






一、编写WordCount程序
使用IDEA软件,在项目的spark.demo包中新建一个WordCount.scala类中然后向其写入单词计数的程序。程序完整代码如下:
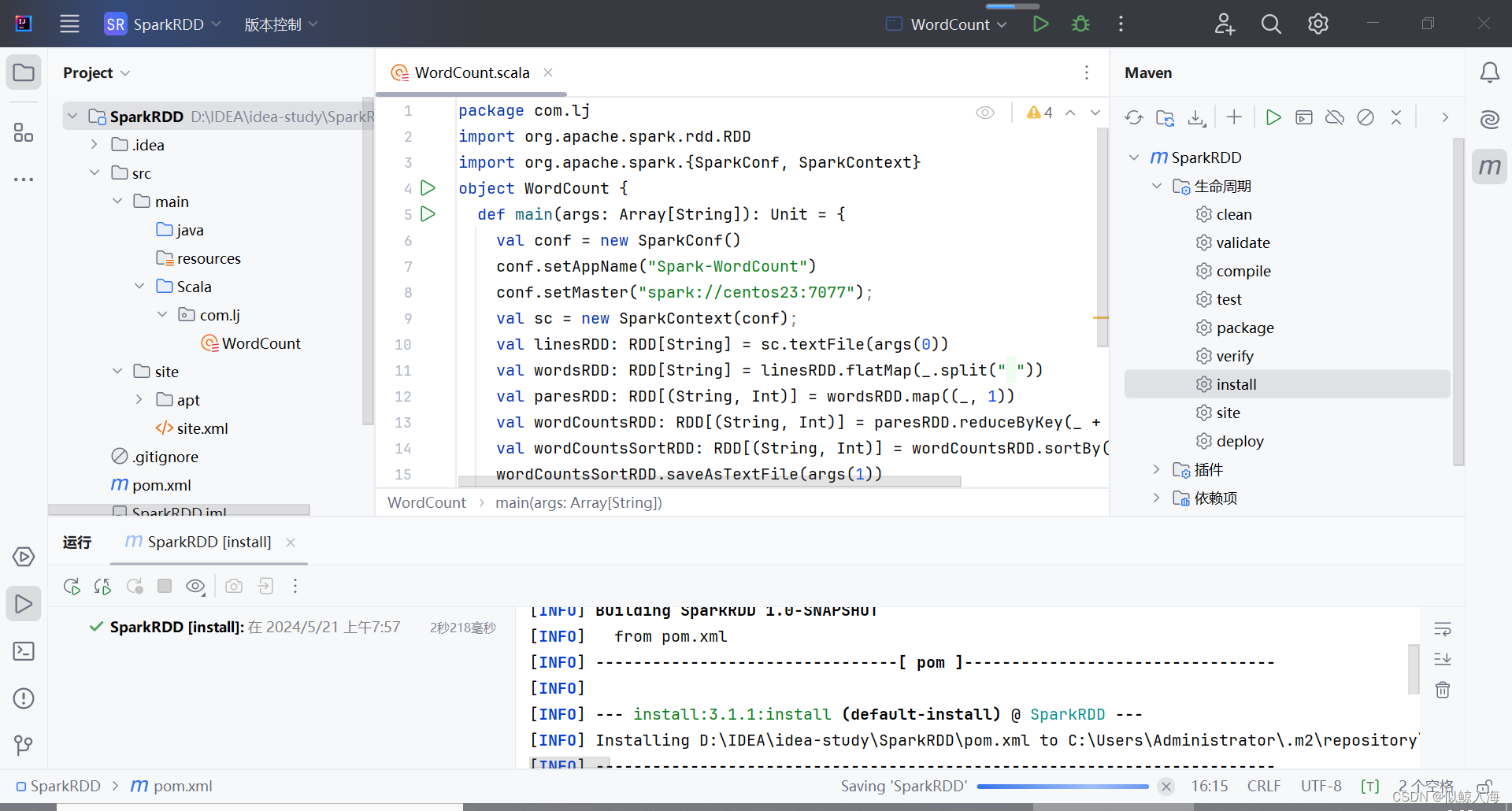
package spark.demo
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("Spark-WordCount")
conf.setMaster("spark://centos23:7077");
val sc = new SparkContext(conf);
val linesRDD: RDD[String] = sc.textFile(args(0))
val wordsRDD: RDD[String] = linesRDD.flatMap(_.split(" "))
val paresRDD: RDD[(String, Int)] = wordsRDD.map((_, 1))
val wordCountsRDD: RDD[(String, Int)] = paresRDD.reduceByKey(_ + _)
val wordCountsSortRDD: RDD[(String, Int)] = wordCountsRDD.sortBy(_._2, false)
wordCountsSortRDD.saveAsTextFile(args(1))
sc.stop();
}
}
二 、提交程序到集群
2.1打包并上传程序
展开IDEA右侧的Maven Projects窗口,双击install选项,将编写好的Spark项目进行编译和打包,
将打包好的SparkRDD.jar 上传到centos01节点的/opt/softwares目录下;
2.2启动spark集群
在centos01节点中进入spark安装目录,执行以下命令,启动spark集群:
sbin/start-all.sh2.3上传单词文件到HDFS
新建文件words.txt,并向其写入以下单词内容:
hello hadoop java
hello java
hello scala然后将文件上传到 HDFS 的/input 目录中,命令如下:
hdfs dfs put words.txt /input
2.4执行WordCount程序
在centos01节点中进入Spark安装目录,执行以下命令,提交WordCount应用程序到集群中运行:
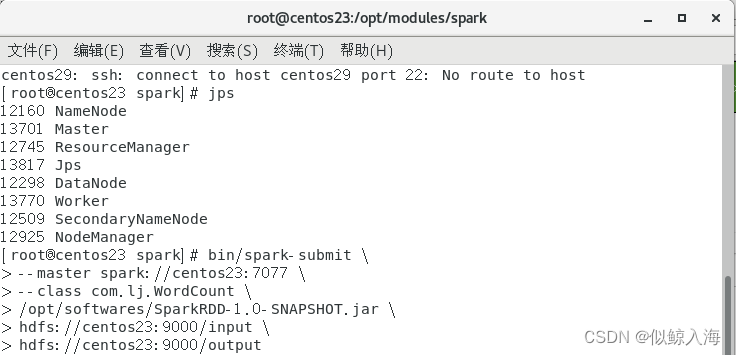
2.5查看执行结果
查看目录/output中的结果文件:

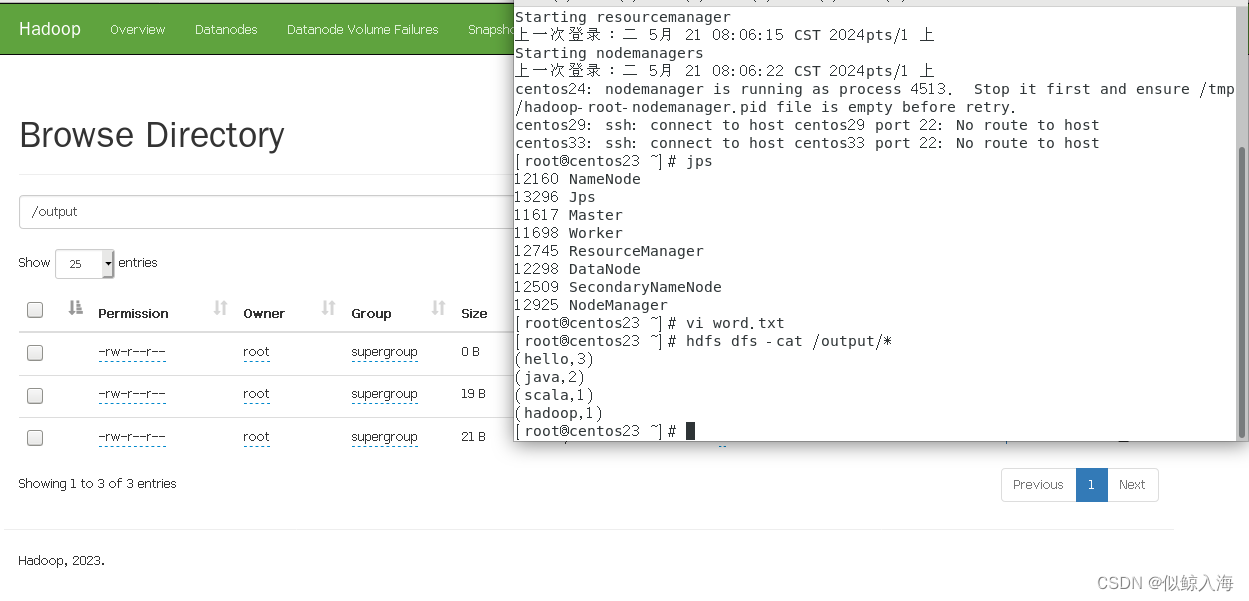















 218
218











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









