







我的github:codetoys,所有代码都将会位于ctfc库中。已经放入库中我会指出在库中的位置。
这些代码大部分以Linux为目标但部分代码是纯C++的,可以在任何平台上使用。
系列入口:编程实战:自己编写HTTP服务器(系列1:概述和应答)-CSDN博客
本文介绍如何处理请求。
目录
一、概述
请求和应答结构其实差不多,但是代码就多了很多分析过程(应答只需要拼接,简单多了)。
应答的代码:
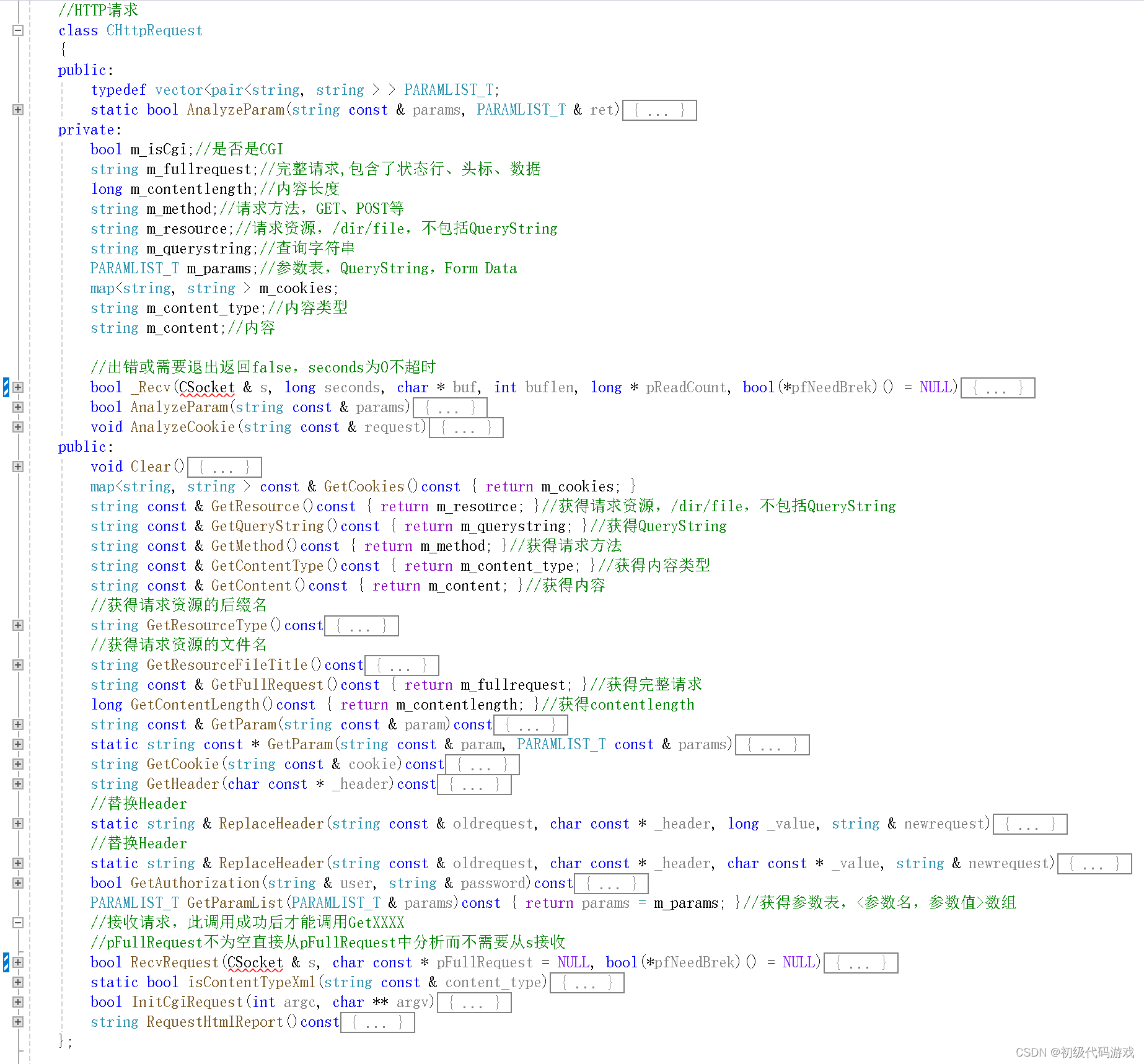
整个类从RecvRequest()开始,然后就是各种Get。显然嘛,服务器收到的请求对服务器来说是个只读信息,修改也没啥用啊。
二、成员变量
private:
bool m_isCgi;//是否是CGI
string m_fullrequest;//完整请求,包含了状态行、头标、数据
long m_contentlength;//内容长度
string m_method;//请求方法,GET、POST等
string m_resource;//请求资源,/dir/file,不包括QueryString
string m_querystring;//查询字符串
PARAMLIST_T m_params;//参数表,QueryString,Form Data
map<string, string > m_cookies;
string m_content_type;//内容类型
string m_content;//内容
与CGI有关的可以无视,CGI没什么用,因为没人再写CGI了,所以支持CGI也没什么用。
分解出的各种元素就在这些变量里,有一些内容是不同的分解程度。比如查询字符串同时被分解为参数,form数据也被分解为参数。虽然一般查询字符串和form data是不同的处理方式,但是其实我们都很希望在代码里能同样对待。
从性能角度来说,这样预分解不是一个好策略,最佳方式是用到什么去找什么,因为大部分内容其实是用不到的。
三、接收并分解请求
3.1 主要过程
代码如下:
//接收请求,此调用成功后才能调用GetXXXX
//pFullRequest不为空直接从pFullRequest中分析而不需要从s接收
bool RecvRequest(CSocket & s, char const * pFullRequest = NULL, bool(*pfNeedBrek)() = NULL)
{
Clear();
m_isCgi = false;
long timeout = 300;//接收超时
string::size_type headlen = 0;
char buf[1024];
long count;
string::size_type pos;
if (NULL != pFullRequest)m_fullrequest = pFullRequest;
//先接收请求头
while (m_fullrequest.npos == (headlen = m_fullrequest.find("\r\n\r\n")))
{
if (!_Recv(s, timeout, buf, 1023, &count, pfNeedBrek))
{
//LOG<<"recv error"<<ENDE;
s.Close();
return false;
}
if (0 == count)
{
//LOG<<"client closed"<<ENDE;
s.Close();
return false;
}
buf[count] = '\0';
m_fullrequest += buf;
}
//获得第一行
pos = m_fullrequest.find("\r\n");
string str;
str = m_fullrequest.substr(0, pos);
//获得method
pos = str.find(" ");
if (str.npos == pos)
{
return false;
}
this->m_method = str.substr(0, pos);
str.erase(0, pos + 1);
//去掉http版本
pos = str.find_last_of(" ");
if (str.npos == pos)
{
return false;
}
str.erase(pos);
//剩下的是URL,问号之后的是GET参数
pos = str.find_first_of("?");
if (str.npos != pos)
{
this->m_resource = str.substr(0, pos);
str.erase(0, pos + 1);
m_querystring = str;
}
else
{
this->m_resource = str;
}
//分析Cookie
AnalyzeCookie(m_fullrequest);
//如果存在请求内容则接收请求内容
pos = m_fullrequest.find("Content-Length:");
if (m_fullrequest.npos == pos || pos >= headlen)
{
m_contentlength = 0;
m_content = "";
}
else
{
m_contentlength = atol(m_fullrequest.c_str() + pos + strlen("Content-Length:"));
while (m_fullrequest.size() < headlen + strlen("\r\n\r\n") + m_contentlength)
{
if (!_Recv(s, timeout, buf, 1023, &count, pfNeedBrek))
{
LOG << "recv error" << ENDE;
s.Close();
return false;
}
if (0 == count)
{
LOG << "client closed" << ENDE;
s.Close();
return false;
}
buf[count] = '\0';
m_fullrequest += buf;
}
m_content = m_fullrequest.substr(headlen + strlen("\r\n\r\n"), m_contentlength);
}
//根据内容类型处理数据
m_content_type = GetHeader("Content-Type");
Trim(m_content_type);
if ("application/x-www-form-urlencoded" == m_content_type)
{
if (m_querystring.size() != 0)m_querystring += "&";
m_querystring += m_content;
}
else if (isContentTypeXml(m_content_type))
{
DEBUG_LOG << "content is xml" << ENDI;
}
else
{
}
this->AnalyzeParam(m_querystring);
return true;
}
_Recv()从socket接收数据:
//出错或需要退出返回false,seconds为0不超时
bool _Recv(CSocket & s, long seconds, char * buf, int buflen, long * pReadCount, bool(*pfNeedBrek)() = NULL)
{
bool isReady = false;
if (!s.IsSocketReadReady2(seconds, isReady, pfNeedBrek))
{
LOG << "CSocket error" << ENDE;
return false;
}
if (!isReady)
{
DEBUG_LOG << "CSocket timeout" << ENDI;
return false;
}
else
{
DEBUG_LOG << "CSocket ready" << ENDI;
}
return s.Recv(buf, buflen, pReadCount);
}
用的是一个socket包装类,从我的另一篇文章里可以获得源代码。
接受请求的代码虽然比较长,但是也没什么难点。
如果内容是form data而且是url编码就把内容追加到查询字符串,然后统一解析查询字符串。
3.2 解析查询字符串
代码如下:
typedef vector<pair<string, string > > PARAMLIST_T;
static bool AnalyzeParam(string const & params, PARAMLIST_T & ret)
{
ret.clear();
if (0 == params.size())return true;
string tmpparams = params + "&";
string::size_type pos;
while (tmpparams.npos != (pos = tmpparams.find("&")))
{
string str = tmpparams.substr(0, pos);
string::size_type pos2;
if (str.npos != (pos2 = str.find("=")))
{
ret.push_back(pair<string, string >(CHtmlDoc::URLDecode(str.substr(0, pos2)), CHtmlDoc::URLDecode(str.substr(pos2 + 1))));
}
tmpparams.erase(0, pos + 1);
}
return true;
}
倒也没什么特别的,就是拆解字符串,不过拆解出来的还要经过解码。
3.3 url解码
static string URLDecode(string const & str)
{
string ret = "";
string::size_type i = 0;
while (i < str.size())
{
if ('+' == str[i])
{
ret += ' ';
++i;
continue;
}
else if ('%' != str[i])
{
ret += str[i];
++i;
continue;
}
else
{
if (i + 2 < str.size())
{
char c = '\0';
c += hexchartolong(str[i + 1]) * 16;
c += hexchartolong(str[i + 2]);
ret += c;
i += 3;
continue;
}
else
{
break;
}
}
}
return ret;
}
规则很简单:
- +代表空格
- %后跟两位16进制代表一个字节
url编码就是逆过程。
四、完整代码
完整代码如下:
//HTTP请求
class CHttpRequest
{
public:
typedef vector<pair<string, string > > PARAMLIST_T;
static bool AnalyzeParam(string const & params, PARAMLIST_T & ret)
{
ret.clear();
if (0 == params.size())return true;
string tmpparams = params + "&";
string::size_type pos;
while (tmpparams.npos != (pos = tmpparams.find("&")))
{
string str = tmpparams.substr(0, pos);
string::size_type pos2;
if (str.npos != (pos2 = str.find("=")))
{
ret.push_back(pair<string, string >(CHtmlDoc::URLDecode(str.substr(0, pos2)), CHtmlDoc::URLDecode(str.substr(pos2 + 1))));
}
tmpparams.erase(0, pos + 1);
}
return true;
}
private:
bool m_isCgi;//是否是CGI
string m_fullrequest;//完整请求,包含了状态行、头标、数据
long m_contentlength;//内容长度
string m_method;//请求方法,GET、POST等
string m_resource;//请求资源,/dir/file,不包括QueryString
string m_querystring;//查询字符串
PARAMLIST_T m_params;//参数表,QueryString,Form Data
map<string, string > m_cookies;
string m_content_type;//内容类型
string m_content;//内容
//出错或需要退出返回false,seconds为0不超时
bool _Recv(CSocket & s, long seconds, char * buf, int buflen, long * pReadCount, bool(*pfNeedBrek)() = NULL)
{
bool isReady = false;
if (!s.IsSocketReadReady2(seconds, isReady, pfNeedBrek))
{
LOG << "CSocket error" << ENDE;
return false;
}
if (!isReady)
{
DEBUG_LOG << "CSocket timeout" << ENDI;
return false;
}
else
{
DEBUG_LOG << "CSocket ready" << ENDI;
}
return s.Recv(buf, buflen, pReadCount);
}
bool AnalyzeParam(string const & params)
{
return AnalyzeParam(params, m_params);
}
void AnalyzeCookie(string const & request)
{
string COOKIE = "Cookie: ";
string::size_type pos_start;
string::size_type pos_end;
pos_start = request.find(COOKIE);
if (request.npos == pos_start)return;
pos_end = request.find("\r\n", pos_start);
if (request.npos == pos_end)return;
string str = request.substr(pos_start + COOKIE.size(), pos_end - (pos_start + COOKIE.size()));
CStringSplit st(str.c_str(), ";");
for (CStringSplit::iterator it = st.begin(); it != st.end(); ++it)
{
CStringSplit st2(it->c_str(), "=");
if (st2.size() != 2)continue;
m_cookies[st2[0]] = st2[1];
}
}
public:
void Clear()
{
m_isCgi = false;
m_fullrequest = "";
m_contentlength = 0;
m_method = "";
m_resource = "";
m_querystring = "";
m_params.clear();
m_cookies.clear();
m_content_type = "";
m_content = "";
}
map<string, string > const & GetCookies()const { return m_cookies; }
string const & GetResource()const { return m_resource; }//获得请求资源,/dir/file,不包括QueryString
string const & GetQueryString()const { return m_querystring; }//获得QueryString
string const & GetMethod()const { return m_method; }//获得请求方法
string const & GetContentType()const { return m_content_type; }//获得内容类型
string const & GetContent()const { return m_content; }//获得内容
//获得请求资源的后缀名
string GetResourceType()const
{
long pos = m_resource.size() - 1;
while (pos >= 0 && m_resource[pos] != '.' && m_resource[pos] != '/')--pos;
if (pos < 0 || m_resource[pos] == '/')return "";
return m_resource.substr(pos + 1);
}
//获得请求资源的文件名
string GetResourceFileTitle()const
{
size_t start = m_resource.find_last_of('/');
size_t end = m_resource.find_last_of('.');
if (start != m_resource.npos && end != m_resource.npos)
{
if (end > start + 1)return m_resource.substr(start + 1, end - start - 1);
}
return "";
}
string const & GetFullRequest()const { return m_fullrequest; }//获得完整请求
long GetContentLength()const { return m_contentlength; }//获得contentlength
string const & GetParam(string const & param)const//获得参数,如果参数有重复则只能取得第一个
{
STATIC_C string const static_str;
string const * p = GetParam(param, m_params);
if (NULL != p)return *p;
else return static_str;
}
static string const * GetParam(string const & param, PARAMLIST_T const & params)//获得参数,如果参数有重复则只能取得第一个
{
string _param = param;
for (string::size_type i = 0; i < params.size(); ++i)
{
string _first = params[i].first;
if (0 == stricmp(_param.c_str(), _first.c_str()))return ¶ms[i].second;
}
return NULL;
}
string GetCookie(string const & cookie)const
{
map<string, string >::const_iterator it = this->m_cookies.find(cookie);
if (it != this->m_cookies.end())return it->second;
else return "";
}
string GetHeader(char const * _header)const
{
if (m_isCgi)
{
//获得HTTP头标,实际上是从环境变量中直接获取
char const * penv = getenv(_header);
if (NULL != penv)return penv;
else return "";
}
else
{
string header = _header;
header += ": ";
string::size_type pos_start;
string::size_type pos_end;
if (m_fullrequest.npos == (pos_start = m_fullrequest.find(header)))return "";
if (m_fullrequest.npos == (pos_end = m_fullrequest.find("\r\n", pos_start)))return "";
string ret = m_fullrequest.substr(pos_start + header.size(), pos_end - pos_start - header.size());
return Trim(ret);
}
}
//替换Header
static string & ReplaceHeader(string const & oldrequest, char const * _header, long _value, string & newrequest)
{
char buf[256];
sprintf(buf, "%ld", _value);
return ReplaceHeader(oldrequest, _header, buf, newrequest);
}
//替换Header
static string & ReplaceHeader(string const & oldrequest, char const * _header, char const * _value, string & newrequest)
{
newrequest = oldrequest;
string header = _header;
header += ": ";
string::size_type pos_start;
string::size_type pos_end;
if (newrequest.npos != (pos_start = newrequest.find(header)))
{
if (newrequest.npos != (pos_end = newrequest.find("\r\n", pos_start)))
{
newrequest.replace(pos_start + header.size(), pos_end - pos_start - header.size(), _value);
return newrequest;
}
else
{
LOG << "格式错误,没有行结束符" << ENDE;
return newrequest = "";
}
}
else
{
if (newrequest.npos != (pos_start = newrequest.find("\r\n")))
{
newrequest.insert(pos_start + strlen("\r\n"), header + _value + "\r\n");
return newrequest;
}
else
{
LOG << "格式错误,没有行结束符" << ENDE;
return newrequest = "";
}
}
}
bool GetAuthorization(string & user, string & password)const
{
string AUTHORIZATION = "Authorization: Basic ";
string::size_type pos_start;
string::size_type pos_end;
string base64;
if (m_fullrequest.npos == (pos_start = m_fullrequest.find(AUTHORIZATION)))return false;
if (m_fullrequest.npos == (pos_end = m_fullrequest.find("\r\n", pos_start)))return false;
base64 = m_fullrequest.substr(pos_start + AUTHORIZATION.size(), pos_end - pos_start - AUTHORIZATION.size());
char buf[2048];
int len;
if (0 > (len = CBase64::Base64Dec(buf, base64.c_str(), (int)base64.size())))
{
LOG << "base64解码错误" << ENDE;
}
buf[len] = '\0';
DEBUG_LOG << buf << ENDI;
CStringSplit st(buf, ":");
if (st.size() != 2)return false;
user = st[0];
password = st[1];
return true;
}
PARAMLIST_T GetParamList(PARAMLIST_T & params)const { return params = m_params; }//获得参数表,<参数名,参数值>数组
//接收请求,此调用成功后才能调用GetXXXX
//pFullRequest不为空直接从pFullRequest中分析而不需要从s接收
bool RecvRequest(CSocket & s, char const * pFullRequest = NULL, bool(*pfNeedBrek)() = NULL)
{
Clear();
m_isCgi = false;
long timeout = 300;//接收超时
string::size_type headlen = 0;
char buf[1024];
long count;
string::size_type pos;
if (NULL != pFullRequest)m_fullrequest = pFullRequest;
//先接收请求头
while (m_fullrequest.npos == (headlen = m_fullrequest.find("\r\n\r\n")))
{
if (!_Recv(s, timeout, buf, 1023, &count, pfNeedBrek))
{
//LOG<<"recv error"<<ENDE;
s.Close();
return false;
}
if (0 == count)
{
//LOG<<"client closed"<<ENDE;
s.Close();
return false;
}
buf[count] = '\0';
m_fullrequest += buf;
}
//获得第一行
pos = m_fullrequest.find("\r\n");
string str;
str = m_fullrequest.substr(0, pos);
//获得method
pos = str.find(" ");
if (str.npos == pos)
{
return false;
}
this->m_method = str.substr(0, pos);
str.erase(0, pos + 1);
//去掉http版本
pos = str.find_last_of(" ");
if (str.npos == pos)
{
return false;
}
str.erase(pos);
//剩下的是URL,问号之后的是GET参数
pos = str.find_first_of("?");
if (str.npos != pos)
{
this->m_resource = str.substr(0, pos);
str.erase(0, pos + 1);
m_querystring = str;
}
else
{
this->m_resource = str;
}
//分析Cookie
AnalyzeCookie(m_fullrequest);
//如果存在请求内容则接收请求内容
pos = m_fullrequest.find("Content-Length:");
if (m_fullrequest.npos == pos || pos >= headlen)
{
m_contentlength = 0;
m_content = "";
}
else
{
m_contentlength = atol(m_fullrequest.c_str() + pos + strlen("Content-Length:"));
while (m_fullrequest.size() < headlen + strlen("\r\n\r\n") + m_contentlength)
{
if (!_Recv(s, timeout, buf, 1023, &count, pfNeedBrek))
{
LOG << "recv error" << ENDE;
s.Close();
return false;
}
if (0 == count)
{
LOG << "client closed" << ENDE;
s.Close();
return false;
}
buf[count] = '\0';
m_fullrequest += buf;
}
m_content = m_fullrequest.substr(headlen + strlen("\r\n\r\n"), m_contentlength);
}
//根据内容类型处理数据
m_content_type = GetHeader("Content-Type");
Trim(m_content_type);
if ("application/x-www-form-urlencoded" == m_content_type)
{
if (m_querystring.size() != 0)m_querystring += "&";
m_querystring += m_content;
}
else if (isContentTypeXml(m_content_type))
{
DEBUG_LOG << "content is xml" << ENDI;
}
else
{
}
this->AnalyzeParam(m_querystring);
return true;
}
static bool isContentTypeXml(string const & content_type)
{
return "Text/xml" == content_type;
}
bool InitCgiRequest(int argc, char ** argv)
{
Clear();
m_isCgi = true;
string tmp;
thelog << "argc " << argc << endi;
if (argc >= 2)
{
thelog << m_resource << endi;
m_resource = argv[1];
}
if (argc >= 3)
{
tmp = argv[2];
thelog << tmp << endi;
m_querystring = tmp;
AnalyzeParam(m_querystring);
}
char const * penv;
if (NULL != (penv = getenv("REQUEST_METHOD")))
{
m_method = penv;
}
if (NULL != (penv = getenv("QUERY_STRING")))
{
tmp = penv;
AnalyzeParam(tmp);
}
//如果是POST,内容从标准输入获取,因为没有文件结束符,长度必须从头标获取
if (NULL != (penv = getenv("CONTENT_LENGTH")))
{
char * p = NULL;
int content_length = atol(penv);
p = new char[content_length + 1];
if (NULL == p)return false;
if (content_length != read(STDIN_FILENO, p, content_length))return false;
p[content_length] = '\0';
tmp = p;
AnalyzeParam(tmp);
delete[] p;
}
if (NULL != (penv = getenv("REQUEST_URI")))
{
tmp = penv;
string::size_type pos = tmp.find_first_of("?");
if (tmp.npos != pos)
{
m_resource = tmp.substr(0, pos);
}
else
{
m_resource = tmp;
}
}
return true;
}
string RequestHtmlReport()const//报告请求信息,HTML格式
{
string ret = "HttpRequest:<HR/>";
ret += m_method;
ret += " ";
ret += m_resource;
ret += "<BR>\n";
for (PARAMLIST_T::size_type i = 0; i < m_params.size(); ++i)
{
ret += CHtmlDoc::HTMLEncode(m_params[i].first);
ret += " = ";
ret += CHtmlDoc::HTMLEncode(m_params[i].second);
ret += "<BR>\n";
}
map<string, string >::const_iterator it;
for (it = m_cookies.begin(); it != m_cookies.end(); ++it)
{
ret += "Cookie: ";
ret += it->first + "=" + it->second + "<BR>\n";
}
ret += "<HR/>";
time_t t1 = time(NULL);
ret += asctime(localtime(&t1));
return ret;
}
};
五、HTTP处理框架
编程实战:自己编写HTTP服务器(系列3:处理框架)-CSDN博客
(这里是结束,但是并不是整个系列的结束)















 282
282











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









