







我的github:codetoys,所有代码都将会位于ctfc库中。已经放入库中我会指出在库中的位置。
这些代码大部分以Linux为目标但部分代码是纯C++的,可以在任何平台上使用。
这可能是应用级程序员最困惑的问题了吧,这真的不怪程序员,因为这里确实太混乱了。
目录
1 理论
你可能看了很多文章解释什么是字符集,然而程序仍然乱码了是吗?
两个基本概念一定要先搞清楚:字符集和字符编码。
一般我们都把这两个概念混起来讲,“以前是多字节字符集,用char存储,后来是UNICODE,用wchar_t存储”,历史上确实这么发展过来的,但是讲理论却并非如此。这两个概念是没有关系的。
字符集可以简单理解为字符的“值”的集合,不同字符集可以用不同的值来表示同一个字符(当然,出于对历史的尊重,大部分字符集都兼容ASCII码),中文这个问题最大,因为有几个不同的机构制定字符集,不同字符集当然也用同一个值表示不同的字符。
字符的值如何存储为字节数据呢?这是个问题叫做字符编码。
英文ASCII最早是单字节存储的,而且只用了0-127(低7位,最高位总是0),后来各种本地语言就使用了128-255这部分(最高位为1),并且连续两个或更多字节表示一个字符,这种存储方式显然兼容了英文ASCII字符集的编码方式,使用这种字符集和编码方式的程序可以正常读取纯英文文本。你要用两字节的short int存储行不行?当然行,但是跟别人不兼容啊,自己掂量掂量。所以此时还没有字符编码的分歧。
因为各国自己定义字符集的时候没考虑其他国家,这就有很多相同的值在不同字符集里表示不同的字符,这样不同字符集的文本没法合并在一起,于是大家联合制定了统一字符集UNICODE。
这个全球统一字符集包含了所有语言的字符,所以非常大,还要考虑字符处理的时候方便,这就产生了多种存储方案,单字节、双字节、四字节都有,所谓UTF-8、UTF-16、UTF-32。
UTF-8的好处是兼容以前的char程序,如果是纯英文,根本就是ASCII码。linux默认就是这个。
UTF-16的好处是Windows内核一直用这个,wchat_t。关于为什么Windows内核要用这个呢,以前的解释是计算字符数很简单,字符串数组的长度和字符数一致,但是呢,其实UNICODE字符集的字符数超过了两个字节的存储范围,字符串数组的长度并不一定和字符数一致,不过起码对中文基本如此。我们以前做SQLServer数据库的时候字符串类型字段的编码选择UNICODE也是基于同样的理由,界面上限制字符串长度的时候比较容易解释(不然的话,就得想办法让用户相信一个中文字符等于两个英文字符)。
UTF-32的好处是一个字符就是一个字符(40亿应该能容纳全宇宙的所有的字符了),处理起来太方便了,但是需要2-4倍存储空间,所以其实也很少见到用。在linux上,wchar_t就是4个字节(跟windows不一样哦)。
由于UTF-16和UTF-32用的是short int和int存储,所以存储顺序就成了问题。UTF-8也要多个字节,为啥没问题?这种基于char的字符编码只有0123这种顺序。
存储顺序就是我们熟知的字节序问题,分大端小端两种,写网络程序我们知道要统一成网络字节序传输,各自转换为本地字节序。对于文本文件不能这样做,文件不可以随便改,所以有些人想了一个办法,加上一个文件头来识别:两个字节的BOM(UTF-32后面多两个字节0)。
“你说UTF-8不需要啊?怎么我看到的文件前面多了三字节?”(苦笑)微软搞出来的。所以用VS的程序员经常需要手工把文件另存为“UTF-8不带签名”。
BOM仅用于文件,那么对于一个字符串,如何检测编码?只能靠猜……
2 总结
总结一下,解决乱码要知道下列信息:
字符集,本地编码还是UNICODE,GB还是大五
字符编码,单字节、双字节还是四字节
BOM,带不带BOM(仅限文件)
另,什么是windows的“代码页”,代码页是以上所有要点的综合表示,每种本地编码都是一种代码页(本地编码不包含BOM),unicode的不同编码也是独立的代码页(但是还要额外区分BOM)。
3 实践
3.1 新建控制台项目(VS2022或任意版本)
我们用一个控制台项目来验证,将主文件替换为如下代码:
//0123456789
#include <iostream>
using namespace std;
char const* a = "0000啊0联0通0000";
string ToHex(char const* str)
{
char buf[16];
string ret;
for (char const* p = str; *p != '\0'; ++p)
{
sprintf_s(buf, 16, "%02X ", (unsigned char)*p);
ret += buf;
}
return ret;
}
int main()
{
std::cout << a << endl;
std::cout << ToHex(a) << endl;
}
代码很简单,输出了一个字符串和字符串的16进制表示,运行输出:
0000啊0联0通0000
30 30 30 30 B0 A1 30 C1 AA 30 CD A8 30 30 30 30
C:\temp\ConsoleApplication1\x64\Debug\ConsoleApplication1.exe (进程 16568)已退出,代码为 0。
按任意键关闭此窗口. . .第一行是字符串,应该不是乱码,第二行是十六进制,字符“0”的ASCII码是30,“B0 A1”应该就是“啊”(牢记这个,后面要做比较),另外两组非30数据当然是“联通”。为什么专门用“联通”呢?这有个典故,早年windows的记事本输入“联通”,再打开显示就是乱码。
3.2 检查文件编码设置(GB2312)
现在我们看看源码文件的编码到底是什么。点击菜单“文件”-“XXX另存为”,在弹出的对话框的“保存”按钮的向下箭头上点击一下,选择“编码保存”:
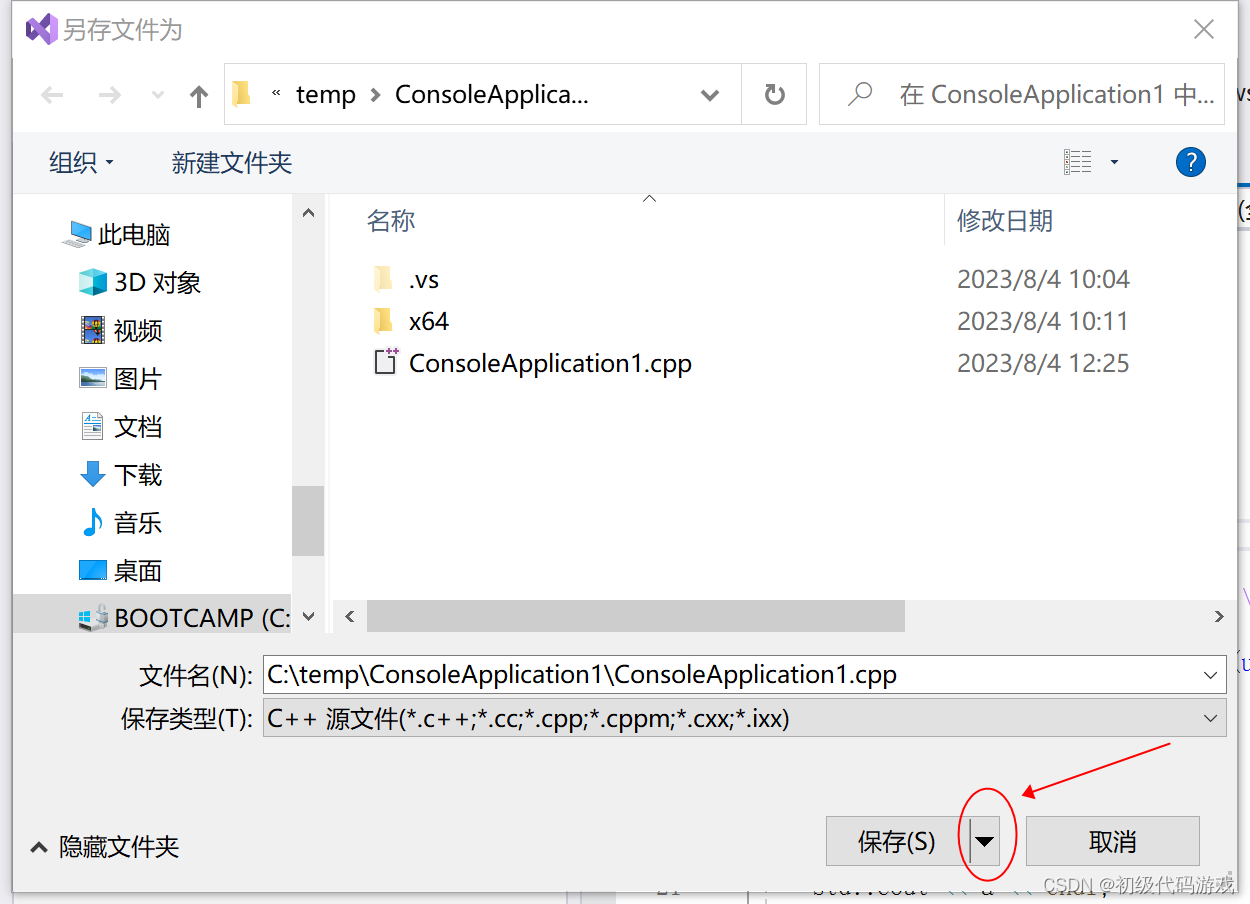
提示是否覆盖文件,选择是,然后看到如下对话框:
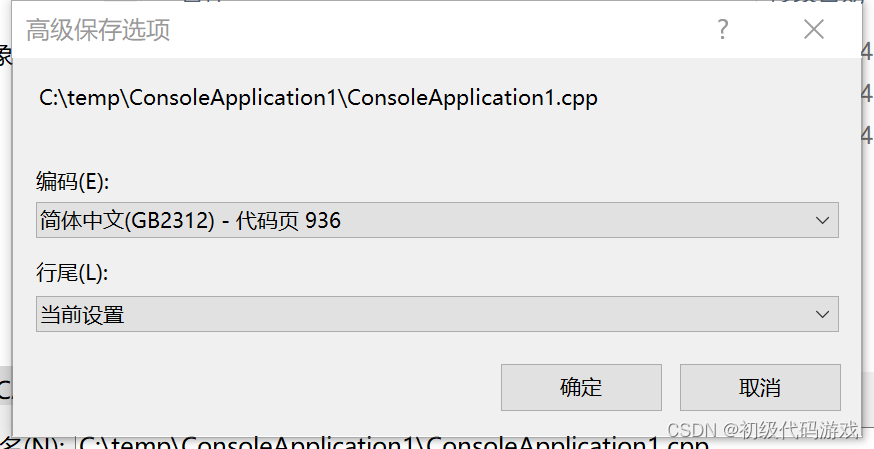
这下就明白了,现在的编码是GB2312,也就是中国大陆地区的本地编码。
在这里可以选择其它编码,然后点击“确定”保存。此刻我们先不修改编码,去看看文件是怎么存储的。
注意,你的源文件不一定是这个编码。
3.3 十六进制查看文件
源代码文件就是一个普通的文本文件,我们可以用任何一种支持十六进制显示的工具查看文件的十六进制内容。比如UltraEDIT(简称UE):

点击图中指示的那个工具栏按钮,切换为十六进制显示:
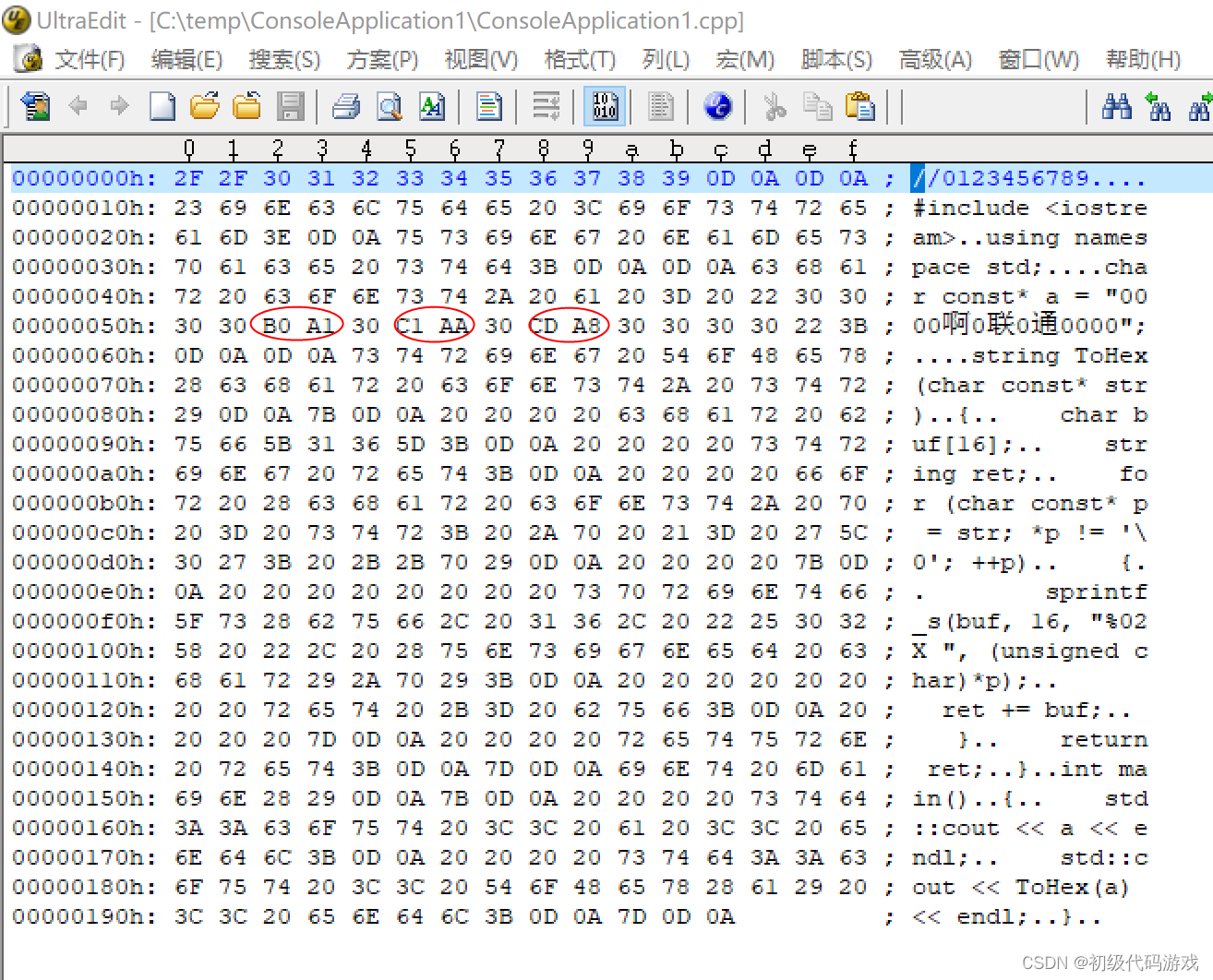
初次看十六进制可能有点晕,斜杠“/”是2F,0-9是30-39,回车换行是0D0A。这个文件的内容跟我们一般理解的文本是完全相同的,英文字符一个字节,中文两个字节,而且高位都是1(80-FF)。
3.4 UTF-8带签名
修改文件编码为UTF-8代签名并保存:
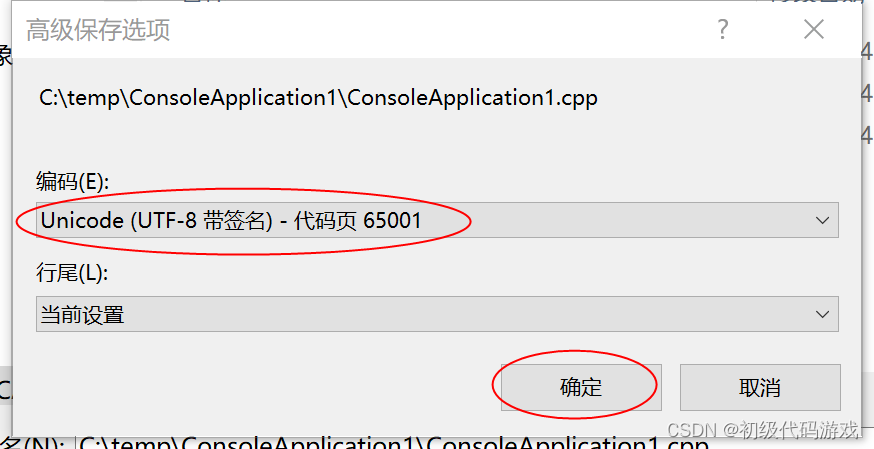
再次用工具查看源代码文件的十六进制内容(注意,如果是UltraEDIT,要先关闭再重新打开,自动重新加载有问题):
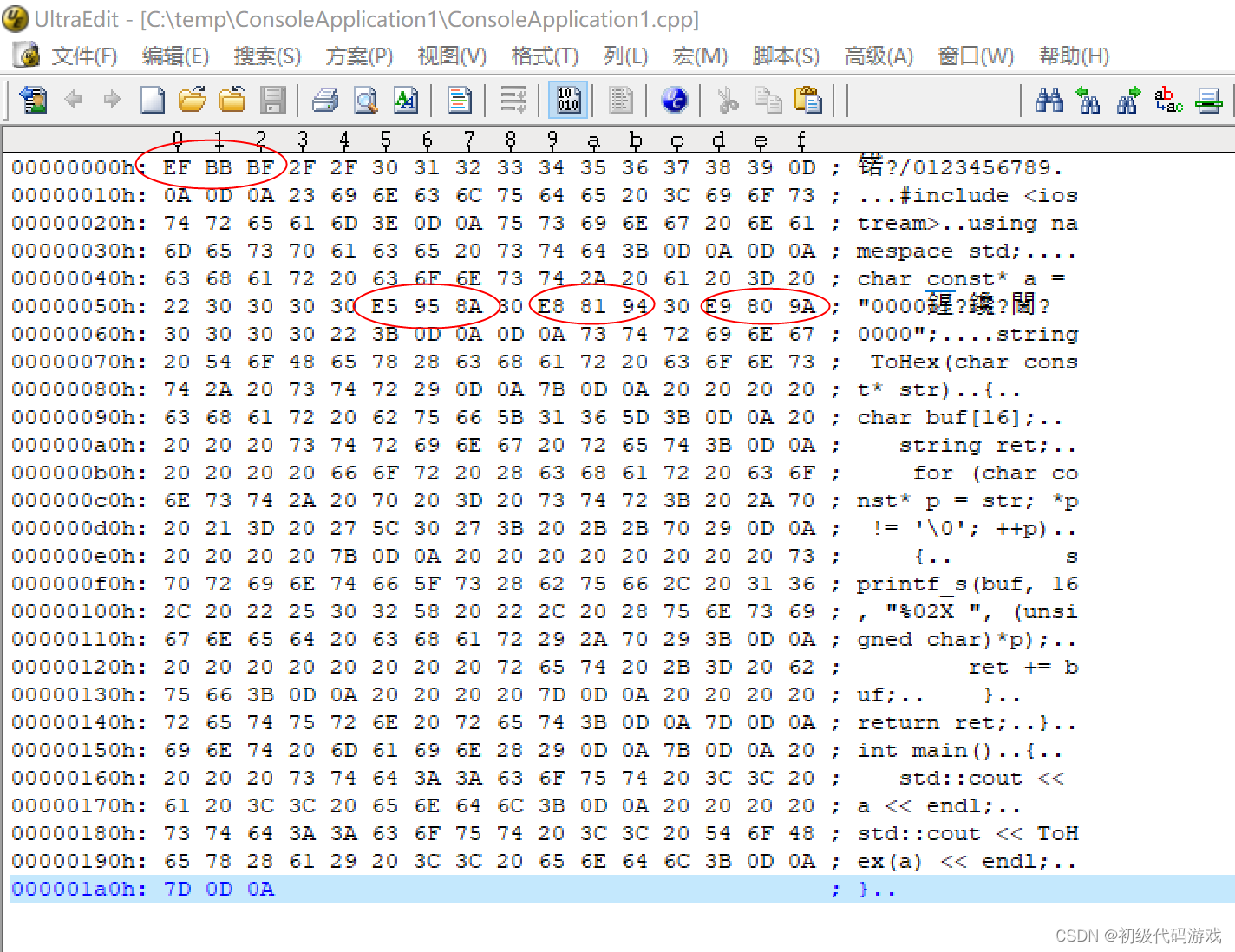
现在我们看到的文件有几处区别:文件开始处多了三个字节“EF BB BF”,这就是微软独创的UTF-8的BOM签名,三个中文字的编码变成了三字节,“啊”是“E5 95 8A”(GB2312是“B0 A1”)。其余英文字符没有变化,也就是说,如果不带签名且没有中文字符,UTF-8和ASCII是一样的。
重新编译运行程序:
0000啊0联0通0000
30 30 30 30 B0 A1 30 C1 AA 30 CD A8 30 30 30 30
C:\temp\ConsoleApplication1\x64\Debug\ConsoleApplication1.exe (进程 19336)已退出,代码为 0。
按任意键关闭此窗口. . .注意“啊”的编码仍然是GB2312的“B0 A1”,这说明不管源文件是什么编码,编译器都生成的是本地编码程序。
此时项目属性设置的是“使用UNICODE字符集”,这个属性只是增加一个宏定义,影响windows API中涉及到字符串的,比如MessageBox根据宏被分别定义到MessageBoxA或MessageBoxW,其实你也可以直接使用MessageBoxA和MessageBoxW。看一下MessageBox的声明就明白了(WinUser.h):
#ifdef UNICODE
#define MessageBox MessageBoxW
#else
#define MessageBox MessageBoxA
#endif // !UNICODE
3.5 UNICODE代码页1200
再将源代码文件设置为“UNICODE 代码页1200”:
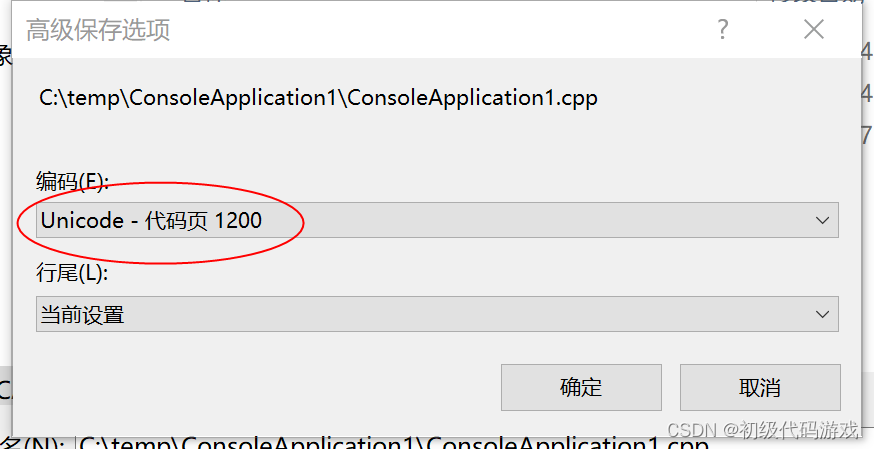
十六进制查看:
 这个文件一下子长了很多,有以下几个特点:文件开始处是“FF FE”,表示这是UTF-16LE,(LE、BE傻傻分不清?没所谓的,又不手写十六进制);每个英文字符都是两个字节,后一个字节是00;“啊”的编码是“4A 55”,和GB2312、UTF-8都不一样(“啊”的UNICODE点位是0x554A,UTF-16对小于0x10000的直接存储为两字节,文件里低字节在前、高字节在后就成了“4A55”,而UTF-8每个字节都有几个位有特殊用途,“啊”被拆成了三个字节)。
这个文件一下子长了很多,有以下几个特点:文件开始处是“FF FE”,表示这是UTF-16LE,(LE、BE傻傻分不清?没所谓的,又不手写十六进制);每个英文字符都是两个字节,后一个字节是00;“啊”的编码是“4A 55”,和GB2312、UTF-8都不一样(“啊”的UNICODE点位是0x554A,UTF-16对小于0x10000的直接存储为两字节,文件里低字节在前、高字节在后就成了“4A55”,而UTF-8每个字节都有几个位有特殊用途,“啊”被拆成了三个字节)。
重新编译执行,程序输出和之前一样,编译器还是把源码的UNICODE编码转换为了本地编码。
如果把文件存储为“UNICODE(Big-Endian)代码页1201”,则文件内容每两个字节互相交换。
注意这里文件是UTF-16,而程序仍然用的是char,这说明char还是wchat_t又是不同于字符集和字符编码的另外一个问题。
3.6 繁体中文Big5
把源文件另存为繁体中文Big5,会提示有些字符保存不了,不要管,强行保存了,然后查看十六进制内容:
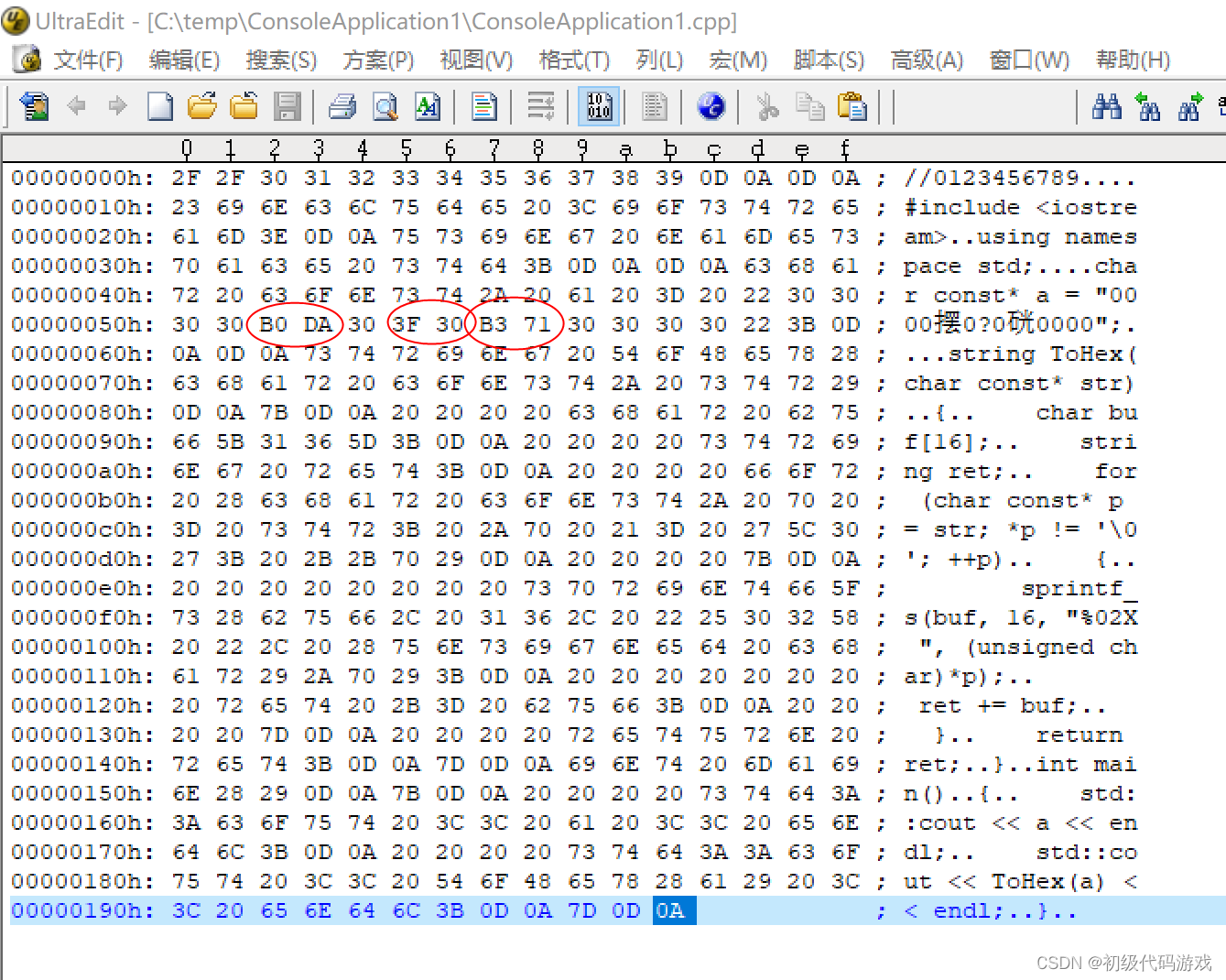
文件格式大致回到了跟GB2312差不多,区别是三个中文字符不一样,“啊”的Big编码是“B0DA”,这是正确的,后面“联”的位置是一个单独的3F,这应该就是保存不了的部分("联"在Big5里面真的没有对应字符)
重新编译运行程序:

壮观了!乱码! 程序应该是只会显示本地编码的,而BIG5被当成GB2312解释,当然乱了。
3.7 头文件编码不同会怎么样(UTF-8不带签名会乱码)
如果头文件编码不一样,会发生什么?我们来实测一下。
添加一个头文件ConsoleApplication1.h:
//啊 此行重要,用作编码识别
char const* a = "0000啊0联0通0000";
另存为UTF-8不带签名(不在列表最上面,需要在列表里面慢慢找)。
再将cpp文件替换为以下内容:
//啊 此行重要,用作编码识别
#include "ConsoleApplication1.h"
#include <iostream>
#include <fstream>
using namespace std;
string ToHex(char const* data, int count)
{
char buf[16];
string ret;
for (char const* p = data; p != data + count; ++p)
{
if (p!=data && 0 == (p - data) % 16)ret += "\n";
sprintf_s(buf, 16, "%02X ", (unsigned char)*p);//必须转换为无符号
ret += buf;
}
return ret;
}
string CheckEncoding(char const* finlename)
{
ifstream file;
file.open(finlename, ios::in | ios::binary);
file.seekg(0, ios::end);
int len = file.tellg();
constexpr int buflen = 17;
char buf[buflen];
//cout << finlename<<" 文件长度 " << len << endl;
if (len >= buflen)len = buflen - 1;
file.seekg(0, ios::beg);
file.read((char *)buf, len);
buf[len] = '\0';
file.close();
//cout << ToHex(buf, len) << endl;
bool hasZero = false;//有0,肯定不是多字节字符集或UTF-8
for (int i = 0; i < len; ++i)
{
if ('\0' == buf[i])
{
hasZero = true;
//cout << "有零" << endl;
break;
}
}
//注意字符的符号问题,默认是有符号的
if ('\xFE' == buf[0] && '\xFF' == buf[1])
{
return "UTF-16BE" ;
}
if ('\xFF' == buf[0] && '\xFE' == buf[1])
{
return "UTF-16LE";
}
if ('\xEF' == buf[0] && '\xBB' == buf[1] && '\xBF' == buf[2])
{
return "UTF-8BOM";
}
if ('\x2F' == buf[0] && '\x2F' == buf[1] && '\xE5' == buf[2] && '\x95' == buf[3] && '\x8A' == buf[4])
{
return "UTF-8 ";
}
if ('\x2F' == buf[0] && '\x2F' == buf[1] && '\xB0' == buf[2] && '\xA1' == buf[3])
{
return "GB2312 ";
}
}
int main()
{
char const* a_cpp = "0000啊0联0通0000";
cout << CheckEncoding("ConsoleApplication1.cpp") << " 源文件 [" << a_cpp << "] " << ToHex(a_cpp, strlen(a_cpp)) << endl;
cout << CheckEncoding("ConsoleApplication1.h") << " 头文件 [" << a << "] " << ToHex(a, strlen(a)) << endl;
return 0;
}
文件另存为UNICODE。这样两个文件编码是不一样的。
注意两个文件第一行都是以“//啊”开始的,CheckEncoding函数通过检查“啊”的编码来判断文件是UTF-8还是本地编码(所以这个函数没什么通用性)。
程序会输出两行,第一行是源文件的格式和源文件里的字符串,第二行是头文件的格式和头文件里的字符串。
编译运行程序:

现在可以看到,源文件的字符串没有乱码,程序里的编码是本地编码,头文件里的字符串是乱码,十六进制值也很奇怪,“啊”的UTF-8编码其实是“E5 95 8A”,前两个字节是一致的,后面就乱套了。
尝试几种不同的组合,最终会发现,问题根本不是源文件和头文件编码不同造成的,而是UTF-8不带签名造成的,只要是UTF-8不带签名,不管是源文件还是头文件,都会乱码。
3.8 记事本是什么编码?
在我的win10中文版上,记事本状态栏显示“UTF-8”,没有设置项,输入文字保存,查看十六进制,发现是不带签名的。够混乱吧。
4 一些案例
跨平台开发,在windows上用VS编写代码,上传到linux,运行程序,有些人乱码有些人不乱码。原因是源代码是GB2312的,linux上编译程序无所谓,反正就是个char *,终端显示的时候按照设置来显示文本,不同的人设置不一样,有些人设置的是utf-8(linux的默认值),所以就乱码了。这个设置可以是linux用户的设置,也可以在某些终端软件上设置。为了照顾linux的情绪一般就把源代码改为UTF-8不带签名,前面已经知道,这样的代码无法兼容windows,在windows上编译运行会乱码。
数据库,有些人乱码有些人不乱码,还是字符集设置问题,一般建议项目开始时就强制所有人使用相同的设置,不然有些地方是unicode有些是GB2312,数据已经进去,很难改,不得不来回切换设置。
所有一切的根源都在于混乱已经形成,文本本身无法表达自己的编码,也不可能再规定一个统一的方式表达编码。
(这里是文档结束)















 2481
2481











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









