










在平时用jmeter做测试时,生成报告的模板,不是特别好。大家应该也知道allure报告,页面美观。
先来看效果图,报告首页,如下所示:
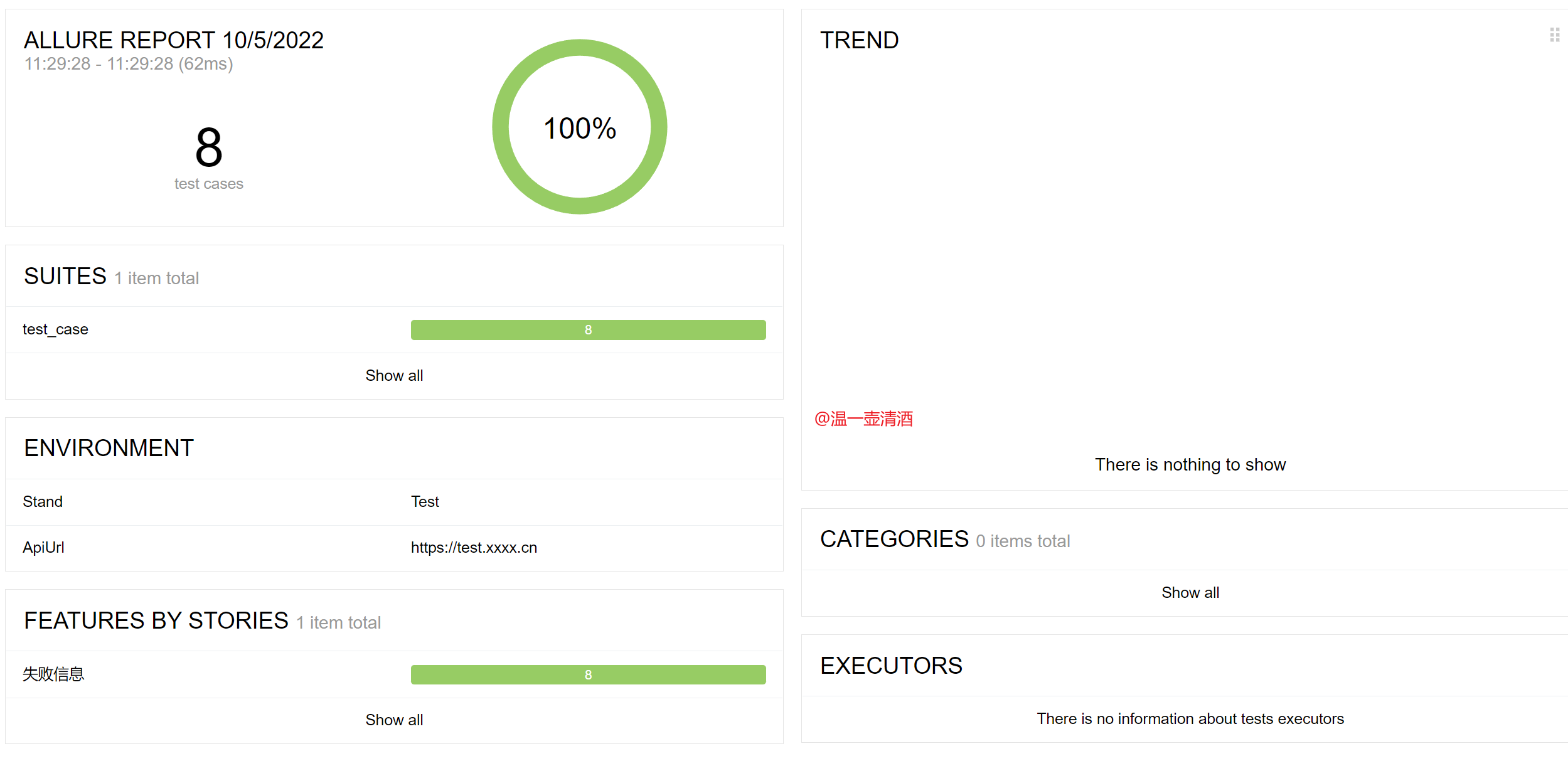
报告详情信息,如下所示:
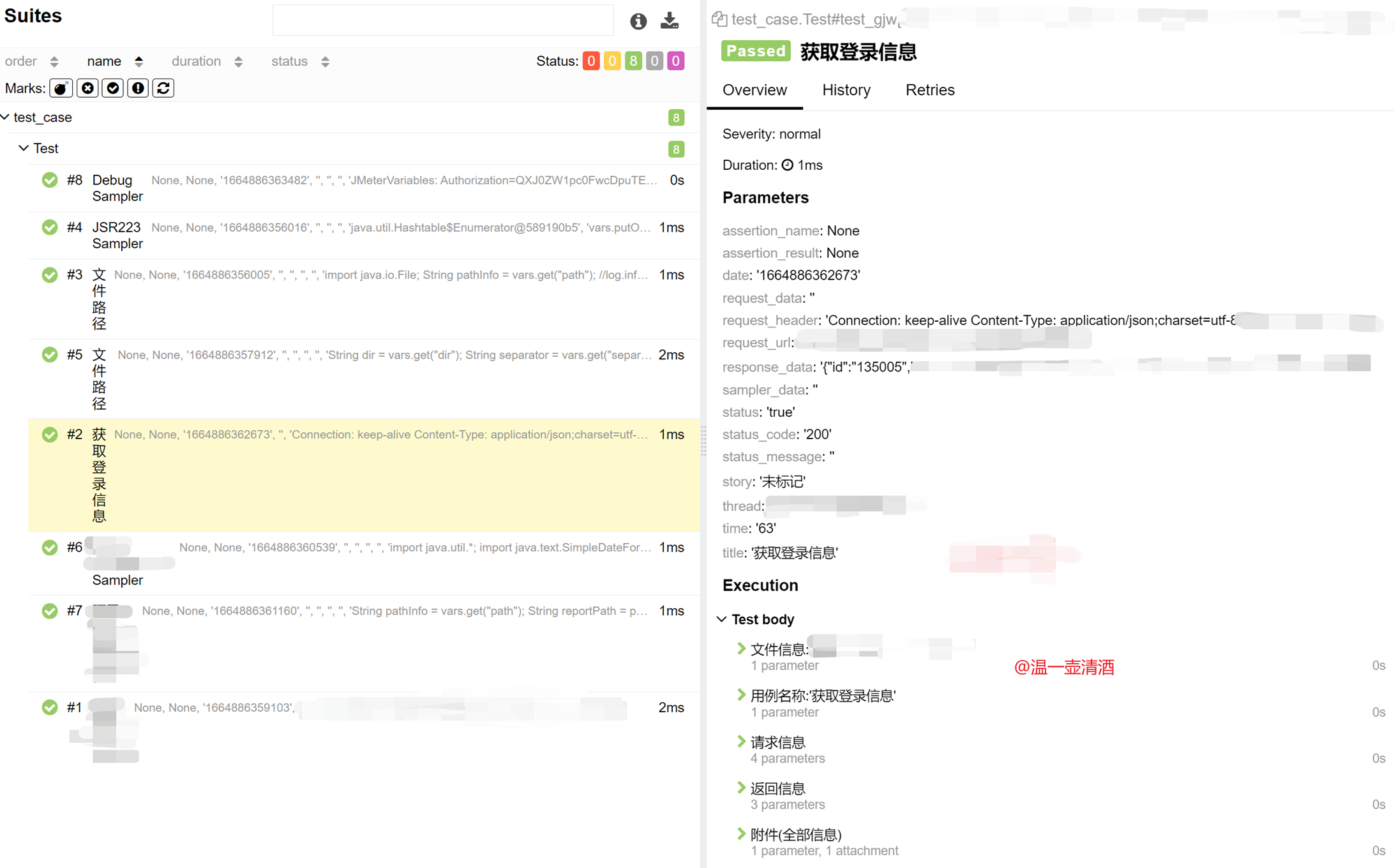
运行run.py文件,运行成功,如下所示:
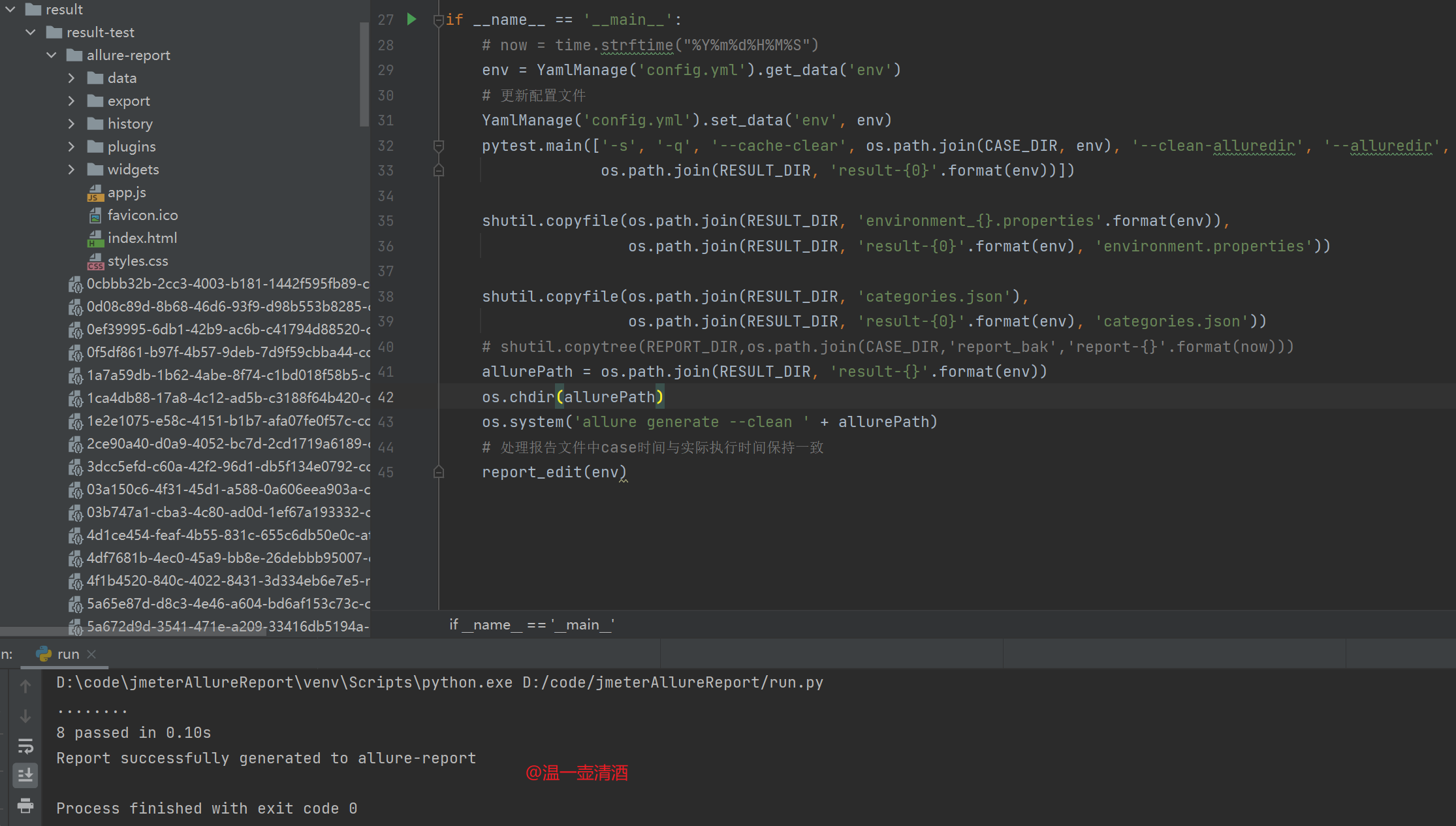
接下来来看下实现过程。
安装allure
allure是开源的,直接到github上下载即可。就不细说了。需要注意的是,环境变量的配置,allure的bin路径,需要配置到环境变量path中。
jmeter配置
找到bin目录下的 jmeter.properties 配置文件,将如下所示对应配置取消注释,jmeter.save.saveservice.output_format 修改为xml。
-
# This section helps determine how result data will be saved. -
# The commented out values are the defaults. -
# legitimate values: xml, csv, db. Only xml and csv are currently supported. -
jmeter.save.saveservice.output_format=xml -
# The below properties are true when field should be saved; false otherwise -
# -
# assertion_results_failure_message only affects CSV output -
#jmeter.save.saveservice.assertion_results_failure_message=true -
# -
# legitimate values: none, first, all -
#jmeter.save.saveservice.assertion_results=none -
# -
jmeter.save.saveservice.data_type=true -
jmeter.save.saveservice.label=true -
jmeter.save.saveservice.response_code=true -
# response_data is not currently supported for CSV output -
jmeter.save.saveservice.response_data=true -
# Save ResponseData for failed samples -
jmeter.save.saveservice.response_data.on_error=true -
jmeter.save.saveservice.response_message=true -
jmeter.save.saveservice.successful=true -
jmeter.save.saveservice.thread_name=true -
jmeter.save.saveservice.time=true -
jmeter.save.saveservice.subresults=true -
jmeter.save.saveservice.assertions=true -
jmeter.save.saveservice.latency=true -
# Only available with HttpClient4 -
jmeter.save.saveservice.connect_time=true -
jmeter.save.saveservice.samplerData=true -
jmeter.save.saveservice.responseHeaders=true -
jmeter.save.saveservice.requestHeaders=true -
jmeter.save.saveservice.encoding=true -
jmeter.save.saveservice.bytes=true -
# Only available with HttpClient4 -
jmeter.save.saveservice.sent_bytes=true -
jmeter.save.saveservice.url=true -
jmeter.save.saveservice.filename=true -
jmeter.save.saveservice.hostname=true -
jmeter.save.saveservice.thread_counts=true -
jmeter.save.saveservice.sample_count=true -
jmeter.save.saveservice.idle_time=true -
# Timestamp format - this only affects CSV output files -
# legitimate values: none, ms, or a format suitable for SimpleDateFormat -
jmeter.save.saveservice.timestamp_format=ms -
jmeter.save.saveservice.timestamp_format=yyyy/MM/dd HH:mm:ss.SSS
生成jmeter结果文件
使用命令 jmeter -n -t C:\Users\Desktop\auth.jmx -l C:\Users\Desktop\result.xml 即可生成xml文件
安装依赖包
按项目中的 requirements.txt 文件,安装对应的依赖包即可。
文件解析生成allure报告
文件解析
xml文件内容如下:

从上述的内容,我们可以分析得出如下内容:
-
t 从请求开始到响应结束的时间 -
ts 表示访问的时刻: date -
s 运行的结果 -
lb 表示标题 -
rc 返回的响应码 -
rm 响应信息 -
tn 线程的名字 -
assertionResult: 断言信息 -
responseData/samplerData: 返回数据 -
queryString: 请求信息
代码实现
利用生成的结果文件生成pytest的参数化数据
-
try: -
converte_data = xmltodict.parse(result_file, encoding='utf-8') -
sample_keys = list(converte_data['testResults'].keys()) -
result = [] -
ws_result = [] -
sample_result = converte_data['testResults']['httpSample'] if isinstance( -
converte_data['testResults']['httpSample'], -
list) else [converte_data['testResults']['httpSample']] -
if 'sample' in sample_keys: -
ws_result = converte_data['testResults']['sample'] if isinstance(converte_data['testResults']['sample'], -
list) else [ -
converte_data['testResults']['sample']] -
result_data = sample_result + ws_result -
for data in result_data: -
time = data['@t'] if '@t' in data else '' -
date = data['@ts'] if '@ts' in data else '' -
status = data['@s'] if '@s' in data else '' -
title = data['@lb'] if '@lb' in data else '' -
status_code = data['@rc'] if '@rc' in data else '' -
status_message = data['@rm'] if '@rm' in data else '' -
thread = data['@tn'] if '@tn' in data else '' -
assertion = data['assertionResult'] if 'assertionResult' in data else '' -
response_data = data['responseData']['#text'] if 'responseData' in data and '#text' in data['responseData'] \ -
else '' -
sampler_data = data['samplerData']['#text'] if 'samplerData' in data and '#text' in data['samplerData'] \ -
else '' -
request_data = data['queryString']['#text'] if 'queryString' in data and '#text' in data[ -
'queryString'] else '' -
request_header = data['requestHeader']['#text'] if 'requestHeader' in data and '#text' in data[ -
'requestHeader'] else '' -
request_url = data['java.net.URL'] if 'java.net.URL' in data else '' -
story = '未标记' -
assertion_name, assertion_result = None, None -
if status == 'false': -
assertion_name, assertion_result = get_assertion(assertion) -
meta_data = ( -
time, date, status, story, title, status_code, status_message, thread, assertion_name, assertion_result, -
response_data -
, sampler_data, request_data, request_header, request_url) -
result.append(meta_data) -
return result -
except Exception as e: -
print(e) -
return [ -
('time', 'date', 'true', 'story', 'title', 'status_code', 'status_message', 'thread', 'assertion_name', -
'assertion_result', -
'response_data', 'sampler_data', 'request_data', 'request_header', 'request_url')]
用例详情字段
-
@allure.step('用例名称:{title}') -
def title_step(self, title): -
pass -
@allure.step('请求信息') -
def request_step(self, request_url, request_header, request_data, sampler_data): -
pass -
@allure.step('断言信息') -
def assert_step(self, assertion_name, assertion_result): -
assert False -
@allure.step('文件信息:{thread}') -
def file_step(self, thread): -
pass -
@allure.step('返回信息') -
def response_step(self, status_code, status_message, response_data): -
pass -
@allure.step('附件(全部信息)') -
def attach_all(self, data): -
allure.attach(str(data), name='attach_all_data', -
attachment_type=allure.attachment_type.JSON) -
def base_step(self, time, date, status, title, status_code, status_message, thread, assertion_name, -
assertion_result, response_data, -
sampler_data, request_data, request_header, -
request_url): -
data = {'title': title, 'thread': thread, 'request_url': request_url, 'request_header': request_header, -
'request_data': request_data, 'sampler_data': sampler_data, 'status_code': status_code, -
'response_data': response_data, 'assertion_name': assertion_name, 'assertion_resul': assertion_result} -
self.file_step(thread) -
self.title_step(title) -
self.request_step(request_url, request_header, request_data, sampler_data) -
self.response_step(status_code, status_message, response_data) -
self.attach_all(data) -
if status == 'false': -
self.assert_step(assertion_name, assertion_result) -
assert False -
else: -
assert True -
@allure.title("{title}") -
@allure.feature("失败信息") -
@pytest.mark.parametrize( -
"time,date,status,story,title,status_code,status_message,thread,assertion_name,assertion_result,response_data,sampler_data,request_data,request_header," -
"request_url", -
xml_2_data(type=1)) -
def test_gjw(self, time, date, status, story, title, status_code, status_message, thread, assertion_name, -
assertion_result, -
response_data, sampler_data, request_data, request_header, -
request_url): -
# allure.dynamic.story(story) -
self.base_step(time, date, status, title, status_code, status_message, thread, assertion_name, assertion_result, -
response_data, -
sampler_data, request_data, request_header, -
request_url)
处理报告转化时间一致
-
def report_edit(env): -
path = os.path.join(Path().get_report_path(), env, 'data') -
# 批量更新聚合文件 -
for file in os.listdir(path): -
if '.json' in file and 'categories' not in file: -
try: -
with open(os.path.join(path, file), 'r') as f: -
json_str = json.loads(f.read()) -
for data in json_str['children'][0]['children']: -
name = data['name'] -
for meta in result: -
if name == meta[3]: -
data['time']['start'] = int(meta[1]) -
data['time']['stop'] = int(meta[1]) + int(meta[0]) -
data['time']['duration'] = int(meta[0]) -
with open(os.path.join(path, file), 'w') as w: -
json.dump(json_str, w, indent=2, sort_keys=True, ensure_ascii=False) -
except Exception as e: -
print(e) -
# 批量更新case文件 -
cases_path = os.path.join(path, 'test-cases') -
for file in os.listdir(cases_path): -
if '.json' in file and 'categories' not in file: -
try: -
with open(os.path.join(cases_path, file), 'r') as f: -
json_str = json.loads(f.read()) -
name = json_str['name'] -
for meta in result: -
if name == meta[3]: -
json_str['time']['start'] = int(meta[1]) -
json_str['time']['stop'] = int(meta[1]) + int(meta[0]) -
json_str['time']['duration'] = int(meta[0]) -
with open(os.path.join(cases_path, file), 'w') as w: -
json.dump(json_str, w, indent=2, sort_keys=True, ensure_ascii=False) -
except Exception as e: -
print(e)
上述只是部分代码,完整代码已上传,JmeterAllureReport ,有兴趣的可以再完善。
总结:
感谢每一个认真阅读我文章的人!!!
作为一位过来人也是希望大家少走一些弯路,如果你不想再体验一次学习时找不到资料,没人解答问题,坚持几天便放弃的感受的话,在这里我给大家分享一些自动化测试的学习资源,希望能给你前进的路上带来帮助。

软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

视频文档获取方式:
这份文档和视频资料,对于想从事【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!以上均可以分享,点下方小卡片即可自行领取。















 2393
2393











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









