







 本文详细介绍了堆的数据结构,包括堆的概念、树的基础知识、堆的分类、如何找到父节点和孩子节点,以及堆的模拟实现,涉及堆的初始化、调整算法和时间复杂度分析,还讨论了堆在排序和TopK问题中的应用。
本文详细介绍了堆的数据结构,包括堆的概念、树的基础知识、堆的分类、如何找到父节点和孩子节点,以及堆的模拟实现,涉及堆的初始化、调整算法和时间复杂度分析,还讨论了堆在排序和TopK问题中的应用。
目录
一、堆的模拟
堆是什么
如图,堆的逻辑结构其实就是树,物理结构就是顺序表或数组,想了解堆,我们先来理解一下树,为什么这么说呢,我们看下文。
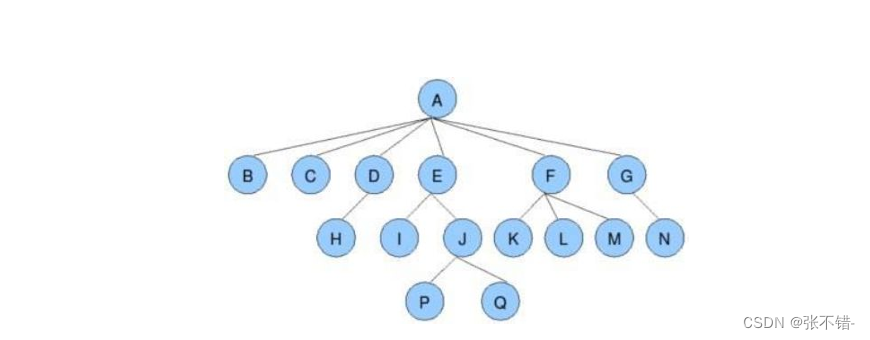
树的相关概念
- 节点的度 ,一个节点含有的字数的个数。如A的为6.
- 叶子节点或终端节点,没有孩子的节点。如B,C,H,L...
- 双亲节点或父节点,若一个节点含有子节点,则这个节点成为其子节点的父节点。
- 兄弟节点,同一节点的孩子。A是B的父节点。
- 孩子节点,如图B是A的孩子。
- 树的高度或深度,树种节点的最大层次。如树的高度为4.
- 节点的祖先,从根到该节点所经分支上的所有节点。如A是所有节点的祖先
- 子孙,如所有节点都是A的子孙。
- 森林,由m(m>0)课互不相交的树的集合成为森林。
树的类型
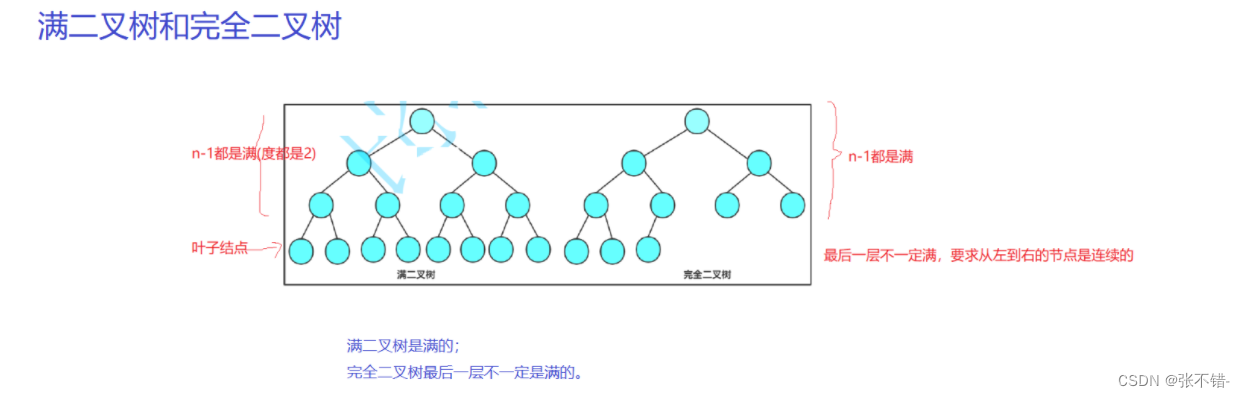
如图,树分为满二叉树和完全二叉树
- 满二叉树:所有节点都是满的。
- 完全二叉树:n-1层是满的,但最后一次不一定是满的。
堆的模拟
了解的树的概念和类型,我们来了解一下堆的分类
堆的分类

如图(图为辅)
堆:完全二叉树和大堆(小堆)
我们看到堆的逻辑结构为树,存储结构(物理结构)为顺序表。
堆如何找到父节点和孩子节点。
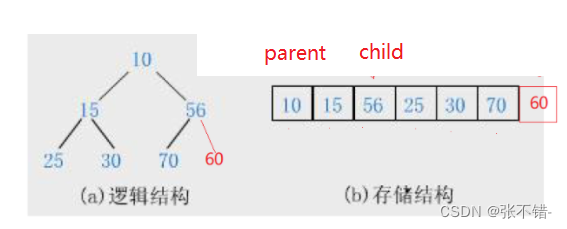
如图,如果我们要找到56的父节点,我们如何操作呢?
父节点
//找父节点
int parent = (child - 1) / 2;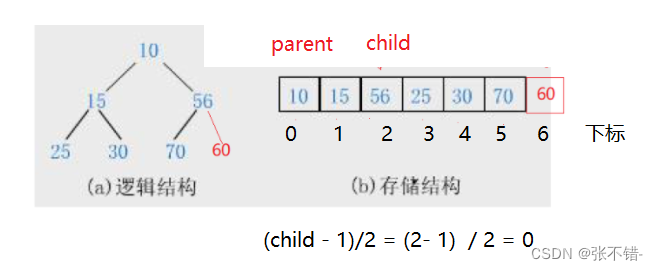
孩子节点
int child = parent * 2 + 1;道理同。
堆的模拟实现(支持CV编程)
了解了这么多堆和树的概念,我们来实现一下堆的模拟吧。
Heap.h文件-头文件
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>
#include<string.h>
typedef int HPDataType;
typedef struct Heap
{
HPDataType* a;
int size;
int capacity;
}HP;
void HPInit(HP* php);
void HPInitArray(HP* php, HPDataType* a, int n);
void HPDestroy(HP* php);
// 插入后保持数据是堆
void HPPush(HP* php, HPDataType x);
HPDataType HPTop(HP* php);//堆顶数据
// 删除堆顶的数据
void HPPop(HP* php);
bool HPEmpty(HP* php);//堆是否为空
void AdjustUp(HPDataType* a, int child);//向上调整
void AdjustDown(HPDataType* a, int n, int parent);//向下调整Heap.c文件-函数实现文件
#include"Heap.h"
void HPInit(HP* php)
{
assert(php);
php->a = NULL;
php->size = 0;
php->capacity = 0;
}
void HPInitArray(HP* php, HPDataType* a, int n)
{
assert(php);
php->a = (HPDataType*)malloc(sizeof(HPDataType) * n);
if (php->a == NULL)
{
perror("malloc fail");
return;
}
memcpy(php->a, a, sizeof(HPDataType) * n);
php->capacity = php->size = n;
// 向上调整,建堆 O(N*logN)
//for (int i = 1; i < php->size; i++)
//{
// AdjustUp(php->a, i);
//}
// 向下调整,建堆 O(N)
for (int i = (php->size - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(php->a, php->size, i);
}
}
void HPDestroy(HP* php)
{
assert(php);
free(php->a);
php->a = NULL;
php->capacity = 0;
php->size = 0;
}
void Swap(HPDataType* px, HPDataType* py)
{
HPDataType tmp = *px;
*px = *py;
*py = tmp;
}
void AdjustUp(HPDataType* a, int child)
{
int parent = (child - 1) / 2;
//while (parent >= 0)
while (child > 0)
{
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
child = parent;
parent = (parent - 1) / 2;
}
else
{
break;
}
}
}
// 时间复杂度:
void HPPush(HP* php, HPDataType x)
{
assert(php);
if (php->size == php->capacity)
{
size_t newCapacity = php->capacity == 0 ? 4 : php->capacity * 2;
HPDataType* tmp = realloc(php->a, sizeof(HPDataType) * newCapacity);
if (tmp == NULL)
{
perror("realloc fail");
return;
}
php->a = tmp;
php->capacity = newCapacity;
}
php->a[php->size] = x;
php->size++;
AdjustUp(php->a, php->size - 1);
}
HPDataType HPTop(HP* php)
{
assert(php);
return php->a[0];
}
void AdjustDown(HPDataType* a, int n, int parent)
{
int child = parent * 2 + 1;
while (child < n)
{
// 假设法,选出左右孩子中小的那个孩子
if (child + 1 < n && a[child + 1] > a[child])
{
++child;
}
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
// 时间复杂度:logN
void HPPop(HP* php)
{
assert(php);
assert(php->size > 0);
Swap(&php->a[0], &php->a[php->size - 1]);
php->size--;
AdjustDown(php->a, php->size, 0);
}
bool HPEmpty(HP* php)
{
assert(php);
return php->size == 0;
}Text.c文件-测试文件
#include"Heap.h"
int main()
{
//int a[] = { 50,100,70,65,60,32 };
int a[] = { 60,70,65,50,32,100 };
HP hp;
HPInitArray(&hp, a, sizeof(a)/sizeof(int));
/*HPInit(&hp);
for (int i = 0; i < sizeof(a)/sizeof(int); i++)
{
HPPush(&hp, a[i]);
}*/
//printf("%d\n", HPTop(&hp));
//HPPop(&hp);
//printf("%d\n", HPTop(&hp));
while (!HPEmpty(&hp))
{
printf("%d\n", HPTop(&hp));
HPPop(&hp);
}
HPDestroy(&hp);
return 0;
}对于无需数组如何变为堆

把数组中的数据一个一个的HPPush一次。
堆
升序建大堆
void HeapSort(int* a, int n){ }// 升序,建大堆还是小堆呢?大堆
// O(N*logN)
void HeapSort(int* a, int n)
{
// a数组直接建堆 O(N)
for (int i = (n-1-1)/2; i >= 0; --i)
{
AdjustDown(a, n, i);
}
// O(N*logN)
int end = n - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0);
--end;
}
}这里的(n-1-1)/2是什么意思呢?
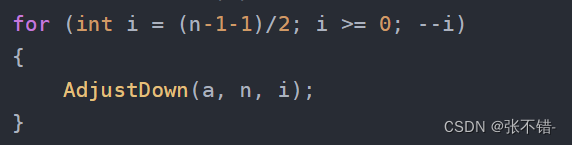
n-1是最后一个数据,然后套公式,找到父节点。
反之降序建小堆
堆找TopK问题
///
/// 找TopK,找前k个大的,用小堆
/// 找前k个小的,用大堆
///
/// </summary>
void CreateNDate()
{
// 造数据
int n = 10;
srand(time(0));
const char* file = "data.txt";
FILE* fin = fopen(file, "w");
if (fin == NULL)
{
perror("fopen error");
return;
}
for (int i = 0; i < n; ++i)
{
int x = (rand() + i) % 1000000;
fprintf(fin, "%d\n", x);
}
fclose(fin);
}
void PrintTopK()
{
printf("请输入k:");
int k = 5;
//scanf("%d ", &k);
const char* file = "data.txt";
FILE* fout = fopen(file, "r");
if (fout == NULL)
{
perror("fopen error");
return;
}
int val = 0;
int* minheap = (int*)malloc(sizeof(int) * k);
if (minheap == NULL)
{
perror("malloc error");
return;
}
for (int i = 0; i < k; i++)
{
fscanf(fout, "%d", &minheap[i]);//读取数据
}
//建小堆
for (int i = (k - 1 - 1) / 2; i > 0; --i)
{
AdjustDown(minheap,k,i);//读取总数为k
}
int x = 0;
while (fscanf(fout, "%d", &x) != EOF)
{
//读剩余数据,比栈顶大就替换,然后调整
if (x > minheap[0])
{
minheap[0] = x;
AdjustDown(minheap, k, 0);
}
}
for (int i = 0; i < k; i++)
{
printf("%d ", minheap[i]);
}
fclose(fout);
}为什么找前K个大的用小堆呢?
把小的数据放进堆里,然后把n-k个数据依次和堆顶的数据进行对比,大的就替换堆顶进堆,
由于是小堆,大的数据进堆后,进行堆排序,大的数据自动往堆的底层走,保持堆顶的数据 是小的数。
找前k个小的也是同样的道理。(建大堆,大的堆顶,比堆顶小就替换,替换的值自动往下走)
二、堆的时间复杂度
关于堆,还有一个非常重要的知识点,就是计算堆的时间复杂度。
插入的时间复杂度(满二叉树与完全二叉树)
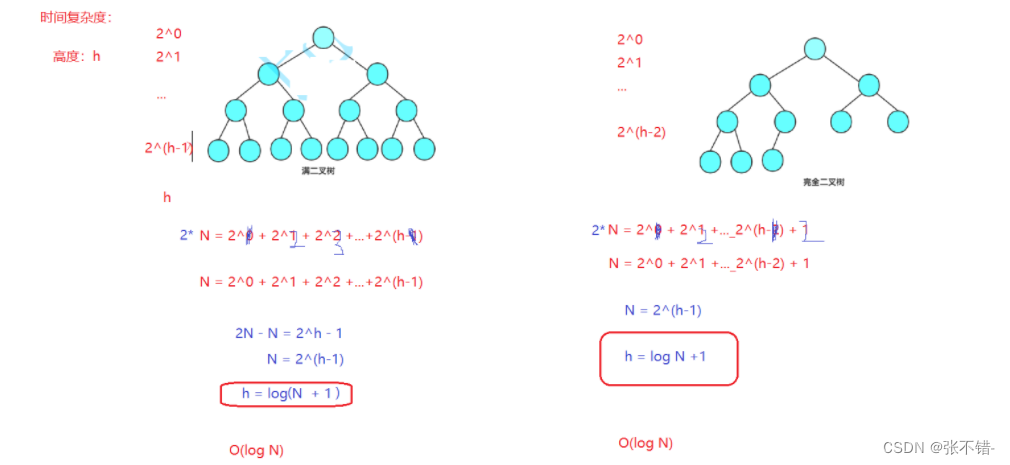
一个小公式:

采用了错位相减法
^插入的时间复杂度为:O(log N)
向上调整的时间复杂度
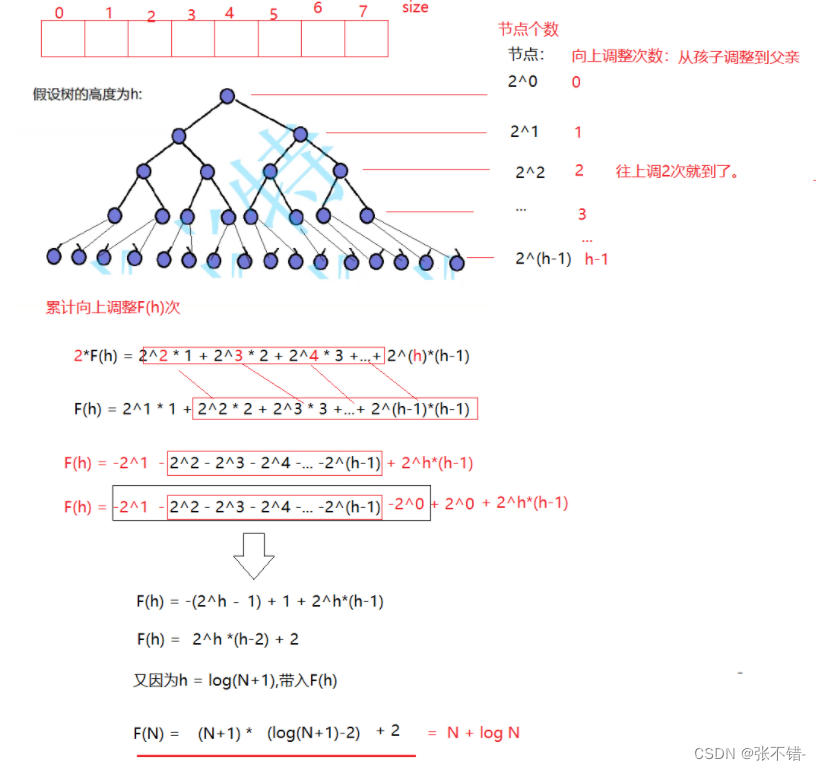
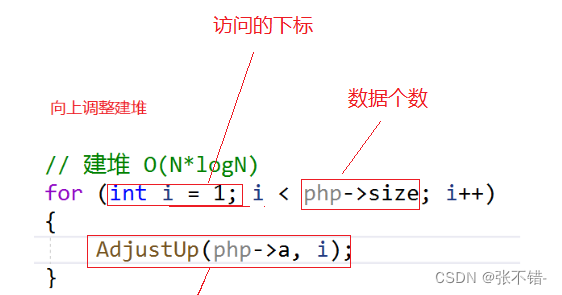
^建堆的时间复杂度:O(N*log N)
向下调整的时间复杂度
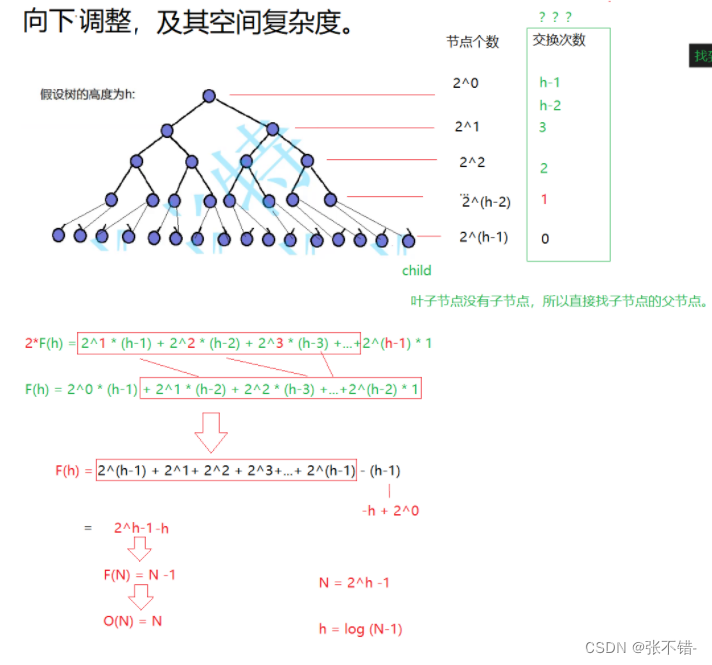
^向下调整的时间复杂度:O(N)















 393
393











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









