









Windows工具 & linux for windows 工具
wireshark 抓包工具
Fiddler http 抓包工具
Postman api调试工具
Winscp ssh scp ftp 文件传输工具
Everything 文件搜索管理工具
MobaXterm ssh ftp telnt console终端工具
OBS 录屏直播推流
spacedesk 分屏工具
APK下载器 goole ply apk download
WO Mic WO 远程麦克风
Ditto 剪切板历史 记录工具github
Ditto 剪切板历史 记录工具app
Cursor 自动生成代码工具 OpenAI
AI 0x0
owncloud-server
owncloud-app
nextcloud
kodcloud
git
sqlite
vim 文本编辑器
neovim 文本编辑器
rsync Windows下使用的同步工具
aria2 for windows windwos 下载工具
GetGnuWin32 – 维护Gnuwin32包存档
linux for windows 命令行GetGNUwin32
UnxUpdates.zip 通用GNU实用程序到本机 Win32 的端口 - 可执行文件仅依赖于 Microsoft C 运行时 (msvcrt.dll),而不是像Cygwin 工具提供的模拟层.
windwos 中文ls 乱码
ls --show -control -chars --color=auto
bc 一個命令行計算器
ag 在源代码或数据文件里检索(grep -r 同样可以做到,但相比之下 ag 更加先进).
bat 代替 cat 格式化文本
xmlstarlet 当你要处理棘手的 XML 时候,xmlstarlet 算是上古时代流传下来的神器.
jq 处理 JSON.
shyaml 处理 YAML.
Glow 基于终端的 Markdown 渲染器
ascii-image-converter 基于终端的 图像转换 ascii 图像转换为 ascii 艺术并在控制台上打印
nano-for-windows 基于终端的 文本编辑器
pandoc Markdown,HTML,以及所有文档格式之间的转换
handle 查询占用进程 句柄查询
process-explorer 基于 GUI 的版本
您是否想知道哪个程序打开了特定的文件或目录?
1. handle [文件名] (通常不加文件的扩展名) 查找哪些程序占用该文件 比如 handle e:\ , 查找所有占用e盘文件的进程
2. handle -a 打印出所有进程详细信息
3. handle -p [进程名] 打印指定进程占用文件信息
sqlitebiter转换为 SQLite 数据库文件
用于将 CSV / Excel / HTML / JSON / Jupyter Notebook / LDJSON / LTSV / Markdown / SQLite / SSV / TSV / Google-Sheets 转换为 SQLite 数据库文件.
poppler-0.68.0_x86_pdftotext_pdftohtml
PDFToText – 从 PDF 文档中提取所有文本.我建议您使用 -Layout 选项以正确的顺序获取内容.
PDFToHTML – 我使用 -xml 选项来获取一个 XML 文件,列出所有文本段的文本、位置和大小,在 C# 中处理非常方便
PDFToCairo – 用于导出图像类型,包括 SVG!
xlsxgrep 用于搜索 excel 数据
Installation
`pip install xlsxgrep`
Example:
`xlsxgrep "PATTERN" -H -N --sep=";" -r /path/to/file_or_folder`
`xlsxgrep %1 -H -N --sep=; -r %2`
NirLauncher 软件包中包含实用程序列表 NirLauncher 软件包下載頁面
fulleventlogview-x64
guipropview
outlookaddressbookview-x64
outlookattachview-x64
outlookstatview-x64
PingInfoView
taskschedulerview-x64
turnedontimesview
whatishang-x64
winlogonview
MSYS2 Windows的软件分发和构建平台
MSYS2是一组工具和库,为您提供易于使用的环境,用于构建、安装和运行本机 Windows 软件.
它由一个名为 mintty的命令行终端、bash、git 和 subversion 等版本控制系统、tar 和 awk 等工具,甚至 autotools 等构建系统组成,所有这些都基于Cygwin的修改版本.尽管其中一些核心部分基于 Cygwin,但 MSYS2 的主要重点是为本地 Windows 软件提供构建环境,并且使用 Cygwin 的部分保持在最低限度.MSYS2 为 GCC、mingw-w64、CPython、CMake、Meson、OpenSSL、FFmpeg、Rust、Ruby 等提供最新的原生构建.
为了提供简单的软件包安装和保持更新的方法,它提供了一个名为 Pacman的软件包管理系统,Arch Linux 用户应该熟悉该系统.它带来了许多强大的功能,例如依赖关系解析和简单的完整系统升级,以及直接和可重复的包构建.我们的包存储库包含2500 多个可以安装的预构建包.
有关详细信息,请参阅“什么是 MSYS2?” 它还将 MSYS2 与其他软件发行版和开发环境进行了比较,例如 Cygwin、 WSL、 Chocolatey、Scoop ......以及“谁在使用 MSYS2?” 查看哪些项目正在使用 MSYS2 以及用途.
第一次运行`pacman -Syu`
使用`pacman -Su`更新其余的基本包
安装一些工具和 mingw-w64 GCC 来开始编译:` pacman -S --needed base-devel mingw-w64-x86_64-toolchain`
要使用 mingw-w64 GCC 开始构建,请关闭此窗口并从“开始”菜单运行“MSYS MinGW 64-bit”.现在您可以调用make或gcc构建适用于 Windows 的软件.
Ripgrep, 简称rg
文本搜索神器rg的介绍和使用
grep更好的替代工具, 最出名的应该是 Ack,Ag , 而现在一个新的替代者 Ripgrep, 简称rg, 比它们更快, 更省电.
- 介绍
RipGrep 与 The Silver Searcher(ag)、Ack 和 GNU Grep 的功能类似.
RipGrep 是一个以行为单位的搜索工具, 它根据提供的 pattern 递归地在指定的目录里搜索.它是由 Rust 语言写成,相较与同类工具,它的特点就是无与伦比地快.
自动递归搜索 (grep 需要-R)
自动忽略.gitignore 中的文件以及二进制文件
可以搜索指定文件类型(rg -t py foo限定 python 文件, rg -T js foo排除 js 文件)
支持大部分 grep 的 feature(常用的都有)
支持各种文件编码(UTF-8, UTF-16, latin-1, GBK, EUC-JP, Shift_JIS 等等)
支持搜索常见压缩文件(gzip, xz, lzma, bzip2, lz4)
自动高亮匹配的结果
1.1 扩展阅读
强中更有强中手, 现在还有rga: ripgrep, 并且还能搜索 PDFs, E-Books, Office documents, zip, tar.gz, 等等.
参考: https://github.com/phiresky/ripgrep-all
2. 使用
2.1 安装
brew install ripgrep
alias grep="rg" # 强制转向 rg
2.2 基础搜索
-
-w有word之意,表示搜索的字符串作为一个独立的单词时才会被匹配到. -
使用
-i选项,即可在搜索时不区分大小写 -
-l只打印有匹配的文件名 -
-C输出匹配上下几行的内容
2.3 高级搜索
- 使用
-e REGEX来指定正则表达式
rg -e "*sql" -C2
- 默认 rg 会忽略
.gitignore和隐藏文件,可以使用-uu来查询所有内容
rg -uu "word" .
- 可以使用
-t type来指定文件类型:
rg -t markdown "mysql" . # 在 md 文件中查找 “mysql” 关键字
支持的文件类型可以通过 rg --type-list 查看
2.4 搜索文件
列出当前文件夹会进行查询的所有文件, 该选项其实可相当于:find . -type f,查找当前目录所有文件
rg --files .
alias rgf='rg --files | rg' # 可来个别名
搜索以 md 为后缀的文件
rg --files . | rg -e ".md$" # 正则匹配
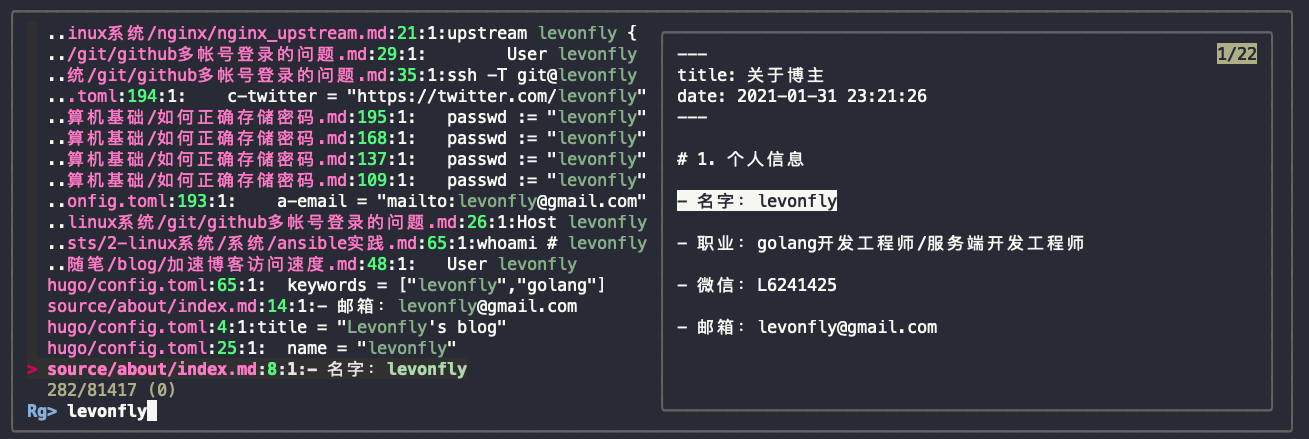
- vim里使用
3.1 配合 fzf
Plug 'junegunn/fzf', { 'do': { -> fzf#install() } } "极限搜索文件
Plug 'junegunn/fzf.vim'
nnoremap <leader>fo :Files<CR>"映射
nnoremap <leader>fif :Rg<CR> "映射
:Rg
- 参考资料
- https://github.com/BurntSushi/ripgrep
- https://einverne.github.io/post/2019/09/ripgrep-recursively-searches-directories-using-regex-pattern.html
- https://juejin.cn/post/6844903680446038029
- https://github.com/phiresky/ripgrep-all
詳細參數説明
| options | Description | other |
| -A, --after-context | 显示匹配内容后的行 | 会覆盖–context |
| -B, --before-context | 显示匹配内容前的行 | 会覆盖–context |
| -b, --byte-offset | 显示匹配内容在文件中的字节偏移 | 和-o 一起使用,只打印偏移 |
| -s, --case-sensitive | 大小写敏感 | 会覆盖-i(ignore case), -S(smart case) |
| –color | 什么时候使用颜色,默认 auto | 如果–vimgre 被使用,那么默认值是 never |
| 可选项有: never, auto, always, ansi | ||
| –colors <COLOR_SPEC>… | 设定输出颜色: | color: red, blue, green, cyan |
{type}:{attribute}:{value} | magenta, yellow, white, black | |
{type}: path, line, column, match | style: nobold, bold, nointense | |
{attribute}: fg, bg, style | intense, nounderline, underline | |
{value}: a color or a text style | Example: | |
{type}:none会清空{type}的颜色设定 | rg --colors ‘match:fg:magenta’ --colors ‘line:bg:yellow’ foo | |
扩展颜色集可以被{value}使用,如果终端支持 ANSI color | ||
| 描述方法是’x’(256-color) 或 ‘x,x,x’(24-bit true color) | ||
| x 是 0-255 之间的数值,默认是 10 进制, 0x 前缀是 16 进制 | ||
| 比如: rg --colors ‘match:bg:0,128,255’ | ||
| 或者等价的:rg --colors ‘match:bg:0x0,0x80,0xFF’ | ||
| 在使用 extended color code 时 intense 和 nointense 是无效的 | ||
| –column | 第一次匹配所在列数(从 1 开始) | 能够被–no-column 取消掉 |
| -C, --context | 显示匹配内容的前面和后面的行 | 它会覆盖-B 和-A 选项 |
| –context-separator | 在输出中用来分隔非连续的行 | x7F 或t 可被使用,默认是– |
| -c, --count | 只显示匹配的行数 | 如果只有一个文件给 ripgrep,那只打印匹配行数 |
| 可以用–with-filename 来强制打印文件名 | ||
| 它会覆盖–count-matches 选项 | ||
| –count-matches | 只显示匹配的次数 | 可以用–with-file 来强制在只有一个文件时也输出文件名 |
| –debug | 显示调试信息 | |
| –dfa-size-limit <NUM+SUFFIX?> | regex DFA 的上限, 默认 10M | |
| -E, --encoding | 描述文本编码, 默认是 auto | https://encoding.spec.whatwg.org/#concept-encoding-get |
| -f, --file … | 从文件中读入 pattern, 一行一 pattern | 可以被多次使用或和-e 一起组合使用,所以有组合会被匹配 |
| –files | 打印所有将被搜索的文件 | 以rg <options> --files [PATH...]方式使用,不能加 pattern |
| -l, --files-with-matches | 只打印有匹配的文件名 | 覆盖–files-without-match |
| –files-without-match | 只打印无匹配的文件名 | 覆盖 --file-with-matches |
| -F, --fixed-strings | 把 pattern 当成常规文字而非 regex | 可以用–no-fixed-strings 来禁止这个选项 |
| -L, --follow | 会递归搜索链接,默认关闭 | 可以用–no-follow 来关闭 |
| -g, --glob … | 通配符文件或文件夹,可以用!来取反 | 可以多次使用, 会匹配.gitignore 的通配符规则 |
| -h, --help | 打印帮助信息 | |
| –heading | 打印文件名到匹配内容的上方而不是同一行 | 这是默认行为,可以用–no-heading 来关闭 |
| –hidden | 搜索隐藏文件和文件夹 | 默认忽略, 可用–no-hidden 关闭 |
| –iglob … | 同–glob, 但这个大小写不敏感 | |
| -i, --ignore-case | pattern 大小写不敏感 | 可通过-s/–case-sensitive 或-S/–smart-case 覆盖这个选项 |
| –ignore-file
| 忽略路径,格式同.gitignore, 可多个 | 多个–ignore-file 标记时,后面优先级高 |
| 在命令上时,使用-g 来达到同样效果 | ||
| -v, --invert-match | 反向匹配 | |
| -n, --line-number | 显示文件行数,默认打开 | |
| -x, --line-regexp | 只显示整行都匹配 pattern 的行 | 会覆盖–word-regexp |
| -M, --max-columns | 不打印长于列的匹配行 | |
| -m, --max-count | 限制一个文件最多行匹配 | |
| –max-depth | 限制文件夹递归搜索深度 | rg --max-depth 0 dir/不执行任何搜索 |
| –max-filesize <NUM+SUFFIX?> | 忽略大于byte 的文件 | suffix 可以是 K, M,G, 默认是 byte |
| –mmap | 尽量使用 memory maps, 默认行为 | 目前它不支持所有选项, 用–no-mmap 来关闭 |
| –no-config | 不读取 conf 文件, 忽略 RIPGREP_CONFIG_PATH | |
| –no-filename | 不要打印匹配文件名 | |
| –no-heading | 在每个匹配行前都打印文件名 | |
| –no-ignore | 取消 ignore 文件,如.gitignore, .ignore | 可以用–ignore 关闭 |
| –no-ignore-global | 取消对全局的 ignore 文件读取 | 如$HOME/.config/git/ignore |
| –no-ignore-messages | 取消解析.ignroe, .gitignore 文件相关错误 | 可通过–ignore-messages 关闭 |
| –no-ignore-parent | 不读取父文件夹里的.gitignore, .ignore 文件 | 可通过 --ignore-parent 关闭 |
| –no-ignore-vcs | 只全能.ignore 文件 | 可通过–ignore-vcs 关闭 |
| -N, --no-line-number | 不打印匹配行数 | |
| –no-messages | 不打印打开和读取文件相关错误 | |
| -0, --null | 在打印的文件路径后加一个 NUL 字符 | 对于 xargs 非常有用 |
| -o, --only-matching | 只打印匹配的内容,而不是整行 | |
| –passthru | 打印匹配和不匹配的行 | |
| –path-separator | 路径分隔符,在 linux 上默认是/ | |
| –pre | 用处理文件,并将结果给 rg | 可能有巨大的性能惩罚 |
| 例如 | ||
| case “$1” in | ||
| *.pdf) | ||
| exec pdftotext “$1” - | ||
| ;; | ||
| *) | ||
| case $(file “$1”) in | ||
| Zstandard) | ||
| exec pzstd -cdq | ||
| ;; | ||
| *) | ||
| exec cat | ||
| ;; | ||
| esac | ||
| ;; | ||
| esac | ||
| -p, --pretty | --color always --heading --line-number | |
| -q, --quiet | 不打印到 stdout, 如果匹配发现,停止 rg | 当 rg 用于 exit 代码时非常有用 |
| –regex-size-limit <NUM+SUFFIX?> | 编译 regex 的上限 | |
| -e, --regexp … | 使用正则来匹配 | 可多次使用这个选项,打印匹配任何 pattern 的行 |
可以用于搜索-开头的 pattern,如rg -e -foo | ||
| -r, --replace <REPLACEMENT_TEXT> | 用相应文件代替匹配内容打印出来 | 组序号($5)可以被使用 |
| -z, --search-zip | 在 gz,bz2,xz,lzma,lz4 文件类型中搜索 | 可通过–no-search-zip 关闭 |
| -S, --smart-case | 如果全小写,则大小写不敏感,否则敏感 | 可通过-s/–case-sensitive 和-i/–ignore-case 关闭 |
| –sort-files | 根据文件路径排序输出结果 | 会关闭并行搜索线程 |
| –stats | 打印出统计结果 | |
| -a, --text | 搜索二进制文件 | 可通过–no-text 关闭 |
| -j, --threads | 大约使用的线程数 | |
| -t, --type … | 只搜索某种文件类型 | 可通过–type-lsit 来列出支持的文件类型 |
| –type-add <TYPE_SPEC>… | 添加文件类型 | 如rg --type-add 'foo:*.foo' -tfoo PATTERN |
| 也可以用来创建某种包含多种文件类型的规则 | –type-add ‘src:include:cpp,py,md’ | |
| –type-clear … | 清除默认的文件类型 | |
| –type-list | 列出所有内置文件类型 | |
| -T, --type-not … | 不要搜索某种文件类型 | |
| -u, --unrestricted | -u 搜索.gitignore 里的文件, -uu 搜索隐藏文件 | -uuu 搜索二进制文件 |
| -V, --version | 打印版本信息 | |
| –vimgrep | 每一次匹配打印一行 | 一行有多次匹配会打印多行 |
| -H, --with-filename | 打印匹配的文件路径,默认 | 可通过–no-filename 关闭 |
| -w, --word-regexp | 把 pattern 作为单独单词匹配,与< >等价 |
export FZF_DEFAULT_OPTS="--height 80% --layout=reverse --border --preview '~/Tools/Other/fzf-scope.sh {} '"
export FZF_DEFAULT_COMMAND="fd --exclude={.wine,.git,.idea,.vscode,.sass-cache,node_modules,build,.local,.steam,.m2,.rangerdir,.ssh,.ghidra,.mozilla} --type f --hidden --follow"
#!/bin/bash
case "$1" in
*.pdf) pdftotext "$1" ;;
*.md) glow -s dark "$1" ;;
*.zip) zipinfo "$1" ;;
*.7z) 7z l "$1" ;;
*) bat --color=always --italic-text=always --style=numbers,changes,header --line-range :500 "$1" ;;
esac
fzf --preview ‘rg {}’
fzf --preview ‘bat --style=numbers --color=always --line-range :500 {}’
chcp 65001
chcp 437
chcp 950
chcp 936
Environment variables
FZF_DEFAULT_COMMAND
Default command to use when input is tty
FZF_DEFAULT_OPTS
Default options
(e.g. ‘–layout=reverse --inline-info’)
busybox
http://k.japko.eu/busybox-vi-tutorial.html
| A | B | C | D | E | F | G |
|---|---|---|---|---|---|---|
| [.exe | [[.exe | ar.exe | arch.exe | ascii.exe | ash.exe | |
| awk.exe | base32.exe | base64.exe | basename.exe | bash.exe | bc.exe | bunzip2.exe |
| busybox.exe | bzcat.exe | bzip2.exe | cal.exe | cat.exe | chattr.exe | chmod.exe |
| cksum.exe | clear.exe | cmp.exe | comm.exe | cp.exe | cpio.exe | crc32.exe |
| cut.exe | date.exe | dc.exe | dd.exe | df.exe | diff.exe | dirname.exe |
| dos2unix.exe | dpkg-deb.exe | dpkg.exe | du.exe | echo.exe | ed.exe | egrep.exe |
| env.exe | expand.exe | expr.exe | factor.exe | false.exe | fgrep.exe | find.exe |
| fold.exe | free.exe | fsync.exe | ftpget.exe | ftpput.exe | getopt.exe | grep.exe |
| groups.exe | gunzip.exe | gzip.exe | hd.exe | head.exe | hexdump.exe | httpd.exe |
| iconv.exe | id.exe | inotifyd.exe | install.exe | ipcalc.exe | kill.exe | killall.exe |
| less.exe | link.exe | ln.exe | logname.exe | ls.exe | lsattr.exe | lzcat.exe |
| lzma.exe | lzop.exe | lzopcat.exe | man.exe | md5sum.exe | mkdir.exe | mktemp.exe |
| mv.exe | nc.exe | nl.exe | nproc.exe | od.exe | paste.exe | patch.exe |
| pgrep.exe | pidof.exe | pipe_progress.exe | pkill.exe | printenv.exe | printf.exe | ps.exe |
| pwd.exe | readlink.exe | realpath.exe | reset.exe | rev.exe | rm.exe | rmdir.exe |
| rpm.exe | rpm2cpio.exe | sed.exe | seq.exe | sh.exe | sha1sum.exe | sha256sum.exe |
| sha3sum.exe | sha512sum.exe | shred.exe | shuf.exe | sleep.exe | sort.exe | split.exe |
| ssl_client.exe | stat.exe | strings.exe | su.exe | sum.exe | sync.exe | tac.exe |
| tail.exe | tar.exe | tee.exe | test.exe | time.exe | timeout.exe | touch.exe |
| tr.exe | true.exe | truncate.exe | ts.exe | ttysize.exe | uname.exe | uncompress.exe |
| unexpand.exe | uniq.exe | unix2dos.exe | unlink.exe | unlzma.exe | unlzop.exe | unxz.exe |
| unzip.exe | uptime.exe | usleep.exe | uudecode.exe | uuencode.exe | vi.exe | watch.exe |
| wc.exe | wget.exe | which.exe | whoami.exe | whois.exe | xargs.exe | xxd.exe |
| xz.exe | xzcat.exe | yes.exe | zcat.exe |
zstd 快速的无损压缩算法 压缩工具
参数:
zstd --help
使用方式 :
zstd [args] [FILE(s)] [-o file]
参数选项 :
-# : 压缩级别(1-19,默认值为3)
-d : 解压
-D file: 使用文件作为字典
-o file: 结果存储在文件中
-f : 在没有提示的情况下覆盖输出并(解压)压缩链接
--rm : 成功解压缩后删除源文件
-k : 保存源文件(默认)
-h/-H : 显示帮助/长帮助并退出
高级选项 :
-V : 显示版本号并退出
-v : 详细模式
-q : 静默输出
-c : 强制写入标准输出
-l : 输出zstd压缩包中的信息
--ultra : 启用超过19级,最多22级(需要更多内存)
-T# : 使用几个线程进行压缩(默认值:1个)
-r : 递归地操作目录
--format=gzip : 将文件压缩为.gz格式
-M# : 为解压设置内存使用限制
字典生成器 :
--train ## : 从一组训练文件中创建一个字典
--train-cover[=k=#,d=#,steps=#] : 使用带有可选参数的cover算法
--train-legacy[=s=#] : 有选择性地使用遗留算法(默认值:9)
-o file : “file”是字典名(默认:字典)
--maxdict=# : 将字典限制为指定大小(默认值:112640)
--dictID=# : 强制字典ID为指定值(默认:随机)
性能测试参数 :
-b# : 基准测试文件,使用#压缩级别(默认为1)
-e# : 测试从-bX到#的所有压缩级别(默认值:1)
-i# : 最小计算时间(秒)(默认为3s)
-B# : 将文件切成大小为#个独立块(默认:无块)
--priority=rt : 将进程优先级设置为实时
简单使用
将一个文件压缩成一个后缀为.zst的新文件
如果命令后面没有文件或文件为-的话,则读取标准输入
zstd file
在压缩操作后删除源文件
默认情况下,源文件在成功压缩或解压缩后不会被删除
zstd --rm file
解压zst压缩包
zstd -d file.zst
解压zst压缩包到标准输出
zstd -dc file.zst
查看zst压缩包
zstd -l file.zst
zstdcat file.zst
高级用法
输出详细信息
zstd -v file
zstd -v -d file.zst
压缩一个文件同时指定压缩级别(19最高,0最低,3为默认)
zstd -level file
zstd -9 file
使用更多的内存(压缩和解压时)以达到更高的压缩比
zstd --ultra -level file
解压缩为单进程
多个进程并发执行压缩过程(0表示自动使用所有CPU核心)
zstd -T0 file
zstd -T4 file
zstd -T4 -d file.zst
Linux 命令行下的二维码,主要核心是这个网址:http://qrenco.de/
echo “https://www.sqlsec.com” |curl -F-=<- qrenco.de
















 1338
1338

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











