






目录
1、指针和指针变量
指针和指针变量是两个重要的概念,但它们有时会被混淆。
指针
“指针”是一个广义的概念,它表示一个值,该值存储了另一个变量在内存中的地址。简单来说,指针就是一个地址的引用。在内存中,每个变量都有一个唯一的地址,这个地址可以被一个指针所持有。
指针就是地址,地址就是指针。
地址就是内存单元的编号。
指针变量
“指针变量”是一个特殊的变量,它存储了一个指针(即一个地址)。因此,指针变量本身也是一个变量,但它存储的不是一般的数据值,而是另一个变量的内存地址。
指针变量就是用来存储内存地址的变量。

在计算机中,内存被划分为许多小的内存单元,每个内存单元大小是1个字节,每个内存单元都有一个唯一的编号,这个编号就是该内存单元的地址。地址是计算机用来识别和操作内存单元的重要依据。
当我们定义一个变量时,操作系统会为这个变量分配一个内存地址,并将这个地址与变量名关联起来。这样,我们就可以通过变量名来访问和操作该变量在内存中的值。而实际上,当我们使用变量名时,编译器会将其转换为对应的内存地址,然后通过这个地址来访问和操作内存中的数据。
通过指针变量,我们可以直接访问和操作内存中的数据,实现一些高级的功能,如动态内存分配、链表、树等数据结构的操作等。但是,使用指针时也需要特别小心,因为错误的指针操作可能会导致程序崩溃或数据损坏。
2、指针变量的定义和使用
1.指针也是一种数据类型,指针变量也是一种变量
2.指针变量指向谁,就是把谁的地址赋值给指针变量
3.* 符号与指针相关时,确实有两种主要的含义:
-
声明时的类型说明符:
在声明指针变量时,*用作类型说明符的一部分,表示该变量是一个指针,指向某种类型的数据。例如,在int *p;中,*p并不是一个整体,*是与int一起构成一个类型说明符int*,表示p是一个指向整型的指针。 -
解引用或间接访问运算符:
当*用在指针变量前面时,它作为一个解引用或间接访问运算符,用于获取指针所指向的数据的值。例如,在*p = 99;中,*p表示指针p所指向的内存位置的值,这里我们将该值设置为99。
- 在声明时,
*紧接在类型之后,并与类型一起构成一个完整的类型说明符。 - 在解引用时,
*单独出现在指针变量前面,用于获取指针所指向的值。


3、核心观点
指针和指针变量
- 指针:是一个抽象的概念,它表示内存中的一个地址。这个地址指向一个特定的内存位置,该位置可以存储某种类型的数据。
- 指针变量:是一个特殊的变量,它的值是一个地址(即指针)。通过指针变量,我们可以间接地访问和操作它所指向的内存位置中的数据。
重要提示:指针变量和它所指向的内存位置是两个不同的概念。指针变量存储的是地址,而该地址处的内存则存储着实际的数据。
变量的值
- 普通变量的值:对于非指针类型的变量(如整型、浮点型、字符型等),它们存储的是实际的数据值。
- 指针变量的值:指针变量存储的是一个地址,这个地址指向了另一个内存位置,该位置存储着实际的数据。
指针的定义
- 地址:在计算机中,内存被组织成一系列连续的存储单元,每个存储单元都有一个唯一的编号,这个编号就是该存储单元的地址。
- 地址范围:在32位系统中,地址空间通常是4GB(从0到2^32-1),但实际的可用内存可能会少于这个数值。在64位系统中,地址空间更大。
4、指针的分类
指针可以根据它们所指向的数据类型进行分类。例如:
- 整型指针:指向整型数据的指针。
- 浮点型指针:指向浮点型数据的指针。
- 字符型指针:指向字符型数据的指针,常用于字符串操作。
- 结构体指针:指向结构体数据的指针。
- 函数指针:指向函数的指针,可以用于函数调用和回调等。
- 数组指针:指向数组首元素的指针,通过它可以访问数组中的元素。
- 空指针:不指向任何有效内存地址的指针,通常被初始化为NULL。
- 野指针:指向无效内存地址的指针,使用野指针可能导致程序崩溃或数据损坏。为了避免野指针,应该在使用指针前确保它已经被正确地初始化或赋值。
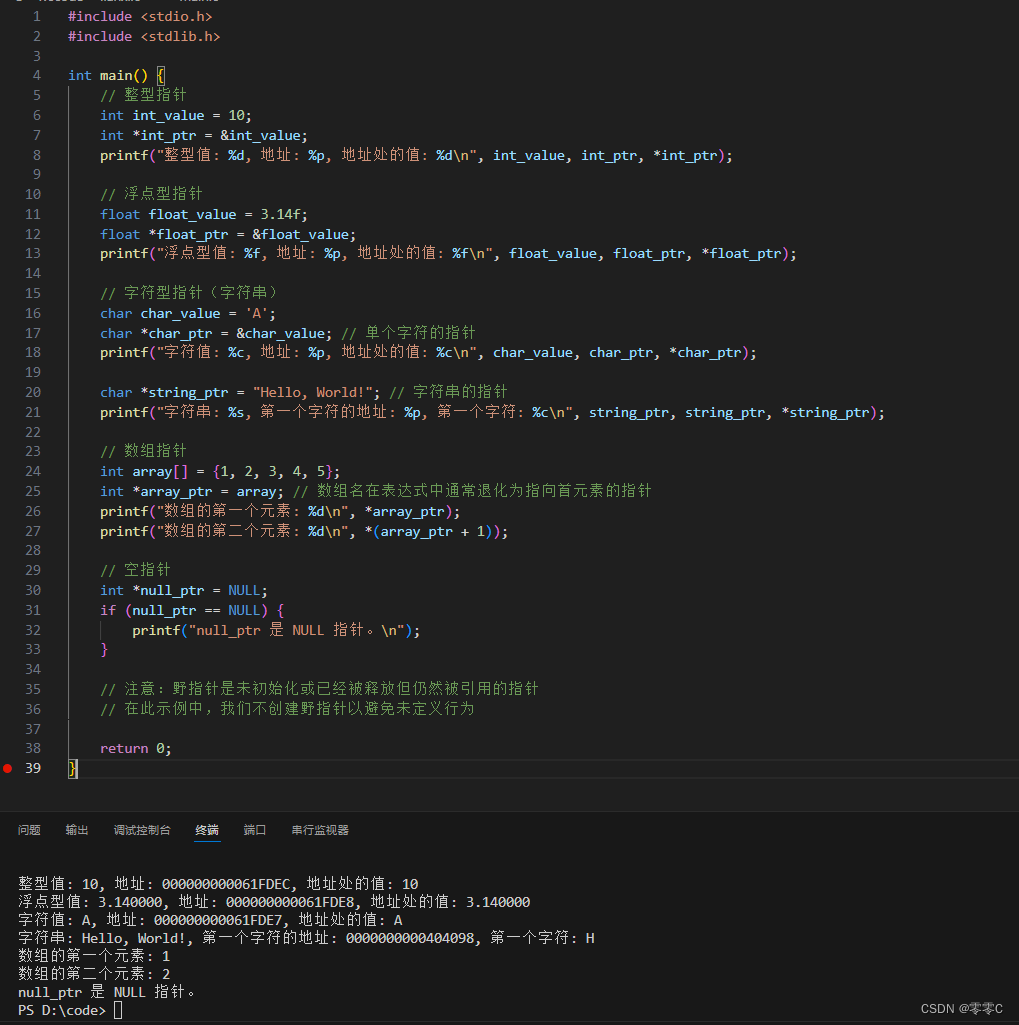
5、空指针和野指针
空指针和野指针是C语言编程中两个重要的概念,它们都与指针的状态和行为有关。
空指针是一个特殊的指针值,它不指向任何有效的内存地址。在C语言中,空指针通常被设置为NULL。
野指针是指已经被释放(如通过free函数)或者从未被正确初始化,但仍然被引用的指针。野指针指向的内存区域可能已经不属于该程序,或者已经被分配给其他变量,因此使用野指针可能会导致程序崩溃、数据损坏或安全漏洞。

简单认识malloc函数
malloc是一个库函数,用于在堆(heap)上动态地分配内存。这个函数是stdlib.h头文件的一部分。malloc接受一个参数,即要分配的字节数,并返回一个指向所分配内存的指针。如果内存分配失败,malloc将返回NULL。
以下是一个使用malloc分配内存的简单示例:

在这个示例中,我们首先使用malloc函数分配了一个足够存储int类型数据的内存块,并将返回的指针存储在ptr中。然后,我们检查ptr是否为NULL,以确保内存分配成功。如果成功,我们设置ptr指向的内存中的值为42,并打印这个值。最后,我们使用free函数释放了分配的内存,并将ptr设置为NULL,以避免成为野指针。
注意,在调用free之后,指针本身的值(即内存地址)并没有改变,但指针所指向的内存区域已经被标记为可用,可以被操作系统重新分配给其他部分的程序。因此,在释放内存后,应该立即将指针设置为NULL,以防止在后续代码中误用该指针。
6、指针的大小
- 32位系统:在32位系统上,一个指针的大小通常是32位(4字节)。这意味着指针可以存储一个32位的内存地址。
- 64位系统:在64位系统上,一个指针的大小通常是64位(8字节)。这意味着指针可以存储一个64位的内存地址。
然而,这并不意味着在64位系统上所有的指针都是64位的。在某些情况下,例如当使用特定的编译器选项或特定的内存模型时,指针的大小可能会有所不同。此外,某些特殊类型的指针(如函数指针或指向特定类型对象的指针)的大小也可能与常规指针不同。

这段代码将打印出在你的系统上int*类型指针的大小(以字节为单位)。















 755
755

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









