







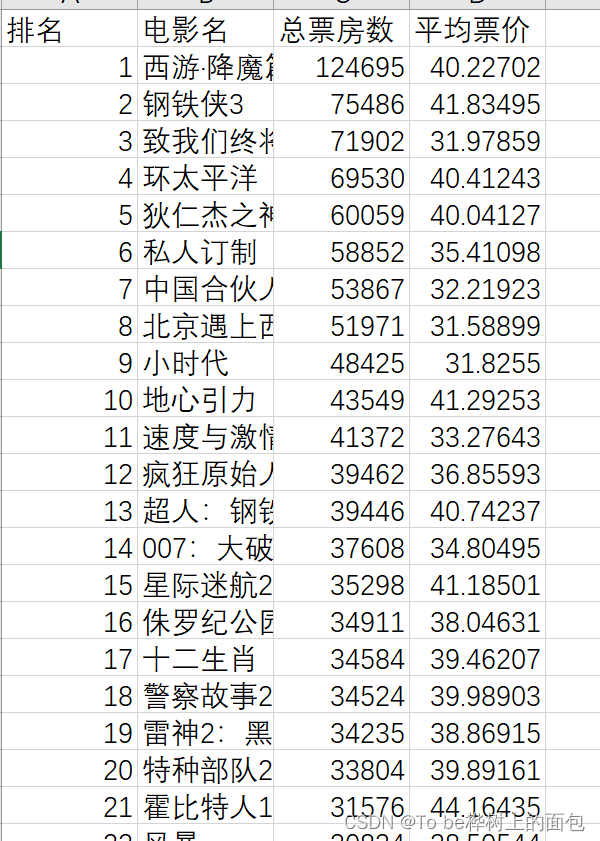
依次进入每年的票房数页面,自动获取票房数前100的电影的排名,电影名,总票房数和平均票价。
根据元素的定位,可以看到其变化的规律,因此,建立循环,将获得的数据导入到csv文件中。
from selenium import webdriver
import numpy as np
import time
import pandas as pd
driver = webdriver.Firefox()
driver.get("https://piaofang.maoyan.com/rankings/year")
time.sleep(1)
for i in range(2,13): #依次进入每一年
web='//*[@id="tab-year"]/ul/li[{}]'.format(i)
driver.find_element_by_xpath(web).click()
time.sleep(1)
lis=[]
txt=[]
for j in range(1,101):
xpath='//*[@id="ranks-list"]/ul[{}]'.format(j)
context=driver.find_element_by_xpath(xpath) #得到相应年的数据
contexts=context.text
lis.append(contexts)
for m in lis:
txt.append(m.split("\n"))
df= pd.DataFrame(txt, columns=['排名', '电影名', '上映时间','总票房数','平均票价','场均人次'])
column=['上映时间','场均人次']
df = df.drop(columns=column, axis=1)
filename='{}年电影票房.csv'.format(2023-i+2)
df.to_csv(filename, sep=',', header=True, index=False,encoding='utf-8-sig')结果展示:

















 833
833

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









