






需要实现先准备两个不同xlsx文件表格(有例子)和粗大数字照片(有例子),并且加到根目录下
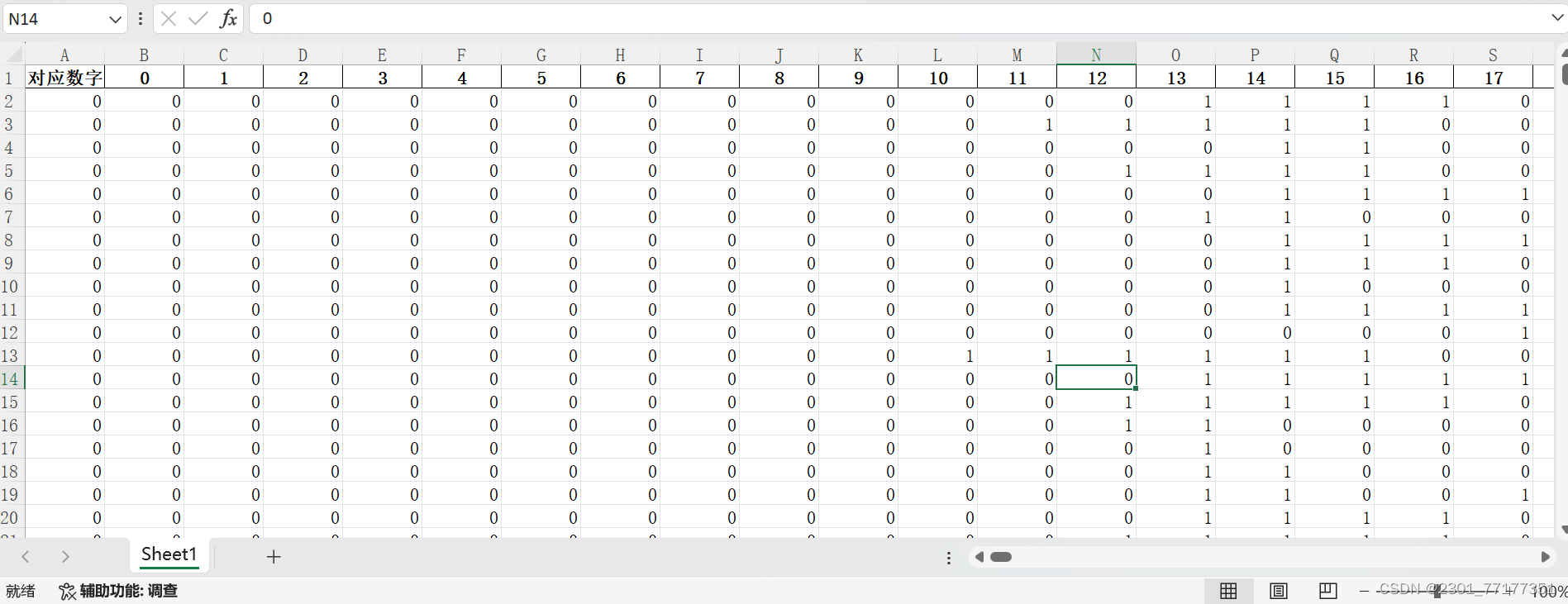
import pandas as pd
df = pd.read_excel('手写字体识别.xlsx')
df.head()
#提取特征变量和目标变量
X = df.drop(columns='对应数字')
y = df['对应数字']
#划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123) # 设置random_state使得每次划分的数据一样
from sklearn.neighbors import KNeighborsClassifier as KNN
knn=KNN(n_neighbors=4)
knn.fit(X_train,y_train)
y_pred=knn.predict(X_test.values) #报错才加'.values'
print(y_pred[0:100])
a=pd.DataFrame()
a['预测值']=list(y_pred)
a['实际值']=list(y_test)
a.head()
#用于评分
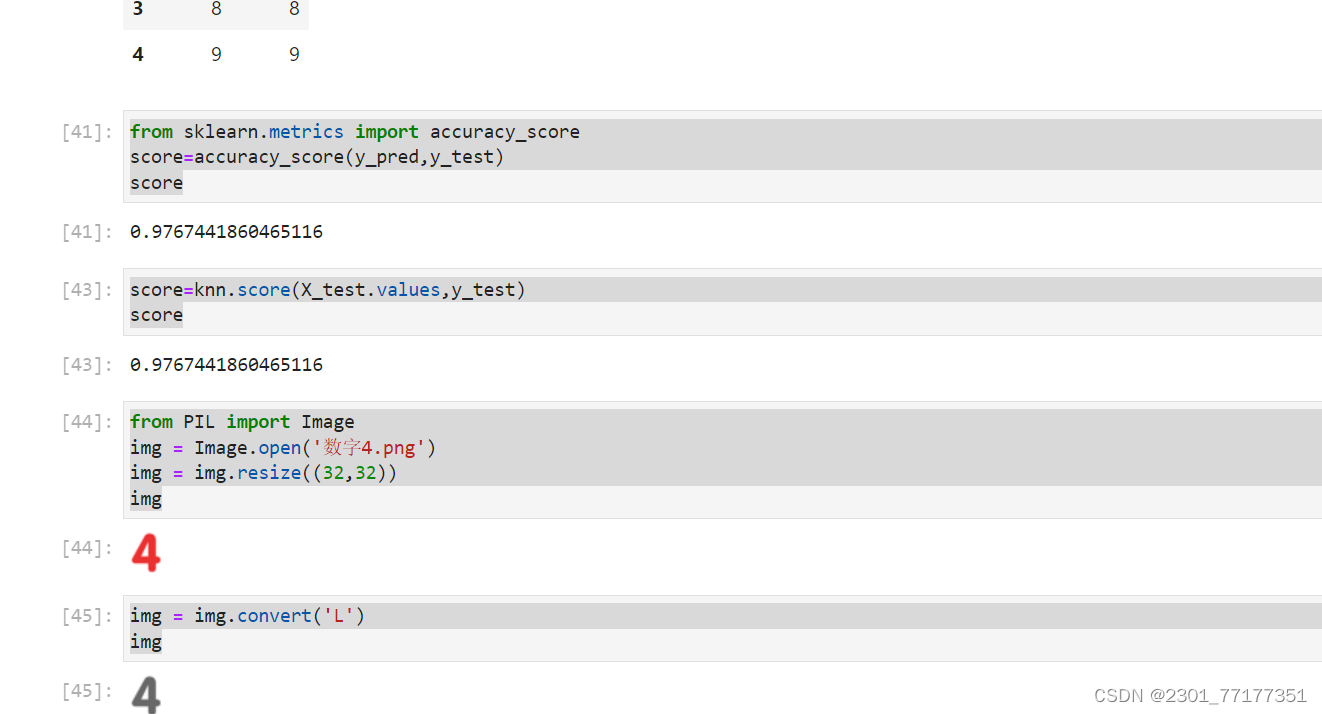
from sklearn.metrics import accuracy_score
score=accuracy_score(y_pred,y_test)
score
#也用于评分,这个是系统自带的
score=knn.score(X_test.values,y_test)
score实操照片
文件
代码


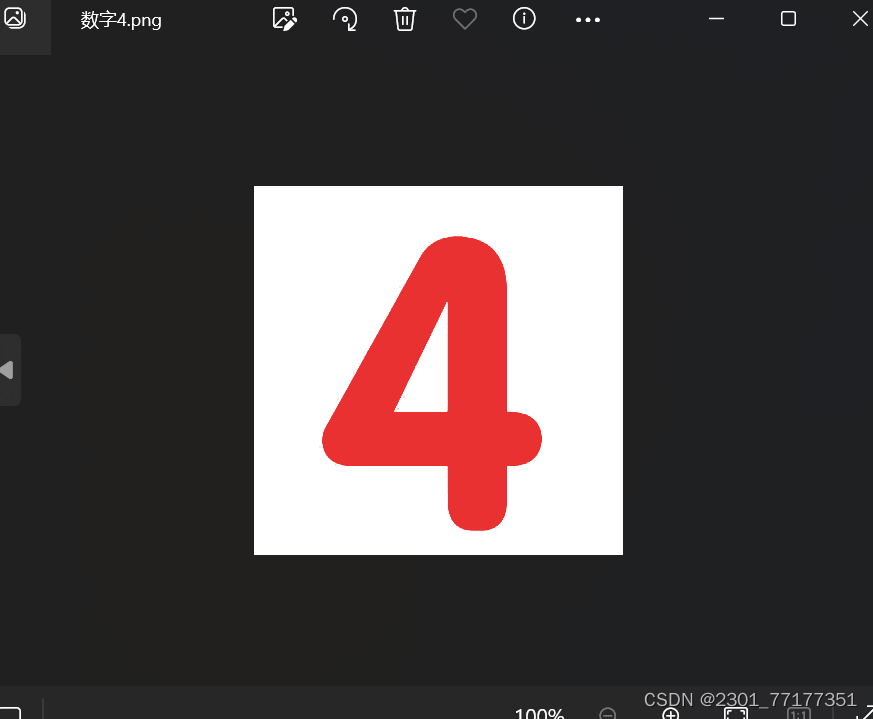
from PIL import Image
img = Image.open('数字4.png')
img = img.resize((32,32))
img
img = img.convert('L')
img
import numpy as np
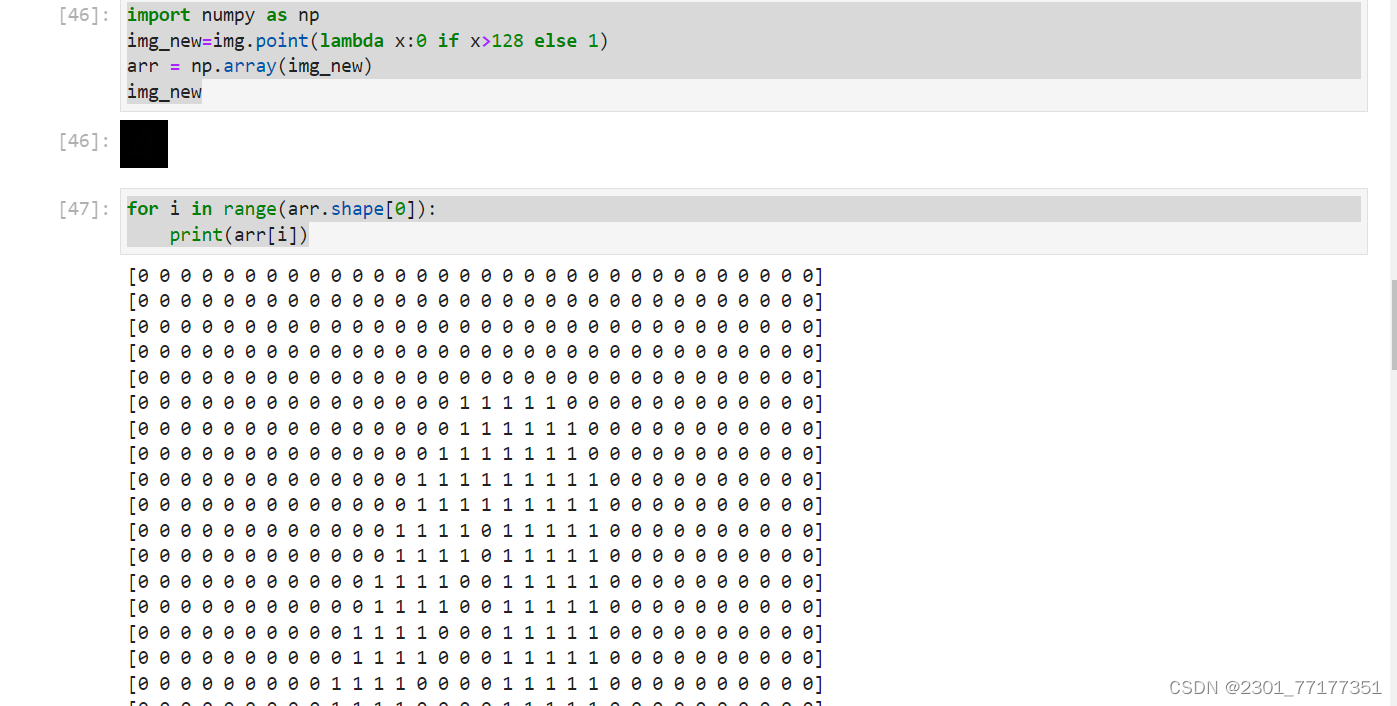
img_new=img.point(lambda x:0 if x>128 else 1)
arr = np.array(img_new)
img_new
for i in range(arr.shape[0]):
print(arr[i])
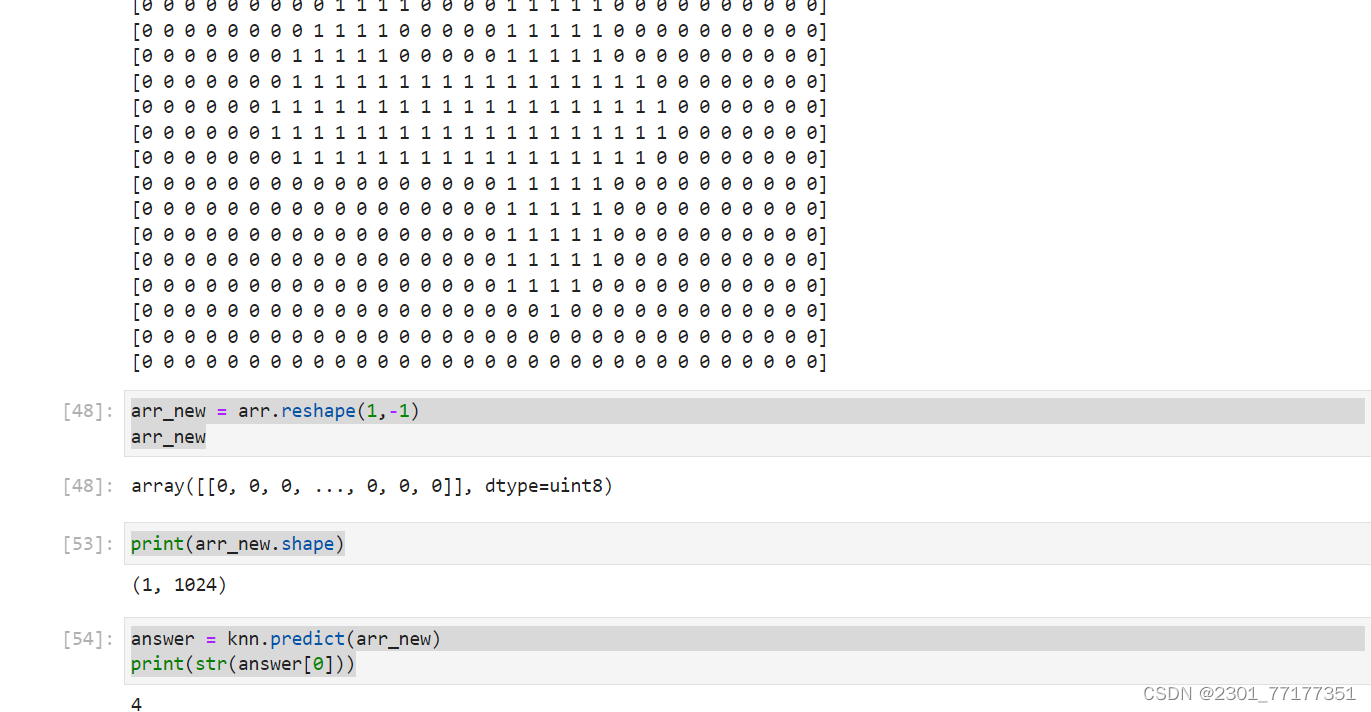
arr_new = arr.reshape(1,-1)
arr_new
print(arr_new.shape)
answer = knn.predict(arr_new)
print(str(answer[0]))
X=[[1,0],[5,1],[6,4],[4,3],[5,2]]
y=[0,1,1,0,0]
from sklearn.neural_network import MLPClassifier
mlp = MLPClassifier()
mlp.fit(X,y)
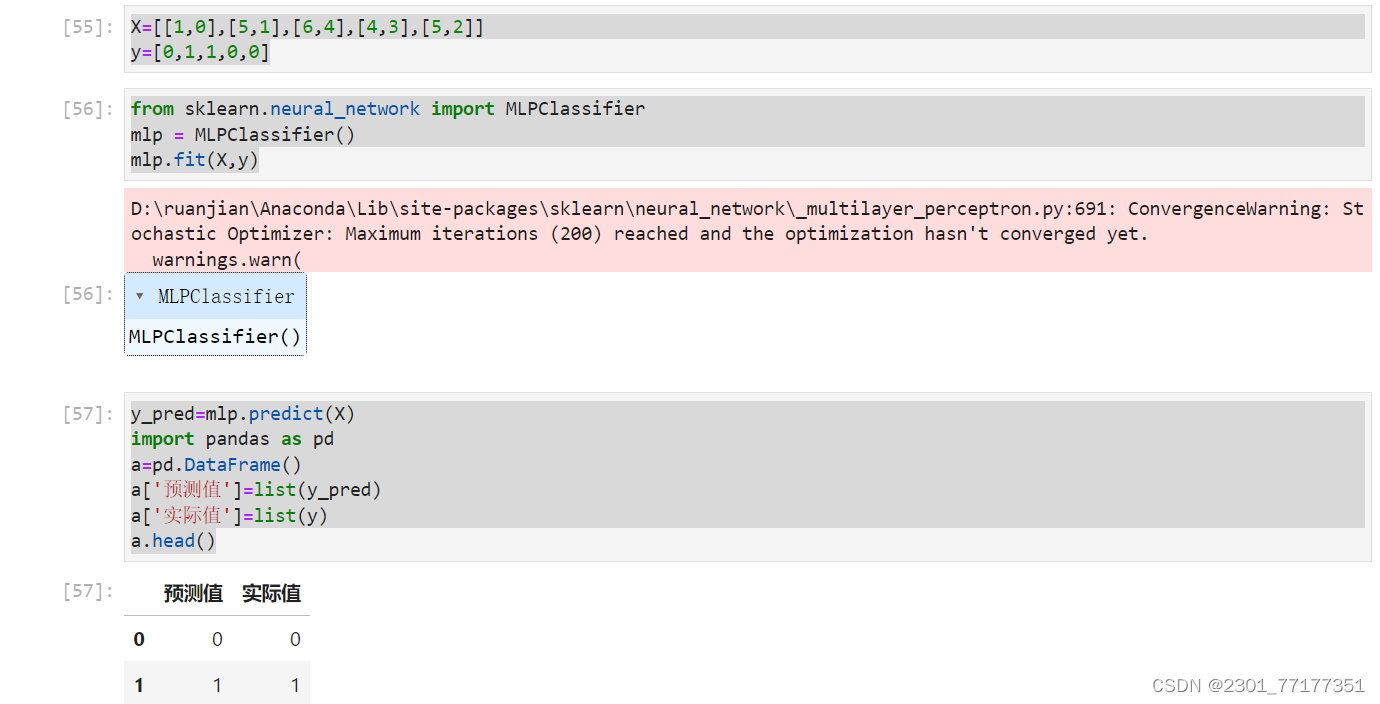
y_pred=mlp.predict(X)
import pandas as pd
a=pd.DataFrame()
a['预测值']=list(y_pred)
a['实际值']=list(y)
a.head()
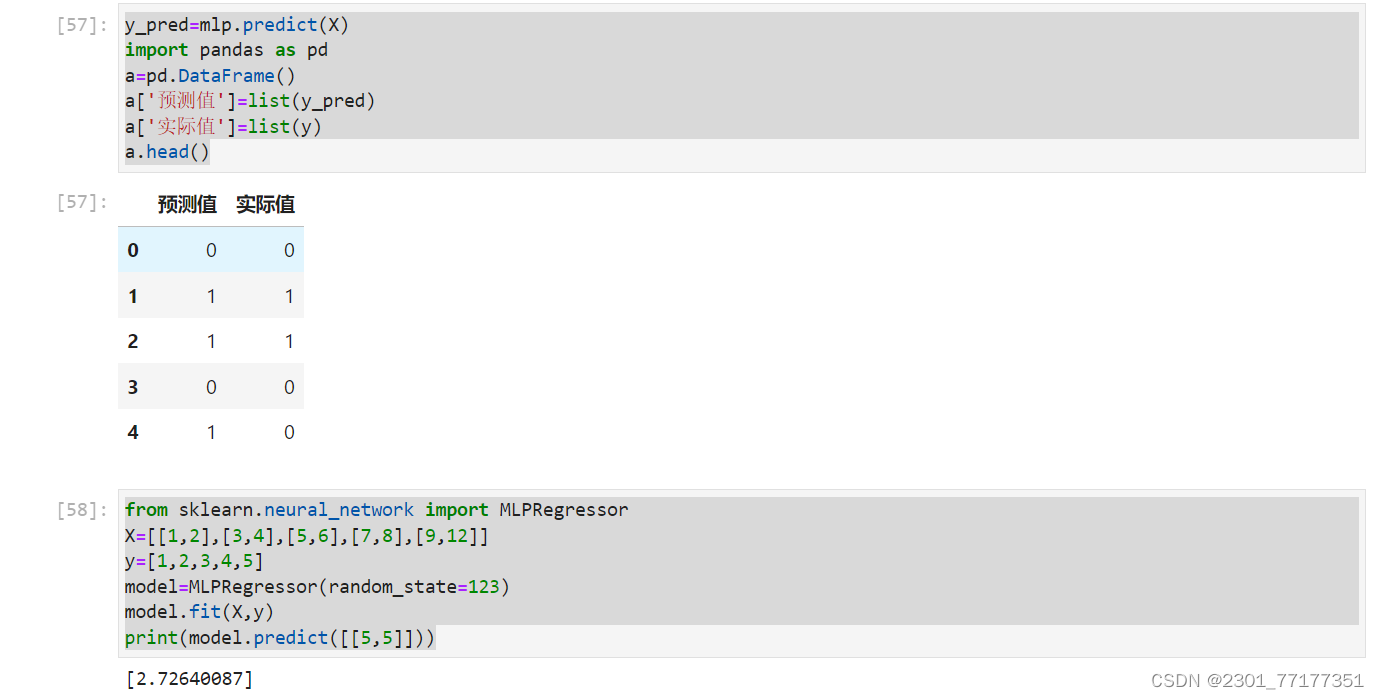
from sklearn.neural_network import MLPRegressor
X=[[1,2],[3,4],[5,6],[7,8],[9,12]]
y=[1,2,3,4,5]
model=MLPRegressor(random_state=123)
model.fit(X,y)
print(model.predict([[5,5]]))实操照片
图片
代码
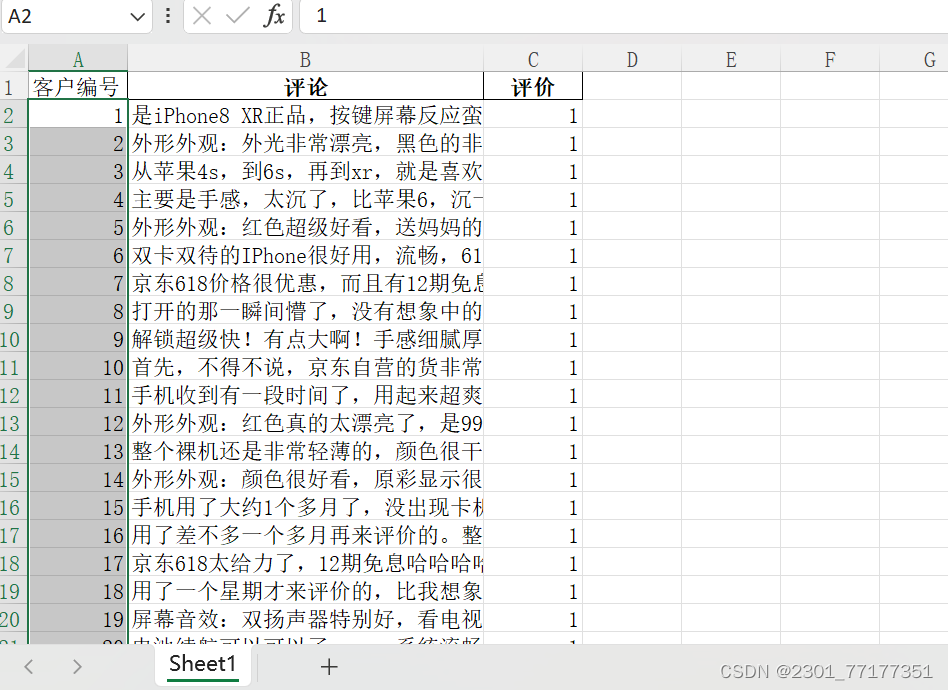
import pandas as pd
df = pd.read_excel('产品评价.xlsx')
df.head()
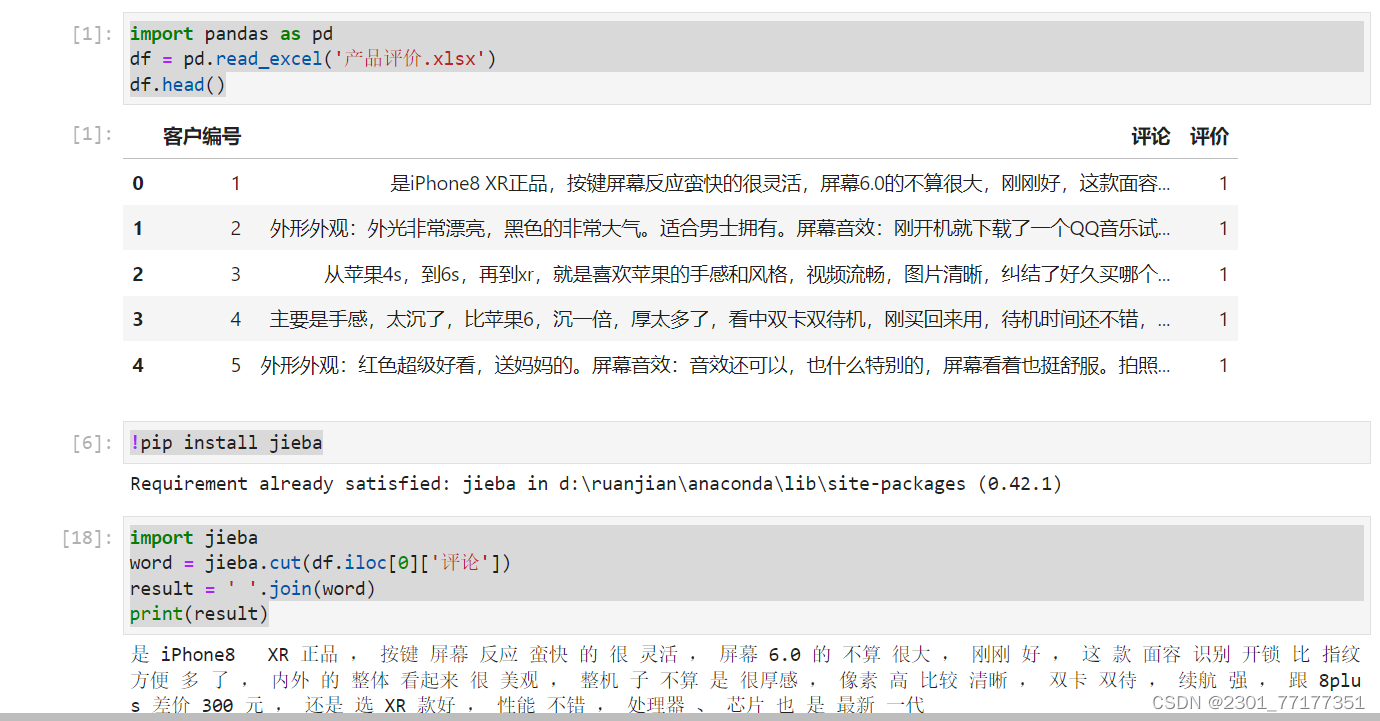
!pip install jieba #用于下载jieba插件
import jieba
word = jieba.cut(df.iloc[0]['评论'])
result = ' '.join(word)
print(result)
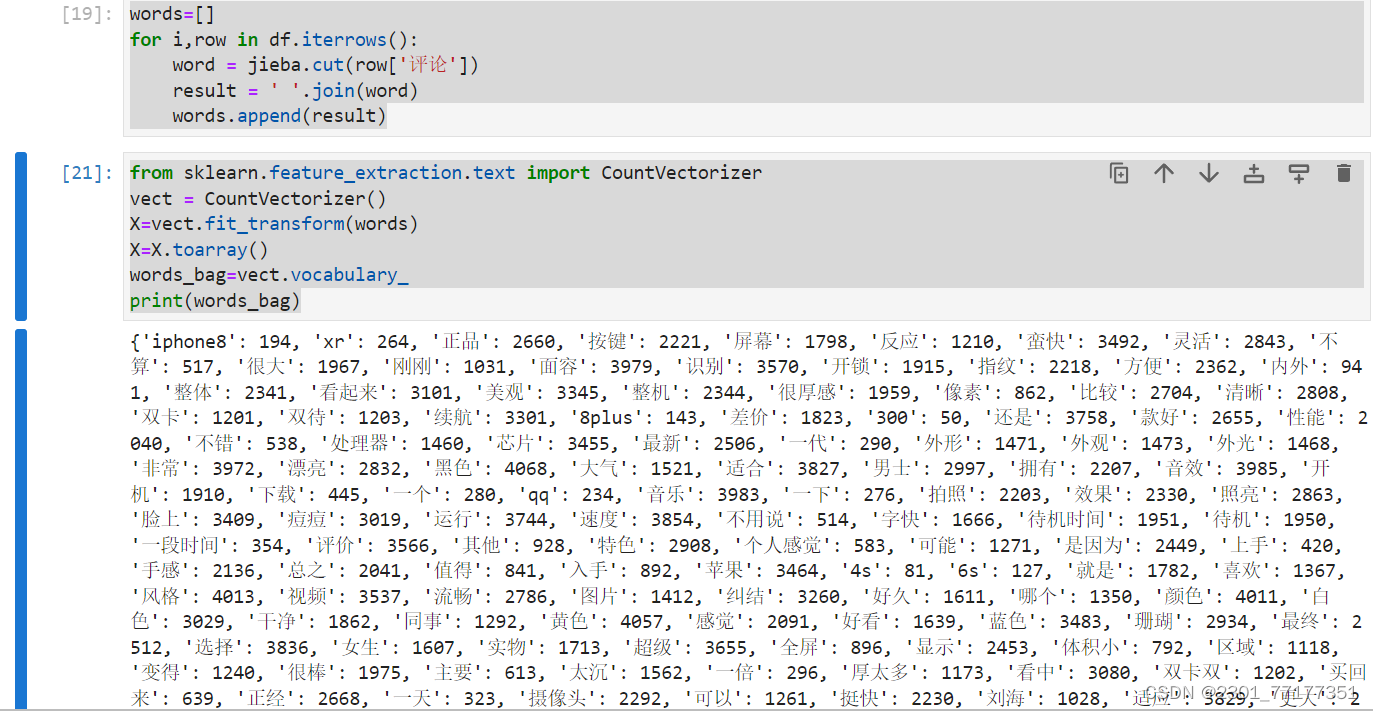
words=[]
for i,row in df.iterrows():
word = jieba.cut(row['评论'])
result = ' '.join(word)
words.append(result)
from sklearn.feature_extraction.text import CountVectorizer
vect = CountVectorizer()
X=vect.fit_transform(words)
X=X.toarray()
words_bag=vect.vocabulary_
print(words_bag)
len(words_bag)
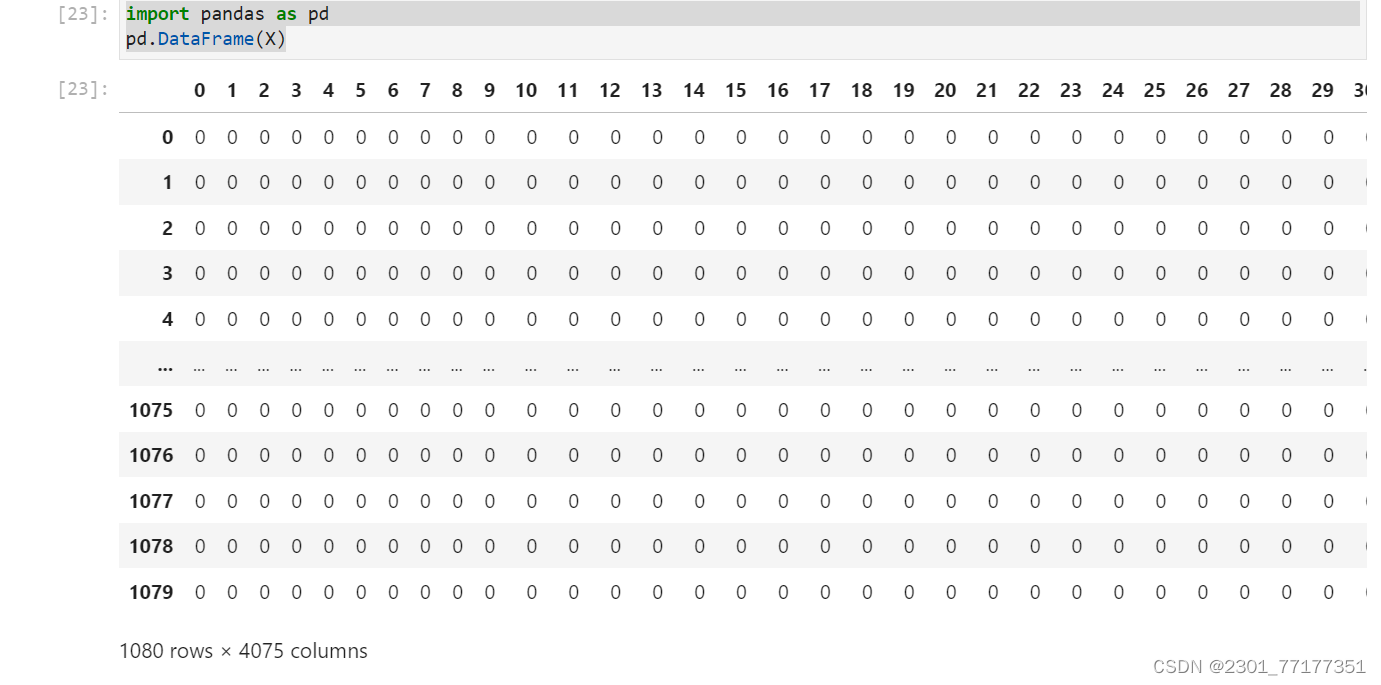
import pandas as pd
pd.DataFrame(X)
pd.set_option('display.max_columns',None)
pd.set_option('display.max_rows',None)
pd.DataFrame(X)
y=df['评价']
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
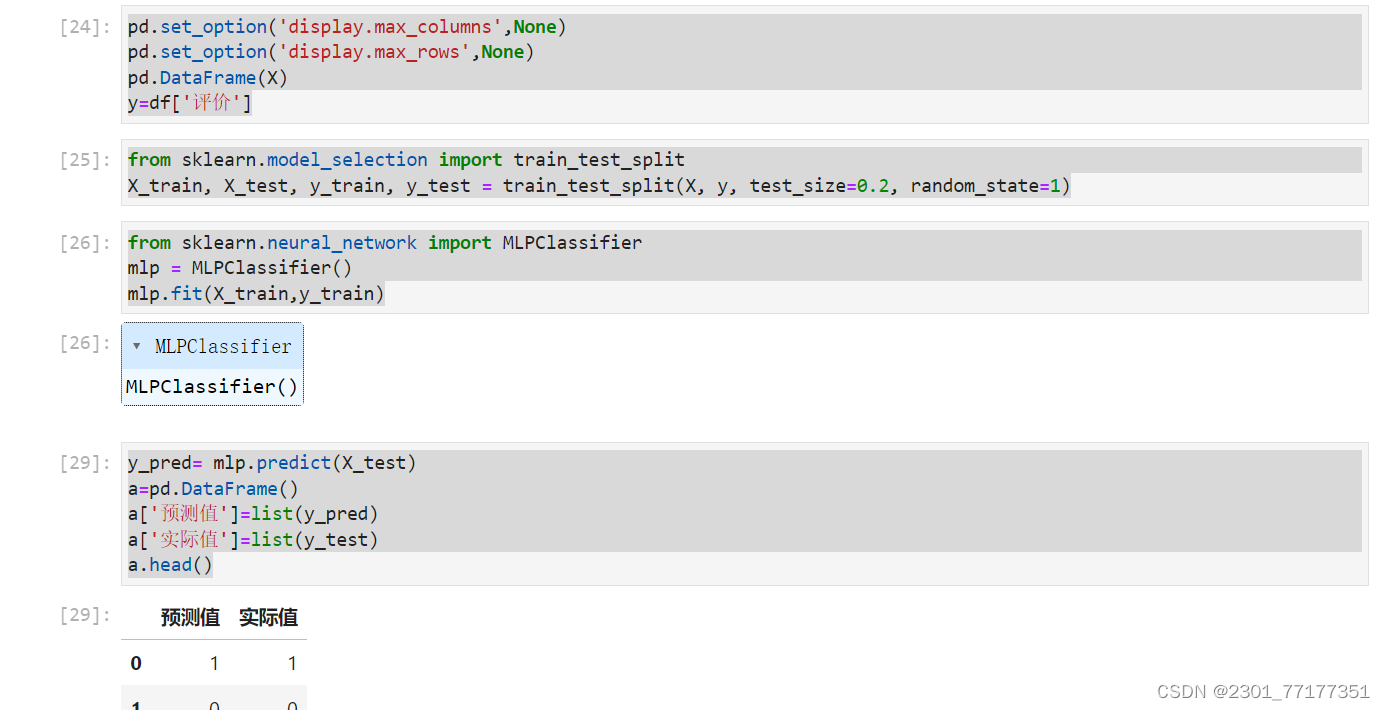
from sklearn.neural_network import MLPClassifier
mlp = MLPClassifier()
mlp.fit(X_train,y_train)
y_pred= mlp.predict(X_test)
a=pd.DataFrame()
a['预测值']=list(y_pred)
a['实际值']=list(y_test)
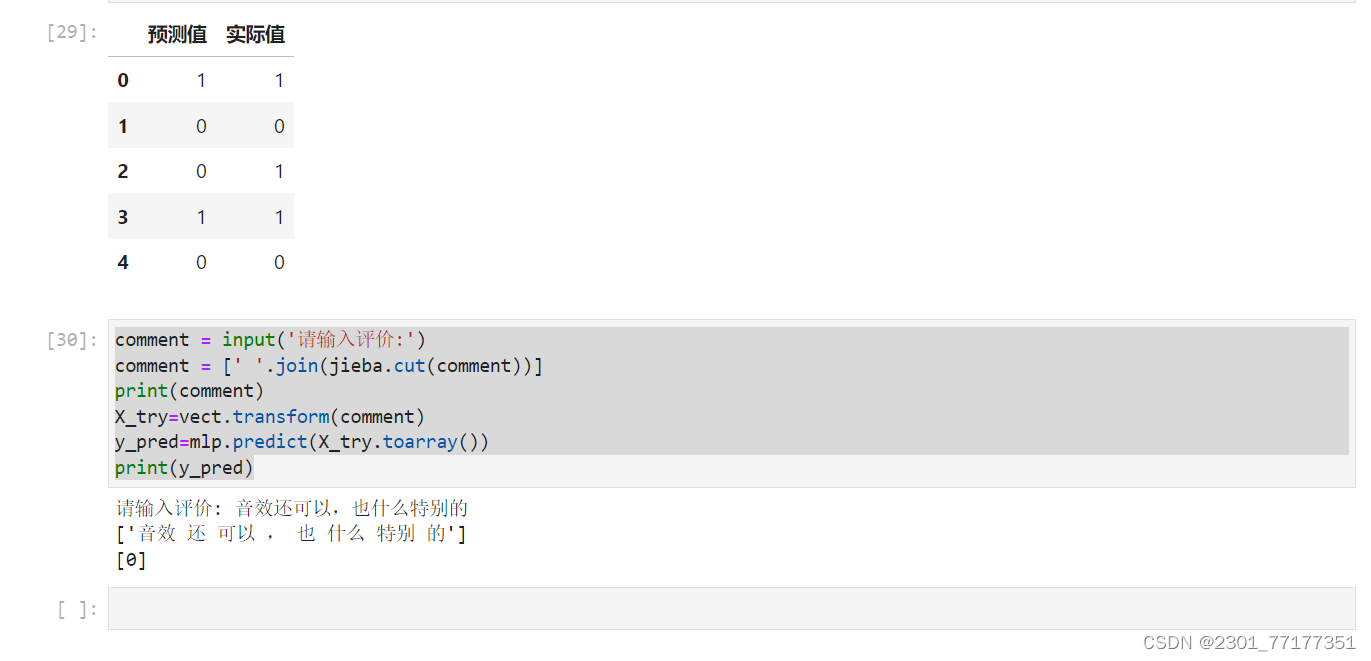
a.head()
comment = input('请输入评价:')
comment = [' '.join(jieba.cut(comment))]
print(comment)
X_try=vect.transform(comment)
y_pred=mlp.predict(X_try.toarray())
print(y_pred)实操照片
文件
代码

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









