







 本文介绍了ApacheShardingSphere在Java项目中的应用,包括JDBC层的扩展、配置、分片算法、SpringBoot集成、数据库操作、微服务实战以及与其他技术如SpringCloud和Seata的整合。内容涵盖了从基础概念到实际案例的详细介绍。
本文介绍了ApacheShardingSphere在Java项目中的应用,包括JDBC层的扩展、配置、分片算法、SpringBoot集成、数据库操作、微服务实战以及与其他技术如SpringCloud和Seata的整合。内容涵盖了从基础概念到实际案例的详细介绍。
🌹文末获取联系方式 📝

往期热门专栏回顾
系列文章目录
第一章 Java线程池技术应用
第二章 CountDownLatch和Semaphone的应用
第三章 Spring Cloud 简介
第四章 Spring Cloud Netflix 之 Eureka
第五章 Spring Cloud Netflix 之 Ribbon
第六章 Spring Cloud 之 OpenFeign
第七章 Spring Cloud 之 GateWay
第八章 Spring Cloud Netflix 之 Hystrix
第九章 代码管理gitlab 使用
第十章 SpringCloud Alibaba 之 Nacos discovery
第十一章 SpringCloud Alibaba 之 Nacos Config
第十二章 Spring Cloud Alibaba 之 Sentinel
第十三章 JWT
第十四章 RabbitMQ应用
第十五章 RabbitMQ 延迟队列
第十六章 spring-cloud-stream
第十七章 Windows系统安装Redis、配置环境变量
第十八章 查看、修改Redis配置,介绍Redis类型
第十九章 Redis RDB AOF
第二十章 Spring boot 操作 Redis
第二十一章 Java多线程安全与锁
第二十二章 Java微服务分布式事务框架seata
第二十三章 Java微服务分布式事务框架seata的TCC模式
第二十四章 Java微服务分库分表ShardingSphere - ShardingSphere-JDBC
前言
Apache ShardingSphere 是一款分布式的数据库生态系统, 可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。
Apache ShardingSphere 设计哲学为 Database Plus,旨在构建异构数据库上层的标准和生态。 它关注如何充分合理地利用数据库的计算和存储能力,而并非实现一个全新的数据库。 它站在数据库的上层视角,关注它们之间的协作多于数据库自身。
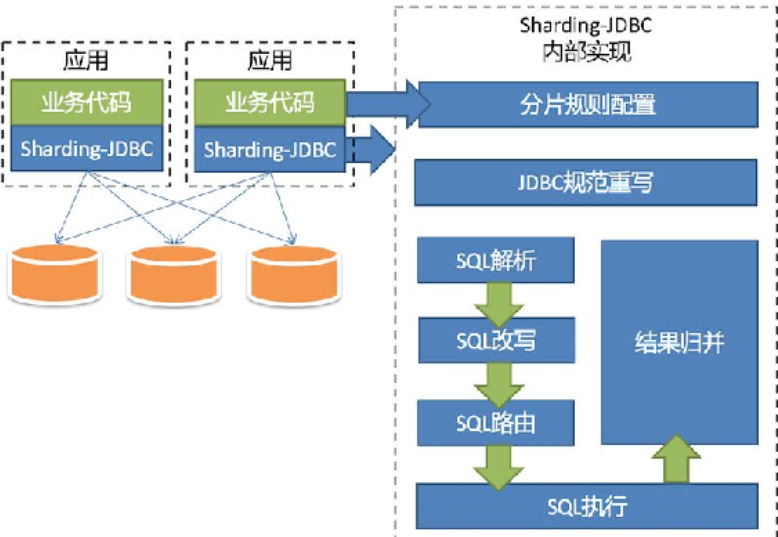
1、ShardingSphere-JDBC
ShardingSphere-JDBC 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。
1.1、应用场景
Apache ShardingSphere-JDBC 可以通过Java 和 YAML 这 2 种方式进行配置,开发者可根据场景选择适合的配置方式。
- 数据库读写分离
- 数据库分表分库
1.2、原理
- Sharding-JDBC中的路由结果是通过分片字段和分片方法来确定的,如果查询条件中有 id 字段的情况还好,查询将会落到某个具体的分片
- 如果查询没有分片的字段,会向所有的db或者是表都会查询一遍,让后封装结果集给客户端。
1.3、spring boot整合
1.3.1、添加依赖
<!-- 分表分库依赖 -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
1.3.2、添加配置
spring:
main:
# 一个实体类对应多张表,覆盖
allow-bean-definition-overriding: true
shardingsphere:
datasource:
ds0:
#配置数据源具体内容,包含连接池,驱动,地址,用户名和密码
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://127.0.0.1:3306/account?autoReconnect=true&allowMultiQueries=true
password: root
type: com.zaxxer.hikari.HikariDataSource
username: root
ds1:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://127.0.0.1:3306/account?autoReconnect=true&allowMultiQueries=true
password: root
type: com.zaxxer.hikari.HikariDataSource
username: root
# 配置数据源,给数据源起名称
names: ds0,ds1
props:
sql:
show: true
sharding:
tables:
user\_info:
#指定 user\_info 表分布情况,配置表在哪个数据库里面,表名称都是什么
actual-data-nodes: ds0.user_info_${0..9}
database-strategy:
standard:
preciseAlgorithmClassName: com.xxxx.store.account.config.PreciseDBShardingAlgorithm
rangeAlgorithmClassName: com.xxxx.store.account.config.RangeDBShardingAlgorithm
sharding-column: id
table-strategy:
standard:
preciseAlgorithmClassName: com.xxxx.store.account.config.PreciseTablesShardingAlgorithm
rangeAlgorithmClassName: com.xxxx.store.account.config.RangeTablesShardingAlgorithm
sharding-column: id
1.3.3、制定分片算法
1.3.3.1、精确分库算法
/\*\*
\* 精确分库算法
\*/
public class PreciseDBShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
/\*\*
\*
\* @param availableTargetNames 配置所有的列表
\* @param preciseShardingValue 分片值
\* @return
\*/
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> preciseShardingValue) {
Long value = preciseShardingValue.getValue();
//后缀 0,1
String postfix = String.valueOf(value % 2);
for (String availableTargetName : availableTargetNames) {
if(availableTargetName.endsWith(postfix)){
return availableTargetName;
}
}
throw new UnsupportedOperationException();
}
}
1.3.3.2、范围分库算法
/\*\*
\* 范围分库算法
\*/
public class RangeDBShardingAlgorithm implements RangeShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) {
return collection;
}
}
1.3.3.3、精确分表算法
/\*\*
\* 精确分表算法
\*/
public class PreciseTablesShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
/\*\*
\*
\* @param availableTargetNames 配置所有的列表
\* @param preciseShardingValue 分片值
\* @return
\*/
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> preciseShardingValue) {
Long value = preciseShardingValue.getValue();
//后缀
String postfix = String.valueOf(value % 10);
for (String availableTargetName : availableTargetNames) {
if(availableTargetName.endsWith(postfix)){
return availableTargetName;
}
}
throw new UnsupportedOperationException();
}
}
1.3.3.4、范围分表算法
/\*\*
\* 范围分表算法
\*/
public class RangeTablesShardingAlgorithm implements RangeShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) {
Collection<String> result = new ArrayList<>();
Range<Long> valueRange = rangeShardingValue.getValueRange();
Long start = valueRange.lowerEndpoint();
Long end = valueRange.upperEndpoint();
Long min = start % 10;
Long max = end % 10;
for (Long i = min; i < max +1; i++) {
Long finalI = i;
collection.forEach(e -> {
if(e.endsWith(String.valueOf(finalI))){
result.add(e);
}
});
}
return result;
}
}
1.3.4、数据库建表
DROP TABLE IF EXISTS `user\_info\_0`;
CREATE TABLE `user\_info\_0` (
`id` bigint(20) NOT NULL,
`account` varchar(255) DEFAULT NULL,
`user\_name` varchar(255) DEFAULT NULL,
`pwd` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
1.3.5、业务应用
1.3.5.1、定义实体类
@Data
@TableName(value = "user\_info")
public class UserInfo {
/\*\*
\* 主键
\*/
private Long id;
/\*\*
\* 账号
\*/
private String account;
/\*\*
\* 用户名
\*/
private String userName;
/\*\*
\* 密码
\*/
private String pwd;
}
1.3.5.2、定义接口
public interface UserInfoService{
/\*\*
\* 保存
\* @param userInfo
\* @return
\*/
public UserInfo saveUserInfo(UserInfo userInfo);
public UserInfo getUserInfoById(Long id);
public List<UserInfo> listUserInfo();
}
1.3.5.3、实现类
@Service
public class UserInfoServiceImpl extends ServiceImpl<UserInfoMapper, UserInfo> implements UserInfoService {
@Override
@Transactional
public UserInfo saveUserInfo(UserInfo userInfo) {
userInfo.setId(IdUtils.getId());
this.save(userInfo);
return userInfo;
}
@Override
public UserInfo getUserInfoById(Long id) {
return this.getById(id);
}
@Override
public List<UserInfo> listUserInfo() {
QueryWrapper<UserInfo> userInfoQueryWrapper = new QueryWrapper<>();
userInfoQueryWrapper.between("id",1623695688380448768L,1623695688380448769L);
return this.list(userInfoQueryWrapper);
}
}
1.3.6、生成ID - 雪花算法
package com.xxxx.tore.common.utils;
import cn.hutool.core.lang.Snowflake;
import cn.hutool.core.util.IdUtil;
/\*\*
\* 生成各种组件ID
\*/
public class IdUtils {
/\*\*
\* 雪花算法
\* @return
\*/
public static long getId(){
Snowflake snowflake = IdUtil.getSnowflake(0, 0);
long id = snowflake.nextId();
return id;
}
}
1.4、seata与sharding-jdbc整合
https://github.com/seata/seata-samples/tree/master/springcloud-seata-sharding-jdbc-mybatis-plus-samples
1.4.1、common中添加依赖
<!--seata依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
### 给大家的福利
**零基础入门**
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

同时每个成长路线对应的板块都有配套的视频提供:

因篇幅有限,仅展示部分资料
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以点击这里获取](https://bbs.csdn.net/topics/618540462)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 6944
6944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









