







大家好!我是职场程序猿,感谢您阅读本文,欢迎一键三连哦。
精彩专栏推荐👇🏻👇🏻👇🏻
开发环境
开发语言:Python
框架:django
Python版本:python3.7.7
数据库:mysql 5.7
数据库工具:Navicat11
开发软件:PyCharm
浏览器:谷歌浏览器
演示视频
web漏洞挖掘技术的研究(django)演示
源码下载地址:
https://download.csdn.net/download/m0_46388260/87891112
论文目录
【如需全文请按文末获取联系】

一、项目简介
本次技术通过利用Python技术来开发一款针对web漏洞挖掘扫描的技术,通过web漏洞的挖掘扫描来实现对网站URL的漏洞检测,通过高中低风险的判断来实现对一款网站中存在的漏洞进行可视化的分析,从而能够找到问题并且尽快的实现问题的解决。
二、系统设计
2.1软件功能模块设计
此次在漏洞挖掘技术的使用上,主要通过以四个部分来进行相应的内容组成,分别为信息采集、输入参数分析、缺陷检测、缺陷报告产生等来进行设计,其主要的整体设计图如下所示:
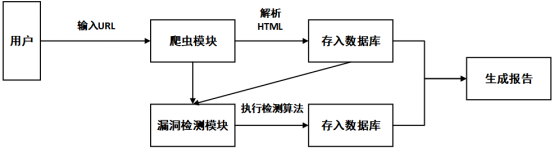
通过上图可以看出此次的系统设计需要通过三大部分来实现有效的功能设计实现,分别为爬虫、漏洞探测、SQL注入,通过这三个步骤之后在网页端形成报告的生成。
(1)爬虫模块是以主题爬虫为最为基础的内容设计,通过对URL的相关数据爬取来实现有效的信息的下载获取;
(2)缺陷探测过程中,通过对正常的URL、带有缺陷的URL等进行检测,将检测出的内容存储在数据库汇总。
(3)通过SQL注入来进行数据库的SQL语句的内容测试。
三、系统项目部分截图
3.1系统的首页面
此次的系统首页面是登录的页面,需要用户完成登录后才能够在网站中实现爬虫的功能应用,。
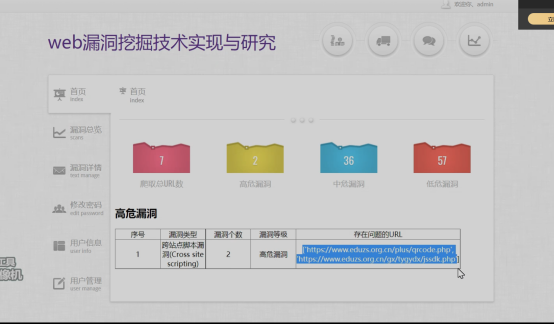
3.2 web漏洞挖掘网站首页
在登录完成后,系统会进入到web漏洞挖掘的网站首页,在该页面中有爬取的总URL数、高危漏洞数、中危漏洞数以及低危漏洞数等。并且其他的功能菜单还有漏洞总览、漏洞详情等功能,配合有个人信息的维护管理的功能模块。如下图所示:
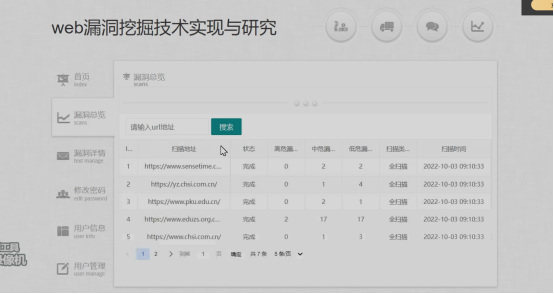
3.3漏洞总览页面
在漏洞总览页面中,能看到扫描历史的主要URL情况,包括扫描的状态,出现的高危、中危、低危的漏洞个数,扫描完成的时间等内容,并且在对话框中也能够进行新的URL地址的输入并且进行搜索。如下图所示:
3.4漏洞详情页面
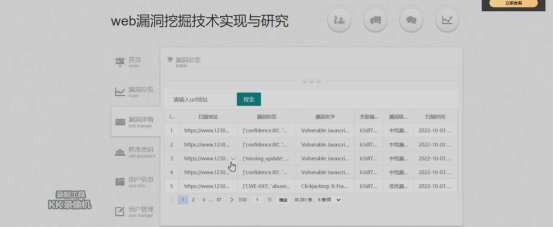
在漏洞详情中,能够看到逐条显示的URL漏洞的名字、关联编号以及漏洞的危险等级等,通过这些信息的归类可以完成对漏洞的详细内容展示的功能实现,如下图所示:
四、部分核心代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import requests
from .Base import Base
class Scan(Base):
def __init__(self, api_base_url, api_key):
super().__init__(api_base_url, api_key)
self.profile_dict = {
'full_scan': '11111111-1111-1111-1111-111111111111',
'high_risk_vuln': '11111111-1111-1111-1111-111111111112',
'xss_vuln': '11111111-1111-1111-1111-111111111116',
'sqli_vuln': '11111111-1111-1111-1111-111111111113',
'weak_passwords': '11111111-1111-1111-1111-111111111115',
'crawl_only': '11111111-1111-1111-1111-111111111117'
}
#self.logger = self.get_logger
def add(self, target_id, profile_key, report_template_id='', schedule=None, ui_session_id=''):
"""添加扫描任务
Args:
target_id (string): 目标ID
profile_key (string): 扫秒类型
schedule (None, optional): 扫秒时间,默认为即时扫描
report_template_id (string, optional): 扫描报告模板ID
ui_session_id (str, optional): Description
schedule格式对照:
1. 定时扫描,time senstive为False
schedule = {disable: False, start_date: "20180816T000000+0700", time_sensitive: False}
2. 定时扫描,time senstive为True
schedule = {disable: False, start_date: "20180816T000000+0700", time_sensitive: True}
3.周期扫描,每天
schedule = {disable: false, recurrence: "DTSTART:20180815T170000Z FREQ=DAILY;INTERVAL=1", time_sensitive: false}
4.周期扫描,每周
schedule = {disable: false, recurrence: "DTSTART:20180815T170000Z FREQ=WEEKLY;INTERVAL=1", time_sensitive: false}
5.周期扫描,每月
schedule = {disable: false, recurrence: "DTSTART:20180815T170000Z FREQ=MONTHLY;INTERVAL=1", time_sensitive: false}
6.周期扫描,每年
schedule = {disable: false, recurrence: "DTSTART:20180815T170000Z FREQ=YEARLY;INTERVAL=1", time_sensitive: false}
7.自定义
修改FREQ和INTERVAL即可
(1)无截止时间格式
schedule = {disable: false, recurrence: "DTSTART:20180815T170000Z FREQ=YEARLY;INTERVAL=1", time_sensitive: false}
(2)有截止时间
schedule = {disable: false, recurrence: "DTSTART:20180815T170000Z FREQ=YEARLY;INTERVAL=1;UNTIL=20180830T170000Z", time_sensitive: false}
"""
data = {
'target_id': target_id,
'profile_id': self.profile_dict.get(profile_key),
}
if report_template_id:
data['report_template_id'] = self.report_template_dict.get(report_template_id)
if not schedule:
schedule = {
'disable': False,
'start_date': None,
'time_sensitive': False
}
data['schedule'] = schedule
try:
response = requests.post(self.scan_api, json=data, headers=self.auth_headers, verify=False)
# self.logger.error(data)
status_code = 200
except Exception:
#self.logger.error('Add Scan Failed......', exc_info=True)
status_code = 404
return status_code
def delete(self, scan_id):
scan_delete_api = f'{self.scan_api}/{scan_id}'
try:
response = requests.delete(scan_delete_api, headers=self.auth_headers, verify=False)
except Exception:
pass
#self.logger.error('Delete Scan Failed......', exc_info=True)
def get_all(self):
try:
response = requests.get(self.scan_api, headers=self.auth_headers, verify=False)
request_url = response.url
scan_response = response.json().get('scans')
scan_list = []
for scan in scan_response:
scan['request_url'] = request_url
scan_list.append(scan)
except Exception:
scan_list = []
#self.logger.error('Get All Scan Failed......\n【ERROR】Please start your AWVS server,Otherwise vulnerability scanning will be disabled!!!\n', exc_info=False) # awvs未启动时,报错信息关闭exc_info=False
return scan_list
def get(self, scan_id):
scan_get_api = f'{self.scan_api}/{scan_id}'
try:
response = requests.get(scan_get_api, headers=self.auth_headers, verify=False)
return response.json()
except Exception:
#self.logger.error('Get Scan Failed......', exc_info=True)
return None
def get_vulns(self, scan_id, scan_session_id):
scan_result_api = f'{self.scan_api}/{scan_id}/results/{scan_session_id}/vulnerabilities'
try:
response = requests.get(scan_result_api, headers=self.auth_headers, verify=False)
vuln_list = response.json().get('vulnerabilities')
return vuln_list
except Exception:
#self.logger.error('Get Scan Result Failed......', exc_info=True)
vuln_list = []
return None
def get_vuln_detail(self, scan_id, scan_session_id, vuln_id):
scan_vuln_detail_api = f'{self.scan_api}/{scan_id}/results/{scan_session_id}/vulnerabilities/{vuln_id}'
try:
response = requests.get(scan_vuln_detail_api, headers=self.auth_headers, verify=False)
vuln_detail = response.json()
return vuln_detail
except Exception:
#self.logger.error('Get Scan Result Failed......', exc_info=True)
return None
获取源码或论文
如需对应的论文或源码,以及其他定制需求,也可以下方微信联系我。


















 1652
1652

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









