







最全的Linux教程,Linux从入门到精通
======================
-
linux从入门到精通(第2版)
-
Linux系统移植
-
Linux驱动开发入门与实战
-
LINUX 系统移植 第2版
-
Linux开源网络全栈详解 从DPDK到OpenFlow

第一份《Linux从入门到精通》466页
====================
内容简介
====
本书是获得了很多读者好评的Linux经典畅销书**《Linux从入门到精通》的第2版**。本书第1版出版后曾经多次印刷,并被51CTO读书频道评为“最受读者喜爱的原创IT技术图书奖”。本书第﹖版以最新的Ubuntu 12.04为版本,循序渐进地向读者介绍了Linux 的基础应用、系统管理、网络应用、娱乐和办公、程序开发、服务器配置、系统安全等。本书附带1张光盘,内容为本书配套多媒体教学视频。另外,本书还为读者提供了大量的Linux学习资料和Ubuntu安装镜像文件,供读者免费下载。

本书适合广大Linux初中级用户、开源软件爱好者和大专院校的学生阅读,同时也非常适合准备从事Linux平台开发的各类人员。
需要《Linux入门到精通》、《linux系统移植》、《Linux驱动开发入门实战》、《Linux开源网络全栈》电子书籍及教程的工程师朋友们劳烦您转发+评论
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
- 分配方式
栈:由编译器自动分配和释放,一般存放函数的参数、局部变量、临时变量、函数返回地址等
堆:堆内存是由程序员进行分配和释放的,也称为动态内存分配。如果没有手动free,在程序结束时有可能由操作系统自动释放(但是仅限于有回收机制的语言, 像C/C++就必须进行手动释放,不然就有可能造成内存泄漏) - 生命周期
栈:由于栈上的空间是自动分配自动回收的,所以栈上数据的生命周期只是在函数的运行过程中存在,运行后就释放掉了
堆:堆上的数据,只要程序员不释放空间,就可以一直访问到。 - 空间申请效率
栈:由系统自动分配,效率比较高
堆:比较慢 - 分配方向
栈:用户进程的用户栈从3GB虚拟空间的顶部开始,由顶向下延伸
堆:分配的空间从数据段的顶部end_data到用户栈的底部。由下往上,每分配一块空间,就把边界往上推进一段。
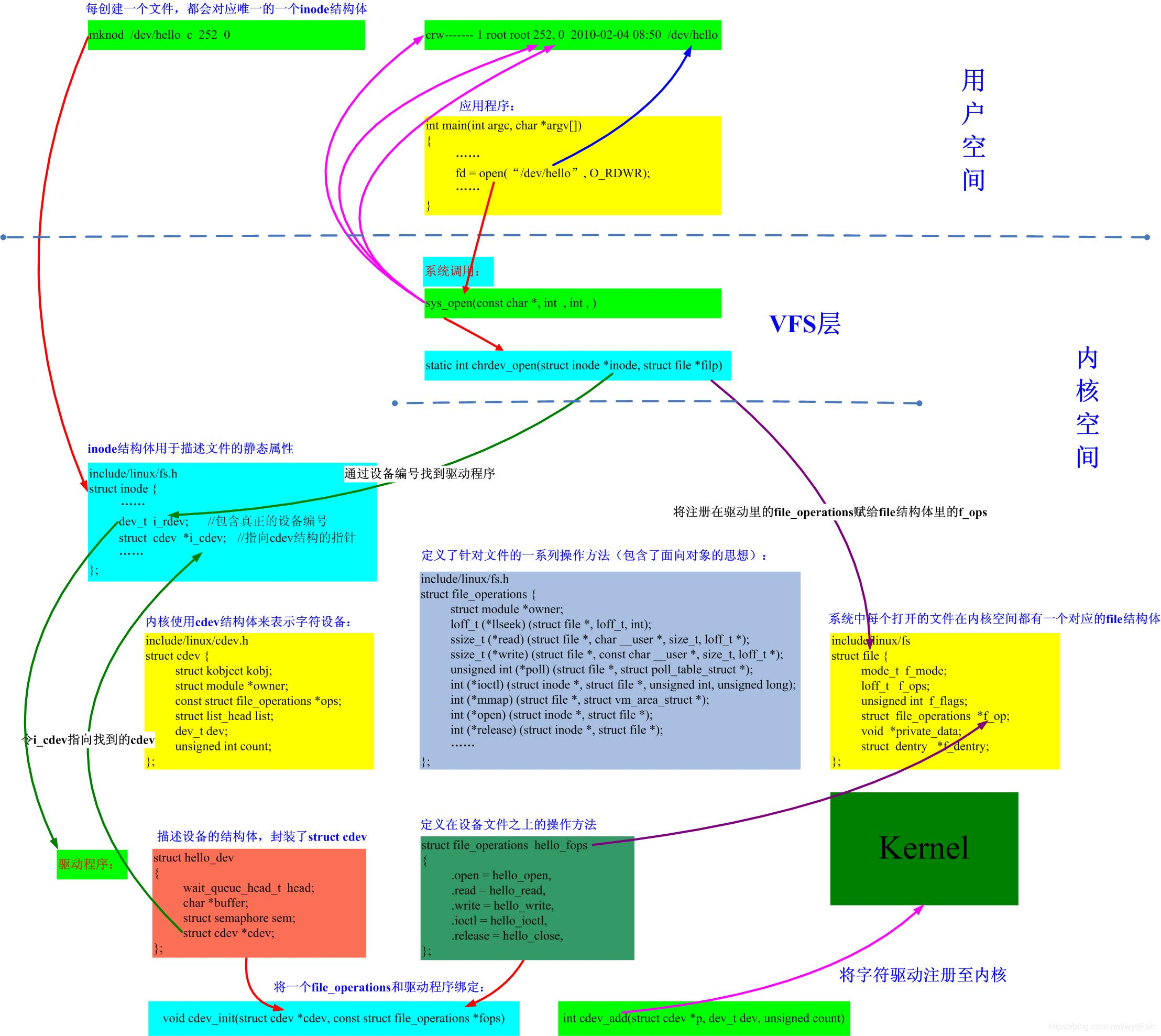
2、用户层open、read等函数如何调用到对应的驱动ops函数?
3、i2c、uart、spi协议
i2c:
物理连接:由SDA、SCL和上拉电阻组成。当总线空闲时,SDA和SCL两根线一般会被上拉电阻拉高,保持高电平
传输速度: I2C总线数据传输速率在标准模式下可以达到100kbit/s,快速模式下可以达到400kbit/s。一般I2C总线接口可通过编程时钟来实现传输速率的调整,同时也跟所接的上拉电阻的阻值有关
通信协议:I2C协议规定,必须以一个起始信号作为开始条件,以一个结束信号作为传输的停止条件(总线在空闲状态,SDA和SCL都是高电平,当SCL为高电平,SDA由高变低的时候,则会产生一个起始条件;当SCL为高电平,SDA由低到高时,则会产生一个停止条件);I2C总线上的每一个设备都对应一个唯一的地址,主从设备之间的数据传输是建立在地址的基础上的,也就是说,主设备在传输有效数据之前 要先指定从设备的地址,地址指定的过程和上面数据传输的过程一样,只不过大多数从设备的地址是7位的,然后协议规定再给地址添加一个最低位用来表示接下来 数据传输的方向,0表示主设备向从设备写数据,1表示主设备向从设备读数据
uart:
物理连接:由一根TX线、一根RX线和一根地线组成
传输速度:传输速度可以由通信双方共同定的波特率来决定
通信协议:UART作为异步串口通信协议的一种,工作原理是将数据的字节一位接一位地传输。默认情况下,UART处于空闲状态,此时信号线为高电平;在开始进行数据传输的时候,发送方要先发送一个低电平,代表起始位;起始位后就是传输的数据位;数据位发送完成后,一般还要一个奇偶校验;最后是停止位,可以是1位、1.5位、2位的高电平。
spi:看这
他们之间更详细的区别介绍,看这
4、说一下volitate和static
https://blog.csdn.net/wyttRain/article/details/117487288
二、Linux内存管理
1、什么是MMU?MMU实现了什么功能?
答: MMU的中文全称为内存管理单元,主要实现的功能是将虚拟地址转换为物理地址。MMU的工作就是一个查询页表的过程,如果页表信息直接存储在内存中,那么查询起来非常费时,所以一般将页表信息存放在MMU上的一小块访问更快的区域,也就是TLB中,用于提高查找效率。
2、简述一下现代处理器(如ARM)寻址的过程
答: 现代处理器,由于引入了分页机制,处理器可以直接寻址虚拟地址,这个虚拟地址会发送到内存管理单元(MMU),通过MMU将虚拟地址转换到物理地址。虚拟地址va[31:0]一般分成两部分,一部分代表的是虚拟页面的偏移量,另一部分用来寻找属于哪个页,被称为虚拟页帧号(Virtual Page Frame Number,VPN)。物理地址也同样分为偏移量和物理页帧号(Physical Frame Number,PFN)。处理器通常会使用一张表来存储VPN到PFN的映射关系,这张表称为页表(Page Table,PT),页表中的每一项被称为页表项(Page Table Entry,PTE)(页表项分成两个部分:一部分是PFN,PFN加上页面偏移量就可以得到最终的物理地址PA,另一部分是页表项的属性。)。如果将这张表放到处理器的寄存器中,则会占用很多硬件资源,因此通常的做法是将这张表存放到主存里,然后通过页表基地址寄存器来指向这张页表的起始地址。
实际上的系统中,包含了多级的页表,比如对于ARM64的处理器来说,一般有4级页表。拿二级页表来举个例子,页表基地址寄存器指向的是一级页表的基地址,一级页表的页表项(PTE)中存放了一个指针,指向了二级页表的基地址。
当TLB未命中时,处理器的MMU页表查询的过程如下:
- 处理器根据页表基地址控制寄存器(TTBCR)和虚拟地址来判断使用哪个页表基地址寄存器(TTBR0或者TTBR1)。页表基地址寄存器中存放着一级页表的基地址;
- 处理器根据虚拟地址的Bit[31:20]作为所有制,在一级页表中找到页表项;
- 一级页表的页表项中存放着二级页表的物理基地址。处理器使用虚拟地址的Bit[19:12]作为所有制,在二级页表中找到相应的页表项
- 二级页表的页表项中存放了4KB页的物理基地址。这样,处理器就完成了页表的查询和翻译工作。
2、什么是DMA?为什么需要DMA?DMA的数据传输流程是怎么样的?DMA有什么弊端?
答: DMA的中文全称是直接访问存储器,可以让存储器和外部设备直接进行数据交换。 DMA在进行数据传输的过程中,其实是不需要CPU参与的,也就是说,当DMA在进行数据传输工作的时候,CPU也可以同步进行其他工作,大大提高了处理器的工作效率。DMA主要用于需要高速、大批量数据传送的系统中,目的是提高数据的吞吐量,如磁盘存取、图像处理、高速数据采集系统方面应用甚广。通常只有数据量较大的外设才需要支持DMA能力,比如视频、音频和网络接口。
DMA的工作过程是由一个DMA控制器来进行控制的。由DMA控制器来接收外设的DMA请求,然后发送一个总线请求信号给CPU,当CPU接收到总线请求信号后,会在总线状态处于空闲时,反馈一个信号给DMA控制器,DMA控制器会获得总线的控制权,然后反馈一个DMA应答信号给外部设备,表示当前允许进行DMA数据传输。
因为在进行DMA数据传输的时候,DMA控制器需要获得总线的控制权,这可能会影响CPU会中断请求的及时响应和处理。因此,在一些系统或速度要求不高,数据传输量不大的系统中,一般并不用DMA方式。
想进一步了解DMA的可以看此链接
3、什么是cache?为什么需要cache?请简述一下cache的工作方式
答: cache是一块介于CPU和主存之间的高速缓冲存储器。cache的作用是加快处理器获取数据的速度,可以有效地提高CPU的效率。当主控发起对某个地址(这个地址是虚拟地址)的访问请求时,会将这个地址同时发送给MMU和cache,虚拟地址会在MMU中的TLB结构中查找,如果TLB命中,那么可以直接返回一个物理地址。如果TLB Miss,那么需要进一步访问MMU并查询页表,如果还是没有找到页表,那么就会触发一个缺页异常中断。同时,处理器通过高速缓存编码地址的索引域(Index)可以很快找到相应的高速缓存行对应的组。但是这里的高速缓存行的数据不一定是处理器所需要的,因此有必要进行一些检查,将高速缓存行中存放的标记域和通过虚实地址转换得到的物理地址的标记域进行比较。如果相同并且状态位匹配,那么就会发生高速缓存命中(cache hit),处理器经过字节选择与对齐(byte select and align)部件,最终就可以获取所需要的数据。如果发生高速缓存 未命中(cache miss),处理器需要用物理地址进一步访问主存储器来获得最终数据,数据也会填充到相应的高速缓存行中。上述描述的是VIPT(Virtual Index Physical Tag)的高速缓存组织方式。这个也是经典的cache运行模式了。
4、cache有哪几种映射方式?它们各自的优点和缺点是什么?
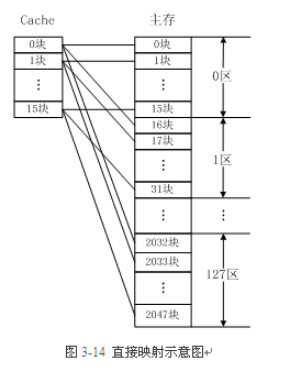
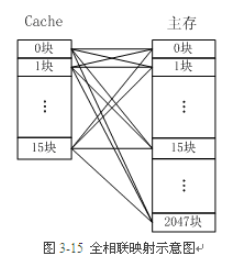
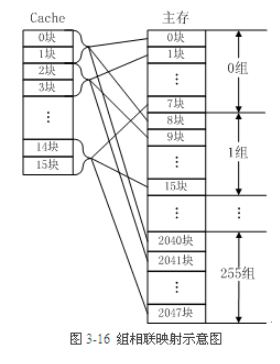
这里的映射指的是cache和主存之间的映射关系。常见的cache映射方式有三种:直接映射、全关联和组相连
直接映射:也就是cache和主存是一一对应的关系。但是,cache的大小是比主存要小得多的,也就是直接映射的话cache只能映射到主存的一小部分,如果处理器想要访问主存的地址A,而cache正好映射在主存地址A的这个区域,那自然好,但是如果处理器想要访问主存的地址B,而cache并没有映射到主存的这个区域,那么就会发生cache miss,那么cache就需要重新映射新的地址,如果处理器频繁地访问主存不同的地址数据,那么cache需要一直不断地重写,这样就会发生cache的颠簸,非常影响处理器效率。全关联:全相联映射方式比较灵活,主存的各块可以映射到Cache的任一块中,Cache的利用率高,块冲突概率低,只要淘汰Cache中的某一块,即可调入主存的任一块。但是,由于Cache比较电路的设计和实现比较困难,这种方式只适合于小容量Cache采用。组相连:组相连是现在最常见的一种cache映射方式,是直接映射和全关联的折中方法。也就是将一块内存分成了很多组,然后cache也分成了很多组,每组cache中都有多个cache line,例如,主存中的第0块、第8块……均映射于Cache的第0组,但可映射到Cache第0组中的第0块或第1块;主存的第1块、第9块……均映射于Cache的第1组,但可映射到Cache第1组中的第2块或第3块。这样就可以减少cache颠簸的概率。
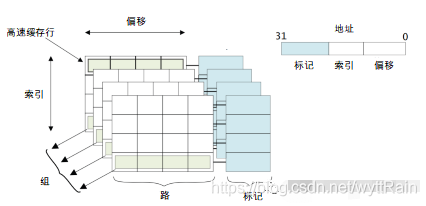
5、cache的cache line、way和set分别指的都是什么?你能画出它们的结构图吗?
以一个32KB的4路组相连的cache中,其中cache line为32 Byte为例。
什么路(way),set(组)都非常难理解,我们换个通俗点的说法。cache是一个高速缓冲存储块,按照上面描述的,这个存储块有32KB,然后还分4路,也就是这个cache总大小是32块,然后还分成4小块,也就是一小块是32/4=8KB,然后后面又说,每个cache line是32Byte,那么一小块里面就有8KB/32Byte=256个cache line,然后每一个小块的相同位置的cache line,就称为一个组。
6、在多核处理器中,cache的一致性是如何保证的?
cache的一致性是通过一个叫做MESI的机制来保证的。
想要进一步了解cache可以看这个链接
7、malloc的实现机制
答: malloc本质上是在维护一条内存空闲链表,每次我们调用mallo分配内存空间时,链表就会从头开始遍历,来寻找一个合适的空闲内存空间,然后把这个空间发分隔开,一部分分配给用户,另一部分标注为空闲。而当没有足够大的内存块时,malloc就会通过系统调用来申请更多的内存块。当我们调用free释放内存块后,该内存块会回到链表中,并且相邻的内存块会合并成一个大内存块。
kmalloc、vmalloc和malloc有什么区别和实现上的差异?
- kmalloc和vmalloc是分配的是内核的内存,malloc分配的是用户的内存
- kmalloc保证分配的内存在物理上是连续的,vmalloc保证的是在虚拟地址空间上的连续
- kmalloc能分配的大小有限,vmalloc和malloc能分配的大小相对较大
- 内存只有在要被DMA访问的时候才需要物理上连续
- vmalloc比kmalloc要慢
- kmalloc是基于slab机制来分配内存的
8、下面程序会有怎样的输出呢?
int cnt = 0;
while(1) {
++cnt;
ptr = (char \*)malloc(1024\*1024\*128);
if (ptr == NULL) {
printf("%s\n", "is null");
break;
}
}
printf("%d\n", cnt);
在Linux32位机上输出的结果应该是:
is null
3057
为什么是3057?
因为用户态虚拟内存地址空间是3G,3057大概就是3G。
可见malloc时是在虚拟地址空间申请的,由于代码里并没有对申请的地址进行访问,所以实际上是不会分配物理内存的,直到对地址进行访问,由于缺页中断才开始处理页表映射,然后分配物理内存。
那如果有对地址进行访问,能够分到多少内存呢?
这就取决于Linux的内核参数和目前剩余的内存了!!!!
请描述一下mmap函数的使用
#include <sys/mman.h>
void \*mmap(void \*addr, size\_t length, int prot, int flags, int fd, off\_t offset);
int munmap(void \*addr, size\_t length);
addr:用于指定映射到进程地址空间的起始地址,为了应用程序的可以执行,一般都设置为NULL,让内核来选择一个合适的地址。length:表示映射到进程地址空间的大小prot:用于设置内存映射区域的读写属性等flags:用于设置内存映射的属性,例如共享映射、私有映射等fd:表示这是一个文件映射offset:在文件映射时,表示文件的偏移量
私有映射和共享映射有什么区别?
答: 如果是共享映射,那么在内存中对文件进行修改,磁盘中对应的文件也会被修改,相反,磁盘中的文件有了修改,内存中的文件也被修改。如果是私有映射,那么内存中的文件是独立的,二者进行修改都不会对对方造成影响。通过这样的内存共享映射就相当于是进程直接对磁盘中的文件进行读写操作一样,那么如果有两个进程来mmap同一个文件,就实现了进程间的通信。
在一个播放系统中同时打开几十个不同的高清视频文件,发现播放有些卡顿,打开视频文件是用mmap函数,请简单分析原因
答: 使用mmap来创建文件映射时,由于只建立了进程地址空间VMA,并没有马上分配page cache和建立映射关系。因此当播放器真正读取文件时,产生了缺页中断才去读取文件内容到page cache中。这样每次播放器真正读取文件时,会频繁地发生缺页中断,然后从文件中读取磁盘内容到page cache中,导致磁盘读性能比较差,从而造成播放视频的卡顿。对于这个问题,能够有效提高流,媒体服务I/O性能的方法是增大内核的默认预读窗口, 可以通过“blockdev --setra”命令来修改。
9、Linux是如何避免内存碎片的?
答: 使用伙伴系统算法来避免外部碎片,用slab算法来避免内部碎片
- 内部碎片:内部碎片就是已经被分配出去的,能明确指出属于哪个进程,缺不能被利用的内存空间(
这个内存块被某一个进程占有,但是这个进程却不用它,然后别的进程也用不了它,这个内存块就被称为内部碎片) - 外部碎片:外部碎片是指还没被分配出去,但是由于内存块太小了,无法分配给申请内存的进程。
10、伙伴系统算法是怎么实现的?它和slab算法有什么区别?
答: 伙伴系统中包含了多条内存链表,每条链表中的包含了多个内存大小相等的内存块(比如4KB链表,代表这台链表中所有的内存块大小都是4KB),比如我们想要分配一个8KB大小的内存,但是发现对应大小的链表上已经没有空闲内存块, 那么伙伴系统就会从16KB的链表中找到一个空闲内存块,然后分成两个8KB的大小,把其中一个返回给申请者使用,另一块放到8KB对应的链表中进行管理。到这里可能有童靴会有疑问:如果我只需要1KB甚至更小的内存,而伙伴系统链表中只有32KB的链表有空闲块了,那岂不是要切很久?
对于进程描述符这些对象大小比较小的,如果直接采用伙伴系统进行分配和释放,不仅会造成大量的内存碎片,并且在处理速度上也会比较慢,slab机制的工作就是针对一些 经常分配并释放的对象,它是基于对象进行管理的,相同类型的对象归为一类 , 每次要申请这样一个对象,slab分配器就从一个slab列表中分配一个这样的大小出去,而当要释放时,将其重新保存到该列表中,而不是直接返回给伙伴系统 。注意:slab分配器最终还是由伙伴系统来分配物理页面的
Linux内核使用伙伴系统管理内存,那么在伙伴系统工作前,如何管理内存?
答: memblock,memblock在系统启动阶段进行简单的内存管理,记录物理内存的使用情况
在系统启动的时候,Linux内核如何知道内存多大?
答: 在对应的平台DTS文件中都会配置memory的节点,描述内存信息,在系统启动的时候,会去解析DTS中配置的memory节点,从而获得内存信息。
memory {
device_type = "memory";
reg = <0 0x40000000 0 0x20000000>;
};
物理内存是如何添加到伙伴系统中的?
答:
内核空间的页表存放在什么地方?
页表是如何映射的?
zone
1、系统在启动过程中,解析DTS中的memory节点,获取物理内存信息,并添加到memblock子系统中
2、对页表进行初始化
3、页表初始化完成后,Linux内核就可以开始对物理内存进行管理
4、Linux内核是通过zone来对物理内存进行管理,在Linux内核中,将物理内存分成几个zone来进行管理
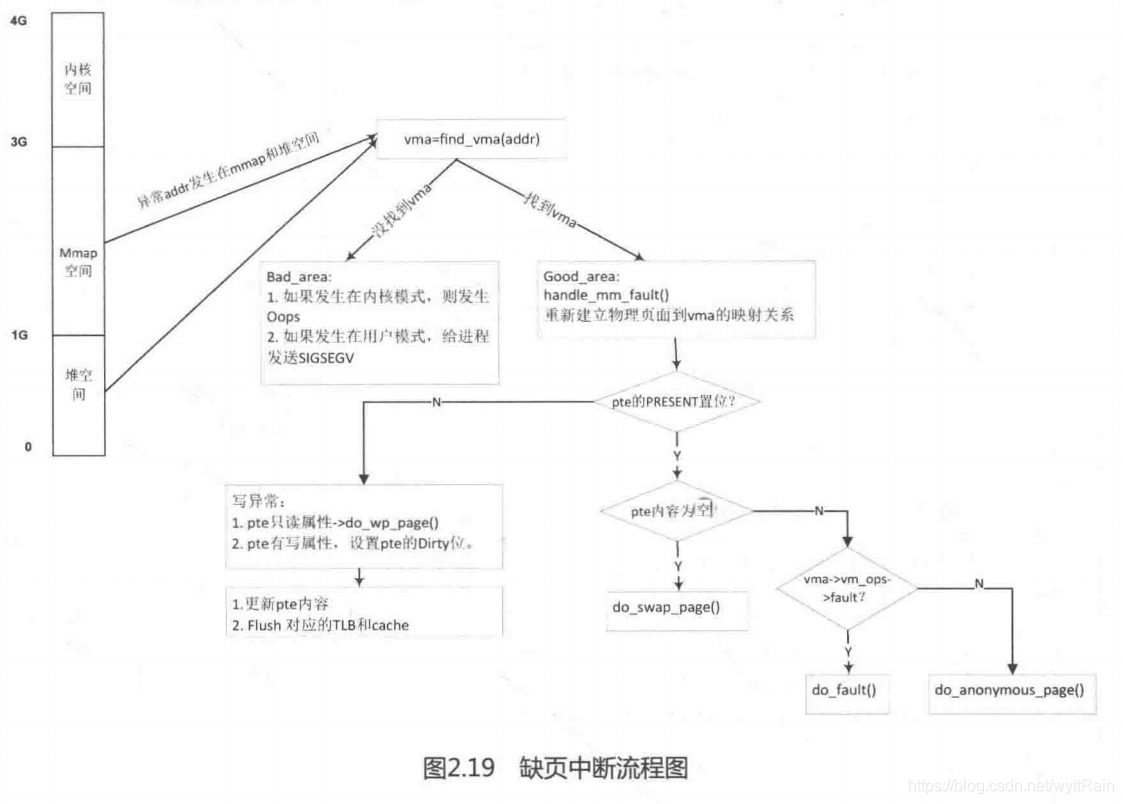
11、什么是缺页中断?发生缺页中断后的处理流程是怎么样的?
我们知道用户空间存在虚拟内存,而用户进程访问虚拟内存的时候,正常情况下,虚拟内存和物理内存需要建立映射关系,用户才可以进一步去访问对应的物理内存,而当进程去访问那些还没有建立映射关系的虚拟内存时,CPU就会触发一个缺页中断异常。
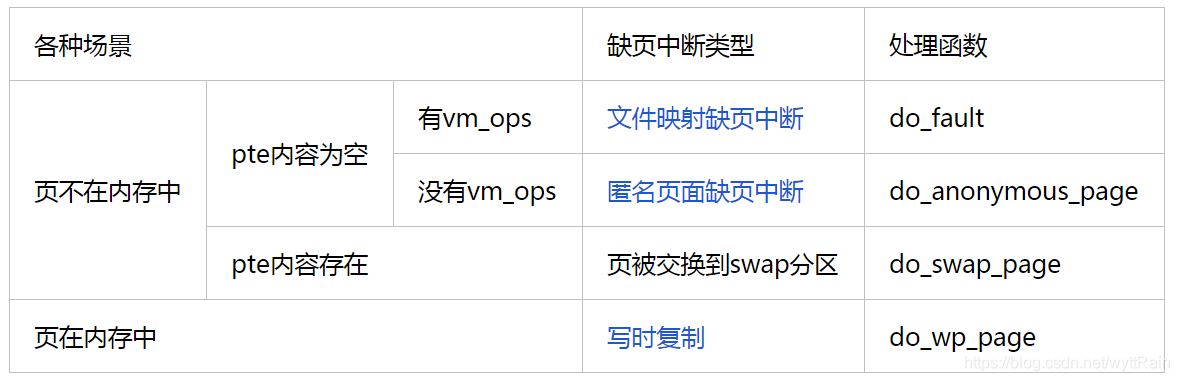
缺页中断有哪几种类型?
12、如果在中断处理函数中出现了缺页中断,会发生什么?
13、Linux内存管理中的分配掩码有什么作用?有哪几个类型?
分配掩码(gfp_mask)是一个决定内存分配动作的参数,主要分成下面五类:
内存管理区修饰符:主要决定需要从哪个内存管理区中分配内存,存管理区修饰符使用gfp_mask的最低4个比特位来表示移动修饰符:用来指示分配出来的页面具有的移动属性水位修饰符:用来控制是否可以使用系统紧急预留的内存

页面回收描述符行动修饰符
关于gfp_mask更加详细的介绍可以看这个链接
三、Linux中断机制
想进一步整体了解学习Linux中断机制的朋友可以看这个链接
ARM处理器中,检测外部硬件中断的任务是由ARM中的中断控制器来检测的。而如果要进一步细分,中断控制器一般分为两个部分,一个是仲裁单元,另一个是CPU Interface模块,所以第一句话可以进一步完善:ARM处理器中,检测外部硬件中断的任务是由ARM中的中断控制器中的仲裁单元来检测的,由中断控制器中的CPU Interface模块来将中断分配给某一个CPU。
1、当发生一个外设中断时,ARM处理器的处理步骤是怎么样的(不涉及下半部的操作)?
当发生一个外设中断后
a:一个中断M产生,发生了电平变化,被中断控制器中的仲裁单元检测到了(仲裁单元检测中断信号)b:然后仲裁单元会把这个中断M的状态设置为pending(等待状态)(仲裁单元将中断信号设置为pending状态)c:然后过了一段时间后,中断控制器中的CPU Interface模块会把nFIQCPU[n]信号拉低,目的是向CPU报告中断请求,然后将中断M的硬件中断号存放到GICC_IAR寄存器中(CPU Interface向CPU报告中断请求)d:如果这个时候有一个更高优先级的中断N来了,由于中断控制器支持优先级抢占功能,所以这个时候N会变成当前CPU所有pending状态下优先级最高的中断(意味着它会被优先分配)。(发生中断抢占)e:然后跟步骤c一样,过了一段时间后,CPU Interface模块会再次去把nFIQCPU[n]信号拉低,由于这个时候nFIQCPU[n]已经是低电平了,所以只需要更新GICC_IAR寄存器的值为中断N的硬件中断号(设置新的优先级较高的中断信号)f:然后CPU就会去读取GICC_IAR寄存器,把寄存器中的硬件中断号读出来,也就相当于是响应中断了。这个时候仲裁单元就会把中断N的状态从pending变成了activce and pending。(响应中断信号)g:然后后面就是Linux内核处理中断N的中断服务程序了(处理中断)h:在Linux中断处理中断N的过程中,CPU Interface模块会重新拉高nFIQCPU[n]信号,当中断N处理完成后,会将N的硬件中断号写入到GICC_EOIR寄存器中,表示完成中断N的全部处理过程。i:然后中断控制器的仲裁单元,会重新选择该CPU下pending状态的中断中优先级最高的一个,发送该中断请求给CPU Interface模块,继续前面的流程。
2、中断发生后的硬件处理和软件处理
硬件处理: CPU核心在感知到中断发生后,硬件会自动做如下一些事情
- 保存中断发生时CPSR寄存器的内容到SPSR_irq寄存器中
- 修改CPSR寄存器,让CPU进入处理器模式中的IRQ模式
- 硬件自动关闭中断
- 保存返回地址到LR_irq中
- 硬件自动跳转到中断向量表的IRQ向量中
软件处理:软件需要做的事情从中断向量表开始
3、何为中断上下文?为什么中断上下文中不能调用含有睡眠的函数?
当CPU响应一个中断并正在执行中断服务程序,那么内核处于中断上下文中。
当ARM处理器响应中断时,ARM处理器会自动保存终端店的CPSR寄存器和LR寄存器内容,并关闭本地中断,进入IRQ模式。
但在Linux内核中,ARM IRQ模式很短暂(中断上半部执行非常快),很快就退出IRQ模式进入SVC模式,并且把IRQ模式的栈内容负责到SVC模式的栈中,保存中断现场,也就是说中断上下文运行在SVC模式下。 既然中断上下文运行在SVC模式下,并且中断现场已经保存在中断打断的进程的内核栈中,为什么中断上下文不能睡眠呢?
假使现在CPU正在执行一个进程A,这个时候发生了中断,那么中断处理函数会用进程A的内核栈来保存中断上下文。睡眠是什么概念呢?也就是需要调用schedule()函数让当前的进程让出CPU,选择另一个进程继续执行。如果这个时候再发生睡眠或者中断,那么会将中断上下文覆盖了原本进程A的内核栈,当后面这个中断返回的时候,找不到最开始的那个中断的上下文,就再也回不去上一次的中断处理函数中了。
4、硬件中断号和Linux内核的IRQ号是如何映射的?
5、发生硬件中断后,Linux内核是如何响应并处理中断的?
6、介绍一下Linux内核中的中断注册函数
在Linux内核中,注册中断的函数有:request_irq和request_threaded_irq,这两个函数调用的其实都是request_threaded_irq,只是request_irq函数的第三个参数传的是NULL(request_threaded_irq(irq, handler, NULL, flags, name, dev))
为什么有了request_irq,还要一个request_threaded_irq? 我们都知道,当一个中断发生后,需要等待中断处理完成后才会返回到起初的状态继续执行,这样会造成那些对于实时性要求比较高的任务得不到及时的处理,所以引入了中断线程化,目的就是将一些工作任务比较繁重的中断处理函数设置成线程看看待,让实时进程能够得到及时的处理。
7、简述一下你对中断上下半部的理解?
答: 我们用一个例子来更好理解中断和中断上下部这两个概念。
什么是中断? 比如你现在肚子饿了,然后叫了个外卖,叫完外卖后你肯定不会傻傻坐在那里等电话响,而是会去干其他事情,比如看电视、看书等等,然后等外卖小哥打电话来,你再接听了电话后才会停止看电视或者看书,进而去拿外卖,这就是一个中断过程。你就相当于CPU,而外卖小哥的电话就相当于一个硬件中断。
什么是中断上下部? 继续参考上面的例子,比如你现在叫的是两份外卖,一份披萨一份奶茶,由两个不同的外卖小哥配送,当第一个送披萨的外卖小哥打电话来的时候(硬件中断来了),你接起电话,跟他聊起了恋爱心得,越聊越欢,但是在你跟披萨小哥煲电话粥的时候,奶茶外卖小哥打电话来了,发现怎么打也打不进来,干脆就把你的奶茶喝了,这样你就痛失了一杯奶茶,这个就叫做中断缺失。所以我们必须保证中断是快速执行快速结束的。 那有什么办法可以保护好你的奶茶呢?当你接到披萨小哥的电话后,你跟他说,我知道外卖来了,等我下楼的时候我们面对面吹水,电话先挂了,不然奶茶小哥打不进来,这个就叫做 中断上半部处理,然后等你下楼见到披萨小哥后,面对面吹水聊天,这个就叫做 中断下半部处理,这样在你和披萨小哥聊天的过程中,手机也不占线,奶茶小哥打电话过来你就可以接到了。所以我们一般在中断上半部处理比较紧急的时间(接披萨小哥的外卖),然后在中断下半部处理执行时间比较长的时间(和披萨小哥聊天),把中断分成上下半部,也可以保证后面的中断过来不会发生中断缺失
上半部通常是完成整个中断处理任务中的一小部分,比如硬件中断处理完成时发送EOI信号给中断控制器等,就是在上半部完成的,其他计算时间比较长的数据处理等,这些任务可以放到中断下半部来执行。Linux内核并没有严格的规则约束究竟什么样的任务应该放到下半部来执行,这是要驱动开发者来决定的。中断任务的划分对系统性能会有比较大的影响。
那下半部具体在什么时候执行呢? 这个没有确定的时间点,一般是从硬件中断返回后的某一个时间点内会被执行。下半部执行的关键点是允许响应所有的中断,是一个开中断的环境。
8、什么是软中断?什么是tasklet?什么是工作队列
软中断是预留给系统中对时间要求最为严格和最重要的下半部使用的,而且目前驱动中只有块设备和网络子系统使用了软中断。 软中断指的,其实就是我们上面所描述的中断的下半部的处理程序。一般是以内核线程的方式运行。系统静态定义了若干种软中断的类型。并且Linux内核开发者不希望用户再扩充新的软中断类型,如果需要,建议使用tasklet
tasklet是基于软中断机制的另一种变种,运行在软中断上下文中。
workqueue是以内核线程的方式来处理中断下半部事务,是基于进程上下文的,而软中断和tasklet是基于中断上下文的,优先级要比进程上下文高,所以当软中断或者tasklet的处理时间太长的话,如果在对于实时性要求较高的进程中发生了中断,那么对于系统性能影响会很大。
四、Linux同步机制
1、Linux内核中包含了哪些同步机制?
答: 原子操作、自旋锁、信号量、互斥锁、读写锁、RCU和Per-CPU变量。
各个同步机制进一步的介绍可以看这个链接
五、Linux进程管理
进程和线程的区别?
进程是资源分配的最小单位,线程是程序执行的最小单位,线程是进程的一个执行单元,是一个比进程要小的独立运行的基本单位,一个程序至少要有一个进程,一个进程至少要有一个线程。更加细致的区别如下:
根本区别:进程是资源分配的最小单位,线程是程序执行的最小单元;
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









