







近期闲来无事学学selenium爬虫技术,参考崔庆才《Python3网络爬虫开发实战》的淘宝商品信息爬取,我也照猫画虎的学了京东的价格和商品评论数据。废话不多说,直接开始吧!
1. 浏览器初始化
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
import time
import re
options = Options()
options.add_argument('--headless') #使用无头浏览器(PhantomJS已经不支持了)
browser = webdriver.Chrome(options = options)
browser.maximize_window()
wait = WebDriverWait(browser, 10)注意这里的browser.maximize_window()非常重要,否则京东自己的弹窗会屏蔽掉网页自身的按钮。
2. 商品页搜索
这里我用的搜索页是京东商品搜索,页面比较简洁。
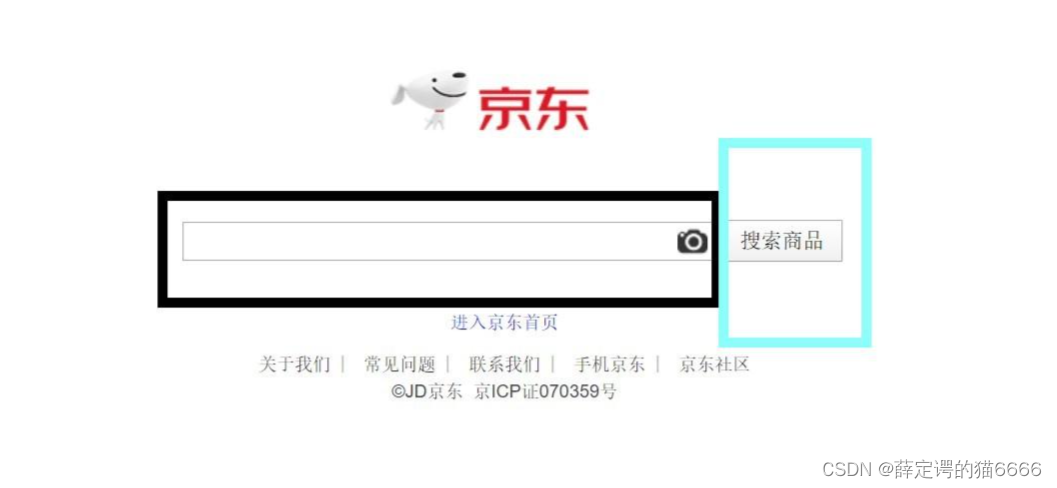
在Chrome浏览器中右键检查后可以看到

搜索商品输入框(黑框)的id是keyword
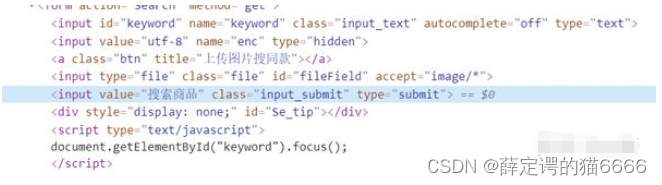
搜索商品确认框(蓝框)的class是input_submit,于是我写了如下代码
def search(keyword):
browser.get("https://search.jd.com/")
input_ = wait.until(EC.presence_of_element_located((By.ID, 'keyword')))
submit = wait.until(EC.element_to_be_clickable((By.CLASS_NAME, "input_submit")))
input_.clear()
input_.send_keys(keyword)
submit.click()
由于最近肺炎比较严重,我们keyword不妨设为口罩,submit过后,我们就会来到商品页。我们先判断口罩商品一共有多少页

可以看到一共有100页,不过在滑动的过程中我们发现网页是不断加载出来的,所以我们代码也得进行滑动到最底端这个操作,现在我们先观察如何获得100这个数字。
 事实上他就是class为p-skip的span元素下属的b元素的文本而已。综上我给出搜索商品及获得页数这块的整体代码
事实上他就是class为p-skip的span元素下属的b元素的文本而已。综上我给出搜索商品及获得页数这块的整体代码
def search(keyword):
browser.get("https://search.jd.com/")
input_ = wait.until(EC.presence_of_element_located((By.ID, 'keyword')))
submit = wait.until(EC.element_to_be_clickable((By.CLASS_NAME, "input_submit")))
input_.clear()
input_.send_keys(keyword)
submit.click()
print("Success")
# 滑到最底端
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
# 总页数
number = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.p-skip b'))).text
return number3. 获得每个商品链接
我们观察商品链接处的源代码(红框处)
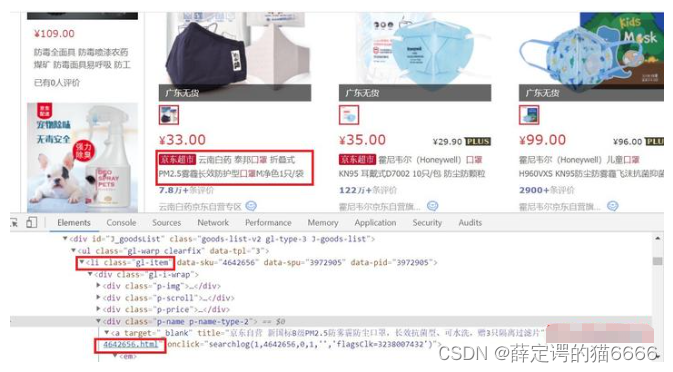 可以发现他们是属于.gl-item的li元素下的.p-name的div元素(.表示class),并且target为_blank,于是我们可以这样访问
可以发现他们是属于.gl-item的li元素下的.p-name的div元素(.表示class),并且target为_blank,于是我们可以这样访问
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.gl-item .p-name [target=_blank]')))
url_list = browser.find_elements_by_css_selector(".gl-item .p-name [target=_blank]")
for url in url_list:
link_list.append(url.get_attribute("href") + "#comment") # 加上#comment是因为这是评论页的后缀
那么link_list里面就包含了我们所有需要的link信息(说明一下,webelement用get_attribute获得href比用bs4解析要好,他会自动补全上级链接信息。如果直接用bs4解析网址,可能你得到的网址没有加"https")
接下来我们要进行换页,同样是下拉到最底端
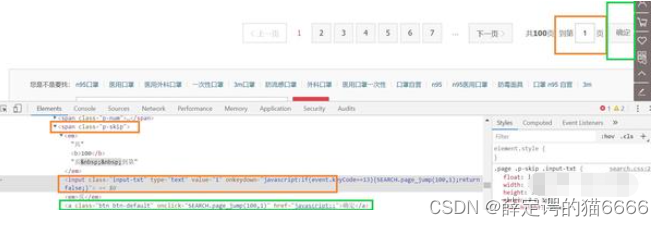 橙框是输入页数框,可以看到他是p-skip下input-text,绿框是确认框,他是p-skip下btn。同时input-text也显示目前所在页数,可以作为我们的翻页是否成功的检验,我们有如下代码。
橙框是输入页数框,可以看到他是p-skip下input-text,绿框是确认框,他是p-skip下btn。同时input-text也显示目前所在页数,可以作为我们的翻页是否成功的检验,我们有如下代码。
def change_page(page):
print("正在爬第", page, "页")
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(3)
page_box = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.p-skip input')))
page_box.clear()
page_box.send_keys(str(page))
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.p-skip .btn')))
submit.click()
# 检查是否加载成功
wait.until(EC.text_to_be_present_in_element_value((By.CSS_SELECTOR, '.p-skip input'), str(page)))在滑到最下面用time.sleep强制休息一下,不然输入框可能加载不出来(估计京东有反爬措施)。并且每次运行完change_page获得商品链接的时候也sleep加载一下
4. 爬取评论
下面就是最难的爬评论了,京东的限制还是比较多的。
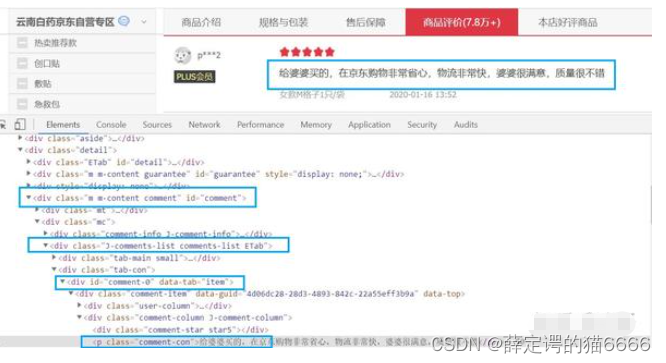
打开评论页发现评论的结构还是蛮简单的,每个评论就是#comment下.comments-list的[data-tab=item],评论文字就是.comment-con的text。对于评论的提取我们不再用webelement的find方式,因为容易出现stale element错误(加载太慢),转而使用bs4的select函数。
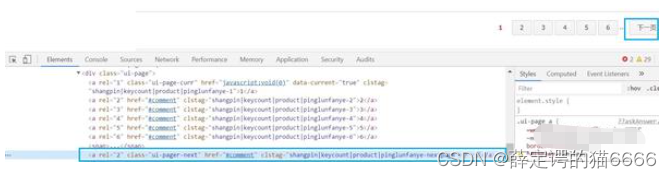
换页的定位也不难,不过下一页按钮容易被小图标遮挡,我们用browser.execute_script("arguments[0].click();", next_page) 解决问题。值得注意的是,如果换页太快容易被京东检测到,所以我们爬取一会儿休息一下。
def get_comment(link):
product_id = re.search("https://item.jd.com/(\d+).html#comment", link).group(1)
browser.get(link)
count = 0
file = open("JD_%s_comments.txt"%product_id, "a", encoding='utf-8')
while True:
try:
if count%10 == 0:
time.sleep(3)
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,"#comment .comments-list [data-tab=item] .comment-con")))
soup = BeautifulSoup(browser.page_source, 'lxml')
url_list = soup.select("#comment .comments-list [data-tab=item] .comment-con")
for url in url_list:
file.write(url.text.strip()+"\n")
count += 1
next_page = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#comment .ui-page .ui-pager-next")))
browser.execute_script("arguments[0].click();", next_page) # 被图标遮挡了
except TimeoutException:
print("已爬取", count, "页评论")
file.close()
break最后我们整合一下完整代码,爬取就完成了
"""
Created on Mon Feb 3 21:01:53 2020
@author: Simon
"""
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
import time
import re
options = Options()
options.add_argument('--headless')
browser = webdriver.Chrome(options = options)
browser.maximize_window()
wait = WebDriverWait(browser, 10)
def search(keyword):
browser.get("https://search.jd.com/")
input_ = wait.until(EC.presence_of_element_located((By.ID, 'keyword')))
submit = wait.until(EC.element_to_be_clickable((By.CLASS_NAME, "input_submit")))
input_.clear()
input_.send_keys(keyword)
submit.click()
print("Success")
# 滑到最底端
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
# 总页数
number = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.p-skip b'))).text
return number
def change_page(page):
print("正在爬第", page, "页")
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(3)
page_box = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.p-skip input')))
page_box.clear()
page_box.send_keys(str(page))
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.p-skip .btn')))
submit.click()
# 检查是否加载成功
wait.until(EC.text_to_be_present_in_element_value((By.CSS_SELECTOR, '.p-skip input'), str(page)))
def get_comment(link):
product_id = re.search("https://item.jd.com/(\d+).html#comment", link).group(1)
browser.get(link)
count = 0
file = open("JD_%s_comments.txt"%product_id, "a", encoding='utf-8')
while True:
try:
if count%10 == 0:
time.sleep(3)
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,"#comment .comments-list [data-tab=item] .comment-con")))
soup = BeautifulSoup(browser.page_source, 'lxml')
url_list = soup.select("#comment .comments-list [data-tab=item] .comment-con")
for url in url_list:
file.write(url.text.strip()+"\n")
count += 1
next_page = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#comment .ui-page .ui-pager-next")))
browser.execute_script("arguments[0].click();", next_page) # 被图标遮挡了
except TimeoutException:
print("已爬取", count, "页评论")
file.close()
break
if __name__ == '__main__':
number = search("口罩")
link_list = []
for page in range(1, int(number) + 1):
change_page(page)
time.sleep(3)
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.gl-item .p-name [target=_blank]')))
url_list = browser.find_elements_by_css_selector(".gl-item .p-name [target=_blank]")
for url in url_list:
link_list.append(url.get_attribute("href") + "#comment")
for link in link_list:
get_comment(link)













 6778
6778











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









