






性能测试概念
性能测试是通过自动化的测试工具模拟多种正常、峰值以及异常负载条件来对系统的各项性能指标进行的测试。
性能测试的分类
1、负载测试:系统运行有效的情况下,不同负载下的服务器性能
2、压力测试:增加负载,直到系统运行失效
3、稳定性测试:测试系统长时间运行的稳定性
4、基准测试:测量和评估系统的性能指标的一项活动,通过基准测试可以建立一个基本的性能水平,以供后续进行参考
例子:主要用于日常中的产品的【跑分】
5、容量测试:测试服务器最大的容量,即用户数最大用户数的容量
6、配置测试:各种的软件或硬件的配置测试
7、从测试手段上:
1)单用户测试
2)并发测试:一般用于针对服务器的性能测试
负载和压力测试的区别?
负载测试是系统运行有效的情况下,不同负载下的服务器性能 ;压力测试:增加负载,直到系统运行失效。
性能测试的流程
1、分析性能需求:
1)哪些功能需要进行性能测试:
- 系统主要的、核心的功能
- 用户访问量较大的功能,即表示服务器的负载越大 例如:双十一秒杀、春节抢票、疫情抢菜等
- 涉及数据量大的功能,即海量数据
- 业务复杂的功能, 例如理财的数据跑批结算
- 其他的特殊场景, 例如上海的沪牌拍卖
2)需要关注常见的性能指标:
并发数:
(1) 同一个时间段内向服务器发送请求的用户的数量,分为2种:普通并发(可以由现后顺序)、极限并发(无现后顺序,同一个时间点一起发送请求);
(2) 性能指标是根据性能需求确定。
响应时间:
- 用户进行操作开始,直到收到服务器返回的响应为止,总共时间称为响应时间 例子:一般网页的响应时间 在 2-5-8秒
事务成功率:
- 多个操作组成事务,事务中的操作共同成功或失败
- 所有的事务中成功的事务的比例 例子:登陆事务成功率>95%
- 资源使用情况:系统运行占用CPU、内存、网络宽带等
- 其他:吞吐量、TPS、QPS等
- 吞吐量:单位时间内产生的样本量
- TPS:每秒的事务数
- QPS:每秒的请求数
没有性能需求怎么办?
根据产品的历史数据,我们可以得出他的性能需求,可以得到
没有历史数据?
可以采用探索式的测试,数据量按照从小到大原则,先使用500条数据探索,若都成功,则再加大数据量(比如1000或10000的数据量)再次进行探索
2、制定测试计划
3、设计、编写测试用例:分为2种场景
- 单场景测试用例
- 多场景测试用例
4、搭建测试环境
5、准备测试数据:
性能测试的数据可能远远多于功能测试。
性能测试数据分为2种:
1)并发数据:并发测试中需要使用的数据
2)铺底数据:(对系统进行填充的作用)对预估系统使用一段时间后的数据量,进行填充的数据
造数据的方法:
1)即复制和使用生产环境的数据。优点:使用最方便最真实;缺点:造成用户信息的泄露
2)使用自动化工具运行,生成数据
3)使用专门的造数据的工具 例如:data factory
4)访问数据库造数据
6、编写测试脚本:
(光写用例是不够的),可以使用Jmeter工具
7、执行测试,分析结果,编写测试报告
Jmeter工具
- 是接口测试、性能测试工具;因是开源工具,故是免费的
- 由Apache官网管理的,目前最新版本5.5 ,无需安装,可直接在官网的压缩包使用, 基于java余元,故要求使用电脑上由Java 8+工具,故需优先查看使用电脑上已安装的java 版本。
- 若是安装java 后,需要配置环境变量
1、jmeter
2、jdk :版本:8+
环境变量的设置:
1)JAVA_HOME ,填写jdk路径
2)path:jdk 路径下的/bin目录
jmeter.properties设置
- 添加语言(中文)格式:jmeter.properties——打开方式:Notepad++——notepad++.exe——搜索language——添加语言“language=zh_CN”——保存后重开jmeter.properties即可。

- 添加utf-8格式:jmeter.properties——搜索encoding——sampleresult.default.encoding=utf-8——保存后重开jmeter.properties即可。

主要元件:
1、测试计划:每个脚本文件只有一个测试计划
2、线程组:模拟用户
3、取样器:模拟用户请求
4、前置处理器:在请求前进行处理,即预请求阶段
5、后置处理器:在收到响应后进行处理
6、断言 Assertions:作用是检查结果
7、监听器 Lis…:查看样本的信息和结果
8、配置元件Config Element:包括变量定义、参数化等
9、逻辑控制器Logic Controller:
10、定时器Timer
Jmeter
1、线程组 :
- 使用线程模拟用户,1个线程表示1个虚拟用户
- 线程属性:1)线程数即用户数;2)ramp-up 时间(秒),即并发用户数总增加时间 ;3)循环次数,线程组下所有线程执行请求的循环次数,可以勾选永远;4)调度器,要先将循环次数设置为永远:启动时间(线程组下的所有线程持续执行的时间,时间到后线程停止执行,即开始结束)、启动延迟(线程执行前等待时间)
2、取样器:发送请求,接收响应,生成样本
- http请求:名称、协议、主机、端口、请求方式、路径簿
例如访问百度————
名称:http请求
(web服务器)协议:https
服务器请求或IP:www.baidu.com
http请求:get(F12 抓包看下请求时get)
路径:/(若查询显示由路径,则需要填入真实路径)- 调取取样器,查看运行中的变量的值
3、监听器:
1)查看结果树——显示每个样本的详细信息,包含取样器的结果、请求、响应数据)。
- 取样器的结果——Load time响应时间 ms(毫秒)、Size in bytes 响应大小、Response code 响应状态码
- 请求(请求头部、请求身体的信息)
- 响应数据(响应头部、响应身体的信息)
2)聚合报告——将样本进行聚合统计,按样本名称进行分组。
- 中位数,即50%百分位:所有样本响应时间,升序排列,第50%个样本的响应时间
- 90%百分位:所有样本响应时间,升序排列,第90%个样本的响应时间
- 95%百分位:所有样本响应时间,升序排列,第95%个样本的响应时间
- 99%百分位:所有样本响应时间,升序排列,第99%个样本的响应时间
- 异常%:所有的样本中,响应异常样本的百分比
- 吞吐量:样本数/时间单位,即单位时间内产生的样本量 sec (秒),min(分钟),hour(小时)
4、测试计划,即用户定义的变量
- 全局变量(整个测试计划下都可以使用变量)

- 调用变量的值 ${变量名}
5、配置元件:,即用户定义的变量
1)用户定义的变量:全局变量、调用变量的值 ${变量名}
- 全局变量

- 调用变量的值 ${变量名}
2)http请求默认值:可以设置http请求参数默认值,供其他请求使用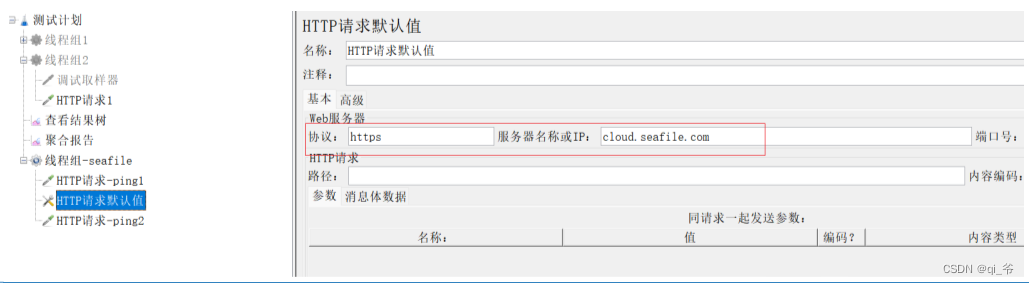
3)http信息头部管理器:可以添加、管理http请求的头部中的信息
4)http cookie管理器:在请求中添加、管理cookie
5)csv数文件设置:实现参数化
添加断言
1、响应断言:检查样本中的响应内容
- 相等:预期和实际要完全一致,则断言通过
- 字符串:响应内容中包含预期值,则断言通过
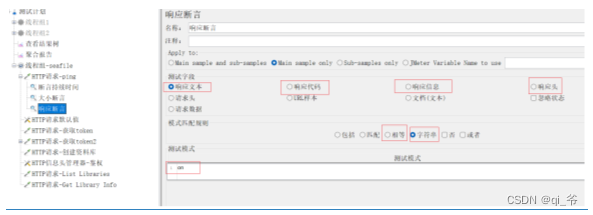
2、响应持续时间 Main sample :
检查样本中的响应时间
- 若是,响应时间<=设置的持续时间,则断言通过
- 若是,响应时间>设置的持续时间,则断言不通过

3、响应大小:
判断样本中的响应,包括整体、头部、身体等
4、JSON 断言:
- json:标识、标志,是javaScript对象的标识,是语法中的一块内容
- {key:value,…}
- " " —— 字符串
- [] 数组(列表)
- json path:用来描述json文档中节点的路径,文本框内是填写json节点的路径
基本语法:http://www.e123456.com/aaaphp/online/jsonpath/
- $ json —— 表示文档根节点
- . 层级 —— 表示a.b ,a下的b节点
- 节点[下标] ——表示数组中的元素,下标从0开始
- 节点1.. 节点2 —— 表示节点1下面的所有节点2,只有节点2 是位于节点1 下,无论在什么位置,不仅仅是该目录下的字节点

5、前置处理器:一般用于变量的设置、测试数据的设置等
- 用户参数:定义变量和值,不同的用户可设置不同的值;
- 前置处理器元件的作用域是局部的

- JSR223 Sampler前置处理器:是一种规范,规定了java虚拟机上执行的脚本语言 JavaScript、groovy ;
- 可以编写脚本,作用于实现功能,其内置对象是 lod 日志(内容) 、vars变量
log.info("今日小雨转中雨"); vars.put("v1","晚上下雨");
6、后置处理器:一般可用于结果的提取等
1)边界提取器:提取左边界、右边界中间的内容:
- 引用名字:设置的变量名称,提取出来的值赋给该变量
- 匹配数字:匹配到多个结果时,即使用哪个,这里的0表示随机

2)json提取器:通过json path提取响应中的json的内容
3)正则表达式提取器,正则表达式基本语法:http://www.regexp.cn/regex
- . ——表示一个任意的字符
- * ——表示重复0到n次
- .* ——表示任意的字符串
- 贪婪匹配模式——表示默认匹配尽量多的内容
- ? 非贪婪匹配——表示匹配尽量少的内容
- ()分组,括号内是提取的内容
- 匹配数字:0表示随机,-1表示全部结果

jsr223 后置处理器
脚本中的可用的内置对象 prev,prev表示样本的结果
- 方法一:getSampleLabel(),返回样本的标签
- 方法二:getResponseCode(),返回响应状态码
- 方法三:getResponseHeaders(),返回响应头
- 方法三:getResponseDataAsString(),返回字符串格式的响应数据

7、逻辑控制器
-
1)IF控制器:
- if控制器 的条件表达式为true,则执行控制器下的元件操作
if 条件:
语句
---------------------------
if 条件:
if 条件
语句
-----------------------------------------------------
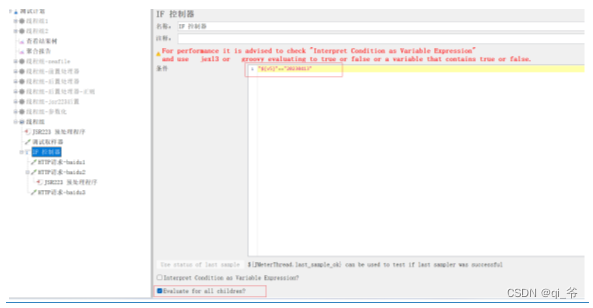
关于js的写法:
if(v5=="20230413"){
}- evaluate for all children:勾选,if控制器下的每个请求执行前都要进行条件判定
if(v5=="20230412"){
1
2
v5="20230415"
3
}
2)吞吐量控制器:
- based on,☞表示百分比
- PercentExecutions,表示可在吞吐量中填写具体的百分比的数值
- TotalExecutions,表示总线程数
- 吞吐量:指目标值
- 吞吐量控制器可以在控制器下的元件执行的线程数,一般作用在多功能场景的测试
- 事务控制器
- 循环控制器
双循环结构-- for: for ---------------------------------------------------------- for 2: if : 1 2 for 1,2,3
- 仅一次控制器
仅在循环的第一次执行下面的元件操作,作用域是针对所在层级的循环
- while控制器
事务控制器
事务 transaction的概念:指一些列操作的集合,事务时是原子性的,在事务中的操作应该是成功或者失败的
generate parent sample —— 勾选情况下,表示聚合报告中仅按事务进行统计
8、定时器:
固定定时器
- 执行的步骤:先等待,再执行请求
- 作用域:定时器在请求下,对该请求都进行等待
- 1)若是放置在某个线程组的下面,则对整个线程组有效
- 2)若是放置在某个请求的下面,则仅对此一个请求有效


同步定时器
作用于:一般用于极限并发
1)模拟用户组的数量:每个的用户数,一起进行极限并发
2)超时时间:最大等待时间,时间超时后则不再等待,线程直接执行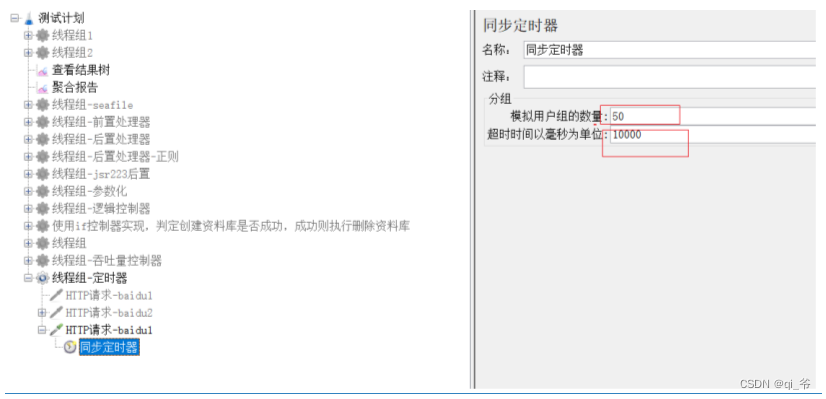
常见的性能测试的用法
一、上下游关联
1、上游的接口通过提取器,获取响应中的内容
作用:后置处理器--提取器:边界提取器,json提取器,正则表达式提取器,jsr223提取器等
例子:seafile的获取token 的接口,可以使用提取器来提取响应中的token值
2、下游接口,在请求中,使用从上游接口提取的内容
通过调用变量的值,来使用上游接口的内容 ${变量名}
例子:创建seafile的接口,在请求的头部中使用token值
二、参数化的用法
数据驱动的测试、关键词驱动、事件驱动
1、数据驱动的测试
测试用例的步骤不变,但测试的数据结果发生改变,即为数据驱动的测试
例子1:
在seafile中,测试创建不同的名称的资料库,可以包括中文、数字、英文、特殊符号、空格、空等资料库
例子2:将资料库的名称进行参数化,即把资料库名称的值设置为变量
例子3:使用jmeter元件创建变量并赋值
1)配置元件----用户定义的变量
2)前置处理器----用户参数
3)配置元件----csv数据文件设置
4)使用函数助手,调用函数:例如使用random随机函数生成随机的值

jmeter工具中如何直接访问数据库?
答:可以用于测试项目数据库服务器的性能;使用mysql,先创建链接,再发送请求
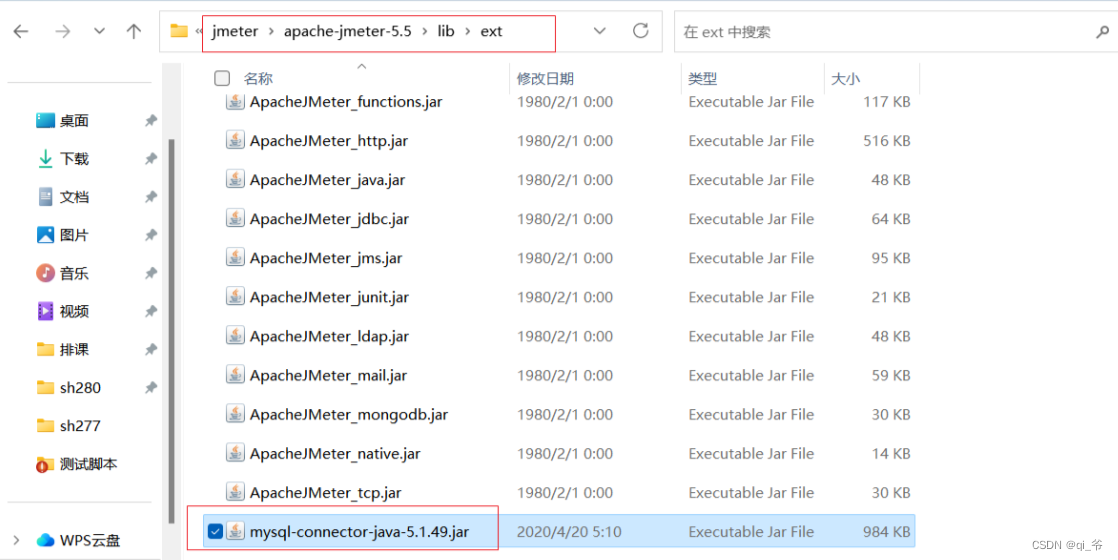
使用MySQL,下载驱动文件放置的路径,创建jdbc连接,再通过取样器向数据库发送请求(取样器---jdbc request),可以用于测试项目数据库服务器的性能
1)使用java数据库的链接,可以网上先找到驱动mysql driver下载,将驱动放置到jmeter的目录下后,启动jmeter,
2)在线程组中添加配置元件----JDBC,JDBCDriverclass com中找到mysqljdbeDriver,在Variablelameforcreatedpool 必须填写名称,在 DatabaseURL 中填写自己历史已创建的数据库的名称(jdbc:mysql://localhost:3306/studysql277),同时填入username、password
3)在线程组中添加取样器----JDBC请求,填入步骤2的(必须填写名称),在文本编写
select * from student表;运行查看响应结果即可。
操作的4个步骤如图所示:
- 步骤1,驱动文件放置的路径
- 步骤2,创建jdbc连接----配置元件--jdbc configration connection

- 步骤3,通过取样器向数据库发送请求----取样器---jdbc request

- 步骤4,可以用于测试项目数据库服务器的性能
一、非图形界面模式执行性能
在jmeter的bin目录中输入CMD打开,再输入jmeter -n即可显示信息
jmeter图形界面可以用于测试脚本的编写和调试
创建是使用图形模式,执行不使用图形模式:因图形模式下本身有占用资源,会对测试产生影响,命令行(CLI模式)可以用于测试的执行:命令行模式本身资源占用少,可以通过其他工具调用命令进行执行
命令:
jmeter -n -t [测试脚本] -l [测试结果日志文件] -e -o [html文档测试报告]

- -l ——测试结果文件
- .csv—— 是建立.csv的表格
- .jtl —— jmeter--查看结果树
练习:
1、创建和调试脚本:seafile,获取token,创建资料库,查看资料库列表;
测试100并发下(每秒增加5线程),创建资料库事务,查看资料库事务,响应时间:(预期:响应时间90% <3秒、事务成功率>=95%)
2、执行脚本:CLI模式执行脚本,生成测试结果文件,以及测试报告

执行前的禁用:
二、分布式测试
1、为了解决单台测试电脑能产生的线程数有限,可以通过多台电脑进行分布式的性能测试;
- 由1台主控机控制n台客户机,主控机上添加测试脚本,客户机产生线程
2、要先进行jmeter配置
1)主控机
- bin目录下的jmeter.properties,设置以下代码内容后,保存关闭
- server.rmi.ssl.disable=true
- mode=Standard
- remote_hosts=192.168.119.130:2099,192.168.119.131:3099
- 使用运行下的远程启动,执行测试脚本
- 由客户机产生线程发送请求
2)客户机
- bin目录下的jmeter.properties
-
server.rmi.ssl.disable=true
- server_port=2099
- 打开jmeter-5.5\bin\jmeter-server.bat
-
启动服务















 2032
2032











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









