







本文用于记录LeetCode中有关单链表这部分知识的题目:题目名称及编号如下:
目录
LeetCode——剑指offer.22-链表中倒数第k个结点:
LeetCode.876——链表中间结点:
具体题目如下:

上篇文章列举了几个关于使用双指针法来解决的题目。对于此题,依旧可以采用双指针法进行解答:
首先创建两个指针,一个指针每次可以访问后面的一个结点,另一个指针可以访问后面的第二个结点。将这两个指针分别命名为:,
对于链表结点数为奇数的情况: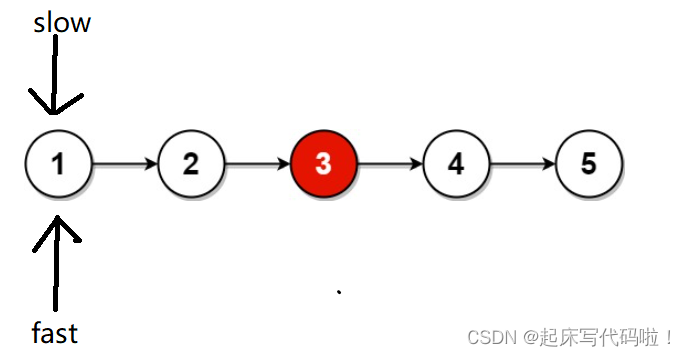
当 指针运行到链表的最后一个结点时,
指针恰好处于链表中间的结点,即:
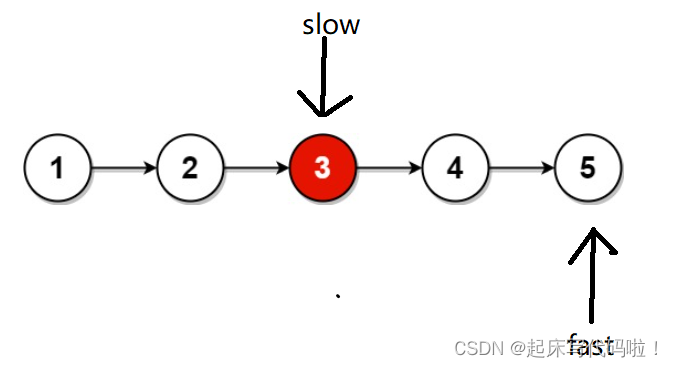
对于链表中结点数为偶数的情况,即:
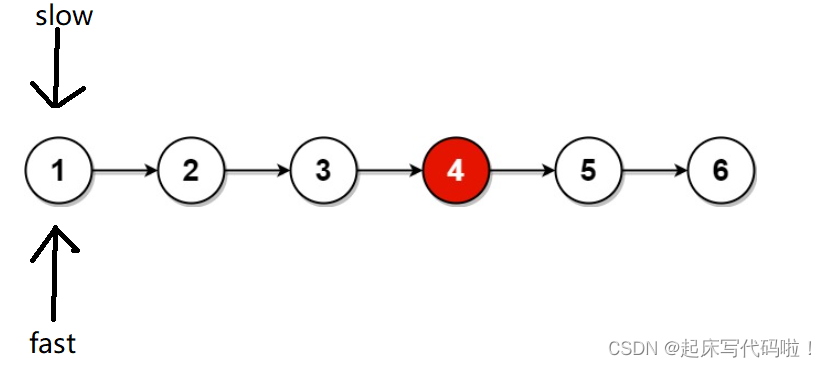
当 指针处于目标结点时,
指针位置为:

所以,对于链表中结点的数量是奇数还是偶数,需要进行区分:这里的区分就体现在了判断循环是否继续的条件上
对于结点数量为奇数的情况:此时指针指向了链表的最后一个结点,由链表的结构可知,最后一个结点存储的地址为
.所以,此时的判定循环是否继续的条件为:
对于结点数量为偶数的情况:此时指针指向的位置在链表最后一个结点的后面,所以,
指向的地址为
,判定循环是否继续的条件为:
将上述过程用代码表示,即:
struct ListNode* middleNode(struct ListNode* head){
struct ListNode* slow = head;
struct ListNode* fast = head;
while( fast && fast -> next)
{
slow = slow -> next;
fast = fast -> next -> next;
}
return slow;
}结果如下:
LeetCode——剑指offer.22-链表中倒数第k个结点:
题目如下:
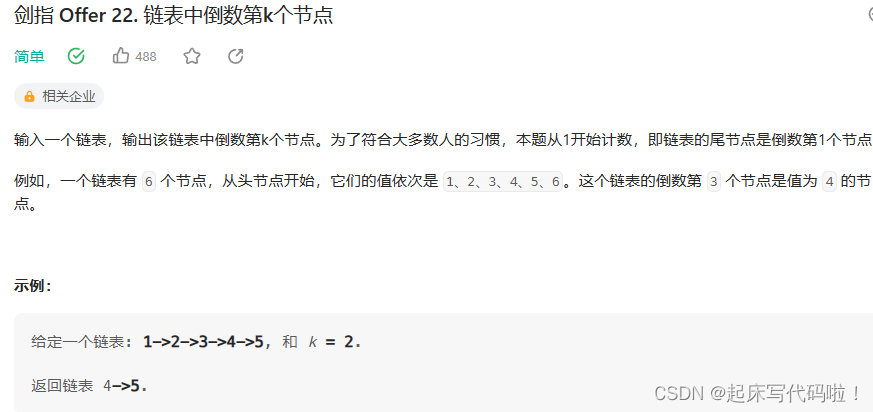
对于此题,采用与寻找中间结点时类似的方法,即:创建,
这两个指针。例如寻找倒数第
个结点时,倒数第三个结点就是正数第二个结点,所以可以先让
走
步,当
走完后,再让
,
一起向后遍历。当
,
对应的结点恰好是倒数第
个结点,即:
代码表示如下:
struct ListNode* getKthFromEnd(struct ListNode* head, int k){
struct ListNode* slow = head,*fast = head;
while( k--)
{
fast = fast->next;
}
while(fast)
{
fast = fast->next;
slow = slow->next;
}
return slow;
}执行结果如下:
LeetCode.206——反转链表:
题目如下:
在顺序表中,改变线性表的顺序只需要将线性表中的值交换位置即可,但是在链表中,因为存储空间并不是连续的,所以不能采用处理改变顺序表顺序的方法。
思路一:
但是,从图上可以看出来,所谓的反转链表,可以通过改变各个结点存储的地址来完成。例如存储了数据的结点,如果想让这两个结点实现反转的效果,只需要让
号结点存储
号结点的地址即可。即:
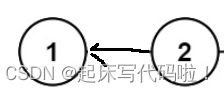
对于一个链表,其最后一个结点存储的地址为,所以,在进行翻转后,存储数据
的结点就是最后一个结点,这个结点中存储的地址应该改为
,所以,为了达到上面的目的,需要创建两个指针,一个用于保存
结点的地址,另一个保存
。将这两个指针,分别命名为:
,即:
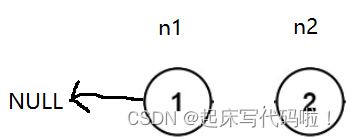
不过此时会出现一个问题,原本结点存储了
结点的地址,但是现在将
结点中存储的地址改为
。导致了
结点的丢失,无法进行后续操作。为了解决这一问题,再创建一个指针用于保存
结点的地址,命名为
,即:
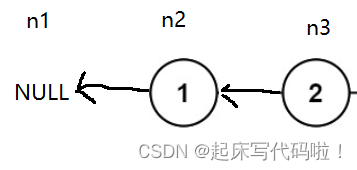
从上面的一步可以看出,三个指针中,适用于链接结点。
适用于存储下一个结点的地址。所以,在对后面的结点进行反转时,依旧沿用三个指针的方法,例如在下一步中,需要:
让存储
中的地址,让
存储
中的地址,即:

再通过改变结点中存储的地址,让结点建立联系。当链接
结点时,此时三个指针的位置如下:

所以,判断程序结束的标志,就是指针是否为空。
将上述过程用代码表示:
struct ListNode* reverseList(struct ListNode* head){
struct ListNode*n1,*n2,*n3;
n1 = NULL;
n2 = head;
if(n2)
{
n3 = n2->next;
}
while(n2)
{
n2->next = n1;
n1 = n2;
n2 = n3;
if(n3)
{
n3 = n3->next;
}
}
return n1;
}其中,语句用于检查指针保存的地址是否为空。
思路二:
头插法:新创建一个指针,让上述结点在
的基础上进行头插,头插结束后,这个指针中存储的地址变为刚刚插入的结点的地址,具体效果如下:
初始阶段: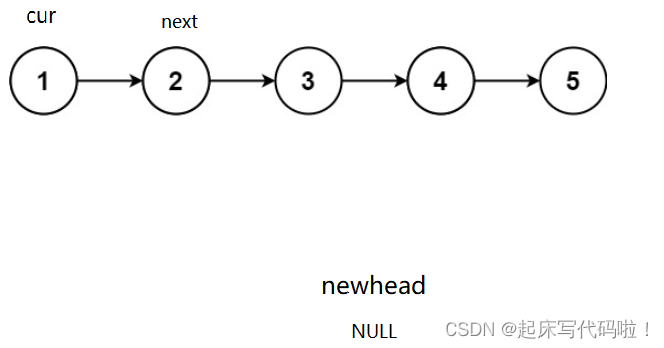
头插一次后:
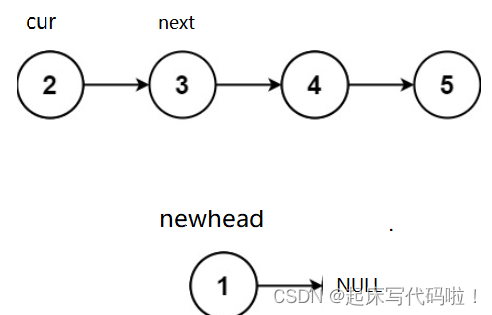
因为进行一次头插后,保存元素的结点中存储的地址从下一个结点的地址被改为
,造成了下一个结点地址的丢失。所以,为了保存下一个结点的地址。另外创建一个指针
来存储下一个结点的地址,代码如下:
struct ListNode* reverseList(struct ListNode* head){
struct ListNode* newhead = NULL,*cur = head;
while(cur)
{
struct ListNode* next = cur -> next;
cur -> next = newhead;
newhead = cur;
cur = next;
}
return newhead;
}结果如下:
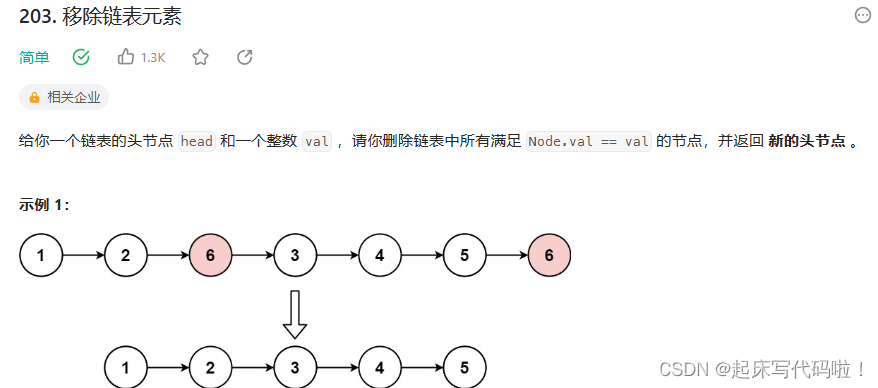
LeetCode.203——移除链表元素:
题目如下:
思路1:
题目要求删除满足一定条件的某个结点。对于在链表中删除某个元素,只需要将链表进行遍历,并且删除满足条件的结点即可。但是如果要达到删除结点,并且将其他结点建立一定的关系,则依旧需要采用双指针的方法:即一个结点用于向后遍历,另一个结点
用于存储
遍历之前的位置。当遇到满足条件的结点时,即:

只需要先将中存储的地址进行改变:
再将指针对应的结点消除:
最后将 存储的地址改变:
.
当对应的结点不满足条件时,即:

向下遍历即可,并且用保存
遍历之前的地址:
但是,当链表的第一个结点就是需要删除的结点时,例如:
此时,如果再按照上面删除结点的代码,即: 运行。会因为
本来就为
而导致错误。所以,对着这种特殊情况,需要在不使用
的情况下删除这部分结点。在题目中提供了一个头结点
,在这种情况下,可以使用头结点来达到删除的目的:
1. 首先判断是否等于
,若不等于则按照上面的方法常规删除。若等于则按照下面的步骤进行处理:
2.让存储下一个结点的地址。并且删除
对应的结点
3.让保存
中存储的地址。
用代码表示上述过程,即:
struct ListNode* removeElements(struct ListNode* head, int val){
struct ListNode* prev = NULL;
struct ListNode* cur = head;
while(cur)
{
if(cur->val == val)//删除
{
if(cur == head)//类似头删
{
head = head->next;
free(cur);
cur = head;
}
else
{
prev->next = cur->next;
free(cur);
cur = prev->next;
}
}
else//向下遍历
{
prev = cur;
cur = cur->next;
}
}
return head;
}思路2:
可以参考上篇文章中将等于值的删除这一题目的思路,即将不等于
的值尾插到新的数组中。同样,对于本题可以建立一个新的结点用于存储
,将存储的数据不等于
的结点在
后进行尾插,即:
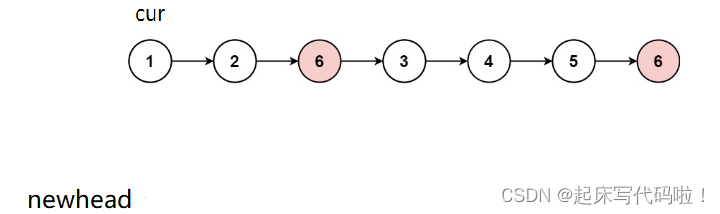
当指针所对应的结点中存储的值不等于
时,便把这个结点在
后面进行一次尾插,即:
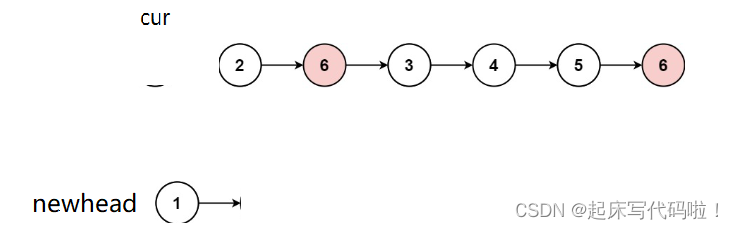
不过,每一次尾插都需要寻找链表的尾部,过于消耗时间,所以,再创建一个指针用于记录每次尾插后链表的尾部链接,再每次尾插过后,
都会记录刚刚尾插进来的结点的地址,即:
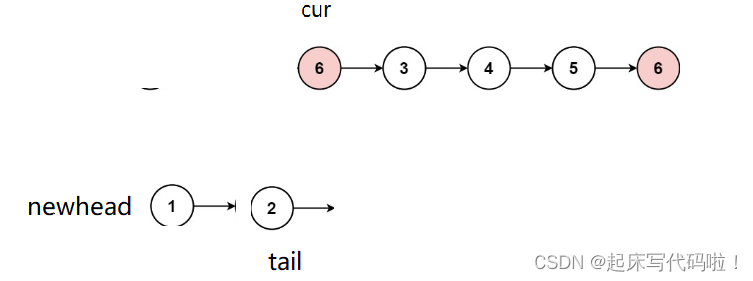
这种方法虽然在表达上是重新建立一个链表,但是其空间复杂度相对于上面的方法并没有发生改变。因为在这种方法中,并没有创建新的链表,只是在原来链表的基础山,不使用原来链表给的头指针,而是认为定义了一个新的开头
,并且,题目要求返回链表的头部,所以,为了不改变
中存储的地址,创建了另一个指针
代替
完成将各个尾插的结点进行链接的功能。并且再链接第一个结点时,同时将这个结点的地址赋值给
,在最后返回时,
就能通过保存的第一个结点的地址,来找到后续结点。
代码表示如下:
struct ListNode* removeElements(struct ListNode* head, int val){
struct ListNode* cur = head;
struct ListNode* newnode = NULL,*tail = NULL;
while(cur)
{
//删除结点
if(cur->val == val)
{
struct ListNode* del = cur;
cur = cur->next;
free(del);
}
//尾插
else
{
if(tail == NULL)
{
newnode = tail = cur;//建立newnode和cur之间的联系
}
else{
tail->next = cur;
tail = tail->next;
}
cur = cur->next;
}
}
if(tail)//判断是否原链表为空
{
tail->next = NULL;
}
return newnode;
}执行结果如下:
LeetCode.21——合并两个有序链表:
题目如下:
思路一:
对于合并两个有序链表这个体,题目中要求返回一个新的升序链表,所以,可以采用之前合并升序数组时所用的思路,即:比较两个链表中每个元素的大小,取较小的进行尾插。题目中分别给了两个指针变量:,
。用于对给出的两个有序链表进行遍历。再返回新的链表时,可以采用上一个题目中的思路,创建两个指针
,
,具体操作过程如下:
取较小的在后进行尾插:(相等则优先取
对应的链表的结点。)
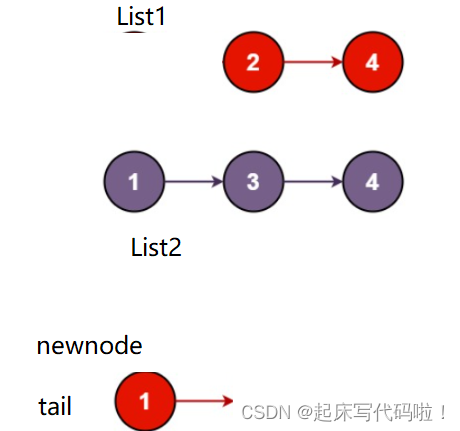
继续向下运行,最后会出现:
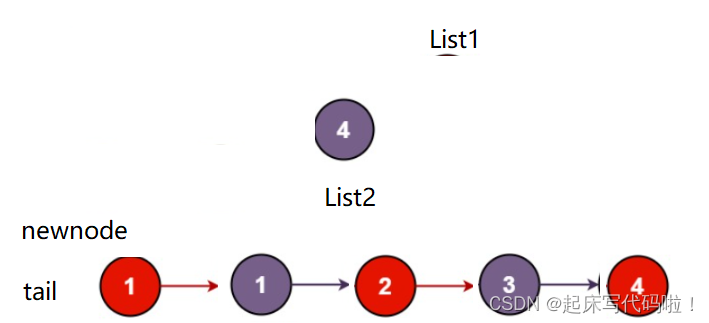
此时对应的链表已经全部遍历完成。所以,可以将
作为循环是否进行的标志。在结束后,将
中剩余的结点直接向后尾插即可。
代码如下:
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2){
//判断链表是否为空
if(list1 == NULL)
{
return list2;
}
if(list2 == NULL)
{
return list1;
}
struct ListNode*newhead = NULL,*tail = NULL;
//从小到大尾插
while( list1 && list2)
{
//list1结点的值大
if( list1 -> val < list2 -> val )
{
//开头还没有元素的情况
if(tail == NULL)
{
newhead = tail = list1;
}
//已经插入了元素的情况
else
{
tail -> next = list1;
tail = tail -> next;
}
list1 = list1 -> next;
}
//list2结点的值大
else
{
if(tail == NULL)
{
newhead = tail = list2;
}
else
{
tail -> next = list2;
tail = tail -> next;
}
list2 = list2 -> next;
}
}
//将 剩余的结点和前面尾插形成的链表建立联系
if(list1)
{
tail -> next = list1;
}
if(list2)
{
tail -> next = list2;
}
return newhead;
}执行结果如下:
思路二:
之前的文章在介绍单链表的相关功能实现时,是没有哨兵位头结点的单链表。对于这种链表在进行尾插时,第一次进行尾插和后续进行尾插所需的操作是不同的。例如上面的思路所给出的代码,当第一次进行尾插时,需要直接改变指针指向的内容,即:
但是在后续的尾插操作中,只需要改变前一个结点中存储的地址即可,即:
如果,对于上面的思路,采用含有哨兵位头结点的单链表,,会由一个结构体存储链表第一个结点而非指针。对含有哨兵位头结点的单链表进行尾插操作时,不管是第一个结点还是后续的结点。都只需要改变哨兵位头结点,即结构体中存储的地址。不再需要针对第一次、后续尾插进行不同情况的分类。代码如下:
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2){
//判断链表是否为空
if(list1 == NULL)
{
return list2;
}
if(list2 == NULL)
{
return list1;
}
struct ListNode*newhead = NULL,*tail = NULL;
newhead = tail = (struct ListNode*)malloc(sizeof(struct ListNode));
//从小到大尾插
while( list1 && list2)
{
//list1结点的值大
if( list1 -> val < list2 -> val )
{
tail -> next = list1;
tail = tail -> next;
list1 = list1 -> next;
}
//list2结点的值大
else
{
tail -> next = list2;
tail = tail -> next;
list2 = list2 -> next;
}
}
//将 剩余的结点和前面尾插形成的链表建立联系
if(list1)
{
tail -> next = list1;
}
if(list2)
{
tail -> next = list2;
}
//将哨兵位头结点free掉
struct ListNode* del = newhead;
newhead = newhead -> next;
free(del);
return newhead;
}需要注意的时,题目中的链表并不含哨兵位头结点。所以,再合并完链表后,需要将哨兵位头结点消除,并且返回链表的第一结点。
为了进一步体现带哨兵位头结点链表的方便操作的特点,文章额外给出一个题目:
牛客CM11——链表分割:

假设,需要被排列的链表为:
题目中要求不能改变原来的数据顺序。即不可以改变元素之间的相对顺序。所以,不能采用交换结点中元素的方法来完成。为了解决这个问题。可以创建两个链表。让小于的结点尾插到一个链表。将大于
的结点尾插到另一个链表,最后,让两个链表链接即可。
在创建链表时。如果采用不带哨兵位头结点的链表,则在运行过程中会有很多的问题:
1.假设链表中没有小于的结点。所以,小于
的结点的链表不存在,此时链表的头指针为空。如果在这种情况下进行链接,会引发错误。
2.如同上面的题目中,不带哨兵位的链表在进行尾插或者头插时需要分情况。
但是如果引入了哨兵位头结点,即使一条链表中没有任何的结点。在链接两条链表时,也可以正常进行链接。
为了方便表示,将用于存储小于结点的链表的哨兵位头结点命名为
,将用于存储大于
结点的链表的哨兵位头结点命名为
。在尾插的过程中,为了灵活转换尾插的位置,创建指针
,
对应代码如下:
class Partition {
public:
ListNode* partition(ListNode* pHead, int x) {
struct ListNode* lhead,*ghead,*ltail,*gtail;
ghead = gtail = (struct ListNode*)malloc(sizeof(struct ListNode));
lhead = ltail = (struct ListNode*)malloc(sizeof(struct ListNode));
struct ListNode* cur = pHead;
while(cur)
{
if( cur -> val < x)
{
ltail -> next = cur;
ltail = ltail -> next;
}
else
{
gtail -> next = cur;
gtail = gtail -> next;
}
cur = cur -> next;
}
ltail -> next = ghead -> next;//链接两个链表
//将最后一位结点存储的元素制空
gtail -> next = NULL;
//销毁哨兵位头结点。
struct ListNode* newhead = lhead -> next;
free(lhead);
free(ghead);
return newhead;
}
};执行结果如下:
对于上述代码,需要注意两点:
1.如果按照代码对上面给出的例子进行排序,则:
排序前:
排序后: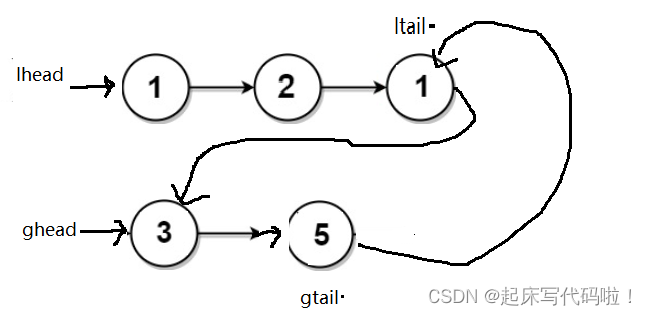
当链表中最大的结点5进行尾插时,会放到ghead对应的链表的最后,但是,此时这个结点中存储的地址却还是指向1结点。但是在正常的单链表中,最后一个结点存储的地址应该指向 所以,在尾插结束后,需要额外添加一步,将最后一个结点存储的地址更改为
。对于置空最后一个结点,也同样可以体现出增加哨兵位头结点的方便。因为假如
对应的链表在进行尾插后,没有结点,则还需要分情况进行讨论。
2.在置空哨兵位头结点时:
对于,需要先创建另一个指针来存储
,再置空
对于,因为
会链接
对应的链表的头结点。直接将
置空即可。
LeetCode.LCR-027——回文链表:
题目如下:
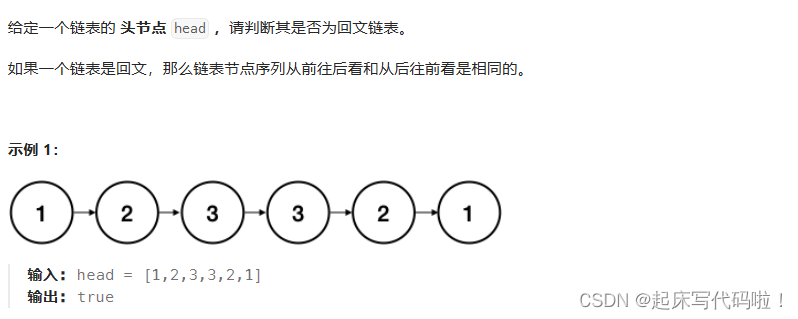
1. 首先,找到链表的中间结点,如果链表的结点数量为偶数个,则找结点。
2. 从上面找到的中间结点开始,把后面的结点全部反转。
3.将逆序的链表与原链表进行比较。若全部相同则判断为回文链表。
对于寻找中间结点和反转链表,可以用到上面题目中的代码:
struct ListNode* middleNode(struct ListNode* head){
struct ListNode* slow = head;
struct ListNode* fast = head;
while( fast && fast -> next)
{
slow = slow -> next;
fast = fast -> next -> next;
}
return slow;
}
struct ListNode* reverseList(struct ListNode* head){
struct ListNode* cur = head, *newhead = NULL;
while(cur)
{
struct ListNode* next = cur -> next;
cur -> next = newhead;
newhead = cur;
cur = next;
}
return newhead;
}
bool isPalindrome(struct ListNode* head){
struct ListNode* mid = middleNode(head);//取中间结点
struct ListNode* rmid = reverseList(mid);//中间结点及之后的结点逆序
while( rmid && head)
{
if( head -> val != rmid -> val)
{
return false;
}
head = head -> next;
rmid = rmid -> next;
}
return true;
}执行结果如下:

LeetCode.160——相交链表:
题目如下: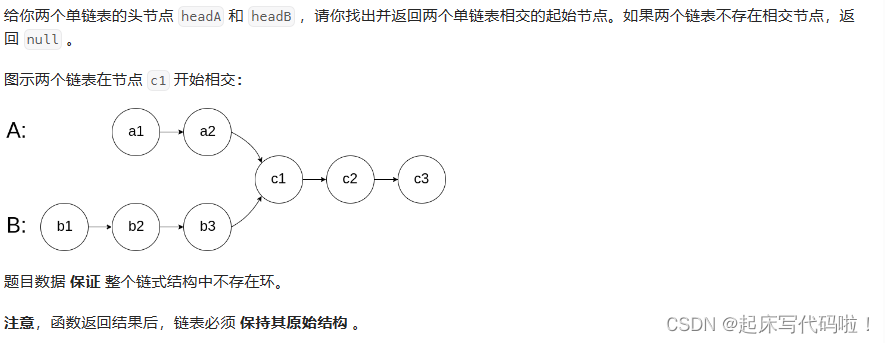
寻找相交结点可以通过遍历来求解。及链表中
结点中存储的地址与
链表中各个结点存储的地址一一对比,找不到则再让
结点一一对比,以此类推。但是这样的方法的时间复杂度为
.过于繁琐。因为不推荐采用这个方法。
寻找相交结点的方法就是通过对比每个结点中存储的地址来实现。但是,因为两个链表的长度是不一样的。不能分别从头开始进行遍历且判断。在解决寻找链表中倒数第个结点 的这个题目中,用到的方法是先让一个指针走
步之后,再让另一个指针往下走。
在本题中,同样可以使用这个方法,即:
1.创建两个指针分别指向,将这两个指针分别命名为
,
。并且创建两个整型变量
,
,用着两个指针分别对链表进行一次遍历。每经过一次遍历,就让整型变量
,最终得到的数值就是链表的长度(即各个链表中结点的个数)
2. 在遍历时,同时也让,
分别找到链表的最后一个结点并且保存这个结点的地址。因为在题目中要求了,如果链表不相交就要返回
.判断链表是否相交。只需要对比两个链表最后一个结点的地址即可。即:
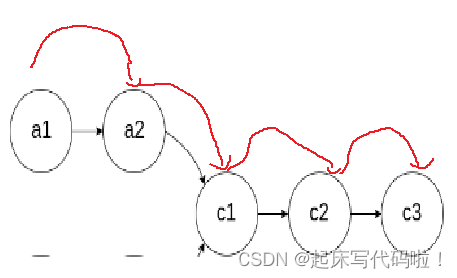
从图中可以看到,当 保存了最后一个结点的地址时,
的值只会增加四次。因为在
指向下一个指针之前,需要判断
是否为空。不过后面会说明
的值比实际值小并没有关系。
3. 在得到,
后,计算二者的差值,并且用绝对值表示,这里的绝对值用
这个变量保存。这样就可以知道两个链表结点的差时多少。
4. 再创建两个结构体指针,
。前面虽然计算出来两个链表之间结点的差值。但是只能得出有一个链表是更加长的。并不能得出哪个链表更长的这个结论。所以,让,
,
进行比较,如果
,则令
,
.如果
则相反。
5.让长的链表,即先走
步,走完就结束。并且将此时的结点看作头结点。此时,两个链表的头结点所对应的编号相同,同时向后遍历,如果出现
则说明找到了相交的点。
上述过程对应的代码如下:
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {
struct ListNode* curA = headA,*curB = headB;
int lenA = 0,lenB = 0;
//计算headA为开头的链表的长度及最后的结点地址
while( curA -> next)
{
curA= curA -> next;
lenA++;
}
//计算headB为开头的链表的长度及最后的结点地址
while( curB -> next)
{
curB = curB -> next;
lenB++;
}
//检查两个链表最后一个结点的地址是否相等。相等则说明有交点
if( curA != curB)
{
return NULL;
}
//计算lenA和lenB的绝对值差值
int gap = abs( lenA - lenB);
//检查lenA和lenB哪个更长
struct ListNode* longlist,*shortlist;
if( lenA > lenB)
{
longlist = headA;
shortlist = headB;
}
else
{
longlist = headB;
shortlist = headA;
}
//longlist先走gap步
while( gap--)
{
longlist = longlist -> next;
}
//上下链表的起点位置没有结点数差,再一起遍历,寻找相交点
while( longlist != shortlist)
{
longlist = longlist -> next;
shortlist = shortlist -> next;
}
return longlist;
}结果如下:
















 442
442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











