







所以可以的话,还是用 Windows 来做。Mac 上还有个比较知名的工具 Charles,有用过的可以留言评价下。
配置
安装好工具后,需要做一些必要配置才能抓包。
1. Fiddler 配置
设置允许抓取 HTTPS 信息包。打开下载好的 fiddler,找到Tools -> Options,然后在 HTTPS 的工具栏下勾选 Decrpt HTTPS traffic,在新弹出的选项栏下勾选Ignore server certificate errors。这样,fiddler 就会抓取到 HTTPS 的信息包。

设置允许外部设备发送 HTTP/HTTPS 到 fiddler。设置端口号,并在 Connections 选项栏下勾选 Allow remote computers to connect。
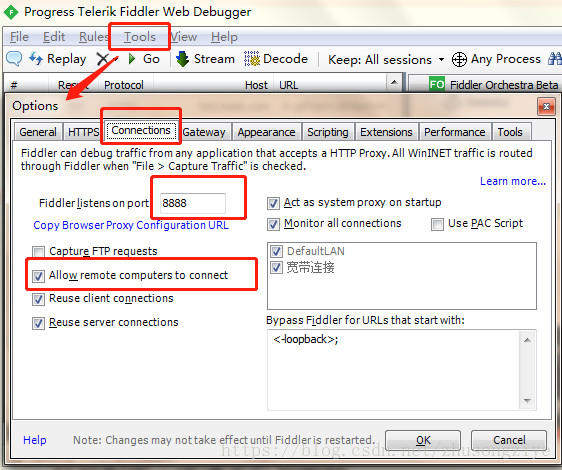
配置好后需重启软件。
2. 设置手机代理
在抓包前,确保你的电脑和手机是在一个可以互访的局域网中。最简单的情况就是都连在同一个 wifi 上,特殊情况这里不展开讨论(有些商用 wifi 并不能互访)。
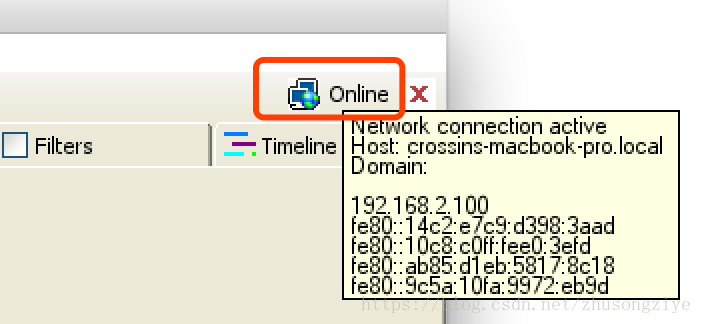
打开软件,鼠标放在右上角的 Online 上可以看到本机的 IP。或者也可以通过命令行中的 ipconfig 命令(Mac/Linux 是 ifconfig)查看。(截图仅为演示,以你自己的 IP 为准)

手机设置代理 IP。打开手机无线网络连接,选择已经连接的网络连接,点击一个小圆圈叹号进入可以看到下图(安卓也类似),选择配置代理,进入后把刚刚的 IP 地址输入进去,端口就是 fiddler 中设置的 8888。

3. 安装证书
获取HTTPS请求必须要验证证书。电脑端访问:http://localhost:8888/ 进行安装。

手机访问前面设置的电脑的 IP 地址加端口 8888 访问,比如图中例子是:http://192.168.23.1:8888

有些安卓需要手动从设置里进入并导入证书,否则无法生效。
4. 测试
开启 fiddler 的状态下,打开手机随便一个 APP,应对可以正常访问,并且在 fiddler 中看到所发出的网络请求。

如果能访问但看不到请求,确认下有没有代理有没有生效。如果不能访问,检查下证书是否都下载并验证。还是不行则按照上述步骤再仔细配置一遍。
分析请求
完成这一步之后,接下来的事情就和网页爬虫没太大区别了。无非就是从这些请求中,找到我们需要的那几个。
fiddler 里记录的是所有请求,比较多。在操作 App 前,记得清空已有请求,方便观察。然后再配合上 filter 筛选器,定义筛选规则,会较容易找你需要的内容。找到请求后,在软件里查看你要的信息,或者右键点击选择将请求导出。

经过操作+观察,可以定位到获取用户上传视频列表的请求是
https://api.amemv.com/aweme/v1/aweme/post/?…
从 WebForms 栏里可以查看请求的详细参数信息。返回值是一个组 JSON 数据,里面包含了视频的下载地址。

这是一个需要经验积累的活儿,不同的网站/App,规则都不一样,但套路是相似的。对网页爬虫还不熟悉的话,搜索文章 爬虫必备工具,掌握它就解决了一半的问题。
代码抓取
得到地址之后,经过在浏览器和代码里的一番尝试,找到了此请求的正确解锁方式:
-
需要提供以下参数:
max_cursor=0&user_id=94763945245&count=20&aid=1128,其中user_id是你要抓取的用户 ID,其他参数都可以固定不用改。 -
需要使用手机的 User-Agent,最简单的就是
{'user-agent': 'mobile'}
请求代码:
import requests as rs
uid = 94763945245
url = 'https://api.amemv.com/aweme/v1/aweme/post/?max_cursor=0&user_id=%d&count=20&aid=1128' % uid
h = {'user-agent': 'mobile'}
req = rs.get(url, headers=h, verify=False)
data = req.json()
print(data)
uid 替换成你想抓的用户 ID。获取用户 ID 有个简单方法:在用户页面选择分享,链接发到微信上,从网页打开就可以看到 user_id。
提取视频列表并下载:
import urllib.request
for video in data['aweme_list']:
name = video['desc'] or video['aweme_id']
url_v = video['video']['download_addr']['url_list'][0]
print(name, url_v, '\n')
urllib.request.urlretrieve(url_v, name + '.mp4')

此方法截止中秋假期还是有效的,可以通过 Chrome 开发者工具进行模拟。之后能使用多久这就没法保证了,爬虫代码都不会是一劳永逸的。
总结下,重点是fiddler 的抓取,关键是配置、代理、证书,难点是 对请求的分析。最终代码只有简单两步,获取视频列表、下载视频。
所有代码其实就上面两段,也上传了,获取地址请在公众号(Crossin的编程教室)回复关键字 抖音
想看其他十多个项目代码实例(电影票、招聘、贪吃蛇、代理池等),回复关键字 项目
最后
🍅 硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
🍅 技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
🍅 面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
🍅 知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

















 1490
1490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









