






- 微内核:早在1969年,UNIX系统开始设计的时候,类似的微内核架构的操作系统就已经出现。微内核的发展到目前为止经历了三代,Mach(1975年)是第一代微内核的代表,Mach将很多内核功能以单独服务的形式运行在用户态,然而Mach微内核自身资源(包括内存和CPU缓存等)占用过大的问题是的其性能与同时期的宏内核相比存在差距;L4是第二代微内核的代表,微内核的最小原则:一个操作系统内核的功能只有在将其放在内核态以外会影响整个系统的功能时,才能被放置在内核态;EROS首次将能力机制引入微内核操作系统中,并高效的实现了该机制;SEL4是第三代微内核的代表(P30)。
- 外核:外核是一种操作系统架构,它将硬件资源管理的基本控制权直接交给应用程序,而不是通过传统操作系统内核提供的抽象层来间接管理。这种设计理念的核心是将资源管理的灵活性最大化,减少内核对应用程序的干预,从而提高性能和效率。外核架构中的库操作系统:库操作系统是一种操作系统架构,它将操作系统的功能实现为一组库,这些库被链接到应用程序中运行。库操作系统旨在提供应用程序所需的操作系统服务,但与传统操作系统不同,它们不运行在独立的内核模式下,而是作为应用程序的一部分运行在用户空间(P32)。
- 多内核架构:多内核架构是一种计算机处理器设计,其中包含多个独立的处理核心在同一个芯片上。这些核心可以同时执行多个任务,提高系统的并行处理能力和总体性能。多内核处理器能够更有效地处理多线程和并行计算任务,常用于服务器、高性能计算和现代桌面系统(P34)。
- 混合内核架构:混合内核架构结合了微内核和宏内核的特点,旨在平衡性能和模块化。宏内核将大部分操作系统服务集成在内核空间中,提供高效的服务调用。微内核则将大部分服务移至用户空间,增强系统的模块化和安全性。混合内核在关键性能需求上使用宏内核方法,而在需要灵活性和安全性的部分采用微内核设计。例如,Windows NT和XNU(用于macOS和iOS)就是混合内核架构的例子(P35)。
- Android架构:Android架构由多个层次组成,包括Linux内核、硬件抽象层、Android运行时、应用框架和应用层。Linux内核提供核心系统服务,如进程管理、内存管理和驱动程序支持。硬件抽象层(HAL)定义标准接口,使Android框架能够与硬件具体实现进行通信。Android运行时包含核心库和Dalvik虚拟机或ART(Android Runtime),支持应用程序的执行。应用框架为开发者提供高层API,简化应用开发,包括Activity Manager、Window Manager等。应用层则包含用户可访问的应用程序,如拨号器、联系人和浏览器(P36)。
- ROS:机器人操作系统(ROS)架构由多个层次组成,包括ROS内核(roscore)、通信层、工具和库、ROS包以及应用层。ROS内核提供基本功能,如通信、包管理和设备控制。通信层通过消息传递机制(发布/订阅模式)、服务调用(客户端/服务器模式)和动作库,实现各节点间的通信。工具和库提供调试、可视化和开发工具,如rviz、rqt和Gazebo。ROS包是模块化的软件单元,包含节点、库和配置文件,支持重用和共享。应用层则由特定机器人应用程序组成,多个节点协同工作实现导航、感知和控制等复杂功能(P37)。
- 内存去重(KSM,Kernel Samepage Merging)是一种内核技术,旨在通过合并不同进程中相同内容的内存页来优化内存使用。KSM机制定期扫描内存,找到相同内容的内存页,将其合并为一个共享页,并将引用这些页的进程的页表项指向该共享页。合并后的页被标记为只读,若进程尝试写入该页,则触发写时复制(Copy-On-Write)操作,为该进程创建一个新的私有副本。KSM主要用于虚拟化环境和运行多个相似进程的系统中,通过减少重复页的数量显著节省内存资源(P60)。
- 内存压缩是一种优化内存使用的技术,通过压缩内存中的数据来减少物理内存消耗。当系统内存压力较大时,内存压缩机制会将不常使用的内存页进行压缩,将其存储在一个特殊的压缩内存区域中,从而释放更多的物理内存供其他进程使用。这种方法可以延迟或减少交换(swap)操作的频率,提升系统性能。内存压缩常用于操作系统内核中,如Linux的zswap和zram。其主要优点包括提高内存利用率、减少磁盘I/O操作以及在高内存压力下维持系统响应速度(P61)。
- SLUB 分配器是 Linux 内核中的一种内存管理机制,旨在提高小块内存的分配和释放效率。它采用了无锁设计,通过减少锁的使用和竞争来提高性能。SLUB 分配器在每个 CPU 上维护自己的小块缓存,从而减少了不同 CPU 之间的竞争,提升了内存操作的速度。它将内存分配和释放分为快速路径和慢速路径,快速路径处理常见的分配和释放操作,以减少延迟,而当缓存不足时转入慢速路径进行更复杂的处理。此外,SLUB 分配器通过合并相同大小的对象来减少内存碎片,提高内存利用率。它还提供了丰富的调试和统计工具,帮助开发者诊断和分析内存使用情况。总体而言,SLUB 分配器通过这些优化机制,显著提高了内存管理的效率和性能(P65)。
- 在Linux操作系统中,会话、前后台进程组、终端和信号相互关联,构成进程管理和控制的核心机制。会话是一组进程的集合,由一个登录进程创建,并有一个会话领导进程,其PID与会话ID相同。在一个会话中,进程被组织成进程组。前台进程组是用户当前交互的进程组,能够接收来自终端的输入和信号;而后台进程组则在后台运行,无法直接接收终端输入和来自终端的信号(P88)。
- Fork的替代函数:posix_spawn、vfork、rfork、clone(P91)。
- 线程本地存储(Thread Local Storage,TLS)是一种用于在多线程编程中,每个线程可以拥有自己独立的存储空间,避免线程之间的数据竞争和共享数据的混乱。TLS允许每个线程维护独立的数据副本,即使多个线程在同一个变量上操作,也不会互相干扰(P94)。可以用关键字__thread来声明线程本地存储。
- 纤程:纤程在创建和上下文切换时的开销比线程小得多,它们通常在用户态管理,而不是依赖内核态的调度。纤程通常使用协作式调度机制,这意味着纤程需要显式地让出控制权给其他纤程,与此相对,线程通常由操作系统进行抢占式调度。同一进程中的所有纤程共享相同的地址空间,这使得它们之间的通信更加高效,但也需要程序员更小心地管理共享资源。由于纤程在用户态管理,创建的数量可以远远超过线程,能够处理更多并发任务。POSIX提供纤程ucontext相关的API:getcontext、setcontext、makecontext等(P102)。
- 公平共享调度:旨在确保所有用户或进程组获得公平的资源分配,而不是单个进程。它通过跟踪每个用户或组的资源使用情况,并根据设定的权重或优先级,动态调整资源分配,以避免资源独占,确保每个用户或组的资源使用符合预期的公平性目标;彩票调度:是一种随机化的调度算法,通过分配“彩票”来决定进程的调度顺序。每个进程获得一定数量的彩票,系统随机抽取一张彩票来决定下一个运行的进程。分配更多彩票的进程获得更多运行机会,从而实现近似的优先级调度。这种方法简单且灵活,适用于多种资源分配场景,能有效避免饥饿问题;步幅调度:是一种确定性调度算法,通过分配一个步幅值(stride)来控制进程的调度频率。每个进程被分配一个步幅值和一个通过计数器(即虚拟时间),系统总是选择通过计数器最小的进程运行。每次运行后,通过计数器增加对应的步幅值。步幅值较小的进程获得更多的CPU时间,从而实现精细的优先级控制,避免饥饿并确保公正性(P133)。
- 速率单调策略(RMS)是实时系统中的固定优先级调度算法,优先级根据任务周期确定,周期越短优先级越高,适用于周期性任务调度(P135)。
- 借用虚拟时间调度(Borrowed Virtual Time, BVT)是一种实时调度算法,结合了虚拟时间和实际时间来优化调度决策。它通过为每个任务分配一个虚拟时间,按虚拟时间排序决定调度顺序(虚拟时间小的先执行),优先级高的任务虚拟时间增速较慢,低优先级任务增速较快。当一个高优先级的任务到达时,可以借用时间(减少自己的虚拟时间),打断低优先级任务的执行,从而实现灵活的优先级调度。BVT调度器既能确保高优先级任务及时执行,又能在低优先级任务间公平分配CPU时间,适用于需要动态优先级调整的系统(P138)。
- 负载分担是一种分布式系统中的技术,旨在将工作负载均匀分布到多个处理单元(如服务器、节点或处理器)上,以优化资源利用率和提高系统性能。通过负载分担,系统能够避免单点过载,提升整体吞吐量和响应时间;协同调度是一种多处理器系统中的调度策略,通过同步调度相关联的任务,以减少任务之间的同步开销和通信延迟。这种调度策略特别适用于需要频繁通信和协作的并行计算任务,如分布式计算和多线程应用,能够显著提升系统性能;群组调度是一种协同调度的一种,将一组需要协同工作的任务(或进程)分配到一组,并以组为单位调度任务在多个CPU上执行;两级调度是一种分层的调度机制,通常应用于集群或多处理器系统中。第一层负责在各个处理节点之间分配任务,第二层在每个节点内部进一步调度任务。这种方法结合了全局调度的灵活性和局部调度的高效性,提高了系统的整体调度性能和资源利用率;负载追踪是一种动态监控和调整系统负载的技术,通过持续跟踪各个资源的使用情况,及时发现和响应负载变化。负载追踪可以帮助系统在负载不均衡时进行调整,例如动态迁移任务或重新分配资源,从而提高系统的适应性和稳定性;负载均衡是一种优化资源利用和性能的技术,通过将工作负载均匀地分配到多个处理单元上,避免某些资源过载和其他资源闲置。常见的负载均衡方法包括轮询、哈希分配和动态调整。负载均衡广泛应用于网络服务、云计算和分布式系统中,以确保高可用性和高性能(P145)。
- Linux内核支持三种主要调度器:完全公平调度器(CFS)、实时调度器(RT)、和Deadline调度器(DL)。完全公平调度器(CFS)是Linux的默认调度器,旨在为所有任务提供公平的CPU时间分配。CFS使用一个红黑树数据结构来维护所有可运行任务的虚拟运行时间,确保每个任务根据其优先级公平地获得CPU资源。它通过最小化调度延迟和平衡系统负载来优化整体性能,适用于大多数普通任务,包括桌面和服务器环境;实时调度器(RT)包含两种策略:SCHED_FIFO和SCHED_RR。SCHED_FIFO(先入先出)调度策略为实时任务提供严格的优先级顺序,任务一旦获得CPU,将持续运行直到完成或被更高优先级任务抢占。SCHED_RR(轮转)在SCHED_FIFO基础上增加了时间片轮转机制,使同一优先级的任务轮流获得CPU时间。RT调度器适用于需要确定性和低延迟的应用,如音视频处理和工业控制系统,通过严格控制任务优先级和调度行为,确保实时任务按时执行;Deadline调度器(DL)专为提供硬实时保障而设计,适用于需要严格执行时间约束的任务。DL调度器根据每个任务的绝对截止时间进行调度,确保任务在其截止时间之前完成。它通过计算和跟踪每个任务的绝对截止时间、相对截止时间和运行时间,动态调整任务的优先级和调度顺序,以满足实时应用的时间约束。DL调度器特别适合关键任务系统,如航空航天和医疗设备中需要确保任务在特定时间内完成的场景(P153)。
- seL4等微内核系统中的Capability机制,会将所有的通信连接抽象成一个个的内核对象。而每个进程对内核对象的访问权限(以及能够在该内核对象上执行的操作)由Capability来刻画。当一个进程企图和某其他进程通信时,内核会检查该进程是否拥有一个Capability,是否有足够的权限访问一个连接对象并且对象是指向目标进程的。类似地,宏内核,如Linux系统,通常会复用其有效用户/有效组的文件权限,以刻画进程对于某个连接的权限。
- Mach通过端口和消息机制实现进程间通信(IPC)。在Mach操作系统中,端口是一种抽象的通信对象,任何进程可以通过持有一个端口的引用来与其通信。消息是端口间传递的数据包,包含了消息头和可选的数据部分。每个端口都有一个消息队列,存储未处理的消息。当一个进程需要与另一个进程通信时,它会向目标端口发送消息。发送消息时,消息被复制到接收方的端口队列中,接收方进程通过从该队列中读取消息来接收数据。消息传递是异步的,发送方不需要等待接收方处理消息,保证了系统的高效性和并发处理能力。Mach的IPC机制提供了灵活性和安全性。进程无法直接访问其他进程的内存空间,必须通过端口和消息进行通信,这种设计增强了系统的安全性。在Mach中,端口不仅可以用于进程间通信,还可以作为消息的一部分进行传递。这种能力使得端口本身成为一种强大的通信机制,可以动态地重构通信路径和权限。当一个进程发送消息时,可以将一个或多个端口的引用包含在消息中,这些端口引用会随着消息一起传递到接收方进程。这意味着接收方进程在接收到消息后,可以获得对这些端口的访问权,从而能够与更多的进程或服务进行通信。(P187)。
- L4微内核操作系统通过高效的进程间通信(IPC)机制传递消息,支持短消息和长消息两种方式。短消息适用于小数据量传递,数据直接加载到CPU寄存器中,通过系统调用发送。这种方式传递过程快速,延迟低,但受寄存器数量和架构限制,只能传递少量数据。长消息则用于传递较大数据量,发送方在消息头中描述待传数据的内存区域,内核将数据从发送方内存拷贝到接收方内存。这一过程虽然开销较大,但能传递大块数据,适用范围广泛。为了进一步优化长消息传递,L4支持消息映射,通过共享内存避免数据拷贝,提高传递效率,同时可以通过权限控制确保安全性。在具体传递流程中,发送方通过系统调用发送消息,内核负责管理消息传递和权限检查,接收方通过系统调用接收消息。L4的IPC机制通过结合短消息和长消息的优势,实现了高效、安全的进程间通信,满足了不同应用场景的数据传输需求(P190)。
- L4的惰性调度是一种延迟调度决策的策略,旨在减少不必要的上下文切换。当一个进程需要等待某个资源(如I/O操作)时,内核并不立即调度其他进程,而是暂时保持当前状态(将其保持在就绪队列中,将其状态改为阻塞),直到确认需要进行上下文切换。这减少了上下文切换的开销,提高了系统效率。直接进程切换则是在两个进程直接通信时进行优化。传统的进程切换通常需要先切换到内核,然后再切换到目标进程,而直接进程切换允许在两个用户进程之间直接切换,跳过内核中转阶段。这不仅减少了切换的开销,还降低了调度延迟,提升了IPC性能(P191)。
- 氏族酋长机制是L4早期版本中的设计,用于组织和管理进程。系统将进程分为若干“氏族”,每个氏族由一个“酋长”管理。氏族内的进程只能通过酋长与外界通信,酋长充当了进程间通信的中介。这种设计增强了安全性,因为所有跨氏族的通信都必须经过酋长的审查和控制,从而确保了权限的有效管理。但由于通信效率较低且灵活性不足,这一机制在后来逐渐被废弃。随着L4的发展,capability机制取代了氏族酋长机制,成为新的进程间通信和权限管理方案。capability是一种包含访问权限的信息对象,进程通过持有capability来访问特定的系统资源或与其他进程通信。这种机制提供了更为细粒度和灵活的权限控制,每个capability都是特定资源的访问凭证,可以安全、有效地在进程之间传递和管理。capability不仅提高了系统的安全性,还增强了通信的效率和灵活性,使得L4在现代操作系统中能够支持复杂的安全策略和资源共享。
- LRPC(轻量级远程过程调用)的迁移线程模型是一种优化进程间通信的方法。传统RPC在调用远程服务时需要频繁上下文切换,导致性能开销较大。LRPC的迁移线程模型通过减少这些上下文切换,显著提高了通信效率。具体实现是当客户端线程发起远程调用时,该线程直接迁移到服务器地址空间执行,完成任务后再返回客户端。这种方式避免了多次线程切换,保持了调用的轻量级特性。迁移线程模型充分利用了同一机器上共享内存的优势,降低了通信延迟和系统资源的消耗,使得进程间通信更加高效和快速(P193)。
- 自旋锁和排号自旋锁都是用于多线程环境中实现同步的锁机制。自旋锁是一种简单的锁类型,它在尝试获取锁时会持续轮询(自旋),直到成功获得锁。这种机制适用于锁持有时间很短的场景,因为自旋可能导致浪费CPU资源,但在锁争用较少时,它能提供较低的延迟。排号自旋锁是一种改进的自旋锁,使用排号机制来减少自旋的浪费。每个线程在请求锁时都会被分配一个排号,并在自旋时只检查自己的排号与当前持锁线程的排号是否匹配。这样可以避免所有线程同时进行自旋,只需要轮询自身的排号,相对减少了竞争带来的开销,提高了效率(P218)。互斥锁可以通过自旋锁实现。
- RCU(Read-Copy-Update)是一种高效的同步机制,适用于读多写少的场景。它允许多个读取者并发访问共享数据而不需要锁,提升了读取性能。RCU 的核心思想是将更新操作与读取操作分离。写操作创建数据的副本,在副本上进行修改,然后在合适的时机替换旧数据。读取操作标记自己处于 RCU 临界区,以确保数据一致性,而无需阻塞写操作。这种机制通过延迟更新和批量处理来实现,既保证了高效的读性能,又在一定程度上优化了写性能(P248)。
- 通常来讲,文件系统层面的操作只允许删除空的目录文件,即目录中只包含“.”和“..”两个目录项。使用“rm -r dir”命令将dir目录以及其下所有文件全都删除时,rm程序会首先遍历要删除的目录,并“自底向上”依次删除遇到的文件,最后才将已经被删空的dir目录删除(P263)。
- 符号链接文件本身的操作和实现并不复杂,但是其对路径解析的过程会产生较大影响。在不考虑符号链接的情况下,从一个路径得到其所代表的文件非常简单与直接:只需在每一层目录中,查找路径里的下一个文件,直到整个路径都被解析完毕,最终得到的文件便是目标文件。然而在支持符号链接的情况下,每解析完路径中的一部分,文件系统都需要判断当前得到的文件是否为符号链接。如果是符号链接,要先跟随符号链接中的路径找到目标文件,再继续解析原路径的剩余部分(P264)。
- inode就是用来记录磁盘块的一种结构。inode是“index node”的简写,即“索引节点”,记录了一个文件所对应的所有存储块号(即存储的索引)。每个inode对应一个文件;通过一个inode,就可以访问这个文件所有的数据。Inode节点前半部分为与文件相关的基本元数据,后半部分为指向文件具体数据块的指针,如下图所示:
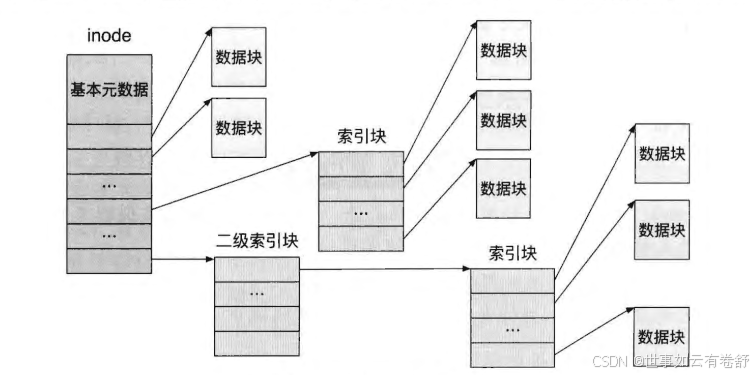
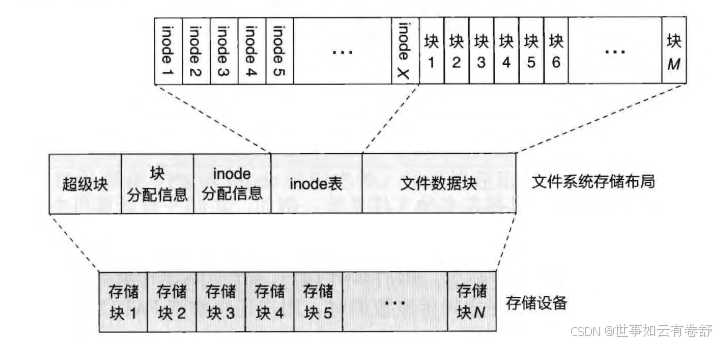
- 一个简单的文件系统布局如下,其中一个存储设备被划分为超级块、块分配信息、inode分配信息、inode表、文件数据块。一般来讲,超级块(super block)是一个文件系统存储布局中必不可少的结构。超级块中记录了整个文件系统的全局元数据。魔数(magic number)是保存在超级块中的比较重要的元数据之一,不同的文件系统通常会使用不同的魔数。通过读取魔数,操作系统可以得知存储设备上文件系统的类型和存储布局。除了魔数之外,超级块中还保存了文件系统的版本、文件系统所管理空间的大小、最后一次挂载时间和一些统计信息等。统计信息中包括文件系统能支持的最大inode 数量、当前空闲可用的inode 数量、能支持的最大的块数量、当前空闲可用的块数量等。在超级块之后,文件系统中存放了块分配信息与inode 分配信息。块分配信息使用位图(bitmap)的格式标记文件数据块区域中各个块的使用情况。块分配信息区域中的每个比特位,对应文件数据块区城中的一个块。若此比特位为1,则表示对应的数据块已经被分配和使用;若为0,则表示对应的数据块空闲。inode 分配信息与块分配信息类似,区别在于其对应的是inode 表中每个inode 的使用情况。inode 分配信息之后的存储空间保存的是inode 表。inode 表以数组的形式保存了整个文件系统中所有的inode 结构。文件系统通常使用inode 在此表中的索引(称为inode 号)对不同 inode进行区分。因此,文件系统中对 inode 的引用只需要使用 inode 号即可,无须保存 inode结构在存储设备中的偏移量。此外,由于inode 表的大小在文件系统创建时已经固定,因此文件系统所能保存的最大文件数量也受此限制。剩余的存储空间为文件数据块区域,用于保存文件的数据。理论上来说,只有文件数据区域被用来存放应用程序的数据。因此在一个存储设备上创建一个新的文件系统后,文件系统显示的可用大小往往比存储设备的总容量小(P265)。
- 在Linux 内核中,读缓存与写缓冲区的功能被合并起来管理,称为页缓存。页缓存以内存页为单位,将存储设备中的存储位置映射到内存中。文件系统通过调用VFS 提供的相应接口对页缓存进行操作。当一个文件被读取时,文件系统会先检查其内容是否已经保存在页缓存中。如果文件数据已保存在页缓存中,则文件系统直接从页缓存中读取数据返回给应用程序;否则,文件系统会在页缓存中创建新的内存页,并从存储设备中读取相关的数据,然后将其保存在创建的内存页中。之后,文件系统从内存页中读取相应的数据,返回给应用程序。在进行文件修改时,文件系统同样会首先检查页缓存。如果要修改的数据已经在页缓存中,文件系统可以直接修改页缓存中的数据,并将该页标记为脏页;若不在页缓存中、文件系统同样先创建页缓存并从存储设备中读取数据,然后在页缓存中进行修改并标记该页为脏页。标记为脏页的缓存会由文件系统定期写回到存储设备中。当操作系统内存不足或者应用程序调用fsync时,文件系统也会将脏页中的数据写回到存储设备中(P279)。
- 内存映射mmap(P280);linux中VFS的文件挂载mount(P281);FAT32文件系统(P284);NTFS文件系统(P288);
- 伪文件系统是一种通过软件模拟出来的文件系统,不实际存在于物理存储介质上,并没有保存文件数据,主要用于提供统一接口来访问系统信息、内核数据结构或虚拟资源。这类文件系统在类linux系统中尤为常见,主要用于提供系统信息和控制接口。一个典型的例子是procfs(/proc),它提供了一个接口,通过读取和写入文件来获取和控制内核和系统进程的信息,/proc中的文件和目录不是存储在磁盘上的,而是由内核在内存中动态生成的。例如,通过读取/proc中的文件,可以获取CPU信息、内存状态和进程列表等系统数据。另一个例子是sysfs(/sys),用于提供访问和管理设备和驱动程序信息的接口。sysfs将设备和内核模块的属性以文件和目录的形式呈现,方便用户和应用程序进行交互。总的来说,伪文件系统简化了系统信息的获取和管理,使得用户和开发者可以通过熟悉的文件操作接口与复杂的系统内部结构进行交互(P282)。
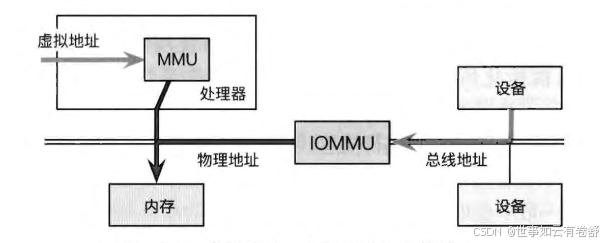
- 总线地址、虚拟地址和物理地址是计算机系统中不同层次的地址。总线地址是用于设备之间通信的地址,由总线控制器管理,设备通过总线地址访问内存和I/O设备。虚拟地址是由操作系统提供的抽象地址空间,每个进程有独立的虚拟地址空间,程序通过虚拟地址访问内存,虚拟地址通过内存管理单元(MMU)转换为物理地址。物理地址是内存芯片上的实际地址,表示数据在物理内存中的位置。总线地址用于硬件通信,虚拟地址用于进程内存管理,物理地址用于实际内存访问。在大多数情况下,处理器上执行的操作系统代码在进行内存访问时使用的是虚拟地址(virtual address),并通过MMU 翻译成物理地址(physical address)。设备进行 DMA时访问的内存地址是总线地址(bus address),其不同于虚拟地址和物理地址(P303)。如下图:
- 设备树(Device Tree,DT)和高级配置与电源接口(Advanced Configuration and Power Interface,ACPI)是用于描述计算机硬件的两种不同的机制。它们的主要功能都是向操作系统提供硬件配置信息,但实现方式和使用场景有所不同。设备树最初由Open Firmware项目引入,现在广泛应用于嵌入式系统和非x86架构,尤其是ARM架构。在设备树中,硬件的描述以树状结构组织,根节点代表系统本身,子节点表示各个硬件设备。每个节点包含设备的属性和参数,以键值对的形式表示。设备树通常在系统启动时由引导加载程序(bootloader)传递给操作系统,使操作系统能在不依赖固件的情况下获取硬件信息。设备树的设计目标是提供一种简单、灵活且硬件无关的硬件描述方法,便于移植和扩展。设备树涉及的文件主要包括以下几种:.dts 文件:设备树源文件(Device Tree Source),使用人类可读的文本格式定义硬件描述。它以树状结构组织各个设备的属性和参数;.dtsi 文件:设备树源包含文件(Device Tree Source Include),用于存放共享的硬件描述,类似于C语言的头文件,可以在多个.dts文件中包含;.dtb 文件:设备树二进制文件(Device Tree Blob),由.dts文件编译而成,以二进制格式存储,供引导加载程序和操作系统使用;Makefile 文件:用于定义编译.dts和.dtsi文件生成.dtb文件的规则和过程,通常由开发人员编写并维护。ACPI是由英特尔、惠普、东芝、微软和凤凰科技公司共同开发的一种接口标准,主要应用于x86架构的个人计算机。ACPI不仅提供硬件配置信息,还管理电源和热量,支持高级电源管理(APM)功能。ACPI使用描述表(如DSDT,Differentiated System Description Table)来定义系统硬件和电源管理功能,这些表格通常存储在系统固件中(如BIOS或UEFI)。操作系统通过读取和解析这些表格来获取硬件信息并执行相应的电源管理操作。ACPI的一个重要特点是其支持动态配置和热插拔设备管理,能在系统运行过程中检测和配置新设备。两者的主要区别在于应用场景和实现方式。设备树通常用于嵌入式系统和ARM架构,强调简单和灵活性,硬件描述信息由引导加载程序传递。而ACPI主要用于x86架构的个人计算机,强调高级电源管理和热插拔功能,硬件描述信息存储在系统固件中,具有更复杂的结构和功能。此外,设备树是静态的,启动时由引导加载程序加载后不可更改,而ACPI支持动态配置,系统运行过程中可以响应硬件变化(P305)。
- Linux 的中断处理机制被分为上半部分(Top Half)和下半部分(Bottom Half),这种分离的设计旨在提高系统的中断响应速度和处理效率。上半部分负责快速响应和处理中断的关键部分,而下半部分则处理较复杂或耗时的任务,以减少中断处理对系统性能的影响。当硬件设备产生中断时,处理器会停止当前的执行流程,转而执行相应的中断服务例程(ISR)。这个中断服务例程的执行即为上半部分。上半部分的主要任务是尽快响应中断,执行必要的硬件操作,如读取硬件寄存器以确定中断源、清除中断信号以防止重复触发,并进行一些简单的处理。由于上半部分在执行过程中会禁用其他中断,因此其处理时间必须尽可能短,以避免长时间禁用中断对系统响应时间的负面影响。然而,某些中断处理任务可能较为复杂,耗时较长,若全部在上半部分处理,会导致系统长时间处于中断禁用状态,影响系统性能。为了解决这一问题,Linux 设计了下半部分机制,将这些复杂或耗时的任务延迟到中断上下文之外处理。在上半部分执行完关键的快速响应任务后,会将剩余的工作安排给下半部分执行。下半部分有多种实现方式,包括软中断(SoftIRQ)、任务队列(Tasklet)和工作队列(Workqueue)。软中断是一种用于处理高优先级任务的下半部分机制,通常用于网络和块设备等需要快速处理的大量数据的场景。任务队列是基于软中断的一种轻量级机制,适合处理稍低优先级的任务。而工作队列则是一种将下半部分任务放入内核线程执行的机制,适合更长时间的任务处理,可以在不同的CPU上调度执行。通过将中断处理任务分为上半部分和下半部分,Linux 内核实现了高效的中断处理机制。上半部分快速响应中断并进行初步处理,确保中断不会长时间阻塞系统,而下半部分则在更安全的环境中完成剩余的工作。这样的设计不仅提高了系统的中断响应速度,还保证了系统的整体性能和稳定性,特别是在多任务和实时操作系统中尤为重要。这种分离的处理方式,使得Linux能高效应对各种复杂的中断处理需求,维持系统的高效运行(P313)。
- 在Linux中,主设备号和次设备号是用于标识和管理设备文件的两个重要标识符。它们用于区分不同类型的设备和设备的不同实例,从而实现对设备的有效管理和访问。主设备号用于标识设备的类型或设备驱动程序。每个设备驱动程序都有一个唯一的主设备号,这个号码告诉内核使用哪个驱动程序来处理对该设备文件的操作。例如,所有的磁盘设备可能共享一个主设备号,而所有的终端设备可能共享另一个主设备号。通过主设备号,内核可以找到相应的设备驱动程序入口点,从而处理具体的设备操作。次设备号用于标识同一类型设备的不同实例。它在同一主设备号范围内区分不同的设备。例如,对于同一个磁盘驱动程序,可以通过不同的次设备号来区分不同的磁盘或磁盘分区。次设备号通常由设备驱动程序自行管理,用于标识和操作具体的设备实例(P316)。
- Linux设备驱动模型通过kobject、kset和ktype构建了一个灵活且可扩展的框架,用于管理系统中的各种设备和驱动程序。kobject是内核中的基本对象类型,负责对象的引用计数、生命周期管理和在sysfs中的表示。每个kobject具有名称、父指针、引用计数和类型指针。kset是相关kobject的集合,用于组织和管理一组内核对象,通过包含所有kobject的链表和自身的kobject,在sysfs中创建相应目录。ktype定义了kobject的类型及其相关操作,包括释放函数、sysfs读写操作和默认属性数组。Linux设备驱动模型中的层次结构包括设备(device)、总线(bus)、驱动程序(driver)和类(class)。设备代表具体的硬件设备,总线代表系统中的总线类型,驱动程序代表设备驱动,类代表一组具有相似属性的设备。通过这些结构,Linux设备驱动模型实现了对系统设备的层次化管理和操作,支持动态设备管理和系统监控(P319)。
- /sys 目录及其支持的 sysfs 文件系统(虚拟文件系统)在 Linux 中起到了桥梁作用,使内核对象在用户空间可视化并可操作。sysfs 提供一个统一的接口,使用户空间应用能够访问和操作内核对象,包括设备、驱动程序、总线等。通过 /sys 目录,系统中的所有设备及其关系得以展示,用户可以查看设备的详细信息,如属性、状态和配置,并进行动态管理。sysfs 文件系统允许通过读取和写入文件来查看和配置内核对象的属性,使得设备参数和内核设置可以灵活调整。这种机制为系统的调试和监控提供了便利,开发者和管理员可以通过 sysfs 获取系统状态信息,从而进行性能优化和故障排查。/sys 目录中的文件与内核对象 kobject 密切相关。/sys 是 sysfs 文件系统的挂载点,sysfs 通过 kobject 提供一个用户空间接口,使用户能够访问和操作内核对象。每个 kobject 在 sysfs 中映射为一个目录,这个目录的名字通常是 kobject 的名字。目录下的文件代表 kobject 的属性,通过读取或写入这些文件,用户可以查看或修改内核对象的属性值。kobject 是内核对象的基础,提供引用计数和生命周期管理功能。通过 kobject 的层次结构,sysfs 中的目录结构反映了内核对象的关系。例如,一个 kobject 的子对象在 sysfs 中会显示为父对象目录下的一个子目录。这种层次结构使用户能够直观地浏览和理解内核对象的组织方式。在 Linux 的设备和驱动模型中,kobject 是设备、驱动和总线等结构的基础。设备文件位于 /sys/devices 目录下,驱动文件位于 /sys/bus 目录下,分别对应具体的设备和驱动程序。这些文件和目录不仅提供了内核对象的状态信息,还允许用户动态管理和配置系统设备(P321)。
- L4的设备驱动环境(DDE)是一种框架,旨在简化设备驱动程序在L4微内核上的开发和移植。DDE通过提供与传统操作系统(如Linux或BSD)相似的API,使现有驱动程序代码可以在最少修改的情况下移植到L4系统上。这种用户态驱动模型使驱动程序运行在用户空间,通过L4内核的高效进程间通信(IPC)机制与硬件交互。DDE提供必要的库和工具,支持这种通信并确保驱动程序与L4内核的高效交互。同时,DDE为开发者提供丰富的调试和测试工具,如日志记录、错误报告和性能分析工具,帮助提高驱动程序的质量和可靠性。模块化设计使驱动程序独立于核心系统,增加了系统的稳定性,因为驱动程序的错误不会直接影响内核。这种设计简化了开发过程,提高了系统的安全性和稳定性(P322)。
- 用户空间I/O和虚拟功能I/O(P325)。
- CP/CMS是1960年代由IBM开发的一种操作系统,专为大型计算机设计。它由CP(Control Program)和CMS(Conversational Monitor System)构成。CP是虚拟机监视器,创建并管理多个虚拟机,使每位用户可以在虚拟机中运行自己的操作系统实例。CMS是运行在每个虚拟机上的单用户操作系统,提供便捷的交互界面和基本功能,如文件管理与程序开发。CP/CMS通过虚拟化技术实现了资源共享和用户隔离,提高了硬件利用率,是现代虚拟化技术的先驱,其概念对后来的计算机技术发展产生了重要影响。
- 虚拟机管理程序(VMM)和虚拟机监视器(hypervisor)都是虚拟化技术中的核心概念,虽然它们常常被互换使用,但在具体技术讨论中有细微区别。Hypervisor 是一种软件、固件或硬件,它的主要功能是创建和运行虚拟机(VM),并直接与物理硬件交互,从而将硬件资源分配给各个虚拟机。Hypervisor 分为两种类型:Type 1(裸金属 hypervisor)直接运行在物理硬件上,如 VMware ESXi、Microsoft Hyper-V 和 Xen;Type 2(托管 hypervisor)则运行在现有操作系统上,作为该操作系统的一个应用程序,如 QEMU、VMware Workstation 和 Oracle VirtualBox。VMM(Virtual Machine Monitor)通常指实现虚拟化功能的核心组件,它专注于管理虚拟机的执行、资源分配和调度等具体任务。VMM 可以被看作是 hypervisor 的一部分,具体处理虚拟机的运行状态、资源调度、状态保存与恢复等。在许多文献中,VMM 和 hypervisor 可能会被互换使用,因为它们都涉及到虚拟机的管理。然而,hypervisor 通常是一个更广泛的概念,涵盖整个虚拟化平台,包括虚拟机管理和其他辅助工具和服务,而 VMM 仅指虚拟机管理的具体实现部分。
- 系统虚拟化技术主要包含三方面,即CPU虚拟化、内存虚拟化和IO虚拟化。 CPU虚拟化:指为虚拟机提供虚拟处理器(virtual CPU,vCPU)的抽象并执行其指令的过程。虚拟机监控器直接运行在物理主机上,使用物理ISA,并向上层虚拟机提供虚拟ISA。虚拟ISA可以与物理主机上的ISA相同,也可以完全不同。如果两者相同,虚拟机中的大多数指令可以在物理主机上直接执行,只有少数敏感指令需要特殊对待,因此具有较好的性能;如果两者不同,虚拟机中的每一条指令都必须通过虚拟机监控器进行软件模拟,翻译成对应物理主机上的指令。内存虚拟化:指为虚拟机提供虚拟的物理地址空间。在虚拟化环境中,虚拟机监控器负责管理所有物理内存,但又要让客户操作系统“以为”自己依然能管理所有物理内存。为此,虚拟机监控器引入了一层新的地址空间——“客户物理地址”,与真实的物理地址相区别;并提供一种翻译机制,将虚拟机中“假”的物理地址翻译成“真”的物理地址。I/O 虚拟化:指为虚拟机提供虚拟的I/O 设备支持。在虚拟化环境中,虚拟机监控器负责管理所有的I/O设备,客户操作系统所管理的仅仅是虚拟机监控器所提供的虚拟设备;虚拟机监控器需要将对虚拟设备的访问映射成对物理设备的访问(P331)。
- 下陷(trapping)和模拟(emulation)是虚拟化技术中的关键机制。下陷指的是当虚拟机执行特权指令时,硬件自动将控制权转移到虚拟化管理程序 ,以确保虚拟机无法直接访问或修改硬件资源,从而保持系统的隔离性和安全性。这个过程包括检测特权指令、产生异常、由hypervisor处理指令并返回控制权。模拟则是通过软件完全模仿硬件行为,使得代码在没有实际硬件支持的情况下运行。模拟软件逐条解释虚拟机中的指令,生成相应的硬件行为,确保虚拟机如同在真实硬件上运行一样。模拟用于跨平台兼容性和在开发测试中提供一致的环境(P333)。
- 敏感指令是管理系统物理资源或更改CPU状态的指令,而特权指令在用户态执行时会触发下陷。可虚拟化架构的特点是所有敏感指令都是特权指令,执行时会触发下陷,从而允许虚拟机监控器完全捕捉客户操作系统的行为。在虚拟机中,用户态程序操作的是虚拟寄存器,这些操作通常直接在虚拟机中完成,不需要每次都经过虚拟机监控程序(VMM),这可以提高性能。在许多现代处理器中,虚拟寄存器的值可以通过硬件虚拟化支持实时映射到物理寄存器,这种映射通常在虚拟机执行过程中自动完成。
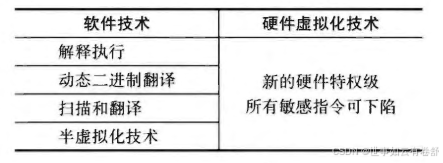
- 弥补不可虚拟化架构缺陷的五中方法:解释执行:解释执行是一种通过软件模拟来弥补不可虚拟化架构缺陷的方法。虚拟机监控程序(VMM)逐条解释并执行虚拟机中的指令,而不是直接在硬件上执行。这样可以捕获和处理所有敏感指令,但由于解释每条指令的开销较大,性能往往较低;动态二进制翻译:动态二进制翻译通过在运行时将虚拟机中的指令转换为等效的、可以安全执行的宿主机指令。VMM动态分析和翻译敏感指令,避免了直接执行这些指令带来的问题。这种方法在提高性能的同时,确保了敏感指令的正确处理,但实现复杂度较高;扫描和翻译:扫描和翻译方法在虚拟机代码执行前,对其进行静态分析,识别和翻译敏感指令(将其替换为会触发下陷的特权指令)。这样可以在运行前解决敏感指令的问题,避免运行时的性能开销。然而,静态分析可能不够准确,且对动态生成的代码无效。由于敏感指令只可能存在于操作系统内核的代码中,用户态通常不会包含这样的指令,因此可只扫描内核代码而忽略所有用户进程的代码,从而进一步提高性能;半虚拟化:半虚拟化通过修改虚拟机操作系统,使其直接调用VMM提供的接口(即超级调用hypercall)来执行敏感操作。这种方法避免了对敏感指令的捕获和处理,但需要对操作系统进行修改,并且只能在支持半虚拟化的操作系统上使用;硬件虚拟化(需要宿主机和虚拟机有相同的ISA):硬件虚拟化通过处理器的虚拟化扩展来直接支持敏感指令的虚拟化。处理器提供额外的硬件支持,如Intel VT-x和AMD-V,使得虚拟机可以在硬件层面安全执行敏感指令,大幅提高了虚拟化性能和兼容性,且无需修改操作系统。当物理主机的ISA和虚拟机的ISA不同时,不能使用硬件虚拟化技术(P336)。
- 内存虚拟化:为每台虚拟机提供从零开始连续增长的物理地址空间,实现虚拟机之间的内存隔离,每台虚拟机只能访问分配给它的物理内存区域。客户虚拟地址(Guest Virtual Address,GVA):是指在虚拟机操作系统(客户操作系统)中使用的地址空间,虚拟机的应用程序和操作系统使用这些地址来访问内存。客户物理地址(Guest Physical Address,GPA):是指在虚拟机中被认为是物理内存的地址空间,这些地址由客户操作系统管理并用于访问虚拟机内部的内存资源。主机物理地址(Host Physical Address,HPA):是指宿主机硬件实际使用的物理内存地址。两阶段地址翻译:在虚拟化环境中,客户虚拟地址首先通过虚拟机内部的内存管理单元(MMU)映射到客户物理地址,再由虚拟机监控程序(VMM)进一步映射到实际的主机物理地址。
- 非虚拟化时的页表配置流程:在ARMv8架构中,页表配置包括几个关键阶段(ARMv8通常是四级页表)。首先,初始化页表结构,为各级页表(L0-L3)分配内存并设置初始状态。然后,配置各级页表项,每个页表项包含物理地址、访问权限和缓存属性等信息,逐级映射虚拟地址空间到物理内存。接下来,设置Translation Table Base Register (TTBR),即TTBRO_EL1寄存器,它指向L0页表的基地址,告诉处理器从哪里开始查找虚拟地址的映射。随后,启用内存管理单元(MMU),激活页表的映射功能。最后,当处理器访问内存时,通过MMU逐级查找页表,将虚拟地址转换为物理地址。
- 影子页表是一种用于虚拟化技术中的内存管理机制。它在虚拟机监控器(VMM)或虚拟化层中维护,目的是让虚拟机能够透明地使用内存管理单元(MMU),就像在物理硬件上一样。虚拟机本身维护自己的页表,但这些页表映射的虚拟地址并不直接与物理内存对应,即只将客户虚拟地址映射到客户物理地址。相反,VMM 使用影子页表来将虚拟机的客户虚拟地址翻译为实际的主机物理地址。虚拟机监控器需要为每个虚拟机维护一个地址转换表(其中记录了客户物理地址到主机物理地址的映射关系),虚拟机监控器遍历客户操作系统需要安装的页表,并根据表中的内容创建一个影子页表,其内容与客户操作系统的页表一一对应,只是将客户物理地址改写成主机物理地址,影子页表最终包含了客户虚拟地址到主机物理地址的映射关系(P344)。随后虚拟机监控器通过配置影子页表,将原页表所在的内存设置为只读权限,并将影子页表的主机物理地址写入TTBR0_EL1寄存器中,然后恢复虚拟机的执行。这样一旦发生缺页异常,首先会下陷到内核态并唤醒虚拟机监控器注册的缺页处理函数,然后根据缺页原因进行相应处理。
- 直接页表映射:在这种机制下,虚拟机“知道”自己运行在虚拟机监控器之上,直接页表映射通过硬件(如内存管理单元,MMU)自动维护页表,将虚拟地址直接映射到物理地址,这种情况下就不需要客户物理地址了。处理器通过查找页表中的页表项,确定虚拟页面对应的物理页面。为了方便客户操作系统配置页表映射,虚拟机监控器需要告知虚拟机允许使用的主机物理地址范围。直接页表映射机制将虚拟机的页表页设置为只读权限,从而阻止虚拟机直接修改页表页,虚拟机必须使用虚拟机监控器提供的超级调用接口对页表页进行修改,在接收到超级调用请求后,虚拟机监控器将检查此次需要添加或修改的映射是否合法,例如是否使用了其他虚拟机的主机物理地址(P346)。
- 影子页表和直接页表映射都是在系统中只有一个页表时使用的方法,当系统中有两个页表时可以直接采用两阶段地址翻译,也就是通过硬件虚拟化技术实现内存虚拟化,具体参考P349。
- 内存气球(Balloon Driver)是一种虚拟化技术,通过动态调整虚拟机内存使用来优化资源分配。其原理基于虚拟机内部的气球驱动程序,模拟一个虚拟内存设备。该驱动程序会根据虚拟化管理程序(Hypervisor)的指示,调整虚拟机的内存占用。当虚拟化管理程序需要回收物理内存时,它会通知气球驱动程序,使其“膨胀”,即占用更多虚拟内存,这会迫使虚拟机操作系统将这些内存标记为不可用,从而释放出实际的物理内存返回给虚拟化管理程序。相反,当虚拟机需要更多内存时,气球驱动程序会“收缩”,释放之前占用的虚拟内存块,增加虚拟机的可用内存。通过这种动态调整,内存气球机制帮助虚拟化环境实现高效的内存管理,优化资源利用,避免内存浪费。
- I/O虚拟化有三种方式——软件模拟、半虚拟化和设备直通。软件模拟方法通过虚拟机管理程序(如QEMU)完全模拟I/O设备的行为,直接作用于机器指令层,使得虚拟机可以在无需修改操作系统源代码的情况下运行。这种方法兼容性强,能够支持广泛的操作系统和硬件设备,但由于所有I/O操作都由软件处理,导致性能较低且资源消耗较大;半虚拟化方法通过在虚拟机内的操作系统中引入特定的驱动程序,使得I/O操作能够直接与虚拟机管理程序通信,从而减少模拟开销,提升性能。虽然半虚拟化提高了I/O操作的效率,使其性能接近原生硬件,但这种方法要求对操作系统进行修改,并且通常依赖于特定的虚拟化平台,因此其灵活性和兼容性相对较差;设备直通方法允许虚拟机直接访问物理I/O设备,通过硬件支持(如IOMMU)将物理设备映射到虚拟机。此方法提供了几乎与原生硬件相同的性能和低延迟,非常适合对I/O性能要求极高的应用场景。然而,设备直通对硬件有较强的依赖性,同时会使物理设备独占,无法被其他虚拟机或主机系统共享,且配置复杂度较高。总的来说,这三种方法各有侧重,适合不同的虚拟化环境和性能需求(P355)。
- 中断虚拟化是一种在虚拟化环境中管理硬件中断的技术,通过捕获和重定向中断,使多个虚拟机能够正确响应硬件事件。它涉及将中断有效分发到合适的虚拟CPU,并依赖现代处理器的硬件支持(如Intel VT-x/VT-d、AMD-V)来加速中断处理。中断虚拟化通过减少延迟和干扰,提升了虚拟化平台的性能和稳定性,尤其在高负载环境中至关重要。
- 可信计算基(Trusted Computing Base,TCB),是指“为实现计算机系统安全保护的所有安全保护机制的集合”, 这里的机制包括了软件、硬件和固件等所有与计算机直接相关的组成部分。 TCB是一个人为定义的概念,首先确定“安全保护”的目标,然后确定系统中对该目标有影响的组件和机制的集合,即为 TCB;换句话说, TCB 之外的组件即使受到攻击或被攻击者完全控制,也不会对安全目标产生影响。
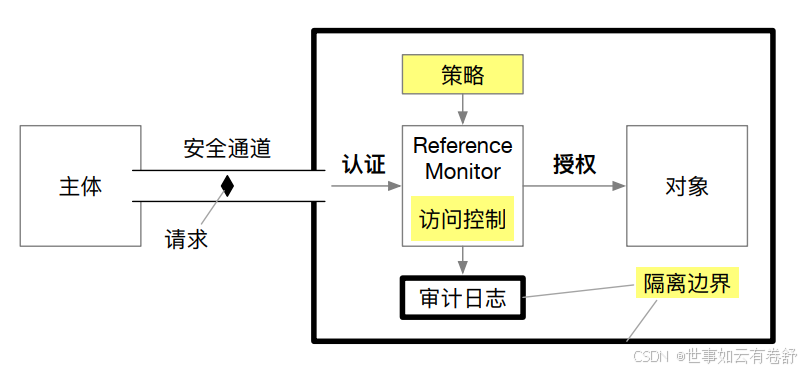
- 引用监视器(Reference Monitor)是实现访问控制的一种方式,该机制的思路是:将主体与对象隔开,即不允许主体直接访问对象,而是必须通过引用(reference)的方式间接访问。引用监视器位于主体和对象之间,负责将来自主体的访问请求应用到对象。通过增加这层抽象,系统能够保证所有请求必须都经过引用监视器,因此可以在这一层进行访问控制。具体来说,引用监视器首先认证主体的身份,然后根据预设的策略,判断主体是否有权限访问对象,并选择允许或拒绝,同时将所做的选择记录到审计日志中。具体架构下图所示:
- 自主访问控制(Discretionary Access Control,DAC),是指一个对象的拥有者有权限决定该对象是否可以被其他人访问。例如,文件系统就是一类典型的DAC,因为文件的拥有者可以设置文件如何被其他用户访问。换句话说,DAC允许一个普通用户配置其所拥有的对象的访问权限。强制访问控制(Mandatory Access Control,MAC)则与DAC相对,即一个对象的拥有者不能决定该对象的访问权限,什么数据能被谁访问,完全由底层的系统决定。例如,在军用的计算机系统中,如果某个文件设置为机密,那么就算是指挥官也不能把这个文件给没有权限的人看——这个规则是由军法(系统)规定的,任何人,包括通讯员(普通用户)和指挥官(特权用户)也不能违反。
- Bell-La Padula强制访问控制模型(BLP):BLP是一个用于访问控制的状态机模型,设计的目的是为了用于政府、军队等具有严格安全等级的场景,是一种典型的MAC设计。BLP规定了两条MAC规则和一条DAC规则,一共三个主要的属性:简单安全属性(Simple Security Property):某个安全级别的主体无法读取更高安全级别的对象;*属性(Star Property,星属性):某一安全级别的主体无法写入任何更低安全级别的对象;自主安全属性(Discretionary Security Property):使用访问矩阵来规定自主访问控制(DAC)。因此,BLP仅允许数据从低机密程度的对象向高机密程度的对象流动,这种策略也可以简称“下读,上写”。具体可参考《现代操作系统第十六章》。
- Flask是一个OS的安全架构,能够灵活地提供不同的安全策略。Flask的全称是“Flux Advanced Security Kernel”,由Utah大学、美国NSA和SCC公司7共同开发。1995年,该架构开始在Mach(Utah版本)上进行开发,一年后转移到了一个名为Fluke(Utah开发)的研究性微内核操作系统上,后来移植到许多不同的操作系统框架中,包括OSKit、BSD、OpenSolaris和Linux。然而,Flask的架构需要对内核进行大量的修改,尤其要在很多关键操作处进行权限检查,而Linux当时的模块框架无法支持Flask以模块的方式实现。为此,Linux社区在2002年提出了LSM(Linux Security Modules)项目,在内核的关键代码区域插入了许多hook,包括在所有系统调用即将访问关键内核对象(如inode或task control block)之前,这些hook会调用模块实现的函数(即upcall),进行访问控制、安全等检查。在Linux上基于Flask实现的LSM模块,就是SELinux。

















10-24
 1977
1977
1977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









