







基于Python将PDF文件分割为png格式图片。
如果,要将PDF的每一页转换为PNG格式的图片并保存到指定文件夹。
需要:使用Python的PyMuPDF库(也被称为fitz)
命令行键入以下代码进行安装PyMuPDF库。
pip install pymupdf
pdf文件路径为:"D:\daku\pdfztu\pdf"
导出图片路径为:"D:\daku\pdfztu\tu"
PDF文件转图片Python完整代码
import fitz # PyMuPDFimport os# 定义PDF和输出文件夹的路径pdf_path = "D:\\daku\\pdfztu\\pdf\\一种基于深度学习及遗忘算法的中文分词方法.pdf"output_folder = "D:\\daku\\pdfztu\\tu"# 确保输出文件夹存在if not os.path.exists(output_folder):os.makedirs(output_folder)# 打开PDF文件doc = fitz.open(pdf_path)# 遍历PDF的每一页for page_num in range(len(doc)):# 获取当前页page = doc[page_num]# 定义PNG文件的名称(例如:page_0.png, page_1.png, ...)png_filename = os.path.join(output_folder, f"page_{page_num}.png")# 将当前页转换为PNG并保存到文件pix = page.get_pixmap()pix.save(png_filename)# 关闭PDF文件doc.close()print(f"转换完成,图片已保存到:{output_folder}")
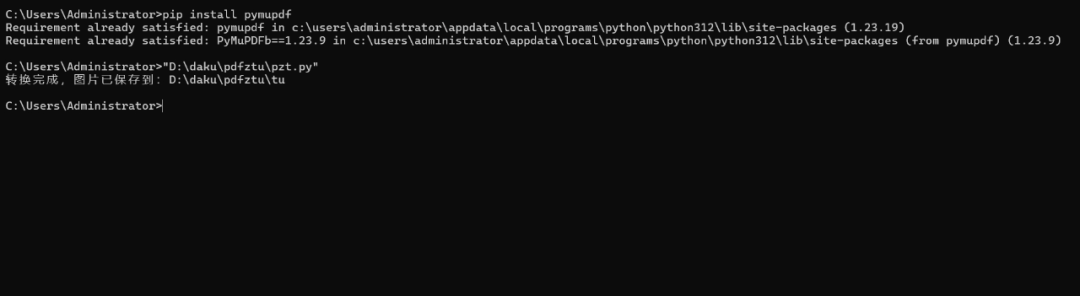

基于Python的PDF文件转图片的导出结果、
















 2583
2583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









