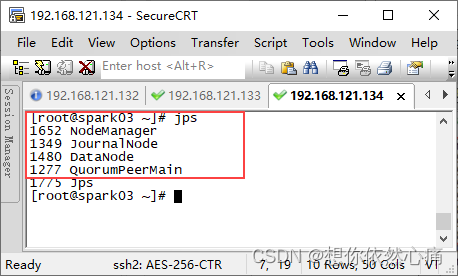
## 四、关闭Hadoop高可用集群
1. 在虚拟机Spark02执行“`yarn-daemon.sh stop resourcemanager`”命令,关闭ResourceManager备用节点。
2. 在虚拟机Spark02执行“`stop-yarn.sh`”命令,关闭YARN。
3. 在虚拟机Spark02执行“`stop-dfs.sh`”命令,关闭HDFS。
4. 分别在虚拟机Spark01、Spark02和Spark03执行“`hadoop-daemon.sh stop journalnode`”命令,关闭JournalNode。
好了,Hadoop的集群部署我们就讲到这里了,下一篇我们将讲解[Spark集群部署]( )
转载自:<https://blog.csdn.net/u014727709/article/details/130915938>
欢迎start,欢迎评论,欢迎指正


**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 820
820











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









