






1.io流的顶级父类
字节输入流:以内存为基准,来自磁盘文件/网络中的数据以字节的形式读入到内存中去的流
字节输出流:以内存为基准,把内存中的数据以字节写出到磁盘文件或者网络中去的流。
字符输入流:以内存为基准,来自磁盘文件/网络中的数据以字符的形式读入到内存中去的流。
字符输出流:以内存为基准,把内存中的数据以字符写出到磁盘文件或者网络介质中去的流。
| 输入流 | 输出流 | |
|---|---|---|
| 字节流 | InputStream | OutputStream |
| 字符流 | Reader | Writer |
这四个类都是抽象类,不能直接使用,但是它们下面有很多子类可以供我们使用。
输入流和输出流名字的定义都是以程序为操作中心
将文件中的内容输入到程序中运行,对于程序而言这就是输入流;
将程序中的运行结果输出到文件中保存,对于程序而言这就是输出流。
 字符流的诞生就是为了解决乱码的问题,其余所有的文件类型字节流都可以操作。
字符流的诞生就是为了解决乱码的问题,其余所有的文件类型字节流都可以操作。
2.中文乱码的两个原因
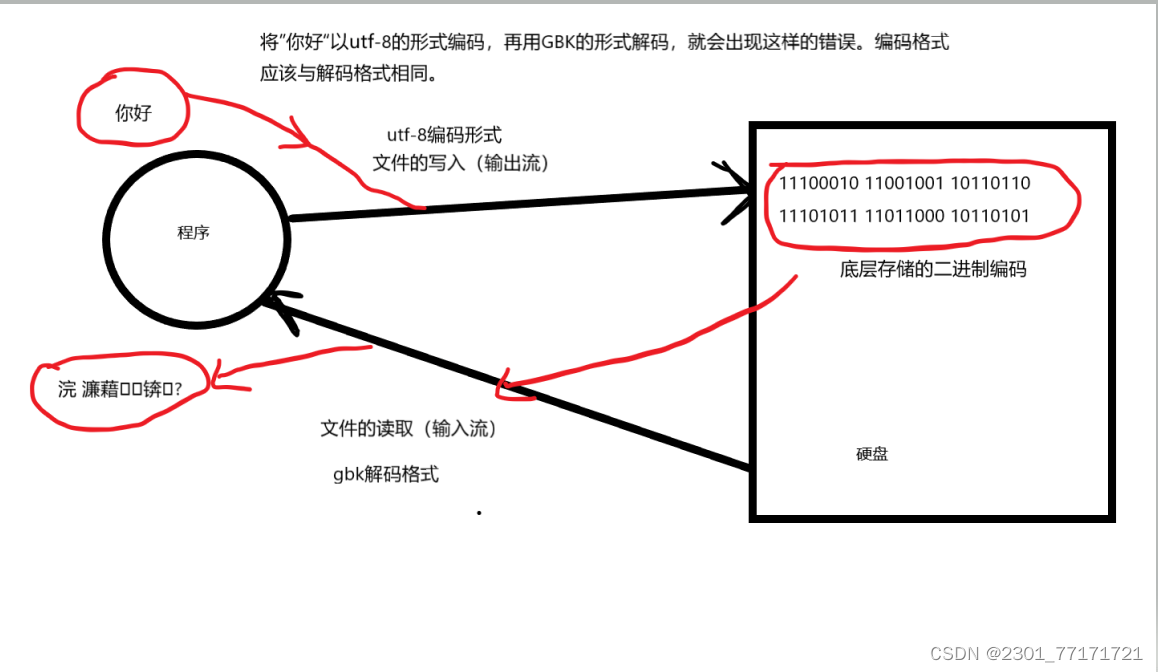
1.编码和解码不一致;
编码:程序在写入文件时,将文件的内容以二进制的方式保存到硬盘中,但是文件变成二进制有好几种不同的方式,这就是编码。采用不同的编码方式,得到的二进制也会不同,例如:GBK编码方式中,一个中文是两个字节,而UTF-8编码方式,一个中文是用三个字节进行保存,“我们“这个中文采取这两种不同的编码格式,得到的二进制也会不同,所以用一个编码格式编码,也要用同一种编码格式解码
解码:读取文件时,系统底层会将存储在硬盘上的文件二进制流输入到程序中,这个时候程序要按照指定的解码格式,才能读取到文件的内容。假如文件保存时编码格式是GBK,文件在硬盘上为GBK形式的二进制编码方式,但是在读取这段二进制以UTF-8的形式读取,它就会按照UTF-8的形式将这个二进制解析出来,结果就会出错,出现乱码的形式
2.一次性读取字节个数的问题
来看看下面的代码a.txt文件中的内容是:你好啊,我是小太阳!
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class Test01 {
public static void main(String[] args) throws IOException {
int len=0;
File file=new File("E:\\javaTest\\a.txt");
//创建了输入字节流
FileInputStream read=new FileInputStream(file);
byte[] b=new byte[1024];
while((len=read.read())!=-1){
//你好,我是小太阳!
System.out.print(new String(b,0,len));
}
read.close();
}
}//第二段代码
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class Test01 {
public static void main(String[] args) throws IOException {
int len=0;
File file=new File("E:\\javaTest\\a.txt");
//创建了输入字节流
FileInputStream read=new FileInputStream(file);
int b=0;
while((b=read.read())!=-1){
//会出现中文乱码的现象,如果文件中有中文,就要用字符流来读取文件FileReader
System.out.print((char)b);//ä½ å¥½åï¼ææ¯å°å¤ªé³ï¼
}
read.close();
}
}这是什么原因呢?
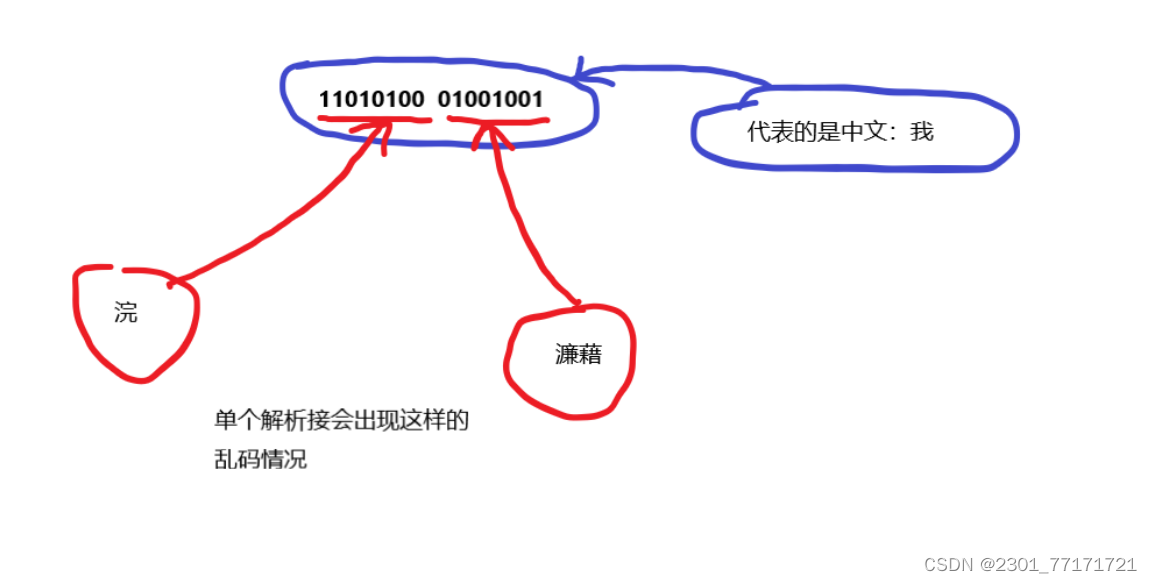
中文编码时,一般一个中文占两到三个字节(这里就默认为两个字节),要将这两个字节一起解析才会得到正确的中文。但是在第二段代码中是一个一个字节地读取,那么这两个字节就会拆开来读取解析,就不会得到正确的中文
这就是如下的示意图:
为什么说第一段代码在中文较多的文件下也会出现乱码呢?
使用FileInputStream每次读取多个字节,读取性能得到了提升,但读取汉字输出还是会乱码
第一段代码一次只能读取1024个字节,当一个中文二进制码的第一个字节为在字节数组中是b[1023],第二个字节就会出现会在下一组的b[0],这就会在末尾出现乱码,并且会影响到下一组字节数组的解析
1.使用字节流读取中文,如何保证输出不乱码,怎么解决?
定义一个与文件一样大的字节数组,一次性读取完文件的全部字节,但是这样很麻烦。
2.直接把文件数据全部读取到一个字节数组可以避免乱码,是否存在问题?
如果文件过大,创建的字节数组也会过大,可能引起内存溢出
java中的io流乱码的问题解决代码,我会后续更新,此次主要讲清楚原理!了解底层运作!















 241
241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









