







 本文详细介绍了如何在Linux环境下搭建Hadoop HDFS的完全分布式集群,包括设置主机名、重启网络服务、配置SSH免密登录、安装与配置Hadoop、同步配置文件到所有节点、启动HDFS和YARN等关键步骤,旨在帮助读者理解并实践Hadoop集群部署。
本文详细介绍了如何在Linux环境下搭建Hadoop HDFS的完全分布式集群,包括设置主机名、重启网络服务、配置SSH免密登录、安装与配置Hadoop、同步配置文件到所有节点、启动HDFS和YARN等关键步骤,旨在帮助读者理解并实践Hadoop集群部署。
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。






既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上网络安全知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注网络安全)

正文
–2. 重启网络服务
[root@master ~]# systemctl restart network
或者
[root@master ~]# service network restart
–3. 修改主机名(如果修改过,请略过这一步)
[root@localhost ~]# hostnamectl set-hostname master
或者
[root@localhost ~]# vi /etc/hostname
master
注意:配置完ip和主机名后,最好reboot一下
4.4 配置/etc/hosts文件
[root@master ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.81.200 master <=添加本机的静态IP和本机的主机名之间的映射关系
4.5 免密登陆认证
-1. 使用rsa加密技术,生成公钥和私钥。一路回车即可
[root@master ~]# cd ~
[root@master ~]# ssh-keygen -t rsa
-2. 进入~/.ssh目录下,将id_rsa.pub复制一份文件,文件名为authorized_keys。保证此文件的权限是600
[root@master ~]# cd ~/.ssh
[root@master .ssh]# cp id_rsa.pub authorized_keys
或者使用ssh-copy-id命令
[root@master .ssh]# ssh-copy-id -i id_ras.pub root@master
-3. 进行验证
[hadoop@master .ssh]# ssh localhost
[hadoop@master .ssh]# ssh master
[hadoop@master .ssh]# ssh 0.0.0.0
#输入yes后,不提示输入密码就对了
注意:三台机器提前安装好的情况下,需要同步公钥文件。如果使用克隆技术。那么使用同一套密钥对就方便多了。
4.6 时间同步
可以参考Linux文档中的时间同步或者搭建局域网时间服务器。
4.7 安装Jdk和Hadoop,配置相关环境变量
-1. 上传和解压两个软件包
[root@master ~]# cd /opt/software/
[root@master software]# tar -zxvf jdk-8u221-linux-x64.tar.gz -C /opt/apps/
[root@master software]# tar -zxvf hadoop-2.7.6.tar.gz -C /opt/apps/
-2. 进入apps里,给两个软件更名
[root@master software]# cd /opt/apps/
[root@master apps]# mv jdk1.8.0_221/ jdk
[root@master apps]# mv hadoop-2.7.6/ hadoop
-3. 配置环境变量
[hadoop@master apps]# vi /etc/profile
…省略…
#java environment
export JAVA_HOME=/opt/apps/jdk
export PATH=
J
A
V
A
H
O
M
E
/
b
i
n
:
JAVA_HOME/bin:
JAVAHOME/bin:JAVA_HOME/jre/bin:KaTeX parse error: Expected 'EOF', got '#' at position 8: PATH #̲hadoop environm…HADOOP_HOME/bin:
H
A
D
O
O
P
H
O
M
E
/
s
b
i
n
:
HADOOP_HOME/sbin:
HADOOPHOME/sbin:PATH
#### **5 Hadoop的配置文件**
5.1 提取四个默认配置文件
第一步:将hadoop安装包解压到pc端的一个目录下,然后在hadoop-2.7.6目录下创建一个default目录,用于存储默认配置文件。 第二步:进入hadoop的share目录中的doc子目录,搜索default.xml。将以下四个默认的xml文件copy到default目录中,方便以后查看

5.2 $HADOOP\_HOME/etc/hadoop/目录下的用户自定义配置文件
- core-site.xml
- hdfs-site.xml
- mapred-site.xml 复制mapred-site.xml.template而来
- yarn-site.xml
5.3 属性的优先级
代码中的属性>xxx-site.xml>xxx-default.xml
#### **6 完全分布式文件配置(重点)**
配置前说明:我们先在master机器节点上配置hadoop的相关属性。
6.1 配置core-site.xml文件
[root@master ~]# cd $HADOOP_HOME/etc/hadoop/
[root@master hadoop]# vi core-site.xml
fs.defaultFS
hdfs://master:8020
hadoop.tmp.dir
/opt/apps/hadoop/tmp
>
> 参考:core-default.xml
>
6.2 再配置hdfs-site.xml文件
[root@master hadoop]# vi core-site.xml
dfs.namenode.name.dir
file://
h
a
d
o
o
p
.
t
m
p
.
d
i
r
/
d
f
s
/
n
a
m
e
<
/
v
a
l
u
e
>
<
/
p
r
o
p
e
r
t
y
>
<
!
−
−
确定
D
F
S
数据节点应该将其块存储在本地文件系统的何处
−
−
>
<
p
r
o
p
e
r
t
y
>
<
n
a
m
e
>
d
f
s
.
d
a
t
a
n
o
d
e
.
d
a
t
a
.
d
i
r
<
/
n
a
m
e
>
<
v
a
l
u
e
>
f
i
l
e
:
/
/
{hadoop.tmp.dir}/dfs/name</value> </property> <!-- 确定DFS数据节点应该将其块存储在本地文件系统的何处--> <property> <name>dfs.datanode.data.dir</name> <value>file://
hadoop.tmp.dir/dfs/name</value></property><!−−确定DFS数据节点应该将其块存储在本地文件系统的何处−−><property><name>dfs.datanode.data.dir</name><value>file://{hadoop.tmp.dir}/dfs/data
dfs.replication
3
dfs.blocksize
134217728
dfs.namenode.secondary.http-address
slave1:50090
>
> 参考:hdfs-default.xml
>
6.3 然后配置mapred-site.xml文件
如果只是搭建hdfs,只需要配置core-site.xml和hdfs-site.xml文件就可以了,但是我们过两天要学习的MapReduce是需要YARN资源管理器的,因此,在这里,我们提前配置一下相关文件。
[root@master hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@master hadoop]# vi mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
master:10020
mapreduce.jobhistory.webapp.address
master:19888
>
> 参考:mapred-default.xml
>
6.4 配置yarn-site.xml文件
[root@master hadoop]# vi yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
master
>
> 参考:yarn-default.xml
>
6.5 配置hadoop-env.sh脚本文件
[root@master hadoop]# vi hadoop-env.sh
…
The java implementation to use.
export JAVA_HOME=/opt/apps/jdk
…
6.6 配置slaves文件,此文件用于指定datanode守护进程所在的机器节点主机名
[root@master hadoop]# vi slaves
master
slave1
slave2
6.7 配置yarn-env.sh文件,此文件可以不配置,不过,最好还是修改一下yarn的jdk环境比较好
[root@master hadoop]# vi yarn-env.sh
…省略…
some Java parameters
export JAVA_HOME=/opt/apps/jdk
…省略…
#### **7 另外两台机器配置说明**
当把master机器上的hadoop的相关文件配置完毕后,我们有以下两种方式来选择配置另外几台机器的hadoop.
**方法1:**“scp”进行同步
提示:本方法适用于多台虚拟机已经提前搭建出来的场景。
–1. 同步hadoop到slave节点上
[root@master ~]# cd /opt/apps
[root@master apps]# scp -r ./hadoop slave1:/opt/apps/
[root@master apps]# scp -r ./hadoop slave2:/opt/apps/
–2. 同步/etc/profile到slave节点上
[root@master apps]# scp /etc/profile slave1:/etc/
[root@master apps]# scp /etc/profile slave2:/etc/
–3. 如果slave节点上的jdk也没有安装,别忘记同步jdk。
–4. 检查是否同步了/etc/hosts文件
**方法2:**克隆master虚拟机
提示:本方法适用于还没有安装slave虚拟机的场景。通过克隆master节点的方式,来克隆一个slave1和slave2机器节点,这种方式就不用重复安装环境和配置文件了,效率非常高,节省了大部分时间(免密认证的秘钥对都是相同的一套)。
–1. 打开一个新克隆出来的虚拟机,修改主机名
[root@master ~]# hostnamectl set-hostname slave1
–2. 修改ip地址
[root@master ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33
…省略…
IPADDR=192.168.10.201 <==修改为slave1对应的ip地址
…省略…
–3. 重启网络服务
[root@master ~]# systemctl restart network
–4. 其他新克隆的虚拟机重复以上1~3步
–5. 免密登陆的验证
从master机器上,连接其他的每一个节点,验证免密是否好使,同时去掉第一次的询问步骤
–6. 建议:每台机器在重启网络服务后,最好reboot一下。
#### **8 格式化NameNode**
**1)**在master机器上运行命令
[root@master ~]# hdfs namenode -format
**注意,注意,注意:** 如果你是从伪分布式过来的,最好先把伪分布式的相关守护进程关闭:stop-all.sh
**2)**格式化的相关信息解读
–1. 生成一个集群唯一标识符:clusterid
–2. 生成一个块池唯一标识符:BlockPoolId
–3. 生成namenode进程管理内容(fsimage)的存储路径:
默认配置文件属性hadoop.tmp.dir指定的路径下生成dfs/name目录
–4. 生成镜像文件fsimage,记录分布式文件系统根路径的元数据
–5. 其他信息都可以查看一下,比如块的副本数,集群的fsOwner等。
参考图片:

**3)**目录里的内容查看
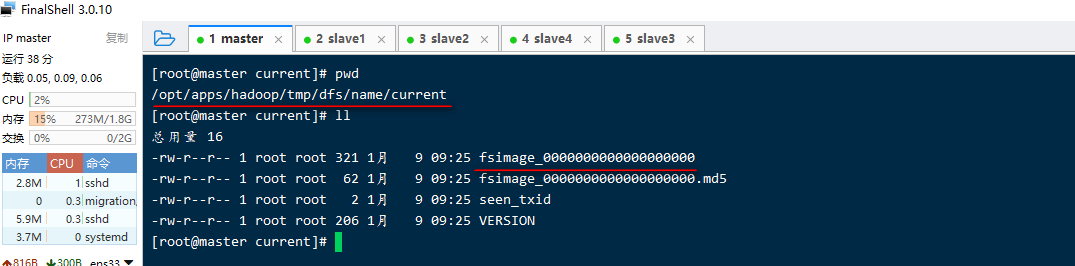
#### **9 启动集群**
**9.1** 启动脚本和关闭脚本介绍
-
启动脚本
– start-dfs.sh :用于启动hdfs集群的脚本
– start-yarn.sh :用于启动yarn守护进程
– start-all.sh :用于启动hdfs和yarn -
关闭脚本
– stop-dfs.sh :用于关闭hdfs集群的脚本
– stop-yarn.sh :用于关闭yarn守护进程
– stop-all.sh :用于关闭hdfs和yarn -
单个守护进程脚本
– hadoop-daemons.sh :用于单独启动或关闭hdfs的某一个守护进程的脚本
– hadoop-daemon.sh :用于单独启动或关闭hdfs的某一个守护进程的脚本
reg:
hadoop-daemon.sh [start|stop] [namenode|datanode|secondarynamenode]– yarn-daemons.sh :用于单独启动或关闭hdfs的某一个守护进程的脚本
– yarn-daemon.sh :用于单独启动或关闭hdfs的某一个守护进程的脚本
reg:
yarn-daemon.sh [start|stop] [resourcemanager|nodemanager]
**9.2** 启动hdfs
**1)**使用start-dfs.sh,启动 hdfs。参考图片
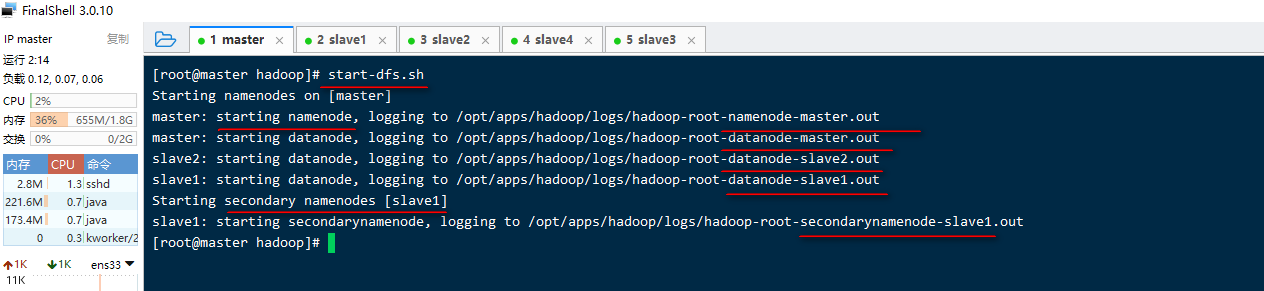
**2)**启动过程解析:
- 启动集群中的各个机器节点上的分布式文件系统的守护进程
一个namenode和resourcemanager以及secondarynamenode
多个datanode和nodemanager - 在namenode守护进程管理内容的目录下生成edit日志文件
- 在每个datanode所在节点下生成${hadoop.tmp.dir}/dfs/data目录,参考下图:
### 给大家的福利
**零基础入门**
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

同时每个成长路线对应的板块都有配套的视频提供:

因篇幅有限,仅展示部分资料
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注网络安全)**

**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
g-blog.csdnimg.cn/img_convert/95608e9062782d28f4f04f821405d99a.png)
同时每个成长路线对应的板块都有配套的视频提供:

因篇幅有限,仅展示部分资料
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注网络安全)**
[外链图片转存中...(img-xwpy96XY-1713329469762)]
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 988
988

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









