







- SQL注入,是从正常的 WWW 端口访问,而且表面看起来跟一般的 Web 页面访问没什么区别,如果管理员没查看日志的习惯,可能被入侵很长时间都不会发觉。
如何过滤与预防?
数据库网页端注入这种,可以考虑使用 nginx_waf 做过滤与预防。
Shell
本小节为选读。我也不太会写 Shell 脚本,都是写的时候,在网络上拼拼凑凑。。。
Shell 脚本是什么?
一个 Shell 脚本是一个文本文件,包含一个或多个命令。作为系统管理员,我们经常需要使用多个命令来完成一项任务,我们可以添加这些所有命令在一个文本文件(Shell 脚本)来完成这些日常工作任务。
什么是默认登录 Shell ?
在 Linux 操作系统,"/bin/bash" 是默认登录 Shell,是在创建用户时分配的。
使用 chsh 命令可以改变默认的 Shell 。示例如下所示:
## chsh <用户名> -s <新shell>
## chsh ThinkWon -s /bin/sh
在 Shell 脚本中,如何写入注释?
注释可以用来描述一个脚本可以做什么和它是如何工作的。每一行注释以 # 开头。例子如下:
#!/bin/bash
## This is a command
echo “I am logged in as $USER”
语法级
可以在 Shell 脚本中使用哪些类型的变量?
在 Shell 脚本,我们可以使用两种类型的变量:
- 系统定义变量
系统变量是由系统系统自己创建的。这些变量通常由大写字母组成,可以通过
set命令查看。
- 用户定义变量
用户变量由系统用户来生成和定义,变量的值可以通过命令
"echo $<变量名>"查看。
Shell脚本中 $? 标记的用途是什么?
在写一个 Shell 脚本时,如果你想要检查前一命令是否执行成功,在 if 条件中使用 $? 可以来检查前一命令的结束状态。
- 如果结束状态是 0 ,说明前一个命令执行成功。例如:
root@localhost:~## ls /usr/bin/shar
/usr/bin/shar
root@localhost:~## echo $?
0
- 如果结束状态不是0,说明命令执行失败。例如:
root@localhost:~## ls /usr/bin/share
ls: cannot access /usr/bin/share: No such file or directory
root@localhost:~## echo $?
2
Bourne Shell(bash) 中有哪些特殊的变量?
下面的表列出了 Bourne Shell 为命令行设置的特殊变量。
内建变量 解释
$0 命令行中的脚本名字
$1 第一个命令行参数
$2 第二个命令行参数
….. …….
$9 第九个命令行参数
$## 命令行参数的数量
$\* 所有命令行参数,以空格隔开
如何取消变量或取消变量赋值?
unset 命令用于取消变量或取消变量赋值。语法如下所示:
## unset <变量名>
Shell 脚本中 if 语法如何嵌套?
if [ 条件 ]
then
命令1
命令2
…..
else
if [ 条件 ]
then
命令1
命令2
….
else
命令1
命令2
…..
fi
fi
在 Shell 脚本中如何比较两个数字?
在 if-then 中使用测试命令( -gt 等)来比较两个数字。例如:
#!/bin/bash
x=10
y=20
if [ $x -gt $y ]
then
echo “x is greater than y”
else
echo “y is greater than x”
fi
Shell 脚本中 case 语句的语法?
基础语法如下:
case 变量 in
值1)
命令1
命令2
…..
最后命令
!!
值2)
命令1
命令2
……
最后命令
;;
esac
Shell 脚本中 for 循环语法?
基础语法如下:
for 变量 in 循环列表
do
命令1
命令2
….
最后命令
done
Shell 脚本中 while 循环语法?
如同 for 循环,while 循环只要条件成立就重复它的命令块。
不同于 for循环,while 循环会不断迭代,直到它的条件不为真。
基础语法:
while [ 条件 ]
do
命令…
done
do-while 语句的基本格式?
do-while 语句类似于 while 语句,但检查条件语句之前先执行命令(LCTT 译注:意即至少执行一次。)。下面是用 do-while 语句的语法:
do
{
命令
} while (条件)
Shell 脚本中 break 命令的作用?
break 命令一个简单的用途是退出执行中的循环。我们可以在 while 和 until 循环中使用 break 命令跳出循环。
Shell 脚本中 continue 命令的作用?
continue 命令不同于 break 命令,它只跳出当前循环的迭代,而不是整个循环。continue 命令很多时候是很有用的,例如错误发生,但我们依然希望继续执行大循环的时候。
如何使脚本可执行?
使用 chmod 命令来使脚本可执行。例子如下:chmod a+x myscript.sh 。
#!/bin/bash 的作用?
#!/bin/bash 是 Shell 脚本的第一行,称为释伴(shebang)行。
- 这里
#符号叫做 hash ,而!叫做 bang。 - 它的意思是命令通过
/bin/bash来执行。
如何调试 Shell脚本?
- 使用
-x'数(sh -x myscript.sh)可以调试 Shell脚本。 - 另一个种方法是使用
-nv参数(sh -nv myscript.sh)。
如何将标准输出和错误输出同时重定向到同一位置?
- 方法一:
2>&1 (如## ls /usr/share/doc > out.txt 2>&1 )。 - 方法二:
&> (如## ls /usr/share/doc &> out.txt )。
在 Shell 脚本中,如何测试文件?
test 命令可以用来测试文件。基础用法如下表格:
Test 用法
-d 文件名 如果文件存在并且是目录,返回true
-e 文件名 如果文件存在,返回true
-f 文件名 如果文件存在并且是普通文件,返回true
-r 文件名 如果文件存在并可读,返回true
-s 文件名 如果文件存在并且不为空,返回true
-w 文件名 如果文件存在并可写,返回true
-x 文件名 如果文件存在并可执行,返回true
在 Shell 脚本如何定义函数呢?
函数是拥有名字的代码块。当我们定义代码块,我们就可以在我们的脚本调用函数名字,该块就会被执行。示例如下所示:
$ diskusage () { df -h ; }
译注:下面是我给的shell函数语法,原文没有
[ function ] 函数名 [()]
{
命令;
[return int;]
}
如何让 Shell 就脚本得到来自终端的输入?
read 命令可以读取来自终端(使用键盘)的数据。read 命令得到用户的输入并置于你给出的变量中。例子如下:
## vi /tmp/test.sh
#!/bin/bash
echo ‘Please enter your name’
read name
echo “My Name is $name”
## ./test.sh
Please enter your name
ThinkWon
My Name is ThinkWon
如何执行算术运算?
有两种方法来执行算术运算:
- 1、使用 expr 命令:
## expr 5 + 2。 - 2、用一个美元符号和方括号(
$[ 表达式 ]):test=$[16 + 4] ; test=$[16 + 4]。
编程题
判断一文件是不是字符设备文件,如果是将其拷贝到 /dev 目录下?
#!/bin/bash
read -p "Input file name: " FILENAME
if [ -c "$FILENAME" ];then
cp $FILENAME /dev
fi
添加一个新组为 class1 ,然后添加属于这个组的 30 个用户,用户名的形式为 stdxx ,其中 xx 从 01 到 30 ?
#!/bin/bash
groupadd class1
for((i=1;i<31;i++))
do
if [ $i -le 10 ];then
useradd -g class1 std0$i
else
useradd -g class1 std$i
fi
done
编写 Shell 程序,实现自动删除 50 个账号的功能,账号名为stud1 至 stud50 ?
#!/bin/bash
for((i=1;i<51;i++))
do
userdel -r stud$i
done
写一个 sed 命令,修改 /tmp/input.txt 文件的内容?
要求:
- 删除所有空行。
- 一行中,如果包含 “11111”,则在 “11111” 前面插入 “AAA”,在 “11111” 后面插入 “BBB” 。比如:将内容为 0000111112222 的一行改为 0000AAA11111BBB2222 。
[root@~]## cat -n /tmp/input.txt
1 000011111222
2
3 000011111222222
4 11111000000222
5
6
7 111111111111122222222222
8 2211111111
9 112222222
10 1122
11
## 删除所有空行命令
[root@~]## sed '/^$/d' /tmp/input.txt
000011111222
000011111222222
11111000000222
111111111111122222222222
2211111111
112222222
1122
## 插入指定的字符
[root@~]## sed 's#\(11111\)#AAA\1BBB#g' /tmp/input.txt
0000AAA11111BBB222
0000AAA11111BBB222222
AAA11111BBB000000222
AAA11111BBBAAA11111BBB11122222222222
22AAA11111BBB111
112222222
1122
实战
如何选择 Linux 操作系统版本?
一般来讲,桌面用户首选 Ubuntu ;服务器首选 RHEL 或 CentOS ,两者中首选 CentOS 。
根据具体要求:
- 安全性要求较高,则选择 Debian 或者 FreeBSD 。
- 需要使用数据库高级服务和电子邮件网络应用的用户可以选择 SUSE 。
- 想要新技术新功能可以选择 Feddora ,Feddora 是 RHEL 和 CentOS 的一个测试版和预发布版本。
- 【重点】根据现有状况,绝大多数互联网公司选择 CentOS 。现在比较常用的是 6 系列,现在市场占有大概一半左右。另外的原因是 CentOS 更侧重服务器领域,并且无版权约束。
CentOS 7 系列,也慢慢使用的会比较多了。
如何规划一台 Linux 主机,步骤是怎样?
- 1、确定机器是做什么用的,比如是做 WEB 、DB、还是游戏服务器。
不同的用途,机器的配置会有所不同。
- 2、确定好之后,就要定系统需要怎么安装,默认安装哪些系统、分区怎么做。
- 3、需要优化系统的哪些参数,需要创建哪些用户等等的。
请问当用户反馈网站访问慢,你会如何处理?
有哪些方面的因素会导致网站网站访问慢?
- 1、服务器出口带宽不够用
- 本身服务器购买的出口带宽比较小。一旦并发量大的话,就会造成分给每个用户的出口带宽就小,访问速度自然就会慢。
- 跨运营商网络导致带宽缩减。例如,公司网站放在电信的网络上,那么客户这边对接是长城宽带或联通,这也可能导致带宽的缩减。
- 2、服务器负载过大,导致响应不过来
可以从两个方面入手分析:
- 分析系统负载,使用 w 命令或者 uptime 命令查看系统负载。如果负载很高,则使用 top 命令查看 CPU ,MEM 等占用情况,要么是 CPU 繁忙,要么是内存不够。
- 如果这二者都正常,再去使用 sar 命令分析网卡流量,分析是不是遭到了攻击。一旦分析出问题的原因,采取对应的措施解决,如决定要不要杀死一些进程,或者禁止一些访问等。
- 3、数据库瓶颈
- 如果慢查询比较多。那么就要开发人员或 DBA 协助进行 SQL 语句的优化。
- 如果数据库响应慢,考虑可以加一个数据库缓存,如 Redis 等。然后,也可以搭建 MySQL 主从,一台 MySQL 服务器负责写,其他几台从数据库负责读。
- 4、网站开发代码没有优化好
- 例如 SQL 语句没有优化,导致数据库读写相当耗时。
针对网站访问慢,怎么去排查?
- 1、首先要确定是用户端还是服务端的问题。当接到用户反馈访问慢,那边自己立即访问网站看看,如果自己这边访问快,基本断定是用户端问题,就需要耐心跟客户解释,协助客户解决问题。
不要上来就看服务端的问题。一定要从源头开始,逐步逐步往下。
- 2、如果访问也慢,那么可以利用浏览器的调试功能,看看加载那一项数据消耗时间过多,是图片加载慢,还是某些数据加载慢。
- 3、针对服务器负载情况。查看服务器硬件(网络、CPU、内存)的消耗情况。如果是购买的云主机,比如阿里云,可以登录阿里云平台提供各方面的监控,比如 CPU、内存、带宽的使用情况。
- 4、如果发现硬件资源消耗都不高,那么就需要通过查日志,比如看看 MySQL慢查询的日志,看看是不是某条 SQL 语句查询慢,导致网站访问慢。
怎么去解决?
- 1、如果是出口带宽问题,那么久申请加大出口带宽。
- 2、如果慢查询比较多,那么就要开发人员或 DBA 协助进行 SQL 语句的优化。
- 3、如果数据库响应慢,考虑可以加一个数据库缓存,如 Redis 等等。然后也可以搭建MySQL 主从,一台 MySQL 服务器负责写,其他几台从数据库负责读。
- 4、申请购买 CDN 服务,加载用户的访问。
- 5、如果访问还比较慢,那就需要从整体架构上进行优化咯。做到专角色专用,多台服务器提供同一个服务。
Linux 性能调优都有哪几种方法?
- 1、Disabling daemons (关闭 daemons)。
- 2、Shutting down the GUI (关闭 GUI)。
- 3、Changing kernel parameters (改变内核参数)。
- 4、Kernel parameters (内核参数)。
- 5、Tuning the processor subsystem (处理器子系统调优)。
- 6、Tuning the memory subsystem (内存子系统调优)。
- 7、Tuning the file system (文件系统子系统调优)。
- 8、Tuning the network subsystem(网络子系统调优)。
文件管理命令
cat 命令
cat 命令用于连接文件并打印到标准输出设备上。
cat 主要有三大功能:
1.一次显示整个文件:
cat filename
2.从键盘创建一个文件:
cat > filename
只能创建新文件,不能编辑已有文件。
3.将几个文件合并为一个文件:
cat file1 file2 > file
- -b 对非空输出行号
- -n 输出所有行号
实例:
(1)把 log2012.log 的文件内容加上行号后输入 log2013.log 这个文件里
cat -n log2012.log log2013.log
(2)把 log2012.log 和 log2013.log 的文件内容加上行号(空白行不加)之后将内容附加到 log.log 里
cat -b log2012.log log2013.log log.log
(3)使用 here doc 生成新文件
cat >log.txt <<EOF
>Hello
>World
>PWD=$(pwd)
>EOF
ls -l log.txt
cat log.txt
Hello
World
PWD=/opt/soft/test
(4)反向列示
tac log.txt
PWD=/opt/soft/test
World
Hello
chmod 命令
Linux/Unix 的文件调用权限分为三级 : 文件拥有者、群组、其他。利用 chmod 可以控制文件如何被他人所调用。
用于改变 linux 系统文件或目录的访问权限。用它控制文件或目录的访问权限。该命令有两种用法。一种是包含字母和操作符表达式的文字设定法;另一种是包含数字的数字设定法。
每一文件或目录的访问权限都有三组,每组用三位表示,分别为文件属主的读、写和执行权限;与属主同组的用户的读、写和执行权限;系统中其他用户的读、写和执行权限。可使用 ls -l test.txt 查找。
以文件 log2012.log 为例:
-rw-r--r-- 1 root root 296K 11-13 06:03 log2012.log
第一列共有 10 个位置,第一个字符指定了文件类型。在通常意义上,一个目录也是一个文件。如果第一个字符是横线,表示是一个非目录的文件。如果是 d,表示是一个目录。从第二个字符开始到第十个 9 个字符,3 个字符一组,分别表示了 3 组用户对文件或者目录的权限。权限字符用横线代表空许可,r 代表只读,w 代表写,x 代表可执行。
常用参数:
-c 当发生改变时,报告处理信息
-R 处理指定目录以及其子目录下所有文件
权限范围:
u :目录或者文件的当前的用户
g :目录或者文件的当前的群组
o :除了目录或者文件的当前用户或群组之外的用户或者群组
a :所有的用户及群组
权限代号:
r :读权限,用数字4表示
w :写权限,用数字2表示
x :执行权限,用数字1表示
- :删除权限,用数字0表示
s :特殊权限
实例:
(1)增加文件 t.log 所有用户可执行权限
chmod a+x t.log
(2)撤销原来所有的权限,然后使拥有者具有可读权限,并输出处理信息
chmod u=r t.log -c
(3)给 file 的属主分配读、写、执行(7)的权限,给file的所在组分配读、执行(5)的权限,给其他用户分配执行(1)的权限
chmod 751 t.log -c(或者:chmod u=rwx,g=rx,o=x t.log -c)
(4)将 test 目录及其子目录所有文件添加可读权限
chmod u+r,g+r,o+r -R text/ -c
chown 命令
chown 将指定文件的拥有者改为指定的用户或组,用户可以是用户名或者用户 ID;组可以是组名或者组 ID;文件是以空格分开的要改变权限的文件列表,支持通配符。
-c 显示更改的部分的信息
-R 处理指定目录及子目录
实例:
(1)改变拥有者和群组 并显示改变信息
chown -c mail:mail log2012.log
(2)改变文件群组
chown -c :mail t.log
(3)改变文件夹及子文件目录属主及属组为 mail
chown -cR mail: test/
cp 命令
将源文件复制至目标文件,或将多个源文件复制至目标目录。
注意:命令行复制,如果目标文件已经存在会提示是否覆盖,而在 shell 脚本中,如果不加 -i 参数,则不会提示,而是直接覆盖!
-i 提示
-r 复制目录及目录内所有项目
-a 复制的文件与原文件时间一样
实例:
(1)复制 a.txt 到 test 目录下,保持原文件时间,如果原文件存在提示是否覆盖。
cp -ai a.txt test
(2)为 a.txt 建议一个链接(快捷方式)
cp -s a.txt link_a.txt
find 命令
用于在文件树中查找文件,并作出相应的处理。
命令格式:
find pathname -options [-print -exec -ok ...]
命令参数:
pathname: find命令所查找的目录路径。例如用.来表示当前目录,用/来表示系统根目录。
-print: find命令将匹配的文件输出到标准输出。
-exec: find命令对匹配的文件执行该参数所给出的shell命令。相应命令的形式为'command' { } \;,注意{ }和\;之间的空格。
-ok: 和-exec的作用相同,只不过以一种更为安全的模式来执行该参数所给出的shell命令,在执行每一个命令之前,都会给出提示,让用户来确定是否执行。
命令选项:
-name 按照文件名查找文件
-perm 按文件权限查找文件
-user 按文件属主查找文件
-group 按照文件所属的组来查找文件。
-type 查找某一类型的文件,诸如:
b - 块设备文件
d - 目录
c - 字符设备文件
l - 符号链接文件
p - 管道文件
f - 普通文件
实例:
(1)查找 48 小时内修改过的文件
find -atime -2
(2)在当前目录查找 以 .log 结尾的文件。 . 代表当前目录
find ./ -name '\*.log'
(3)查找 /opt 目录下 权限为 777 的文件
find /opt -perm 777
(4)查找大于 1K 的文件
find -size +1000c
查找等于 1000 字符的文件
find -size 1000c
-exec 参数后面跟的是 command 命令,它的终止是以 ; 为结束标志的,所以这句命令后面的分号是不可缺少的,考虑到各个系统中分号会有不同的意义,所以前面加反斜杠。{} 花括号代表前面find查找出来的文件名。
head 命令
head 用来显示档案的开头至标准输出中,默认 head 命令打印其相应文件的开头 10 行。
常用参数:
-n<行数> 显示的行数(行数为复数表示从最后向前数)
实例:
(1)显示 1.log 文件中前 20 行
head 1.log -n 20
(2)显示 1.log 文件前 20 字节
head -c 20 log2014.log
(3)显示 t.log最后 10 行
head -n -10 t.log
less 命令
less 与 more 类似,但使用 less 可以随意浏览文件,而 more 仅能向前移动,却不能向后移动,而且 less 在查看之前不会加载整个文件。
常用命令参数:
-i 忽略搜索时的大小写
-N 显示每行的行号
-o <文件名> 将less 输出的内容在指定文件中保存起来
-s 显示连续空行为一行
/字符串:向下搜索“字符串”的功能
?字符串:向上搜索“字符串”的功能
n:重复前一个搜索(与 / 或 ? 有关)
N:反向重复前一个搜索(与 / 或 ? 有关)
-x <数字> 将“tab”键显示为规定的数字空格
b 向后翻一页
d 向后翻半页
h 显示帮助界面
Q 退出less 命令
u 向前滚动半页
y 向前滚动一行
空格键 滚动一行
回车键 滚动一页
[pagedown]: 向下翻动一页
[pageup]: 向上翻动一页
实例:
(1)ps 查看进程信息并通过 less 分页显示
ps -aux | less -N
(2)查看多个文件
less 1.log 2.log
可以使用 n 查看下一个,使用 p 查看前一个。
ln 命令
功能是为文件在另外一个位置建立一个同步的链接,当在不同目录需要该问题时,就不需要为每一个目录创建同样的文件,通过 ln 创建的链接(link)减少磁盘占用量。
链接分类:软件链接及硬链接
软链接:
- 1.软链接,以路径的形式存在。类似于Windows操作系统中的快捷方式
- 2.软链接可以 跨文件系统 ,硬链接不可以
- 3.软链接可以对一个不存在的文件名进行链接
- 4.软链接可以对目录进行链接
硬链接:
- 1.硬链接,以文件副本的形式存在。但不占用实际空间。
- 2.不允许给目录创建硬链接
- 3.硬链接只有在同一个文件系统中才能创建
需要注意:
- 第一:ln命令会保持每一处链接文件的同步性,也就是说,不论你改动了哪一处,其它的文件都会发生相同的变化;
- 第二:ln的链接又分软链接和硬链接两种,软链接就是ln –s 源文件 目标文件,它只会在你选定的位置上生成一个文件的镜像,不会占用磁盘空间,硬链接 ln 源文件 目标文件,没有参数-s, 它会在你选定的位置上生成一个和源文件大小相同的文件,无论是软链接还是硬链接,文件都保持同步变化。
- 第三:ln指令用在链接文件或目录,如同时指定两个以上的文件或目录,且最后的目的地是一个已经存在的目录,则会把前面指定的所有文件或目录复制到该目录中。若同时指定多个文件或目录,且最后的目的地并非是一个已存在的目录,则会出现错误信息。
常用参数:
-b 删除,覆盖以前建立的链接
-s 软链接(符号链接)
-v 显示详细处理过程
实例:
(1)给文件创建软链接,并显示操作信息
ln -sv source.log link.log
(2)给文件创建硬链接,并显示操作信息
ln -v source.log link1.log
(3)给目录创建软链接
ln -sv /opt/soft/test/test3 /opt/soft/test/test5
locate 命令
locate 通过搜寻系统内建文档数据库达到快速找到档案,数据库由 updatedb 程序来更新,updatedb 是由 cron daemon 周期性调用的。默认情况下 locate 命令在搜寻数据库时比由整个由硬盘资料来搜寻资料来得快,但较差劲的是 locate 所找到的档案若是最近才建立或 刚更名的,可能会找不到,在内定值中,updatedb 每天会跑一次,可以由修改 crontab 来更新设定值 (etc/crontab)。
locate 与 find 命令相似,可以使用如 *、? 等进行正则匹配查找
常用参数:
-l num(要显示的行数)
-f 将特定的档案系统排除在外,如将proc排除在外
-r 使用正则运算式做为寻找条件
实例:
(1)查找和 pwd 相关的所有文件(文件名中包含 pwd)
locate pwd
(2)搜索 etc 目录下所有以 sh 开头的文件
locate /etc/sh
(3)查找 /var 目录下,以 reason 结尾的文件
locate -r '^/var.\*reason$'(其中.表示一个字符,*表示任务多个;.*表示任意多个字符)
more 命令
功能类似于 cat, more 会以一页一页的显示方便使用者逐页阅读,而最基本的指令就是按空白键(space)就往下一页显示,按 b 键就会往回(back)一页显示。
命令参数:
+n 从笫 n 行开始显示
-n 定义屏幕大小为n行
+/pattern 在每个档案显示前搜寻该字串(pattern),然后从该字串前两行之后开始显示
-c 从顶部清屏,然后显示
-d 提示“Press space to continue,’q’ to quit(按空格键继续,按q键退出)”,禁用响铃功能
-l 忽略Ctrl+l(换页)字符
-p 通过清除窗口而不是滚屏来对文件进行换页,与-c选项相似
-s 把连续的多个空行显示为一行
-u 把文件内容中的下画线去掉
常用操作命令:
Enter 向下 n 行,需要定义。默认为 1 行
Ctrl+F 向下滚动一屏
空格键 向下滚动一屏
Ctrl+B 返回上一屏
= 输出当前行的行号
:f 输出文件名和当前行的行号
V 调用vi编辑器
!命令 调用Shell,并执行命令
q 退出more
实例:
(1)显示文件中从第3行起的内容
more +3 text.txt
(2)在所列出文件目录详细信息,借助管道使每次显示 5 行
ls -l | more -5
按空格显示下 5 行。
mv 命令
移动文件或修改文件名,根据第二参数类型(如目录,则移动文件;如为文件则重命令该文件)。
当第二个参数为目录时,第一个参数可以是多个以空格分隔的文件或目录,然后移动第一个参数指定的多个文件到第二个参数指定的目录中。
实例:
(1)将文件 test.log 重命名为 test1.txt
mv test.log test1.txt
(2)将文件 log1.txt,log2.txt,log3.txt 移动到根的 test3 目录中
mv llog1.txt log2.txt log3.txt /test3
(3)将文件 file1 改名为 file2,如果 file2 已经存在,则询问是否覆盖
mv -i log1.txt log2.txt
(4)移动当前文件夹下的所有文件到上一级目录
mv * ../
rm 命令
删除一个目录中的一个或多个文件或目录,如果没有使用 -r 选项,则 rm 不会删除目录。如果使用 rm 来删除文件,通常仍可以将该文件恢复原状。
rm [选项] 文件…
实例:
(1)删除任何 .log 文件,删除前逐一询问确认:
rm -i *.log
(2)删除 test 子目录及子目录中所有档案删除,并且不用一一确认:
rm -rf test
(3)删除以 -f 开头的文件
rm -- -f*
tail 命令
用于显示指定文件末尾内容,不指定文件时,作为输入信息进行处理。常用查看日志文件。
常用参数:
-f 循环读取(常用于查看递增的日志文件)
-n<行数> 显示行数(从后向前)
(1)循环读取逐渐增加的文件内容
ping 127.0.0.1 > ping.log &
后台运行:可使用 jobs -l 查看,也可使用 fg 将其移到前台运行。
tail -f ping.log
(查看日志)
touch 命令
Linux touch命令用于修改文件或者目录的时间属性,包括存取时间和更改时间。若文件不存在,系统会建立一个新的文件。
ls -l 可以显示档案的时间记录。
语法
touch [-acfm][-d<日期时间>][-r<参考文件或目录>] [-t<日期时间>][--help][--version][文件或目录…]
- 参数说明:
- a 改变档案的读取时间记录。
- m 改变档案的修改时间记录。
- c 假如目的档案不存在,不会建立新的档案。与 --no-create 的效果一样。
- f 不使用,是为了与其他 unix 系统的相容性而保留。
- r 使用参考档的时间记录,与 --file 的效果一样。
- d 设定时间与日期,可以使用各种不同的格式。
- t 设定档案的时间记录,格式与 date 指令相同。
- –no-create 不会建立新档案。
- –help 列出指令格式。
- –version 列出版本讯息。
实例
使用指令"touch"修改文件"testfile"的时间属性为当前系统时间,输入如下命令:
$ touch testfile #修改文件的时间属性
首先,使用ls命令查看testfile文件的属性,如下所示:
$ ls -l testfile #查看文件的时间属性
#原来文件的修改时间为16:09
-rw-r--r-- 1 hdd hdd 55 2011-08-22 16:09 testfile
执行指令"touch"修改文件属性以后,并再次查看该文件的时间属性,如下所示:
$ touch testfile #修改文件时间属性为当前系统时间
$ ls -l testfile #查看文件的时间属性
#修改后文件的时间属性为当前系统时间
-rw-r--r-- 1 hdd hdd 55 2011-08-22 19:53 testfile
使用指令"touch"时,如果指定的文件不存在,则将创建一个新的空白文件。例如,在当前目录下,使用该指令创建一个空白文件"file",输入如下命令:
$ touch file #创建一个名为“file”的新的空白文件
vim 命令
Vim是从 vi 发展出来的一个文本编辑器。代码补完、编译及错误跳转等方便编程的功能特别丰富,在程序员中被广泛使用。
- 打开文件并跳到第 10 行:
vim +10 filename.txt。 - 打开文件跳到第一个匹配的行:
vim +/search-term filename.txt。 - 以只读模式打开文件:
vim -R /etc/passwd。
基本上 vi/vim 共分为三种模式,分别是命令模式(Command mode),输入模式(Insert mode)和底线命令模式(Last line mode)。
简单的说,我们可以将这三个模式想成底下的图标来表示:
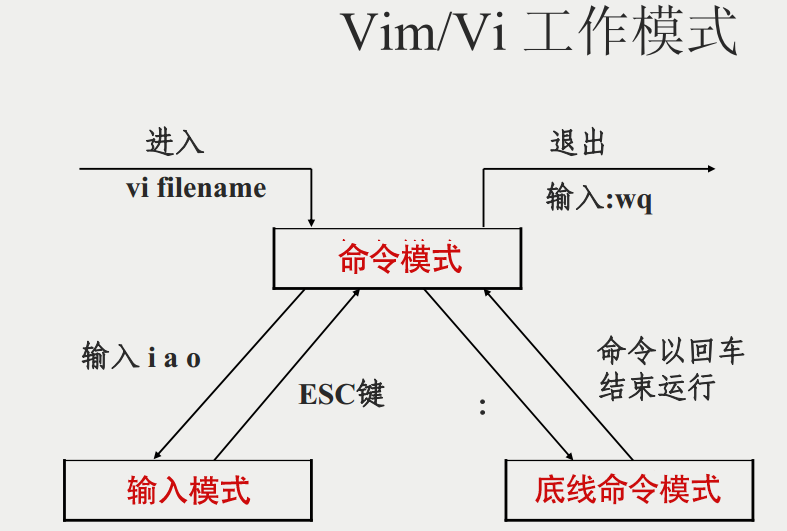
whereis 命令
whereis 命令只能用于程序名的搜索,而且只搜索二进制文件(参数-b)、man说明文件(参数-m)和源代码文件(参数-s)。如果省略参数,则返回所有信息。whereis 及 locate 都是基于系统内建的数据库进行搜索,因此效率很高,而find则是遍历硬盘查找文件。
常用参数:
-b 定位可执行文件。
-m 定位帮助文件。
-s 定位源代码文件。
-u 搜索默认路径下除可执行文件、源代码文件、帮助文件以外的其它文件。
实例:
(1)查找 locate 程序相关文件
whereis locate
(2)查找 locate 的源码文件
whereis -s locate
(3)查找 lcoate 的帮助文件
whereis -m locate
which 命令
在 linux 要查找某个文件,但不知道放在哪里了,可以使用下面的一些命令来搜索:
which 查看可执行文件的位置。
whereis 查看文件的位置。
locate 配合数据库查看文件位置。
find 实际搜寻硬盘查询文件名称。
which 是在 PATH 就是指定的路径中,搜索某个系统命令的位置,并返回第一个搜索结果。使用 which 命令,就可以看到某个系统命令是否存在,以及执行的到底是哪一个位置的命令。
常用参数:
-n 指定文件名长度,指定的长度必须大于或等于所有文件中最长的文件名。
实例:
(1)查看 ls 命令是否存在,执行哪个
which ls
(2)查看 which
which which
(3)查看 cd
which cd(显示不存在,因为 cd 是内建命令,而 which 查找显示是 PATH 中的命令)
查看当前 PATH 配置:
echo $PATH
或使用 env 查看所有环境变量及对应值
文档编辑命令
grep 命令
强大的文本搜索命令,grep(Global Regular Expression Print) 全局正则表达式搜索。
grep 的工作方式是这样的,它在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。搜索的结果被送到标准输出,不影响原文件内容。
命令格式:
grep [option] pattern file|dir
常用参数:
-A n --after-context显示匹配字符后n行
-B n --before-context显示匹配字符前n行
-C n --context 显示匹配字符前后n行
-c --count 计算符合样式的列数
-i 忽略大小写
-l 只列出文件内容符合指定的样式的文件名称
-f 从文件中读取关键词
-n 显示匹配内容的所在文件中行数
-R 递归查找文件夹
grep 的规则表达式:
^ #锚定行的开始 如:'^grep'匹配所有以grep开头的行。
$ #锚定行的结束 如:'grep$'匹配所有以grep结尾的行。
. #匹配一个非换行符的字符 如:'gr.p'匹配gr后接一个任意字符,然后是p。
* #匹配零个或多个先前字符 如:'*grep'匹配所有一个或多个空格后紧跟grep的行。
.* #一起用代表任意字符。
[] #匹配一个指定范围内的字符,如'[Gg]rep'匹配Grep和grep。
[^] #匹配一个不在指定范围内的字符,如:'[^A-FH-Z]rep'匹配不包含A-R和T-Z的一个字母开头,紧跟rep的行。
\(..\) #标记匹配字符,如'\(love\)',love被标记为1。
\< #锚定单词的开始,如:'\<grep'匹配包含以grep开头的单词的行。
\> #锚定单词的结束,如'grep\>'匹配包含以grep结尾的单词的行。
x\{m\} #重复字符x,m次,如:'0\{5\}'匹配包含5个o的行。
x\{m,\} #重复字符x,至少m次,如:'o\{5,\}'匹配至少有5个o的行。
x\{m,n\} #重复字符x,至少m次,不多于n次,如:'o\{5,10\}'匹配5--10个o的行。
\w #匹配文字和数字字符,也就是[A-Za-z0-9],如:'G\w*p'匹配以G后跟零个或多个文字或数字字符,然后是p。
\W #\w的反置形式,匹配一个或多个非单词字符,如点号句号等。
\b #单词锁定符,如: '\bgrep\b'只匹配grep。
实例:
(1)查找指定进程
ps -ef | grep svn
(2)查找指定进程个数
ps -ef | grep svn -c
(3)从文件中读取关键词
cat test1.txt | grep -f key.log
(4)从文件夹中递归查找以grep开头的行,并只列出文件
grep -lR '^grep' /tmp
(5)查找非x开关的行内容
grep '^[^x]' test.txt
(6)显示包含 ed 或者 at 字符的内容行
grep -E 'ed|at' test.txt
wc 命令
wc(word count)功能为统计指定的文件中字节数、字数、行数,并将统计结果输出
命令格式:
wc [option] file..
命令参数:
-c 统计字节数
-l 统计行数
-m 统计字符数
-w 统计词数,一个字被定义为由空白、跳格或换行字符分隔的字符串
实例:
(1)查找文件的 行数 单词数 字节数 文件名
wc text.txt
结果:
7 8 70 test.txt
(2)统计输出结果的行数
cat test.txt | wc -l
磁盘管理命令
cd 命令
cd(changeDirectory) 命令语法:
cd [目录名]
说明:切换当前目录至 dirName。
实例:
(1)进入要目录
cd /
(2)进入 “home” 目录
cd ~
(3)进入上一次工作路径
cd -
(4)把上个命令的参数作为cd参数使用。
cd !$
df 命令
显示磁盘空间使用情况。获取硬盘被占用了多少空间,目前还剩下多少空间等信息,如果没有文件名被指定,则所有当前被挂载的文件系统的可用空间将被显示。默认情况下,磁盘空间将以 1KB 为单位进行显示,除非环境变量 POSIXLY_CORRECT 被指定,那样将以512字节为单位进行显示:
-a 全部文件系统列表
-h 以方便阅读的方式显示信息
-i 显示inode信息
-k 区块为1024字节
-l 只显示本地磁盘
-T 列出文件系统类型
实例:
(1)显示磁盘使用情况
df -l
(2)以易读方式列出所有文件系统及其类型
df -haT
du 命令
du 命令也是查看使用空间的,但是与 df 命令不同的是 Linux du 命令是对文件和目录磁盘使用的空间的查看:
命令格式:
du [选项] [文件]
常用参数:
-a 显示目录中所有文件大小
-k 以KB为单位显示文件大小
-m 以MB为单位显示文件大小
-g 以GB为单位显示文件大小
-h 以易读方式显示文件大小
-s 仅显示总计
-c或--total 除了显示个别目录或文件的大小外,同时也显示所有目录或文件的总和
实例:
(1)以易读方式显示文件夹内及子文件夹大小
du -h scf/
(2)以易读方式显示文件夹内所有文件大小
du -ah scf/
(3)显示几个文件或目录各自占用磁盘空间的大小,还统计它们的总和
du -hc test/ scf/
(4)输出当前目录下各个子目录所使用的空间
du -hc --max-depth=1 scf/
ls命令
就是 list 的缩写,通过 ls 命令不仅可以查看 linux 文件夹包含的文件,而且可以查看文件权限(包括目录、文件夹、文件权限)查看目录信息等等。
常用参数搭配:
ls -a 列出目录所有文件,包含以.开始的隐藏文件
ls -A 列出除.及..的其它文件
ls -r 反序排列
ls -t 以文件修改时间排序
ls -S 以文件大小排序
ls -h 以易读大小显示
ls -l 除了文件名之外,还将文件的权限、所有者、文件大小等信息详细列出来
实例:
(1) 按易读方式按时间反序排序,并显示文件详细信息
ls -lhrt
(2) 按大小反序显示文件详细信息
ls -lrS
(3)列出当前目录中所有以"t"开头的目录的详细内容
ls -l t*
(4) 列出文件绝对路径(不包含隐藏文件)
ls | sed "s:^:`pwd`/:"
(5) 列出文件绝对路径(包含隐藏文件)
find $pwd -maxdepth 1 | xargs ls -ld
mkdir 命令
mkdir 命令用于创建文件夹。
可用选项:
- -m: 对新建目录设置存取权限,也可以用 chmod 命令设置;
- -p: 可以是一个路径名称。此时若路径中的某些目录尚不存在,加上此选项后,系统将自动建立好那些尚不在的目录,即一次可以建立多个目录。
实例:
(1)当前工作目录下创建名为 t的文件夹
mkdir t
(2)在 tmp 目录下创建路径为 test/t1/t 的目录,若不存在,则创建:
mkdir -p /tmp/test/t1/t
pwd 命令

最全的Linux教程,Linux从入门到精通
======================
-
linux从入门到精通(第2版)
-
Linux系统移植
-
Linux驱动开发入门与实战
-
LINUX 系统移植 第2版
-
Linux开源网络全栈详解 从DPDK到OpenFlow

第一份《Linux从入门到精通》466页
====================
内容简介
====
本书是获得了很多读者好评的Linux经典畅销书**《Linux从入门到精通》的第2版**。本书第1版出版后曾经多次印刷,并被51CTO读书频道评为“最受读者喜爱的原创IT技术图书奖”。本书第﹖版以最新的Ubuntu 12.04为版本,循序渐进地向读者介绍了Linux 的基础应用、系统管理、网络应用、娱乐和办公、程序开发、服务器配置、系统安全等。本书附带1张光盘,内容为本书配套多媒体教学视频。另外,本书还为读者提供了大量的Linux学习资料和Ubuntu安装镜像文件,供读者免费下载。

本书适合广大Linux初中级用户、开源软件爱好者和大专院校的学生阅读,同时也非常适合准备从事Linux平台开发的各类人员。
需要《Linux入门到精通》、《linux系统移植》、《Linux驱动开发入门实战》、《Linux开源网络全栈》电子书籍及教程的工程师朋友们劳烦您转发+评论
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 739
739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









