






目录
1.前言
通过自己搭建的神经网络模型,在PC上训练Cifar-10数据集,生成模型文件,将其部署到STM32F4控制器上。测试时,使用串口工具将测试图像的数据发送给STM32,串口输出分类识别结果。
2.神经网络设计和模型训练
2.1 数据集
Cifar-10数据集由 10 个类的60000 张 32x32彩色图像组成,50000张训练图像和10000张测试图像,每类6000张图像。数据集中的类别包括飞机、汽车、鸟类、猫、鹿、狗、青蛙、马、船和卡车。

获取方式:
1. cifar-10数据集官方下载地址:CIFAR-10 and CIFAR-100 datasets
2. python下载(下载可能有点慢):
# x_train_original和y_train_original代表训练集的图像与标签, x_test_original与y_test_original代表测试集的图像与标签
(x_train_original, y_train_original), (x_test_original, y_test_original) = cifar10.load_data()2.2 网络设计
与其称网络设计,我更愿称之为“反复尝试+开盲盒”,其实网络设计最终目的是能够在有限的STM32资源上,加载模型,顺利通过编译,预留出一些代码空间,资源利用最大化。
废话不多说,这里先附上我的训练模型(识别率91%):
本案例神经网络模型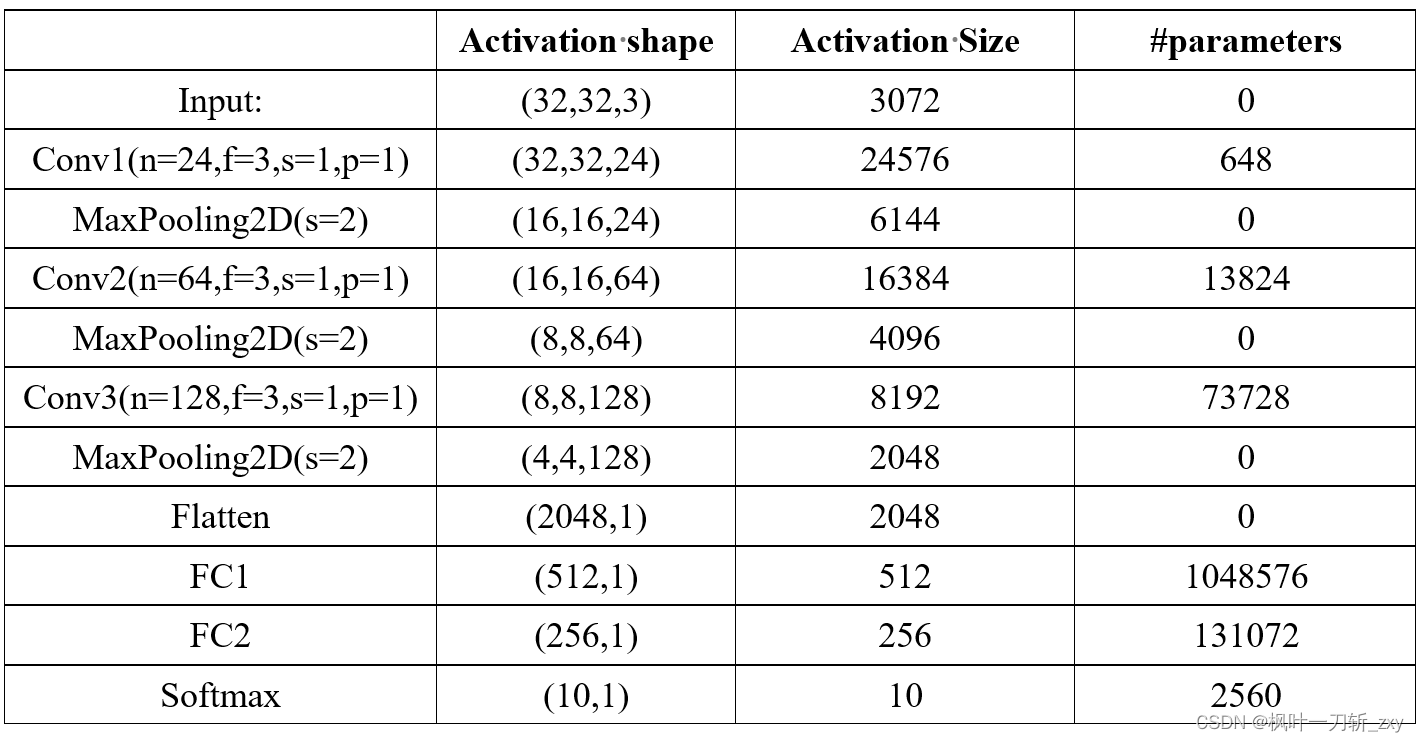
神经网络模型由三个卷积层,三个全连接层构成,其中:n为卷积核个数,f是卷积核尺寸,s是步长,p为Padding,我为了方便参数计算,上表parameters中忽略了偏置参数。其中Activation Size主要影响RAM,parameters主要影响ROM。
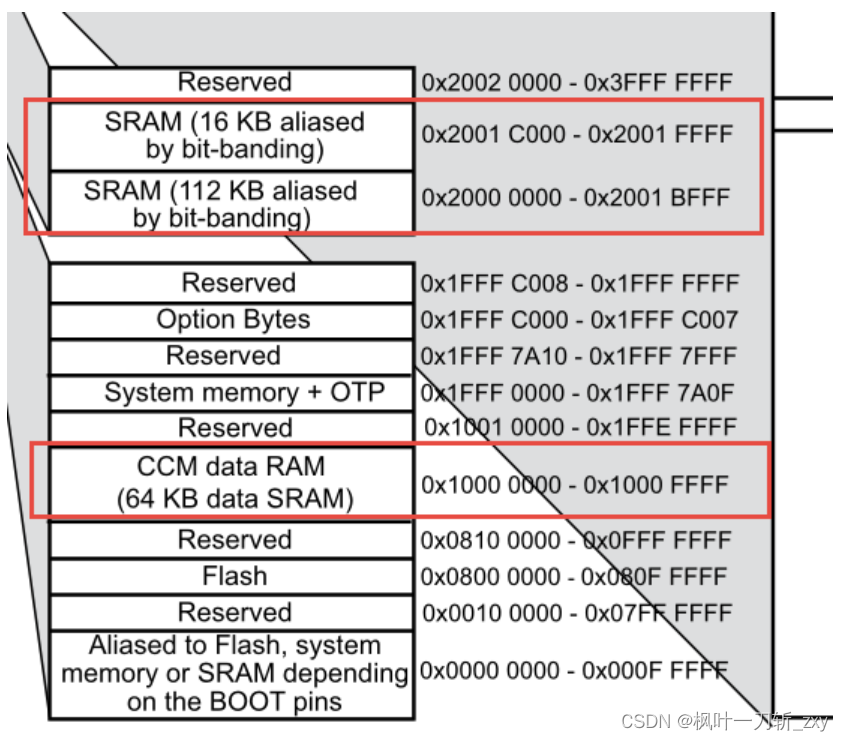
本人使用的是STM32F407ZGT6控制器,可用ROM(1MB),模型的权重参数主要是保存在ROM上的,一般模型大小20MB以下经过高压缩率都能上ROM。其实, 能否部署成功的主要影响因素是RAM,这是因为虽然STM32F407 的可用 RAM 是192KB,但这 192 KB不是连续的,而是分了三块,其中只有两块是连续的,分别是SRAM1(112KB)和SRAM2(16KB),另一块内存CCM的起始地址是 0x10000000,和SRAM的内存地址是分开的。由于STM32F4 没有 MMU 这样的内存管理单元,可以将连续的虚拟内核地址翻译到非连续的物理地址,所以程序中已初始化的数组长度就不能超过128KB了。
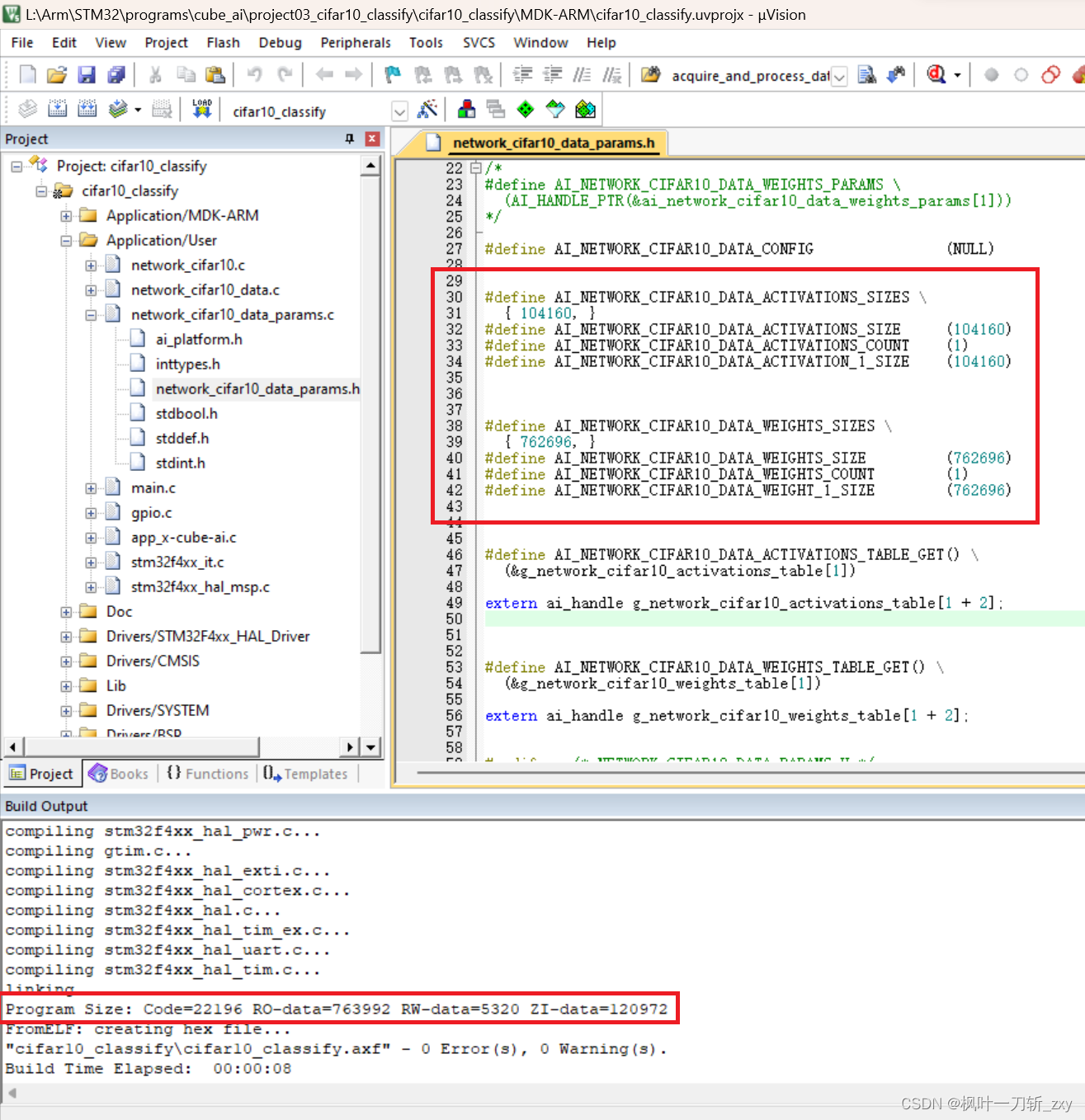
我们可以看一下模型的分析数据,主要了解ROM和RAM占用情况,可以看到,模型文件经压缩后,权重参数是放在ROM上的,Activations是放在RAM上。
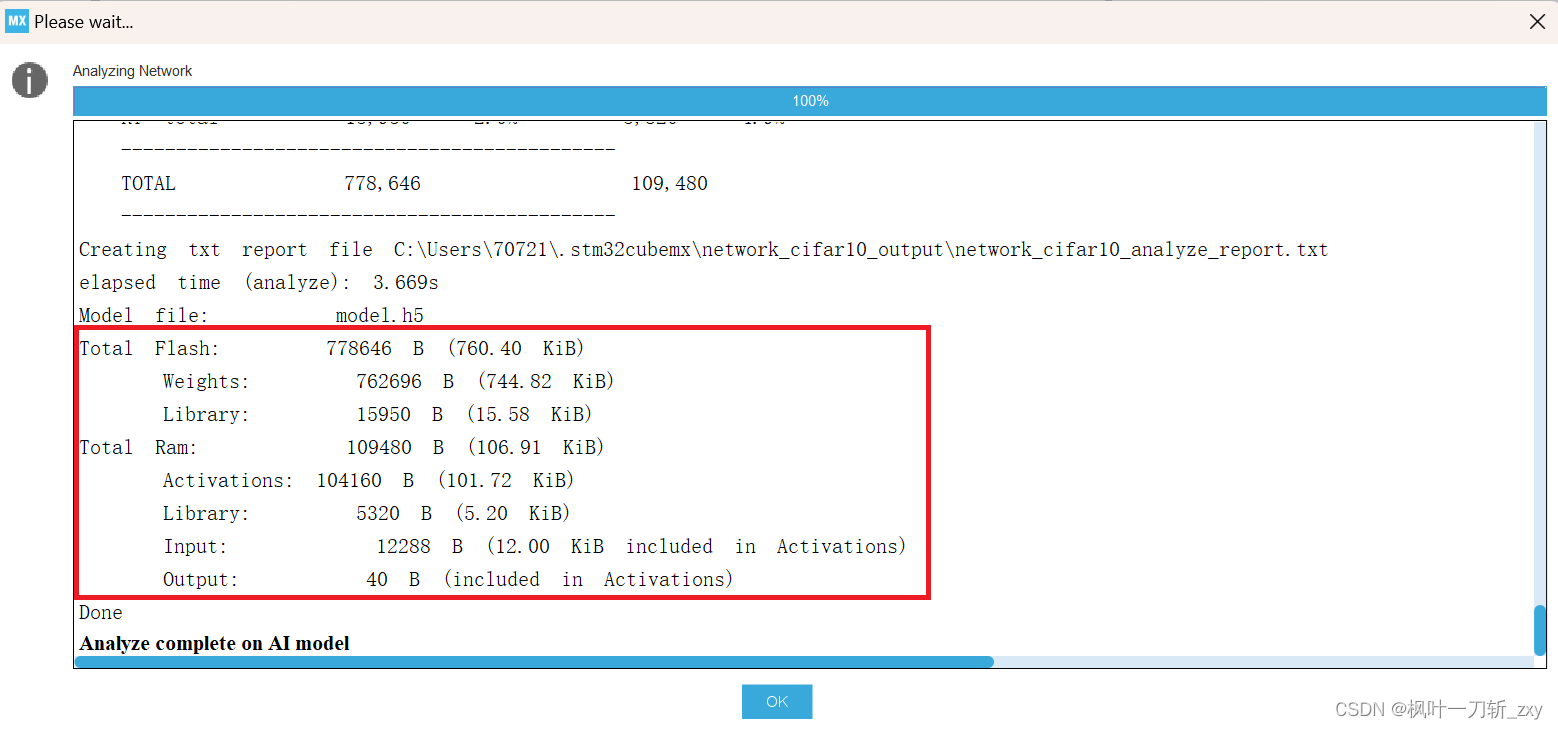
结合STM32F407控制器的硬件资源,所以这里先给出一个模型可部署的必要不充分条件:Activations大小不超过128KB。
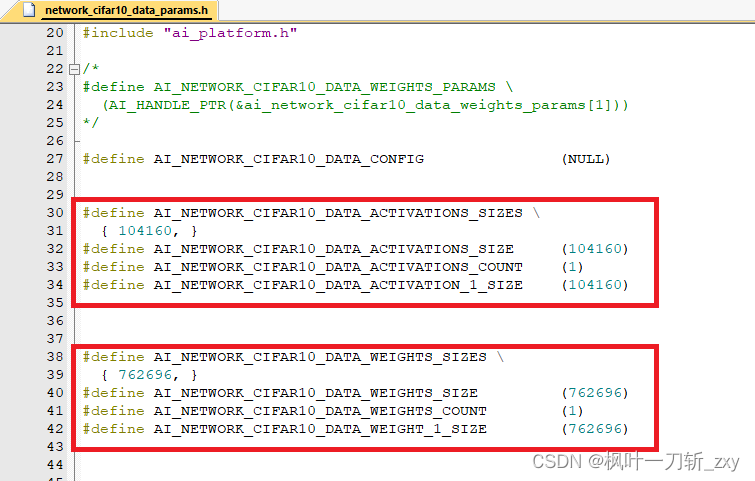
从下图中可以看到,Activations对应宏“AI_NETWORK_CIFAR10_DATA_ACTIVATIONS_SIZE”大小,并且作为数组pool0的数组长度,其在后续引导程序中被初始化。
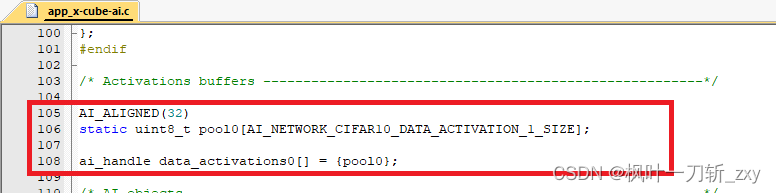
但实际上,在CubeMX构建工程时, 默认对SRAM进行了划区(分为112KB和16KB),如下图所示。所以在不手动重新分配的情况下,Activations大小最好不要超过112KB。
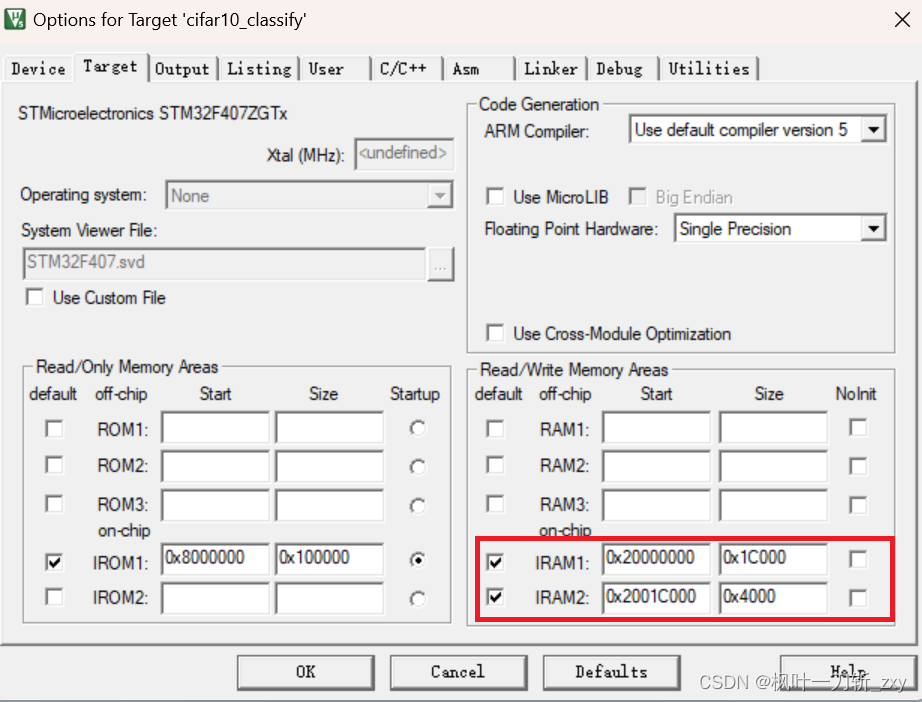
结合上述情况,这里我们做个简单的试验,新建一个HAL最小系统工程,将SRAM划区分配,分别为112KB和16KB,定义和初始化使用一个数组。
1. 当数组长度为112KB,编译可以通过。
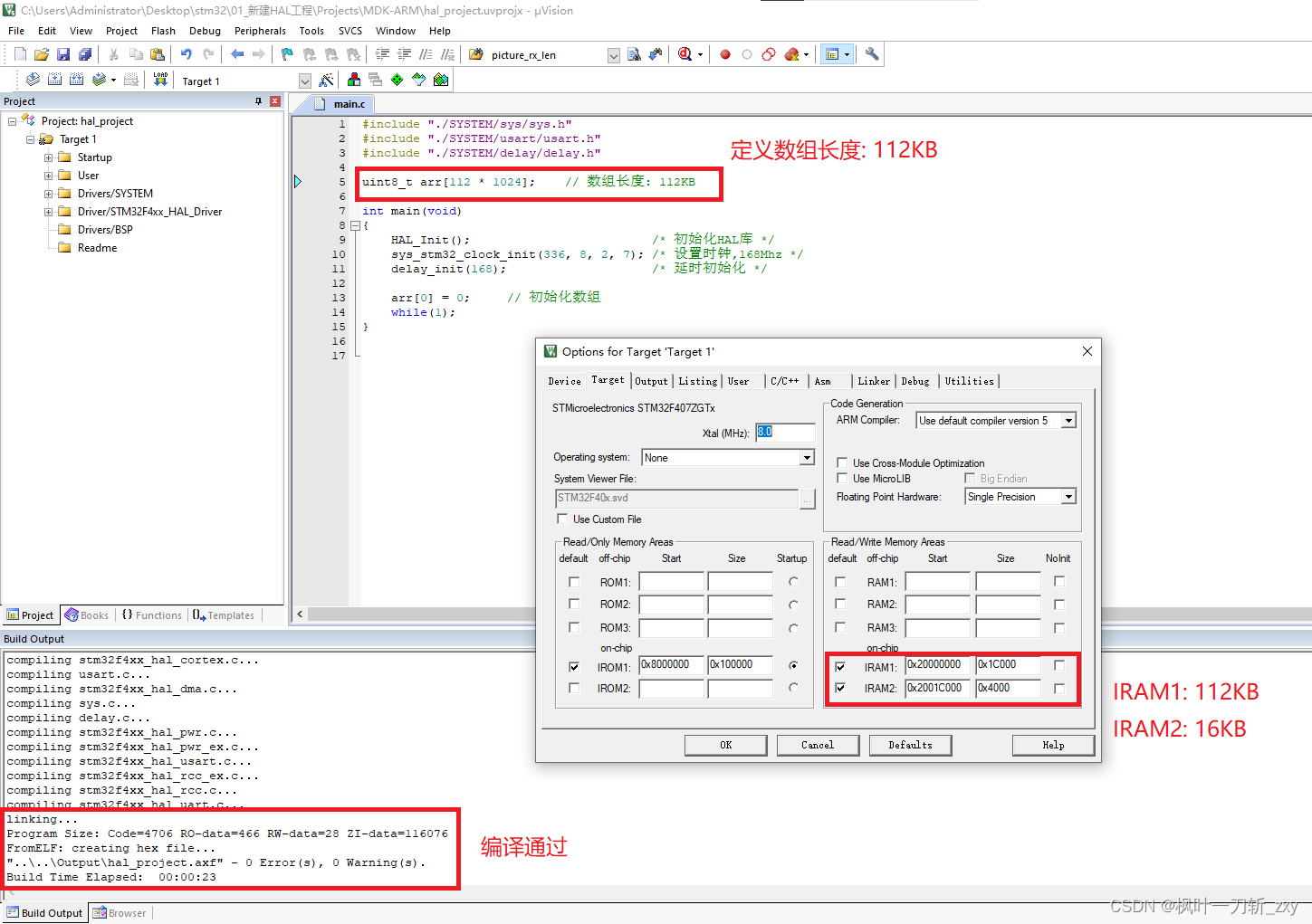
2. 当数组长度为112KB+1时,编译无法通过。
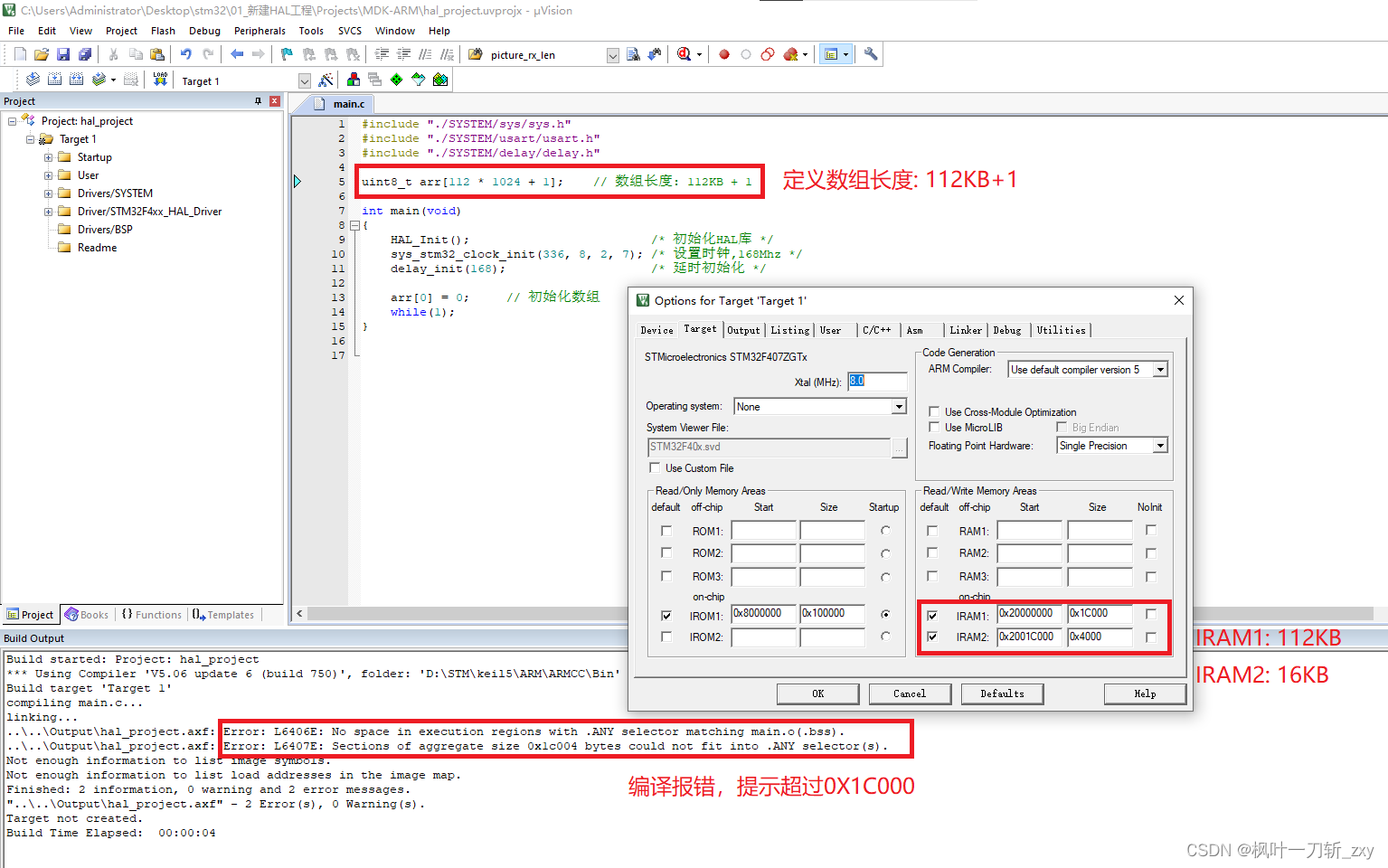
3. 当把128KB的SRAM整体不划区分配,数组长度112KB+1时,即可编译再次通过。
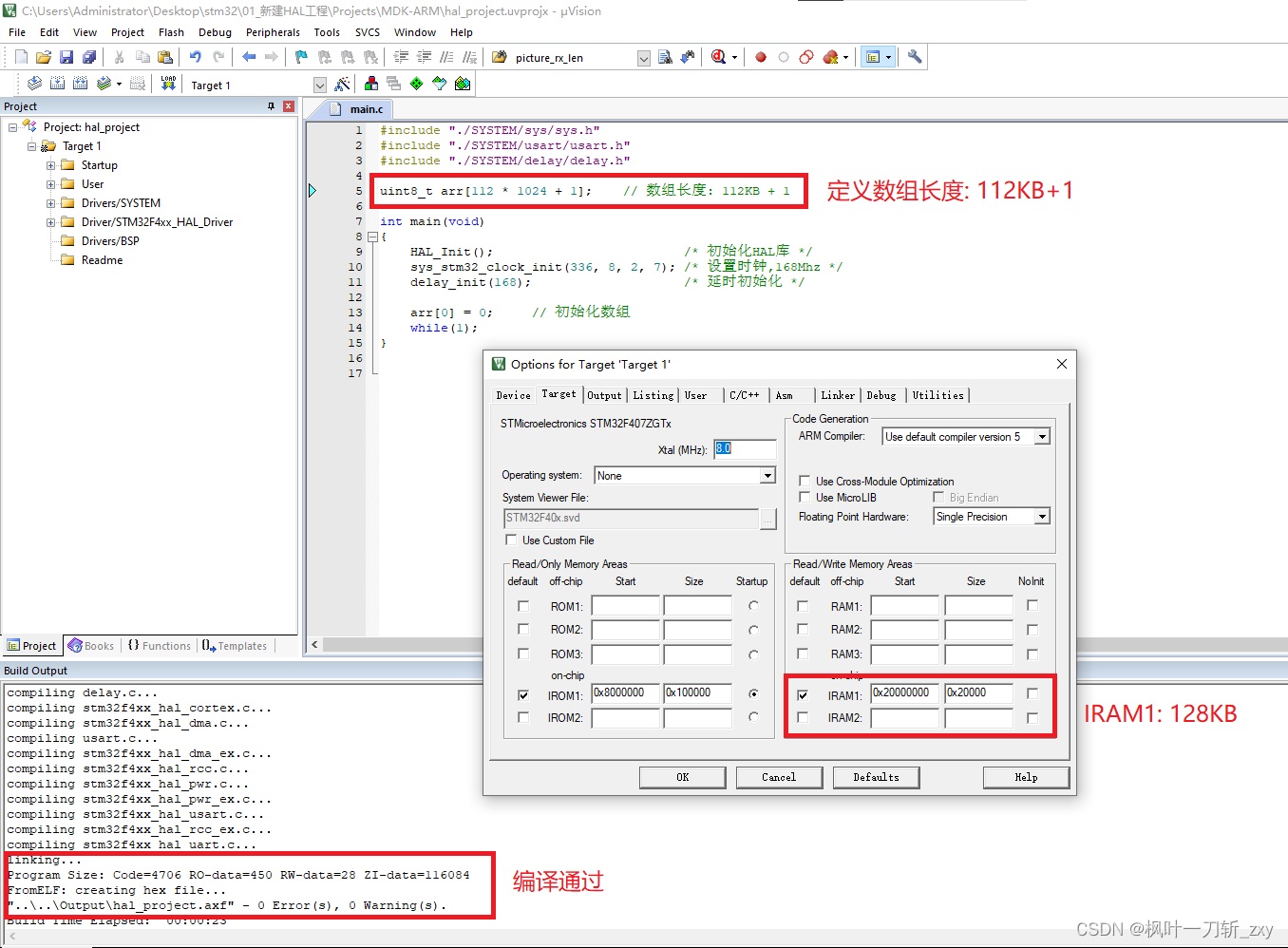
在实际模型部署时,往往会出现ROM够用而RAM不足的情况,要不断关注Actications的大小或者它对应的宏定义大小。
综上,我的神经网络的设计思路大致是:
步骤1:先估算下程序RAM占用空间,确定网络的卷积层数,以及全连接的层数和每层的维度大小。全连接层主要以权重参数为主,维度过高也可能会导致ROM不够用,亦或模型“死记硬背”。
步骤2:尝试设定第一层卷积核数量,初步部署并了解RAM占用情况。由于Activation Size大小主要还是集中在第一次卷积和池化,所以卷积核数量可先设定小一些的,比如:4。
步骤3:随后设定尝试后续层的卷积核数量,查看内存占用。
步骤4:在不断调整后续层的数量的同时,RAM容量允许的情况下,尝试增加第一层的卷积核数量。比如后续8,16的时候,稍微提高第一层至8。
步骤5:重复执行步骤3和步骤4,直到RAM占用达至预期。
步骤6:如果模型不理想,return 步骤1。
经过若干次开盲盒,最后网络模型如下:
def res_model():
input_shape = Input(shape=(32, 32, 3))
x = Conv2D(filters=24, kernel_size=(2, 2), padding='same', activation='relu')(input_shape)
x = BatchNormalization()(x)
x = MaxPooling2D(pool_size=(2, 2), strides=(2, 2))(x)
x = Conv2D(filters=64, kernel_size=(2, 2), padding='same', activation='relu')(x)
x = BatchNormalization()(x)
x = MaxPooling2D(pool_size=(2, 2), strides=(2, 2))(x)
x = Conv2D(filters=128, kernel_size=(2, 2), padding='same', activation='relu')(x)
x = BatchNormalization()(x)
x = MaxPooling2D(pool_size=(2, 2), strides=(2, 2))(x)
x = Flatten()(x)
x = Dense(512, activation='relu')(x)
x = Dropout(0.5)(x)
x = Flatten()(x)
x = Dense(256, activation='relu')(x)
x = Dropout(0.5)(x)
output = Dense(10, activation='softmax')(x)
model = tf.keras.Model(input_shape, output)
validity = model(input_shape)
return Model(input_shape, validity)编译后空间占用如下:
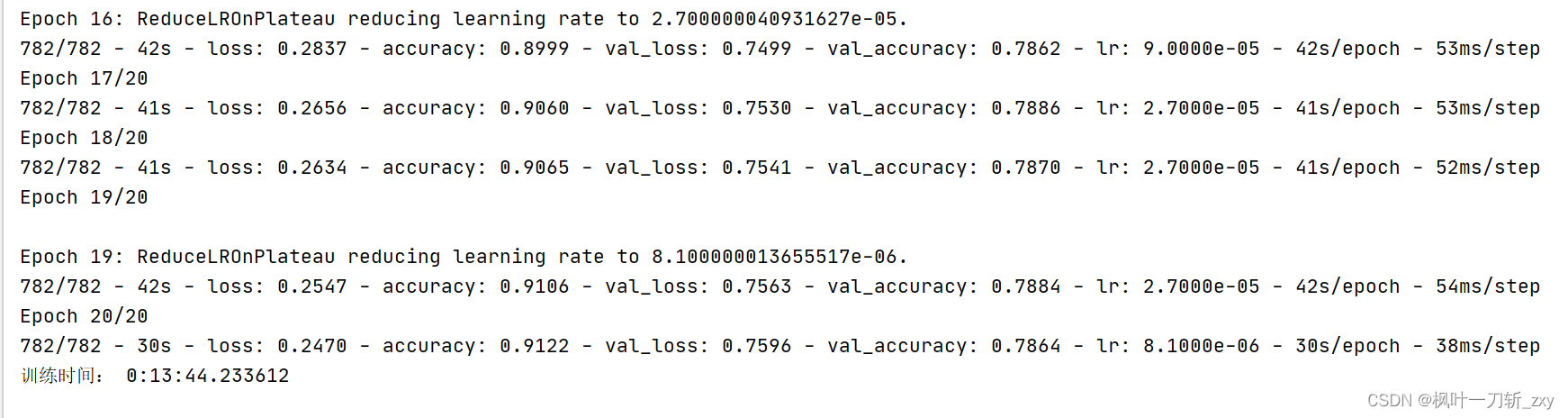
2.3 训练结果
所使用的Keras版本是2.1.2,训练结果如下 :
生成的model.h5模型大小14M :

3.配置CubeMX和Keil环境
在配置CubeMX和Keil环境之前,CubeMX需要安装STM32F4对应的MCU包和X-CUBE-AI组件(已安装的可跳过),MCU包可以用来构建HAL库代码,X-CUBE-AI组件作为中间件用于模型部署,如下图所示:
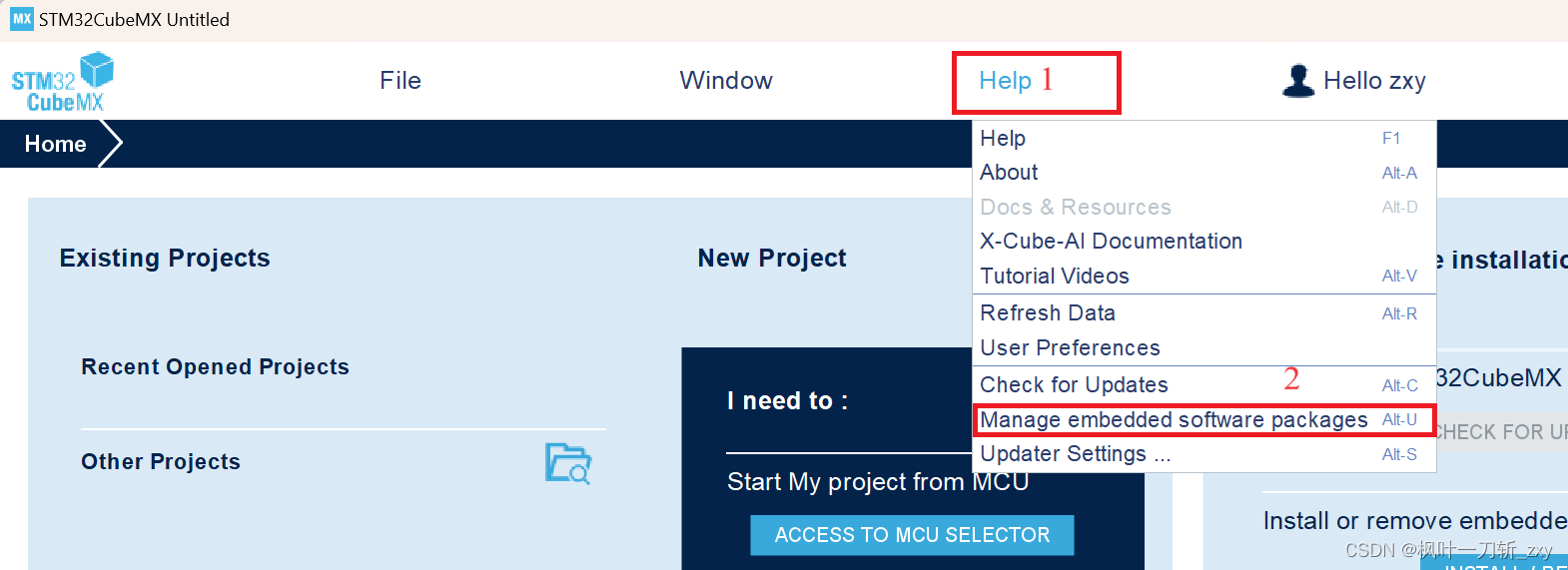
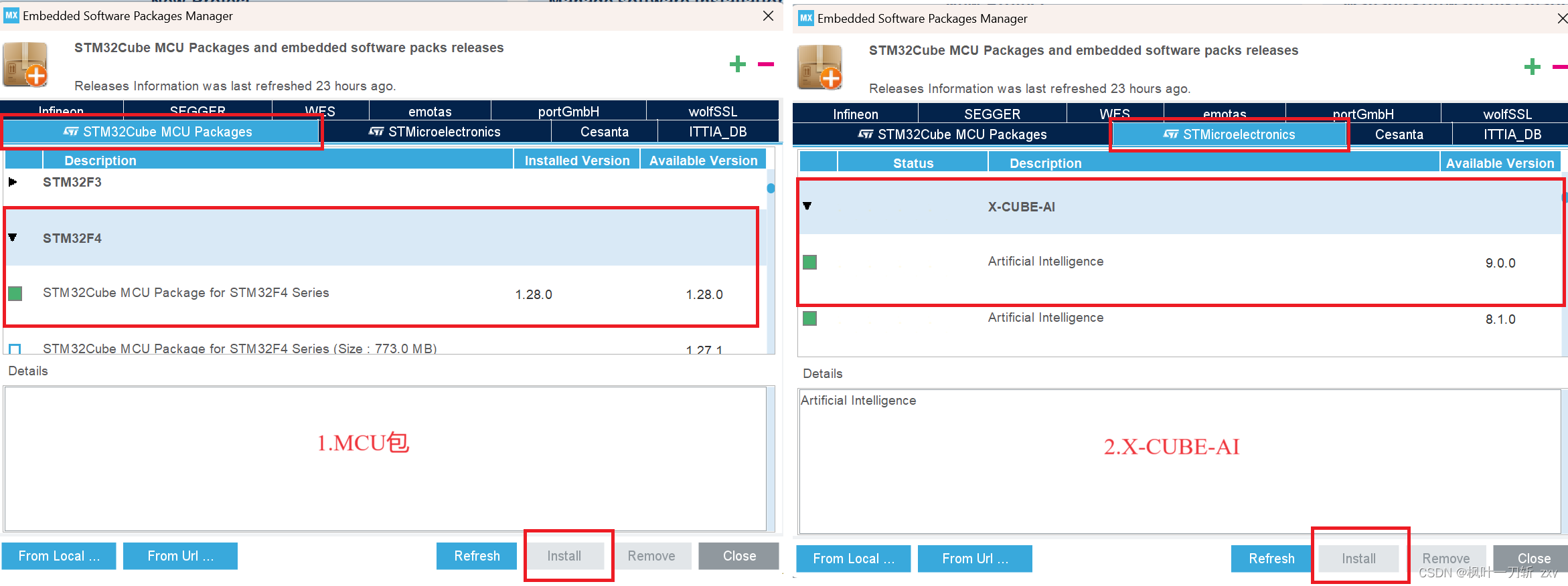
选择安装对应STM32控制器型号的 MCU包,勾选前面方格,点击右下角install即可。X-CUBE-AI组件选择对应版本的进行安装,我这里安装了若干个版本(前面的绿色方块表示已安装),一般只需安装最新版即可,不过有的模型文件需要低版本才能部署,亲测。
3.1 配置CubeMX
这里详细记录一下项目搭建过程:
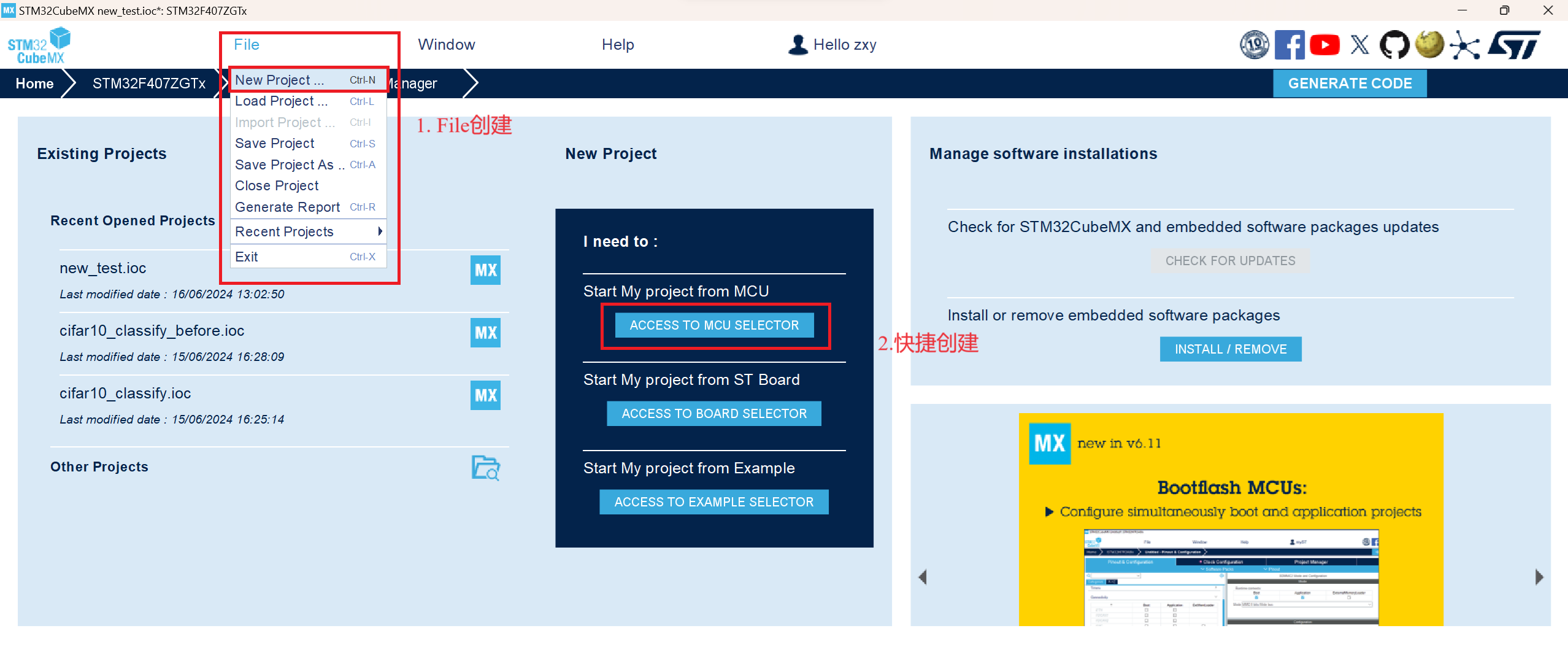
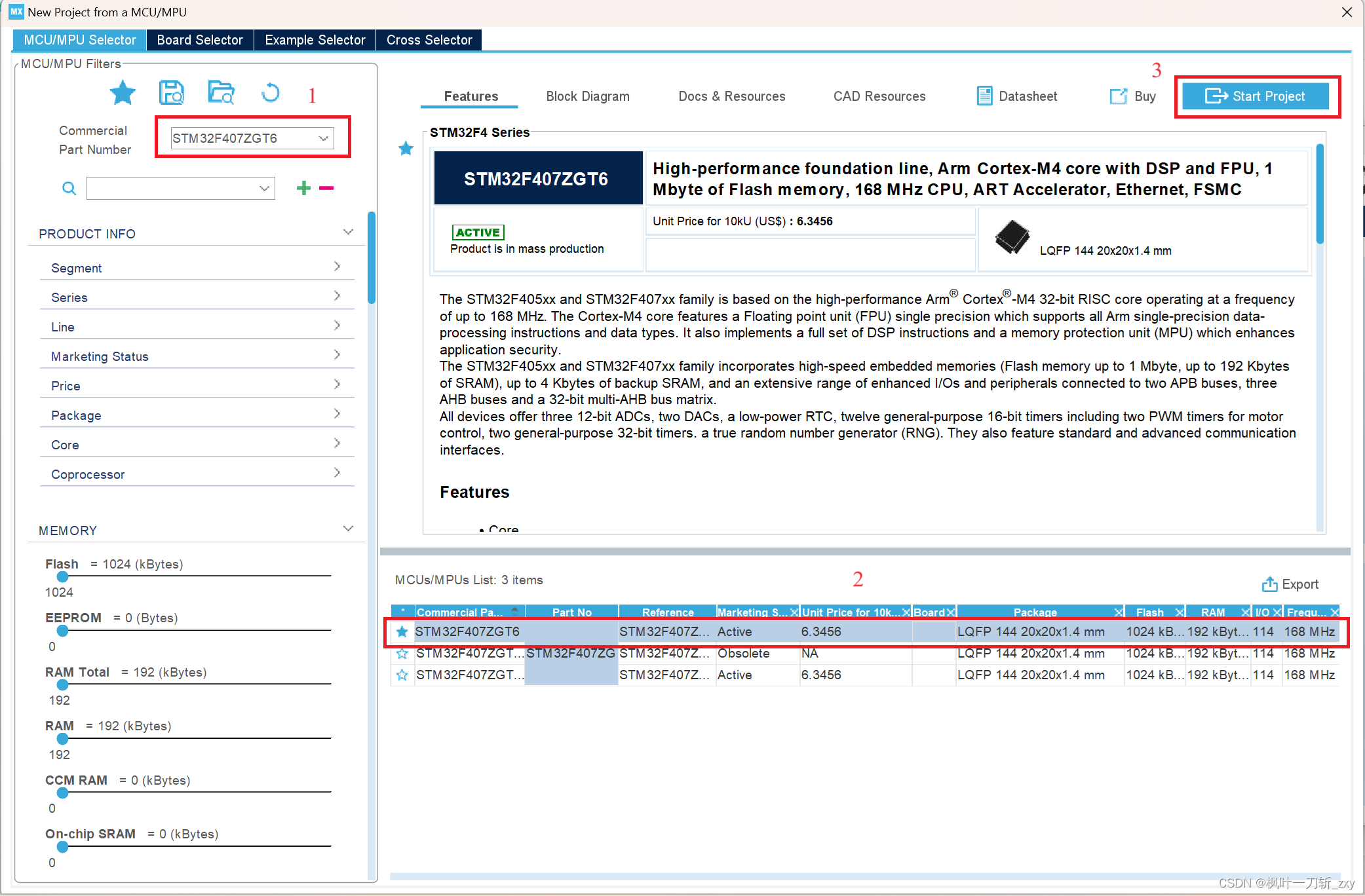
1. 首先是创建一个工程,通过File创建(方式1)或者快捷创建(方式2)均可,然后选择对应的芯片,开始工程即可。
2. 配置RCC和时钟。
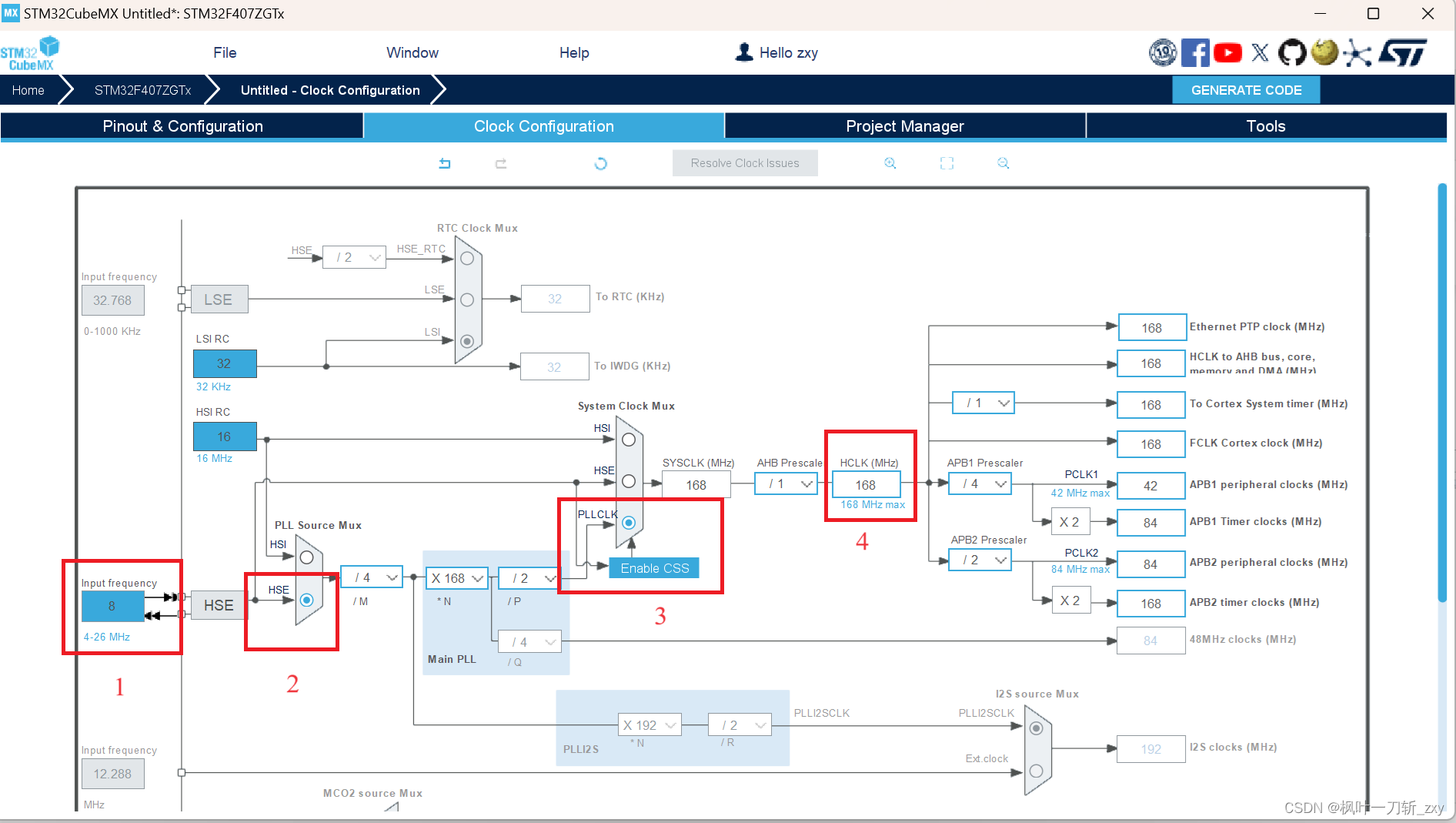
(1) 下图选上HSE,使用外部晶振,然后进入时钟配置界面。

(2)结合自己使用的控制器,我选择不使用内部高速时钟源(HSI),使用外部高速时钟源(HSE),晶振频率8MHz,设置工作主频。这里要注意,一定要根据正确的晶振频率进行配置,不然串口就会出现乱码,除非重写HAL_Init()函数。
tips: 输入完工作主频按回车,CubeMX可自动计算生成。
3. 按照以下步骤,选用X-CUBE-AI组件。其中Application选择Application Template,后续会自动生成用户模板文件:app_x-cube-ai.c和app_x-cube-ai.h。
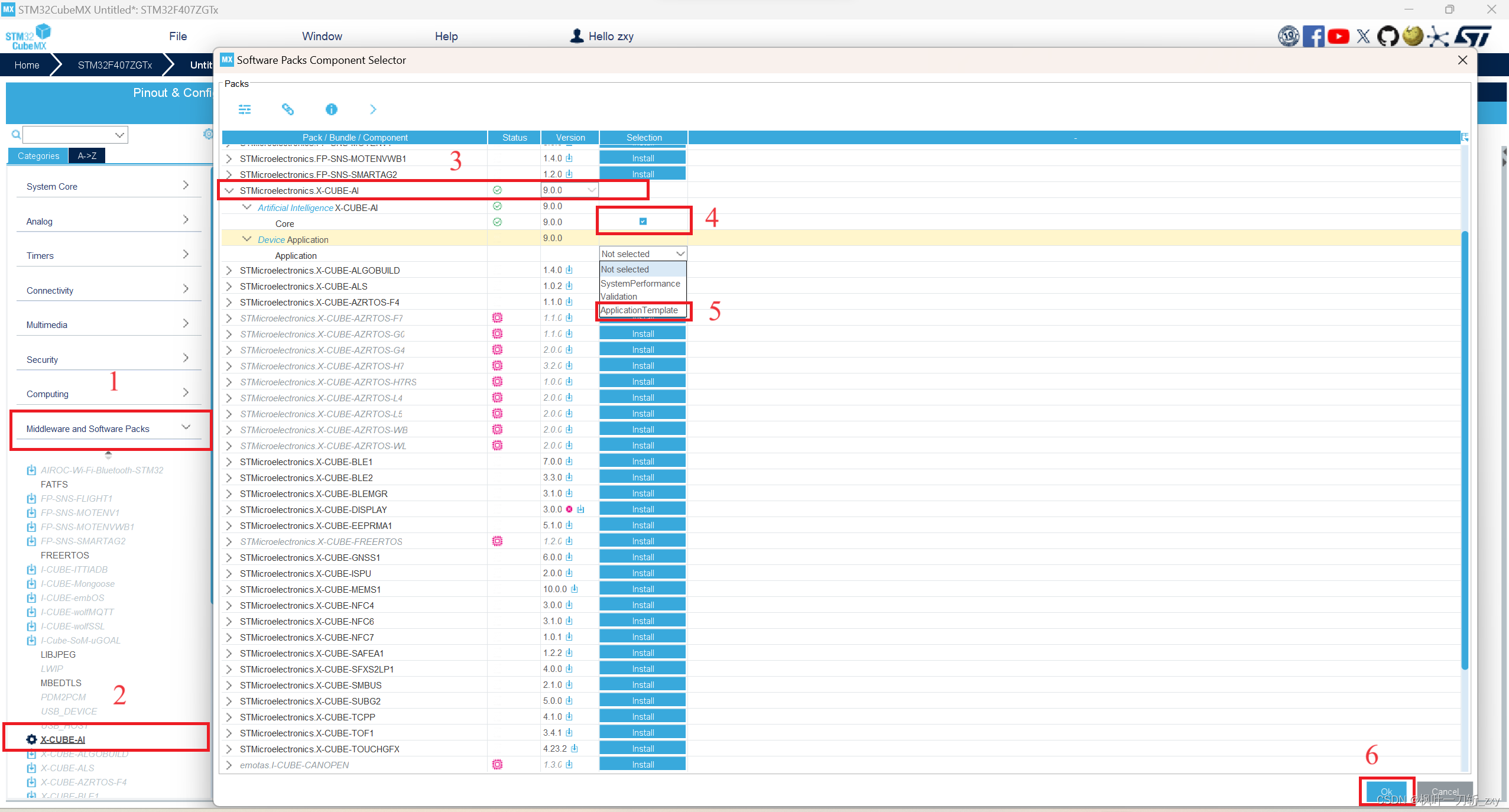
4. 配置X-CUBE-AI组件。
按照下图所示的顺序,依次部署配置模型:
步骤1:选择X-CUBE-AI组件;
步骤2:添加一个网络模型;
步骤3:给网络模型重命名,这里我命名为“network_cifar10”,会影响生成文件的宏定义命名;(该步骤可省略)
步骤4:选择所训练模型的网络框架;
步骤5:加载模型文件,注意不要有中文路径;
步骤6:根据模型大小,选择压缩方式,这里选择中等压缩;(模型文件较小步骤可省略)
步骤7:分析模型文件;(如果不手动分析,在最后生成工程前仍会自动分析)
步骤8:查看网络模型架构,需要在步骤7完成之后方可查看。(该步骤可省略)
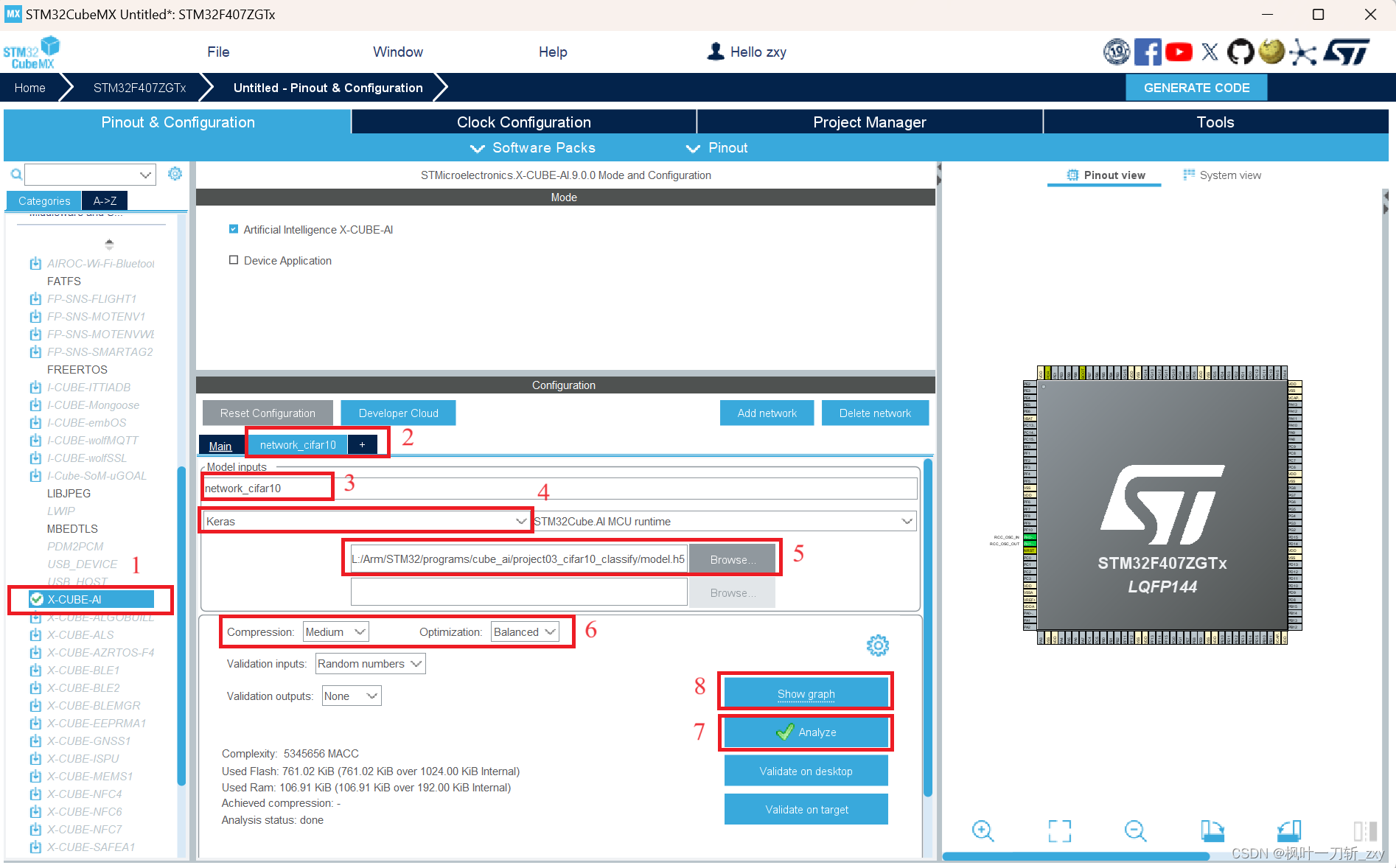
下图是步骤7生成模型的分析结果,包含输入模型架构、数据类型等信息。从上面可看到所占用ROM和RAM情况,尤其是RAM,很容易超128KB。
下图是步骤8生成的网络架构图,也与所输入网络模型架构一致 。

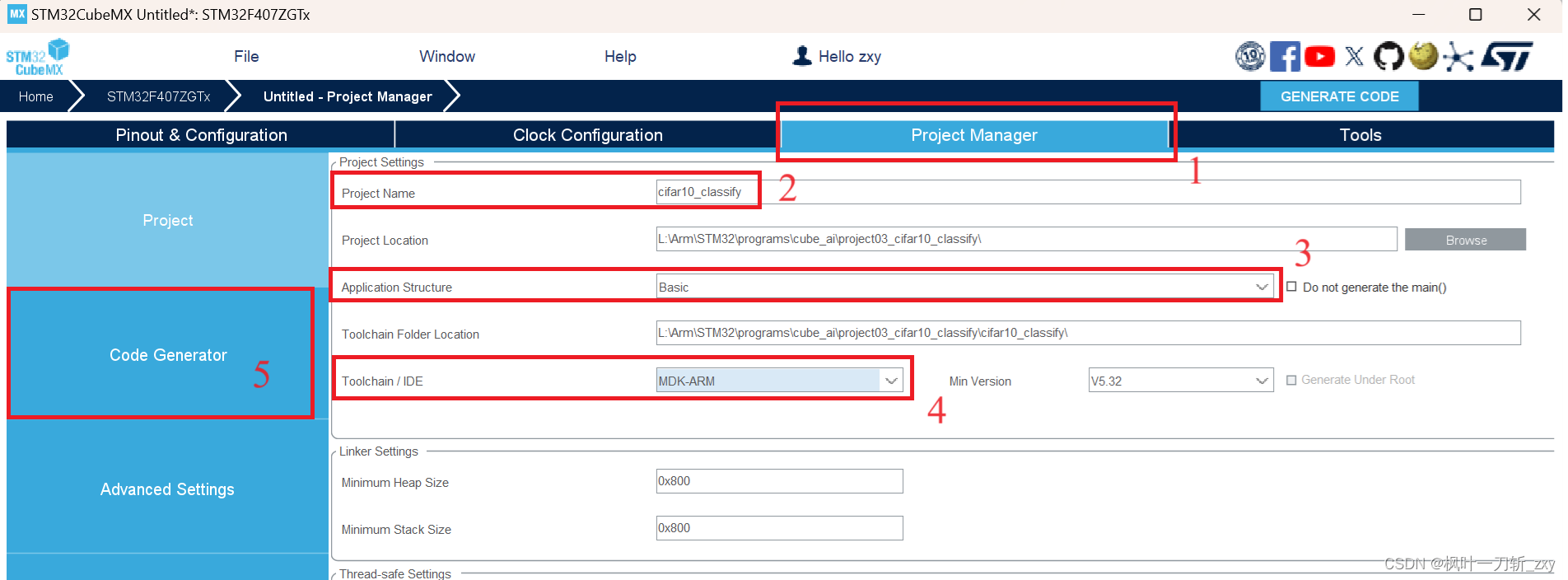
5. 部署模型,创建工程文件。
按照下图的步骤,构建HAL库的项目模板,步骤2为项目名称,步骤3为代码架构,其中步骤4选择MDK_ARM作为IDE工具。
3.2 Keil环境
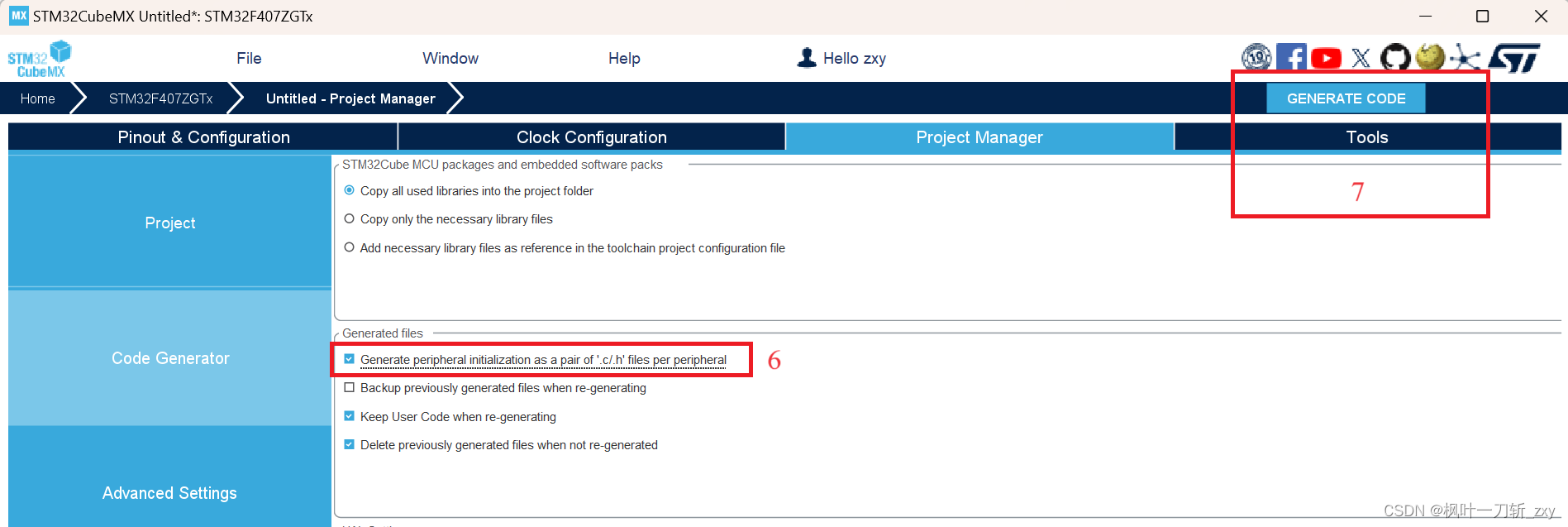
Keil环境配置为了能够使用prinf()函数,这里移植正点原子的HAL系统工程文件,包括delay.c、sys.c和usart.c。由于在CubeMX配置时,没有开启串口功能,所以构建的代码中没有包含串口的HAL库驱动程序,需要从Drivers\STM32F4xx_HAL_Driver\Src下添加stm32f4xx_hal_uart.c文件。
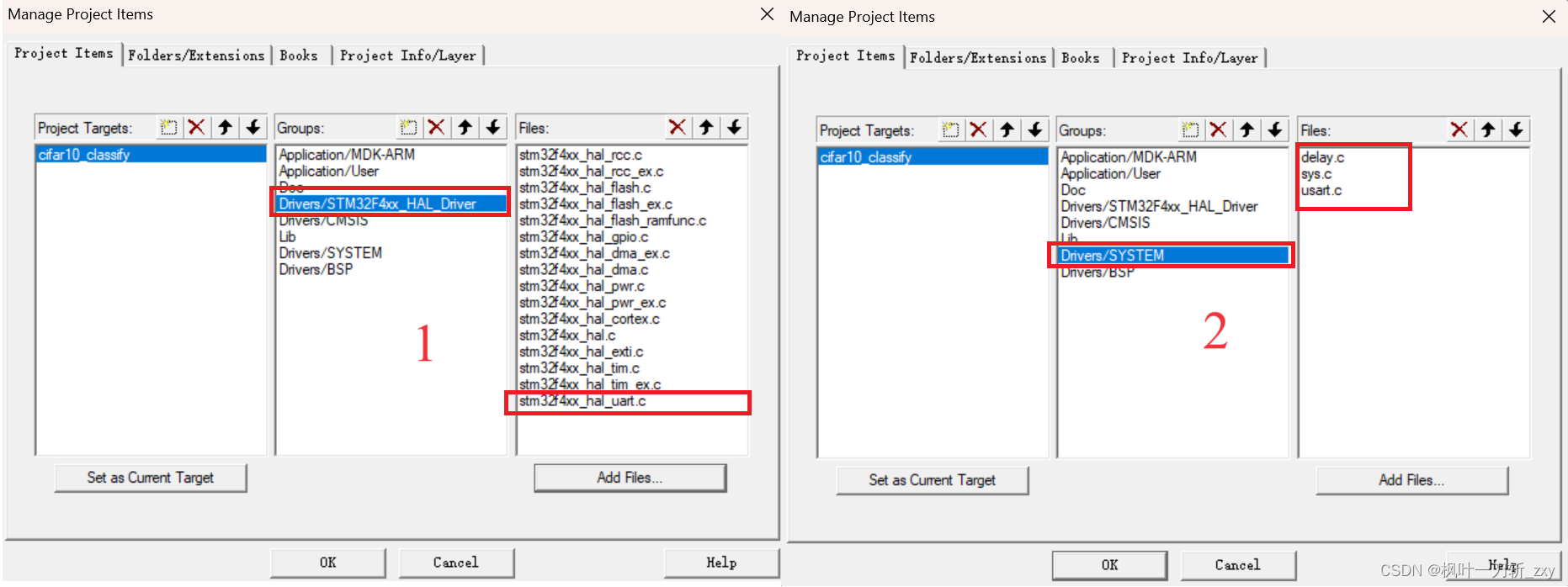
另外,需要添加一个include路径,这样移植之后就不用在代码中修改include路径了,如下图所示:
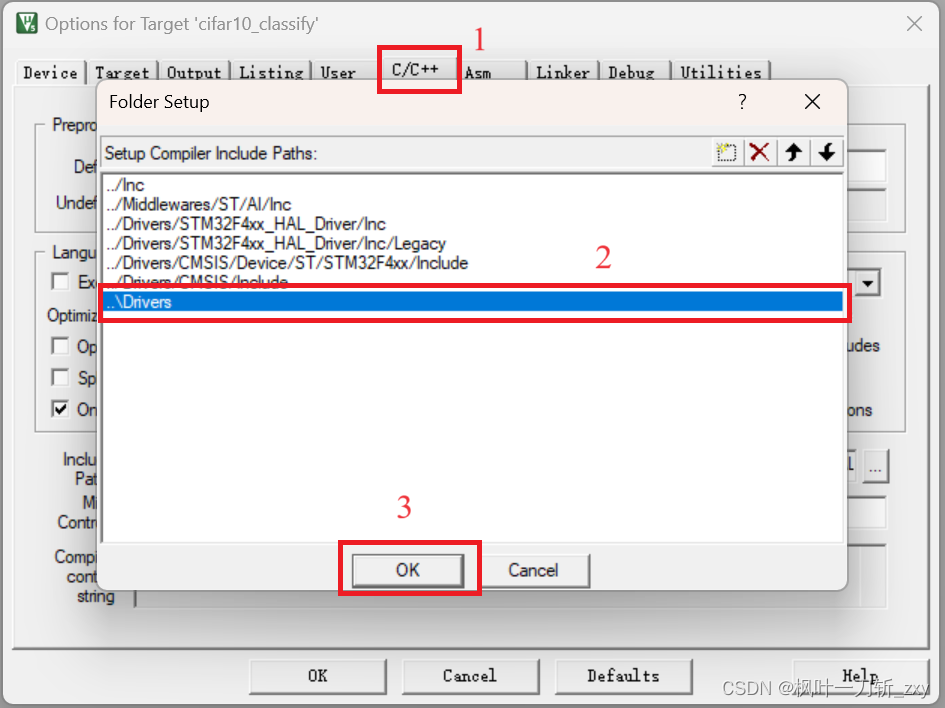
同样地,因为在CubeMX没有配置串口,所以需要在配置文件stm32f4xx_hal_conf.h中,开启串口的宏定义。这里我用到了定时器,用于计算run模型的耗时,所以也顺便开启了。
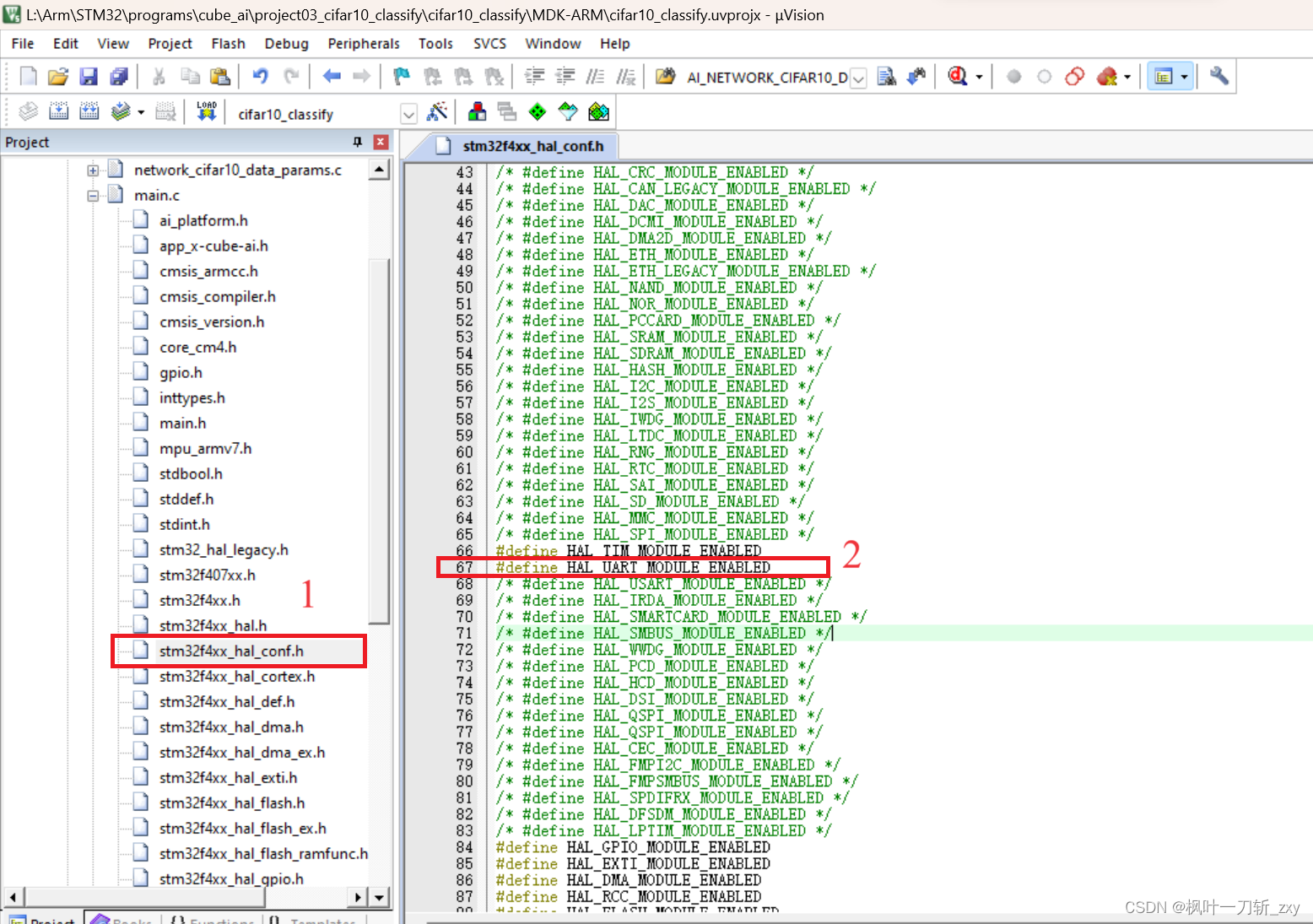 在main.,c主文件中,删除生成的时钟配置函数,更换为下图中的头文件和系统初始化函数。
在main.,c主文件中,删除生成的时钟配置函数,更换为下图中的头文件和系统初始化函数。 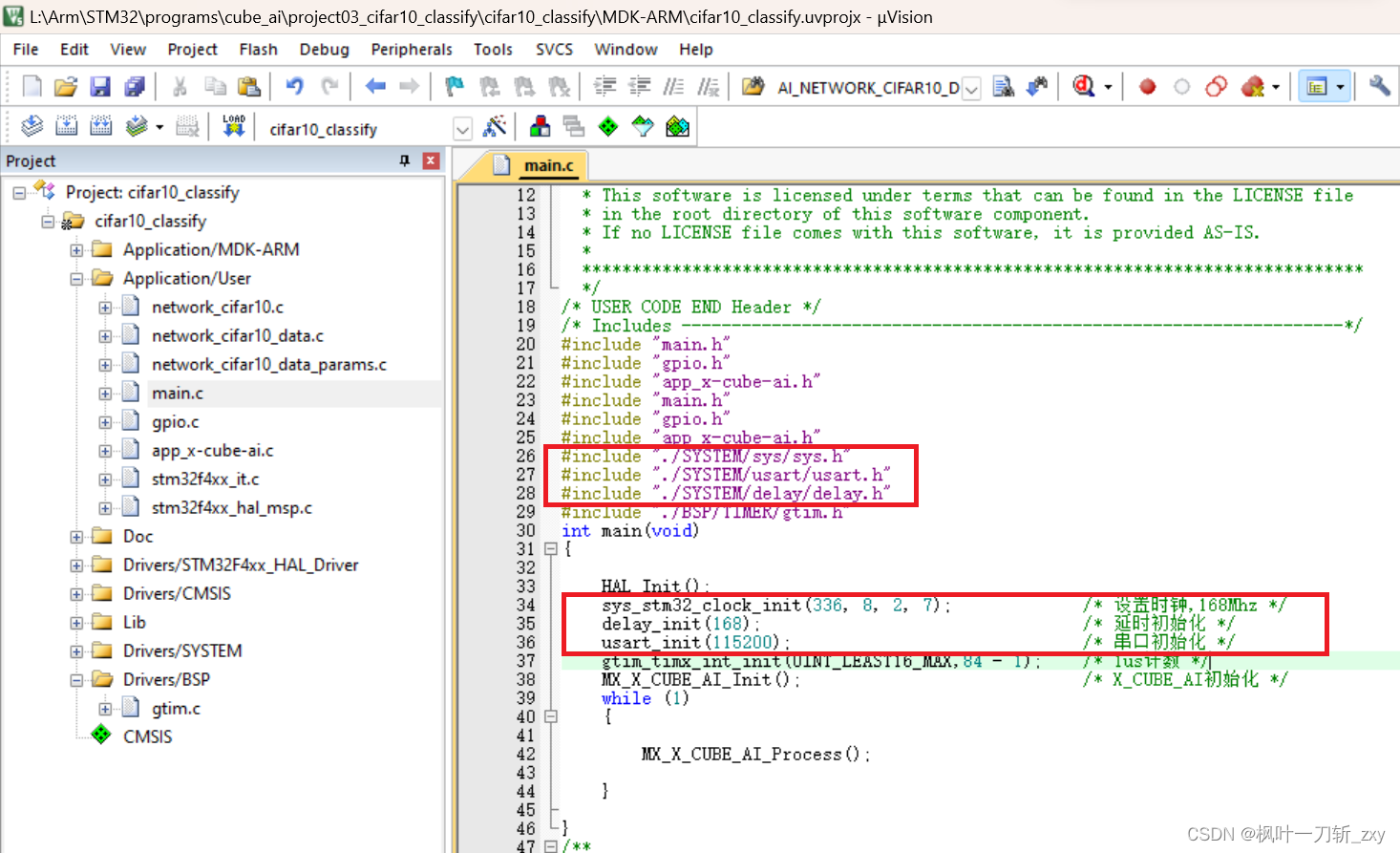
至此,整个工程模板基本完成,然后重新编译整个工程。
4. 模型实现
上文提及到,在配置X-CUBE-AI时选择Application Template,X-CUBE-AI会自动生成用户模板文件:app_x-cube-ai.c和app_x-cube-ai.h,它们是用户工程模板,用户只需要根据需求,修改app_x-cube-ai.c即可,以下修改均在该文件中进行。
1. 首先,添加了两个头文件和声明一些变量。
#include "./SYSTEM/usart/usart.h"
#include "./BSP/TIMER/gtim.h"
float cifar10_in_data[AI_NETWORK_CIFAR10_IN_1_SIZE]; // 图像输入数据(归一化后)
float cifar10_out_data[AI_NETWORK_CIFAR10_OUT_1_SIZE]; // 分类输出数据
const char* labels_en[] = {"airplane","automobile","bird","cat","deer","dog","frog","horse","ship","truck"};
const char* labels_cn[] = {"飞机","汽车","小鸟","猫","鹿","狗","青蛙","马","船","卡车"};
uint8_t uart_rx_byte = 0; // 串口接收数据(1 byte)
uint16_t uart_rx_len = 0; // 统计所接收数据的长度
volatile uint8_t picture_receive_completed = 0; // 图像数据接收完成标识
uint32_t time_count = 0; // 用于计算网络模型运行耗时2. 部署的网络模型首先会进行初始化,执行MX_X_CUBE_AI_Init()函数,在该函数中,打印初始化信息,然后跳转至ai_boostrap()引导程序中执行。在引导程序中,我主要完成了输入和输出数组的初始化。
特别注意:打印初始化信息是X-CUBE-AI自动生成的,所以为了保证X-CUBE-AI的初始化,要么在CubeMX中配置串口自动生成,要么就自编写或者移植串口驱动。(我果断选择移植)
/*
* Function : ai_run
* Description : 初始化引导程序
*/
static int ai_boostrap(ai_handle *act_addr)
{
ai_error err;
err = ai_network_cifar10_create_and_init(&network_cifar10, act_addr, NULL);
if (err.type != AI_ERROR_NONE) {
ai_log_err(err, "ai_network_cifar10_create_and_init");
return -1;
}
ai_input = ai_network_cifar10_inputs_get(network_cifar10, NULL);
ai_output = ai_network_cifar10_outputs_get(network_cifar10, NULL);
ai_input[0].data = cifar10_in_data;
ai_output[0].data = cifar10_out_data;
return 0;
}
/*
* Function : MX_X_CUBE_AI_Init
* Description : X-CUBE-AI 初始化
*/
void MX_X_CUBE_AI_Init(void)
{
printf("\r\nTEMPLATE - initialization\r\n");
ai_boostrap(data_activations0);
}3. 数据接收。以中断方式进行数据接收,并对数据预处理。
/*
* Function : HAL_UART_RxCpltCallback
* Description : 串口数据接收和预处理
*/
void HAL_UART_RxCpltCallback(UART_HandleTypeDef *huart)
{
if(huart->Instance == USART_UX) /* 如果是串口1 */
{
HAL_UART_Receive_IT(&g_uart1_handle, &uart_rx_byte, RXBUFFERSIZE);
cifar10_in_data[ uart_rx_len++ ] = (float)(uart_rx_byte/255.0); // 数据预处理
if(uart_rx_len== AI_NETWORK_CIFAR10_IN_1_SIZE){
uart_rx_len= 0;
picture_receive_completed = 1;
}
}
}4. MX_X_CUBE_AI_Process是模型的主进程,其在main.c的主while循环中不断被执行。这里我为了变量的使用方便,直接在该函数中构建了while子循环:当一次完整的图像数据接收到之后,执行ai_run()程序,顾名思义,它是模型的执行部分。
/*
* Function : MX_X_CUBE_AI_Process
* Description : X-CUBE-AI 主进程
*/
void MX_X_CUBE_AI_Process(void)
{
/* USER CODE BEGIN */
printf("TEMPLATE - run - main loop\r\n");
while(1){
if(picture_receive_completed == 1)
{
ai_run();
picture_receive_completed = 0;
}
}
}5. 在模型的执行过程中,这里主要做了两件事:计算运行耗时和打印输出结果。
/*
* Function : ai_run
* Description : 运行网络模型
*/
static int ai_run(void)
{
ai_i32 batch;
int max_index = 0; // 保存分类输出最大值索引
float max_val = 0; // 保存分类输出最大值
tim_runtime_start(); // 开启定时器计时
batch = ai_network_cifar10_run(network_cifar10, ai_input, ai_output); // run网络模型
time_count = tim_runtime_stop(); // 关闭定时器计时
if (batch != 1) {
ai_log_err(ai_network_cifar10_get_error(network_cifar10),"ai_network_cifar10_run");
return -1;
}
printf("----------------------------------------- \r\n");
for (uint32_t i = 0; i < AI_NETWORK_CIFAR10_OUT_1_SIZE; i++) {
if(max_val < cifar10_out_data[i])
{
max_index = i;
max_val = cifar10_out_data[i];
}
printf("%s(%s) : %.4f \r\n",labels_cn[i], labels_en[i], (float)cifar10_out_data[i]);
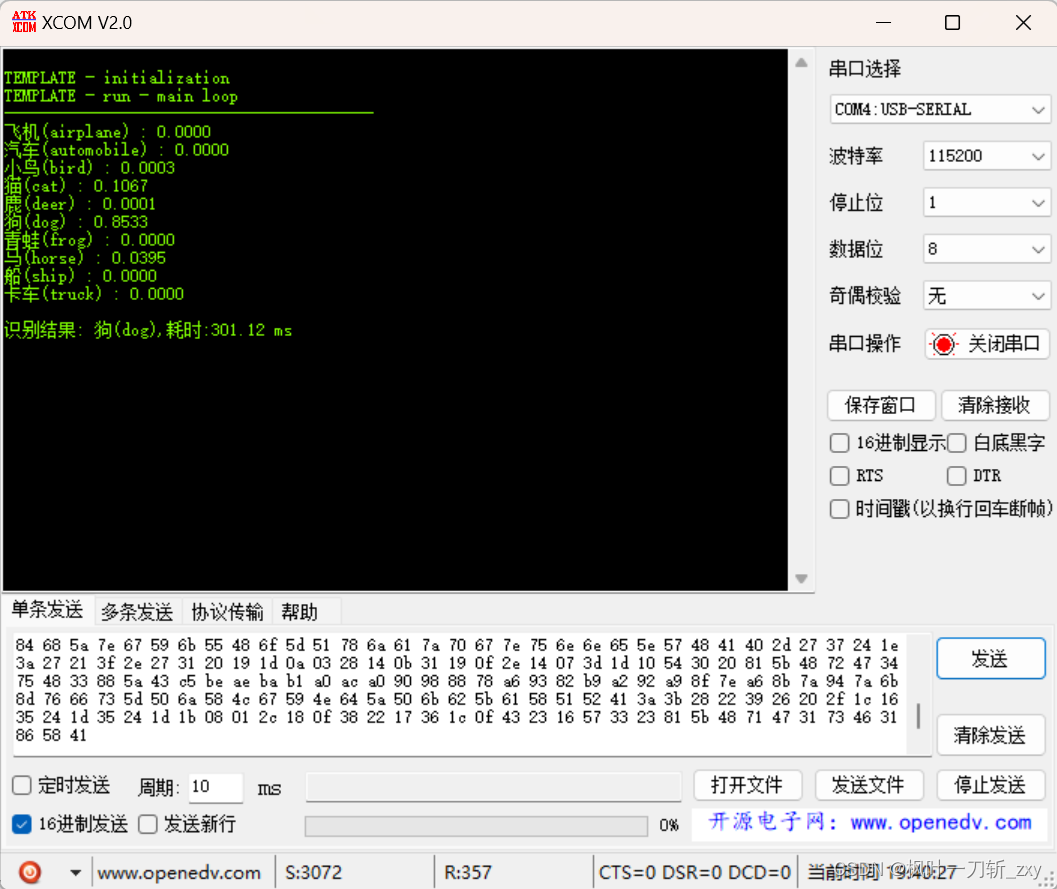
}
printf("\r\n识别结果: %s(%s),耗时:%.2f ms\r\n", labels_cn[max_index], labels_en[max_index], ((double)time_count/1000.0));
return 0;
}5. 实际运行效果
1. 首先选择一张测试集中的图像,出于对狗物种的喜欢,这里我从“狗”类别中随便选择了一张图像进行测试。
补充说明: 为了后续方便测试,我提前通过python程序将各个类别的图像从数据集中提取了出来,并按照顺序依次编号,放在所创建的“train”和“test”文件夹中(每个文件夹下有10个类别),所以训练集每个类别各有5000张图像,测试集每个类别各有1000张图像。(想省时间或有兴趣的可以自行下载)
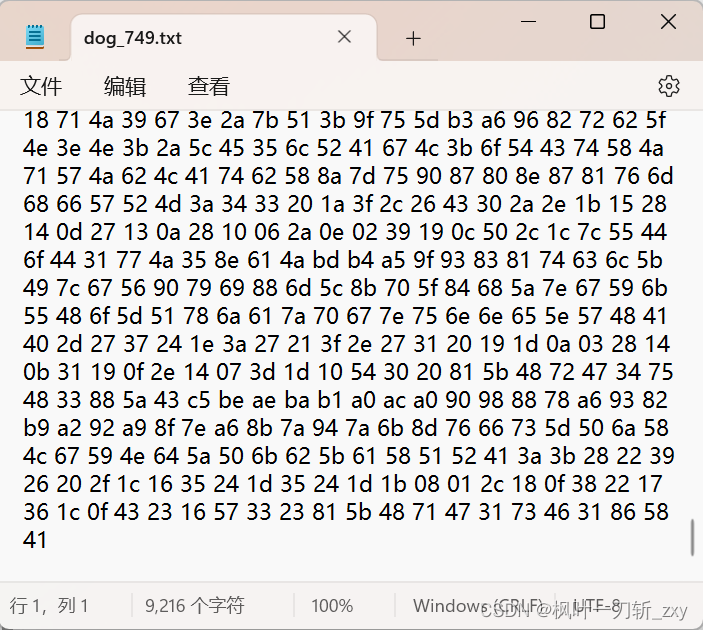
2. 下面是将输入图像转16进制,然后输出至txt文件。(没有选择解析后直接利用串口发送给控制器)
import numpy as np
from PIL import Image
#labels = ["airplane","automobile","bird","cat","deer","dog","frog","horse","ship","truck"]
label = 'dog'
root_path = '.\\test\\' + label
img_id = 749
img = Image.open(root_path + "\\" + str(img_id) + ".jpg")
# 转为numpy数组
img_arr = np.asarray(img)
# 转为(1,3072)格式
img_flatten = img_arr.flatten().reshape(1,-1)
# 保存为16进制数据
np.savetxt(label + '_' + str(img_id)+".txt", X=img_flatten, fmt="%02x")
经过转换后的16进制格式数据:
3. 通过串口助手发送(记得勾选16进制发送),输出各个类别的概率、分类结果和run模型耗时。
6. 案例资料
附:本案例全部资料















 379
379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









