







 本文介绍如何使用selenium爬取猫眼电影实时票房常规版网站,获取并分析暑期综合票房、排片占比等信息,通过数据可视化展示票房情况。
本文介绍如何使用selenium爬取猫眼电影实时票房常规版网站,获取并分析暑期综合票房、排片占比等信息,通过数据可视化展示票房情况。
每至暑期,电影市场都会掀起一波又一波的高潮,众多佳片在这个黄金档期相继上映,面临着激烈的票房争夺战。猫眼电影是美团旗下的一站式电影互联网平台,占据网络购票市场份额的40%以上,本文将基于selenium爬取猫眼实时票房网站,获取暑期综合票房、排片占比、排座占比等信息,并进行可视化分析。
一
网页分析
爬取的目标网页为猫眼电影实时票房常规版(https://piaofang.maoyan.com/box-office?ver=normal),选择该网页而不是专业版(https://piaofang.maoyan.com/dashboard)是因为专业版网页爬取难度较大。查看源码,可以看到在专业版网页中,综合票房显示为一段div包裹的不可见文本。对于常规版网页来说,票房数字在源码中正常显示,因此本文将爬取猫眼电影实时票房常规版网页的内容。
图1 猫眼电影实时票房专业版网页
图2 猫眼电影实时票房常规版网页
观察源码和网页内显示的内容是否一致。在源码中找到名为**的HTML标签,依次展开,发现网页呈现出的内容和源码一致。但在使用requests库请求该地址时发现得到的数据并不完整,这是因为该网页使用了异步加载方式。因此,接下来考虑使用selenium**库。
图3 观察源码
二
提取信息
首先引入库,使用webdriver进入页面。注意:在使用selunium之前要下载对应浏览器版本的webDriver驱动,解压后的存放路径为:浏览器的根目录下**(windows)、/usr/local/bin/(macos、linux)。本文使用的是chrome**浏览器:
from selenium import webdriver``from selenium.webdriver.common.by import By``driver = webdriver.Chrome()``driver.get('http://piaofang.maoyan.com/box-office?ver=normal')
然后观察网页结构,发现影片名称均存放在名称为p、属性class的值为“movie-name”的节点下,因此可以使用xpath元素进行定位,即**//\*[@class=‘movie-name’]**,并且具有唯一性。类似地,对于总票房、实时综合票房、综合票房占比、排片占比、排座占比均可使用xpath元素定位并获取元素。
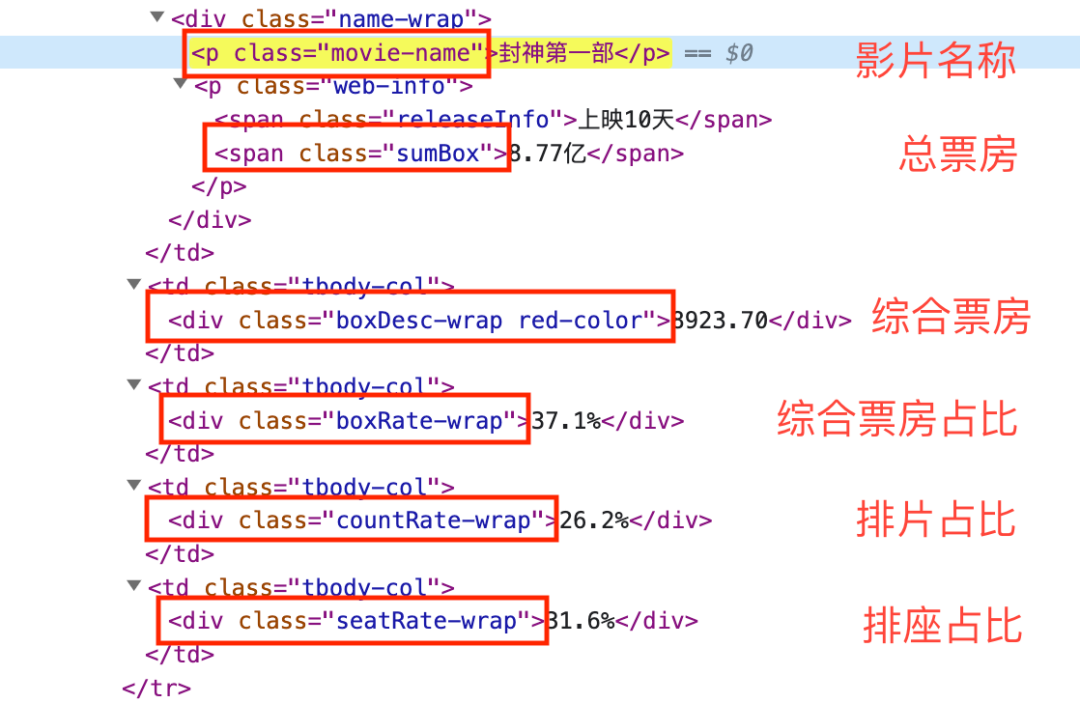
图4 xpath元素定位
我们需要获取的是页面中的多个相同元素,因此使用find_elements,得到的是一个列表:
name = driver.find_elements(By.XPATH, "//*[@class='movie-name']")``sumBox = driver.find_elements(By.XPATH, "//*[@class='sumBox']")``box = driver.find_elements(By.XPATH, "//*[@class='boxDesc-wrap red-color']")``boxRate = driver.find_elements(By.XPATH, "//*[@class='boxRate-wrap']")``showRate = driver.find_elements(By.XPATH, "//*[@class='countRate-wrap']")``seatRate = driver.find_elements(By.XPATH, "//*[@class='seatRate-wrap']")
由于find_elements仅能获取元素,不能获取其中的数据。我们需要的数据是定位得到的标签对象的文本内容,因此使用element.text获取文本。本文封装了名为transfer_to_text的函数,依次从上述获得的所有元素中提取对应的文本内容。代码如下:
# 构造函数``def transfer_to_text(input_list):` `new_list = []` `for i in input_list:` `text_str = i.text` `new_list.append( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









