






1、什么是宽依赖,什么是窄依赖?哪些算子是宽依赖,哪些是窄依赖?
窄依赖就是一个父RDD分区对应一个子RDD分区,如map,filter
或者多个父RDD分区对应一个子RDD分区,如co-partioned join
宽依赖是一个父RDD分区对应非全部的子RDD分区,如groupByKey,ruduceByKey
或者一个父RDD分区对应全部的子RDD分区,如未经协同划分的join
https://www.jianshu.com/p/736a4e628f0f
2、Transformation和action算子有什么区别?举例说明
Transformation 变换/转换:这种变换并不触发提交作业,完成作业中间过程处理。Transformation 操作是延迟计算的,也就是说从一个RDD 转换生成另一个 RDD 的转换操作不是马上执行,需要等到有 Action 操作的时候才会真正触发运算
map, filter
Action 行动算子:这类算子会触发 SparkContext 提交 Job 作业。
Action 算子会触发 Spark 提交作业(Job)。
count
3、讲解spark shuffle原理和特性?shuffle write 和 shuffle read过程做些什么?
https://blog.csdn.net/zhanglh046/article/details/78360762
4、Shuffle数据块有多少种不同的存储方式?分别是什么
RDD数据块:用来存储所缓存的RDD数据。
Shuffle数据块:用来存储持久化的Shuffle数据。
广播变量数据块:用来存储所存储的广播变量数据。
任务返回结果数据块:用来存储在存储管理模块内部的任务返回结果。通常情况下任务返回结果随任务一起通过Akka返回到Driver端。但是当任务返回结果很大时,会引起Akka帧溢出,这时的另一种方案是将返回结果以块的形式放入存储管理模块,然后在Driver端获取该数据块即可,因为存储管理模块内部数据块的传输是通过Socket连接的,因此就不会出现Akka帧溢出了。
流式数据块:只用在Spark Streaming中,用来存储所接收到的流式数据块
5、哪些spark算子会有shuffle?
去重,distinct
排序,groupByKey,reduceByKey等
重分区,repartition,coalesce
集合或者表操作,interection,join
https://kuncle.github.io/spark/2017/03/13/Spark%E7%9A%84shuffle%E7%AE%97%E5%AD%90.html
6、讲解spark schedule(任务调度)?
https://www.cnblogs.com/missmzt/p/6734078.html
7、Spark stage是如何划分的?
从hdfs中读取文件后,创建 RDD 对象
DAGScheduler模块介入运算,计算RDD之间的依赖关系。RDD之间的依赖关系就形成了DAG
每一个JOB被分为多个Stage,划分Stage的一个主要依据是当前计算因子的输入是否是确定的,如果是则将其分在同一个Stage,避免多个Stage之间的消息传递开销。
因此spark划分stage的整体思路是:从后往前推,遇到宽依赖就断开,划分为一个stage;遇到窄依赖就将这个RDD加入该stage中。
8、Spark cache一定能提升计算性能么?说明原因?
不一定啊,cache是将数据缓存到内存里,当小数据量的时候是能提升效率,但数据大的时候内存放不下就会报溢出。
9、Cache和persist有什么区别和联系?
cache调用了persist方法,cache只有一个默认的缓存级别MEMORY_ONLY ,而persist可以根据情况设置其它的缓存级别。
https://blog.csdn.net/houmou/article/details/52491419
10、RDD是弹性数据集,“弹性”体现在哪里呢?你觉得RDD有哪些缺陷?
自动进行内存和磁盘切换
基于lineage的高效容错
task如果失败会特定次数的重试
stage如果失败会自动进行特定次数的重试,而且只会只计算失败的分片
checkpoint【每次对RDD操作都会产生新的RDD,如果链条比较长,计算比较笨重,就把数据放在硬盘中】和persist 【内存或磁盘中对数据进行复用】(检查点、持久化)
数据调度弹性:DAG TASK 和资源管理无关
数据分片的高度弹性repartion
缺陷:
惰性计算的缺陷也是明显的:中间数据默认不会保存,每次动作操作都会对数据重复计算,某些计算量比较大的操作可能会影响到系统的运算效率
11、RDD有多少种持久化方式?memory_only如果内存存储不了,会怎么操作?
cache和persist
memory_and_disk,放一部分到磁盘
MEMORY_ONLY_SER:同MEMORY_ONLY,但是会使用Java序列化方式,将Java对象序列化后进行持久化。可以减少内存开销,但是需要进行反序列化,因此会加大CPU开销。
MEMORY_AND_DSK_SER:同MEMORY_AND_DSK。但是使用序列化方式持久化Java对象。
DISK_ONLY:使用非序列化Java对象的方式持久化,完全存储到磁盘上。
MEMORY_ONLY_2或者MEMORY_AND_DISK_2等:如果是尾部加了2的持久化级别,表示会将持久化数据复用一份,保存到其他节点,从而在数据丢失时,不需要再次计算,只需要使用备份数据即可。
12、RDD分区和数据块有啥联系?
13、当GC时间占比很大可能的原因有哪些?对应的优化方法是?
垃圾回收的开销和对象合数成正比,所以减少对象的个数,就能大大减少垃圾回收的开销。序列化存储数据,每个RDD就是一个对象。缓存RDD占用的内存可能跟工作所需的内存打架,需要控制好
14、Spark中repartition和coalesce异同?coalesce什么时候效果更高,为什么
repartition(numPartitions:Int):RDD[T]
coalesce(numPartitions:Int, shuffle:Boolean=false):RDD[T]
1
2
以上为他们的定义,区别就是repartition一定会触发shuffle,而coalesce默认是不触发shuffle的。
他们两个都是RDD的分区进行重新划分,repartition只是coalesce接口中shuffle为true的简易实现,(假设RDD有N个分区,需要重新划分成M个分区)
减少分区提高效率
15、Groupbykey和reducebykey哪个性能更高,为什么?
reduceByKey性能高,更适合大数据集
https://www.jianshu.com/p/0c6705724cff
16、你是如何理解caseclass的?
https://blog.csdn.net/hellojoy/article/details/81034528
17、Scala里trait有什么功能,与class有何异同?什么时候用trait什么时候该用class
它可以被继承,而且支持多重继承,其实它更像我们熟悉的接口(interface),但它与接口又有不同之处是:
trait中可以写方法的实现,interface不可以(java8开始支持接口中允许写方法实现代码了),这样看起来trait又很像抽象类
18、Scala 语法中to 和 until有啥区别
to 包含上界,until不包含上界
21、Spark相比MapReduce的计算模型有哪些区别?
spark处理数据是基于内存的,而MapReduce是基于磁盘处理数据的。
Spark在处理数据时构建了DAG有向无环图,减少了shuffle和数据落地磁盘的次数
Spark是粗粒度资源申请,而MapReduce是细粒度资源申请
你是怎么理解Spark,它的特点是什么?
Spark是一个基于内存的,用于大规模数据处理(离线计算、实时计算、快速查询(交互式查询))的统一分析引擎。
它内部的组成模块,包含SparkCore,SparkSQL,SparkStreaming,SparkMLlib,SparkGraghx等…
 它的特点:
它的特点:
- 快
Spark计算速度是MapReduce计算速度的10-100倍
- 易用
MR支持1种计算模型,Spark支持更多的计算模型(算法多)
- 通用
Spark 能够进行离线计算、交互式查询(快速查询)、实时计算、机器学习、图计算
- 兼容性
Spark支持大数据中的Yarn调度,支持mesos。可以处理hadoop计算的数据。
二、Spark有几种部署方式,请分别简要论述
1) Local:运行在一台机器上,通常是练手或者测试环境。
2)Standalone:构建一个基于Mster+Slaves的资源调度集群,Spark任务提交给Master运行。是Spark自身的一个调度系统。
3)Yarn: Spark客户端直接连接Yarn,不需要额外构建Spark集群。有yarn-client和yarn-cluster两种模式,主要区别在于:Driver程序的运行节点。
4)Mesos:国内大环境比较少用。
三、Spark提交作业的参数
因为我们Spark任务是采用的Shell脚本进行提交,所以一定会涉及到几个重要的参数,而这个也是在面试的时候容易被考察到的“细节”。
executor-cores —— 每个executor使用的内核数,默认为1,官方建议2-5个,我们企业是4个
num-executors —— 启动executors的数量,默认为2
executor-memory —— executor内存大小,默认1G
driver-cores —— driver使用内核数,默认为1
driver-memory —— driver内存大小,默认512M
四、简述Spark的作业提交流程
Spark的任务提交方式实际上有两种,分别是YarnClient模式和YarnCluster模式。大家在回答这个问题的时候,也需要分类去介绍。千万不要被冗长的步骤吓到,一定要学会总结差异,发现规律,通过图形去增强记忆。
- YarnClient 运行模式介绍
 在YARN Client模式下,Driver在任务提交的本地机器上运行,Driver启动后会和ResourceManager通讯申请启动ApplicationMaster,随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster的功能相当于一个ExecutorLaucher,只负责向ResourceManager申请Executor内存。
在YARN Client模式下,Driver在任务提交的本地机器上运行,Driver启动后会和ResourceManager通讯申请启动ApplicationMaster,随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster的功能相当于一个ExecutorLaucher,只负责向ResourceManager申请Executor内存。
ResourceManager接到ApplicationMaster的资源申请后会分配container,然后ApplicationMaster在资源分配指定的NodeManager上启动Executor进程,Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数,之后执行到Action算子时,触发一个job,并根据宽依赖开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行。
- YarnCluster 模式介绍
 在YARN Cluster模式下,任务提交后会和ResourceManager通讯申请启动ApplicationMaster,随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster就是Driver。
在YARN Cluster模式下,任务提交后会和ResourceManager通讯申请启动ApplicationMaster,随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster就是Driver。
Driver启动后向ResourceManager申请Executor内存,ResourceManager接到ApplicationMaster的资源申请后会分配container,然后在合适的NodeManager上启动Executor进程,Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数,之后执行到Action算子时,触发一个job,并根据宽依赖开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行。
五、你是如何理解Spark中血统(RDD)的概念?它的作用是什么?
RDD 可是Spark中最基本的数据抽象,我想就算面试不被问到,那自己是不是也应该非常清楚呢!
下面提供菌哥的回答,供大家参考:
- 概念
RDD是弹性分布式数据集,是Spark中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算 的集合。
- 作用
提供了一个抽象的数据模型,将具体的应用逻辑表达为一系列转换操作(函数)。另外不同RDD之间的转换操作之间还可以形成依赖关系,进而实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘IO和序列化开销,并且还提供了更多的API(map/reduec/filter/groupBy…)
如果还想锦上添花,可以添上这一句:
“
RDD在Lineage依赖方面分为两种Narrow Dependencies与Wide Dependencies,用来解决数据容错时的高效性以及划分任务时候起到重要作用
”
六、简述Spark的宽窄依赖,以及Spark如何划分stage,每个stage又根据什么决定task个数?
Spark的宽窄依赖问题是SparkCore部分的重点考察内容,多数出现在笔试中,大家需要注意。
窄依赖:父RDD的一个分区只会被子RDD的一个分区依赖
宽依赖:父RDD的一个分区会被子RDD的多个分区依赖(涉及到shuffle)
那Stage是如何划分的呢?
根据RDD之间的依赖关系的不同将Job划分成不同的Stage,遇到一个宽依赖则划分一个Stage。
每个stage又根据什么决定task个数?
Stage是一个TaskSet,将Stage根据分区数划分成一个个的Task。
这里为了方便大家理解,贴上一张过程图

七、列举Spark常用的transformation和action算子,有哪些算子会导致Shuffle?
我们在Spark开发过程中,避不开与各种算子打交道,其中Spark 算子分为transformation 和 action 算子,下面列出一些常用的算子,具体的功能还需要小伙伴们自行去了解。
transformation
- map
- mapRartition
- flatMap
- filter
- …
action
- reduce
- collect
- first
- take
- …
如果面试官问你,那小伙几,有哪些会引起Shuffle过程的Spark算子呢?
你只管自信的回答:
- reduceByKey
- groupByKey
- …ByKey
八、reduceByKey与groupByKey的区别,哪一种更具优势?
既然你上面都提到 reduceByKey 和groupByKey ,那哪一种更具优势,你能简单分析一下吗?
能问这样的问题,已经暗示面试官的水平不低了,那么我们该如何回答呢:
reduceByKey:按照key进行聚合,在shuffle之前有combine(预聚合)操作,返回结果是RDD[k,v]。
groupByKey:按照key进行分组,直接进行shuffle
所以,在实际开发过程中,reduceByKey比groupByKey,更建议使用。但是需要注意是否会影响业务逻辑。
九、Repartition和Coalesce 的关系与区别,能简单说说吗?
这道题就已经开始掺和有“源码”的味道了,为什么呢?
1)关系:
两者都是用来改变RDD的partition数量的,repartition底层调用的就是coalesce方法:coalesce(numPartitions, shuffle = true)
2)区别:
repartition一定会发生shuffle,coalesce 根据传入的参数来判断是否发生shuffle。
一般情况下增大rdd的partition数量使用repartition,减少partition数量时使用coalesce。
十、简述下Spark中的缓存(cache和persist)与checkpoint机制,并指出两者的区别和联系
关于Spark缓存和检查点的区别,大致可以从这3个角度去回答:
- 位置
Persist 和 Cache将数据保存在内存,Checkpoint将数据保存在HDFS
- 生命周期
Persist 和 Cache 程序结束后会被清除或手动调用unpersist方法,Checkpoint永久存储不会被删除。
- RDD依赖关系
Persist 和 Cache,不会丢掉RDD间的依赖链/依赖关系,CheckPoint会斩断依赖链。
十一、简述Spark中共享变量(广播变量和累加器)的基本原理与用途
关于Spark中的广播变量和累加器的基本原理和用途,答案较为固定,大家无需刻意去记忆。
累加器(accumulator)是Spark中提供的一种分布式的变量机制,其原理类似于mapreduce,即分布式的改变,然后聚合这些改变。累加器的一个常见用途是在调试时对作业执行过程中的事件进行计数。
广播变量是在每个机器上缓存一份,不可变,只读的,相同的变量,该节点每个任务都能访问,起到节省资源和优化的作用。它通常用来高效分发较大的对象。
十二、当Spark涉及到数据库的操作时,如何减少Spark运行中的数据库连接数?
嗯,有点“调优”的味道,感觉真正的“风暴”即将到来,这道题还是很好回答的,我们只需要减少连接数据库的次数即可。
使用foreachPartition代替foreach,在foreachPartition内获取数据库的连接。
十三、能介绍下你所知道和使用过的Spark调优吗?
恐怖如斯,该来的还是会来的,庆幸自己看了菌哥的面试杀招,丝毫不慌:
资源参数调优
- num-executors:设置Spark作业总共要用多少个Executor进程来执行
- executor-memory:设置每个Executor进程的内存
- executor-cores:设置每个Executor进程的CPU core数量
- driver-memory:设置Driver进程的内存
- spark.default.parallelism:设置每个stage的默认task数量
- …
开发调优
- 避免创建重复的RDD
- 尽可能复用同一个RDD
- 对多次使用的RDD进行持久化
- 尽量避免使用shuffle类算子
- 使用map-side预聚合的shuffle操作
- 使用高性能的算子
“
①使用reduceByKey/aggregateByKey替代groupByKey
②使用mapPartitions替代普通map
③使用foreachPartitions替代foreach
④使用filter之后进行coalesce操作
⑤使用repartitionAndSortWithinPartitions替代repartition与sort类操作
”
- 广播大变量
“
在算子函数中使用到外部变量时,默认情况下,Spark会将该变量复制多个副本,通过网络传输到task中,此时每个task都有一个变量副本。如果变量本身比较大的话(比如100M,甚至1G),那么大量的变量副本在网络中传输的性能开销,以及在各个节点的Executor中占用过多内存导致的频繁GC(垃圾回收),都会极大地影响性能。
”
- 使用Kryo优化序列化性能
- 优化数据结构
“
在可能以及合适的情况下,使用占用内存较少的数据结构,但是前提是要保证代码的可维护性。
”
如果能够尽可能的把这些要点说出来,我想面试官可能就一个想法:
十四、如何使用Spark实现TopN的获取(描述思路或使用伪代码)?
能让你使用伪代码来描述这已经非常“苛刻”了,但是不慌,这里提供3种思路供大家参考:
- 方法1:
(1)按照key对数据进行聚合(groupByKey)
(2)将value转换为数组,利用scala的sortBy或者sortWith进行排序(mapValues)
注意:当数据量太大时,会导致OOM
- 方法2:
(1)取出所有的key
(2)对key进行迭代,每次取出一个key利用spark的排序算子进行排序
- 方法3:
(1)自定义分区器,按照key进行分区,使不同的key进到不同的分区
(2)对每个分区运用spark的排序算子进行排序
1、spark的有几种部署模式,每种模式特点?(☆☆☆☆☆)
本地模式
Spark不一定非要跑在hadoop集群,可以在本地,起多个线程的方式来指定。将Spark应用以多线程的方式直接运行在本地,一般都是为了方便调试,本地模式分三类
local:只启动一个executor
local[k]:启动k个executor
local[*]:启动跟cpu数目相同的 executor
standalone模式
分布式部署集群,自带完整的服务,资源管理和任务监控是Spark自己监控,这个模式也是其他模式的基础。
Spark on yarn模式
分布式部署集群,资源和任务监控交给yarn管理,但是目前仅支持粗粒度资源分配方式,包含cluster和client运行模式,cluster适合生产,driver运行在集群子节点,具有容错功能,client适合调试,dirver运行在客户端。
Spark On Mesos模式
官方推荐这种模式(当然,原因之一是血缘关系)。正是由于Spark开发之初就考虑到支持Mesos,因此,目前而言,Spark运行在Mesos上会比运行在YARN上更加灵活,更加自然。用户可选择两种调度模式之一运行自己的应用程序:
(1)粗粒度模式(Coarse-grained Mode):每个应用程序的运行环境由一个Dirver和若干个Executor组成,其中,每个Executor占用若干资源,内部可运行多个Task(对应多少个“slot”)。应用程序的各个任务正式运行之前,需要将运行环境中的资源全部申请好,且运行过程中要一直占用这些资源,即使不用,最后程序运行结束后,回收这些资源。
(2)细粒度模式(Fine-grained Mode):鉴于粗粒度模式会造成大量资源浪费,Spark On Mesos还提供了另外一种调度模式:细粒度模式,这种模式类似于现在的云计算,思想是按需分配。
2、Spark为什么比MapReduce块?(☆☆☆☆☆)
1)基于内存计算,减少低效的磁盘交互;
2)高效的调度算法,基于DAG;
3)容错机制Linage,精华部分就是DAG和Lingae
3、简单说一下hadoop和spark的shuffle相同和差异?(☆☆☆☆☆)
1)从 high-level 的角度来看,两者并没有大的差别。 都是将 mapper(Spark 里是 ShuffleMapTask)的输出进行 partition,不同的 partition 送到不同的 reducer(Spark 里 reducer 可能是下一个 stage 里的 ShuffleMapTask,也可能是 ResultTask)。Reducer 以内存作缓冲区,边 shuffle 边 aggregate 数据,等到数据 aggregate 好以后进行 reduce() (Spark 里可能是后续的一系列操作)。
2)从 low-level 的角度来看,两者差别不小。 Hadoop MapReduce 是 sort-based,进入 combine() 和 reduce() 的 records 必须先 sort。这样的好处在于 combine/reduce() 可以处理大规模的数据,因为其输入数据可以通过外排得到(mapper 对每段数据先做排序,reducer 的 shuffle 对排好序的每段数据做归并)。目前的 Spark 默认选择的是 hash-based,通常使用 HashMap 来对 shuffle 来的数据进行 aggregate,不会对数据进行提前排序。如果用户需要经过排序的数据,那么需要自己调用类似 sortByKey() 的操作;如果你是Spark 1.1的用户,可以将spark.shuffle.manager设置为sort,则会对数据进行排序。在Spark 1.2中,sort将作为默认的Shuffle实现。
3)从实现角度来看,两者也有不少差别。 Hadoop MapReduce 将处理流程划分出明显的几个阶段:map(), spill, merge, shuffle, sort, reduce() 等。每个阶段各司其职,可以按照过程式的编程思想来逐一实现每个阶段的功能。在 Spark 中,没有这样功能明确的阶段,只有不同的 stage 和一系列的 transformation(),所以 spill, merge, aggregate 等操作需要蕴含在 transformation() 中。
如果我们将 map 端划分数据、持久化数据的过程称为 shuffle write,而将 reducer 读入数据、aggregate 数据的过程称为 shuffle read。那么在 Spark 中,问题就变为怎么在 job 的逻辑或者物理执行图中加入 shuffle write 和 shuffle read的处理逻辑?以及两个处理逻辑应该怎么高效实现?
Shuffle write由于不要求数据有序,shuffle write 的任务很简单:将数据 partition 好,并持久化。之所以要持久化,一方面是要减少内存存储空间压力,另一方面也是为了 fault-tolerance。
4、Spark工作机制(☆☆☆☆☆)
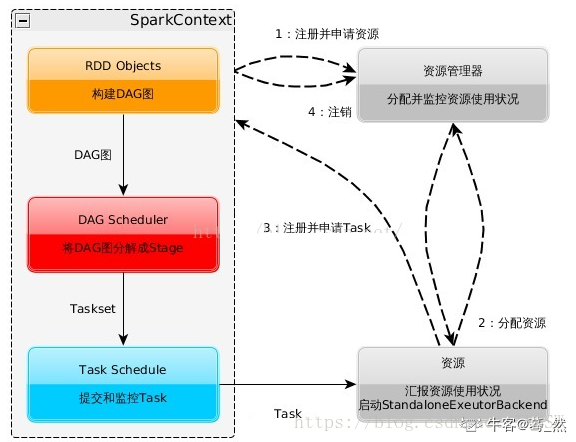
1)构建Application的运行环境,Driver创建一个SparkContext
val conf = new SparkConf(); conf.setAppName("test") conf.setMaster("local") val sc = new SparkContext(conf)
2)SparkContext向资源管理器(Standalone、Mesos、Yarn)申请Executor资源,资源管理器启动StandaloneExecutorbackend(Executor)
3)Executor向SparkContext申请Task
4)SparkContext将应用程序分发给Executor
5)SparkContext就建成DAG图,DAGScheduler将DAG图解析成Stage,每个Stage有多个task,形成taskset发送给task Scheduler,由task Scheduler将Task发送给Executor运行
6)Task在Executor上运行,运行完释放所有资源
5、Spark的优化怎么做?(☆☆☆☆☆)
Spark调优比较复杂,但是大体可以分为三个方面来进行
1)平台层面的调优:防止不必要的jar包分发,提高数据的本地性,选择高效的存储格式如parquet
2)应用程序层面的调优:过滤操作符的优化降低过多小任务,降低单条记录的资源开销,处理数据倾斜,复用RDD进行缓存,作业并行化执行等等
3)JVM层面的调优:设置合适的资源量,设置合理的JVM,启用高效的序列化方法如kyro,增大off head内存等等
6、数据本地性是在哪个环节确定的?(☆☆☆☆☆)
具体的task运行在那他机器上,DAG划分stage的时候确定的
7、RDD的弹性表现在哪几点?(☆☆☆☆☆)
1)存储的弹性:内存与磁盘的自动切换
Spark优先把数据放到内存中,如果内存放不下,就会放到磁盘里面,程序进行自动的存储切换
2)容错的弹性:数据丢失可以自动恢复
在RDD进行转换和动作的时候,会形成RDD的Lineage依赖链,当某一个RDD失效的时候,可以通过重新计算上游的RDD来重新生成丢失的RDD数据
3)计算的弹性:计算出重试机制
(1)Task如果失败会自动进行特定次数的重试
RDD的计算任务如果运行失败,会自动进行任务的重新计算,默认次数是4次
(2)Stage如果失败会自动进行特定次数的重试
如果Job的某个Stage阶段计算失败,框架也会自动进行任务的重新计算,默认次数也是4次
4)分片的弹性:可根据需要重新分片
可以根据业务的特征,动态调整数据分片的个数,提升整体的应用执行效率
5)Checkpoint和Persist可主动或被动触发
RDD可以通过Persist持久化将RDD缓存到内存或者磁盘,当再次用到该RDD时直接读取就行。也可以将RDD进行检查点,检查点会将数据存储在HDFS中,该RDD的所有父RDD依赖都会被移除
8、RDD有哪些缺陷?(☆☆☆☆☆)
1)不支持细粒度的写和更新操作(如网络爬虫),spark写数据是粗粒度的。所谓粗粒度,就是批量写入数据,为了提高效率。但是读数据是细粒度的也就是说可以一条条的读
2)不支持增量迭代计算,Flink支持
9、Spark的Shuffle过程(☆☆☆☆☆)
Shuffle核心要点
ShuffleMapStage与ResultStage
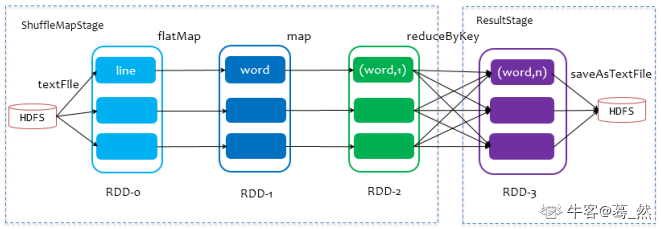
在划分stage时,最后一个stage称为FinalStage,它本质上是一个ResultStage对象,前面的所有stage被称为ShuffleMapStage。
ShuffleMapStage的结束伴随着shuffle文件的写磁盘。
ResultStage基本上对应代码中的action算子,即将一个函数应用在RDD的各个partition的数据集上,意味着一个job的运行结束。
Shuffle中的任务个数
我们知道,Spark Shuffle分为map阶段和reduce阶段,或者称之为ShuffleRead阶段和ShuffleWrite阶段,那么对于一次Shuffle,map过程和reduce过程都会由若干个task来执行,那么map task和reduce task的数量是如何确定的呢?
假设Spark任务从HDFS中读取数据,那么初始RDD分区个数由该文件的split个数决定,也就是一个split对应生成的RDD的一个partition,我们假设初始partition个数为N。
初始RDD经过一系列算子计算后(假设没有执行repartition和coalesce算子进行重分区,则分区个数不变,仍为N,如果经过重分区算子,那么分区个数变为M),我们假设分区个数不变,当执行到Shuffle操作时,map端的task个数和partition个数一致,即map task为N个。
reduce端的stage默认取spark.default.parallelism这个配置项的值作为分区数,如果没有配置,则以map端的最后一个RDD的分区数作为其分区数(也就是N),那么分区数就决定了reduce端的task的个数。
reduce端数据的读取
根据stage的划分我们知道,map端task和reduce端task不在相同的stage中,map task位于ShuffleMapStage,reduce task位于ResultStage,map task会先执行,那么后执行的reduce task如何知道从哪里去拉取map task落盘后的数据呢?
reduce端的数据拉取过程如下:
1)map task执行完毕后会将计算状态以及磁盘小文件位置等信息封装到MapStatus对象中,然后由本进程中的MapOutPutTrackerWorker对象将mapStatus对象发送给Driver进程的MapOutPutTrackerMaster对象;
2)在reduce task开始执行之前会先让本进程中的MapOutputTrackerWorker向Driver进程中的MapoutPutTrakcerMaster发动请求,请求磁盘小文件位置信息;
3)当所有的Map task执行完毕后,Driver进程中的MapOutPutTrackerMaster就掌握了所有的磁盘小文件的位置信息。此时MapOutPutTrackerMaster会告诉MapOutPutTrackerWorker磁盘小文件的位置信息;
4)完成之前的操作之后,由BlockTransforService去Executor0所在的节点拉数据,默认会启动五个子线程。每次拉取的数据量不能超过48M(reduce task每次最多拉取48M数据,将拉来的数据存储到Executor内存的20%内存中)。
Shuffle过程介绍
Shuffle Writer
Spark丰富了任务类型,有些任务之间数据流转不需要通过Shuffle,但是有些任务之间还是需要通过Shuffle来传递数据,比如wide dependency的group by key。
Spark中需要Shuffle输出的Map任务会为每个Reduce创建对应的bucket,Map产生的结果会根据设置的partitioner得到对应的bucketId,然后填充到相应的bucket中去。每个Map的输出结果可能包含所有的Reduce所需要的数据,所以每个Map会创建R个bucket(R是reduce的个数),M个Map总共会创建M*R个bucket。
Map创建的bucket其实对应磁盘上的一个文件,Map的结果写到每个bucket中其实就是写到那个磁盘文件中,这个文件也被称为blockFile,是Disk Block Manager管理器通过文件名的Hash值对应到本地目录的子目录中创建的。每个Map要在节点上创建R个磁盘文件用于结果输出,Map的结果是直接输出到磁盘文件上的,100KB的内存缓冲是用来创建Fast Buffered OutputStream输出流。这种方式一个问题就是Shuffle文件过多。
针对上述Shuffle过程产生的文件过多问题,Spark有另外一种改进的Shuffle过程:consolidation Shuffle,以期显著减少Shuffle文件的数量。在consolidation Shuffle中每个bucket并非对应一个文件,而是对应文件中的一个segment部分。Job的map在某个节点上第一次执行,为每个reduce创建bucket对应的输出文件,把这些文件组织成ShuffleFileGroup,当这次map执行完之后,这个ShuffleFileGroup可以释放为下次循环利用;当又有map在这个节点上执行时,不需要创建新的bucket文件,而是在上次的ShuffleFileGroup中取得已经创建的文件继续追加写一个segment;当前次map还没执行完,ShuffleFileGroup还没有释放,这时如果有新的map在这个节点上执行,无法循环利用这个ShuffleFileGroup,而是只能创建新的bucket文件组成新的ShuffleFileGroup来写输出。
比如一个Job有3个Map和2个reduce:(1) 如果此时集群有3个节点有空槽,每个节点空闲了一个core,则3个Map会调度到这3个节点上执行,每个Map都会创建2个Shuffle文件,总共创建6个Shuffle文件;(2) 如果此时集群有2个节点有空槽,每个节点空闲了一个core,则2个Map先调度到这2个节点上执行,每个Map都会创建2个Shuffle文件,然后其中一个节点执行完Map之后又调度执行另一个Map,则这个Map不会创建新的Shuffle文件,而是把结果输出追加到之前Map创建的Shuffle文件中;总共创建4个Shuffle文件;(3) 如果此时集群有2个节点有空槽,一个节点有2个空core一个节点有1个空core,则一个节点调度2个Map一个节点调度1个Map,调度2个Map的节点上,一个Map创建了Shuffle文件,后面的Map还是会创建新的Shuffle文件,因为上一个Map还正在写,它创建的ShuffleFileGroup还没有释放;总共创建6个Shuffle文件。
Shuffle Fetcher
Reduce去拖Map的输出数据,Spark提供了两套不同的拉取数据框架:
1)通过socket连接去取数据
2)使用netty框架去取数据
每个节点的Executor会创建一个BlockManager,其中会创建一个BlockManagerWorker用于响应请求。当Reduce的GET_BLOCK的请求过来时,读取本地文件将这个blockId的数据返回给Reduce。如果使用的是Netty框架,BlockManager会创建ShuffleSender用于发送Shuffle数据。
并不是所有的数据都是通过网络读取,对于在本节点的Map数据,Reduce直接去磁盘上读取而不再通过网络框架。
Reduce拖过来数据之后以什么方式存储呢?Spark Map输出的数据没有经过排序,Spark Shuffle过来的数据也不会进行排序,Spark认为Shuffle过程中的排序不是必须的,并不是所有类型的Reduce需要的数据都需要排序,强制地进行排序只会增加Shuffle的负担。Reduce拖过来的数据会放在一个HashMap中,HashMap中存储的也是<key, value>对,key是Map输出的key,Map输出对应这个key的所有value组成HashMap的value。Spark将Shuffle取过来的每一个<key, value>对插入或者更新到HashMap中,来一个处理一个。HashMap全部放在内存中。
Shuffle取过来的数据全部存放在内存中,对于数据量比较小或者已经在Map端做过合并处理的Shuffle数据,占用内存空间不会太大,但是对于比如group by key这样的操作,Reduce需要得到key对应的所有value,并将这些value组一个数组放在内存中,这样当数据量较大时,就需要较多内存。
当内存不够时,要不就失败,要不就用老办法把内存中的数据移到磁盘上放着。Spark意识到在处理数据规模远远大于内存空间时所带来的不足,引入了一个具有外部排序的方案。Shuffle过来的数据先放在内存中,当内存中存储的<key, value>对超过1000并且内存使用超过70%时,判断节点上可用内存如果还足够,则把内存缓冲区大小翻倍,如果可用内存不再够了,则把内存中的<key, value>对排序然后写到磁盘文件中。最后把内存缓冲区中的数据排序之后和那些磁盘文件组成一个最小堆,每次从最小堆中读取最小的数据,这个和MapReduce中的merge过程类似。
MapReduce和Spark的Shuffle过程对比
| MapReduce | Spark | |
|---|---|---|
| collect | 在内存中构造了一块数据结构用于map输出的缓冲 | 没有在内存中构造一块数据结构用于map输出的缓冲,而是直接把输出写到磁盘文件 |
| sort | map输出的数据有排序 | map输出的数据没有排序 |
| merge | 对磁盘上的多个spill文件最后进行合并成一个输出文件 | 在map端没有merge过程,在输出时直接是对应一个reduce的数据写到一个文件中,这些文件同时存在并发写,最后不需要合并成一个 |
| copy框架 | jetty | netty或者直接socket流 |
| 对于本节点上的文件 | 仍然是通过网络框架拖取数据 | 不通过网络框架,对于在本节点上的map输出文件,采用本地读取的方式 |
| copy过来的数据存放位置 | 先放在内存,内存放不下时写到磁盘 | 一种方式全部放在内存;另一种方式先放在内存 |
| merge sort | 最后会对磁盘文件和内存中的数据进行合并排序 | 对于采用另一种方式时也会有合并排序的过程 |
Shuffle后续优化方向
通过上面的介绍,我们了解到,Shuffle过程的主要存储介质是磁盘,尽量的减少IO是Shuffle的主要优化方向。我们脑海中都有那个经典的存储金字塔体系,Shuffle过程为什么把结果都放在磁盘上,那是因为现在内存再大也大不过磁盘,内存就那么大,还这么多张嘴吃,当然是分配给最需要的了。如果具有“土豪”内存节点,减少Shuffle IO的最有效方式无疑是尽量把数据放在内存中。下面列举一些现在看可以优化的方面,期待经过我们不断的努力,TDW计算引擎运行地更好。
MapReduce Shuffle后续优化方向
-
压缩:对数据进行压缩,减少写读数据量;
-
减少不必要的排序:并不是所有类型的Reduce需要的数据都是需要排序的,排序这个nb的过程如果不需要最好还是不要的好;
-
内存化:Shuffle的数据不放在磁盘而是尽量放在内存中,除非逼不得已往磁盘上放;当然了如果有性能和内存相当的第三方存储系统,那放在第三方存储系统上也是很好的;这个是个大招;
-
网络框架:netty的性能据说要占优了;
-
本节点上的数据不走网络框架:对于本节点上的Map输出,Reduce直接去读吧,不需要绕道网络框架。
Spark Shuffle后续优化方向
Spark作为MapReduce的进阶架构,对于Shuffle过程已经是优化了的,特别是对于那些具有争议的步骤已经做了优化,但是Spark的Shuffle对于我们来说在一些方面还是需要优化的。
-
压缩:对数据进行压缩,减少写读数据量;
-
内存化:Spark历史版本中是有这样设计的:Map写数据先把数据全部写到内存中,写完之后再把数据刷到磁盘上;考虑内存是紧缺资源,后来修改成把数据直接写到磁盘了;对于具有较大内存的集群来讲,还是尽量地往内存上写吧,内存放不下了再放磁盘。
-
面试题1:Spark 运行架构的特点是什么?
答案:每个 Application 获取专属的 executor 进程,该进程在 Application 期间一直驻留,并以多线程方式运行 tasks。Spark 任务与资源管理器无关,只要能够获取 executor 进程,并能保持相互通信就可以了。提交 SparkContext 的 Client 应该靠近 Worker 节点(运行 Executor 的节点),最好是在同一个 Rack 里,因为 Spark 程序运行过程中 SparkContext 和Executor 之间有大量的信息交换;如果想在远程集群中运行,最好使用 RPC 将SparkContext 提交给集群,不要远离 Worker 运行 SparkContext。Task 采用了数据本地性和推测执行的优化机制。
面试题2:描述一下Spark运行的基本流程。
答案:这个是面试大数据岗位的一道基础题。Spark 运行基本流程可以参考下面的示意图:
面试题3:Spark 中的 RDD 是什么?
答案:RDD(Resilient Distributed Dataset)叫做分布式数据集,是 Spark 中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD 中的数据可以存储在内存或者是磁盘,而且RDD 中的分区是可以改变的。
面试题4:Spark 中的常用算子有哪些区别?
答案:map : 用 于 遍 历 RDD , 将 函 数 f 应 用 于 每 一 个 元 素 , 返 回 新 的
RDD(transformation 算子);foreach:用于遍历 RDD,将函数 f 应用于每一个元素,无返回值(action 算子);mapPartitions:用于遍历操作 RDD 中的每一个分区,返回生成一个新的RDD(transformation 算子);foreachPartition: 用于遍历操作 RDD 中的每一个分区。无返回值(action 算子)。总结的来说,一般使用 mapPartitions 或者 foreachPartition 算子比 map 和 foreach更加高效,推荐使用。
面试题5:spark 中 cache 和 persist 有什么区别?
答案:cache:缓存数据,默认是缓存在内存中,其本质还是调用 persist;persist:缓存数据,有丰富的数据缓存策略。数据可以保存在内存也可以保存在磁盘中,使用的时候指定对应的缓存级别就可以了。
面试题6:如何解决 spark 中的数据倾斜问题?
答案:这也是在大数据岗位上会常常遇到的问题,当我们发现数据倾斜的时候,不要急于提高 executor 的资源,修改参数或是修改程序,首先要检查数据本身,是否存在异常数据。如果是数据问题造成的数据倾斜,找出异常的 key,如果任务长时间卡在最后最后 1 个(几个)任务,首先要对 key 进行抽样分析,判断是哪些 key 造成的。选取 key,对数据进行抽样,统计出现的次数,根据出现次数大小排序取出前几个。
面试题7:谈谈 你对spark中宽窄依赖的认识。
答案:RDD 和它依赖的父 RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。宽依赖指的是多个子 RDD 的 Partition 会依赖同一个父 RDD 的 Partition窄依赖:指的是每一个父 RDD 的 Partition 最多被子 RDD 的一个 Partition使用。

















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









