






第1关:Numpy的排序和条件筛选
任务描述
本关任务:掌握numpy的排序方法,并编写一个能筛选并排序的程序。
相关知识
说到排序想必你的脑海中会想到快速排序、插入排序、冒泡排序、选择排序等复杂的排序算法,所有的这些算法都是为了实现一个任务 —— 排序。
庆幸的是在Python中已经封装了排序的函数,不需要我们再去造轮子了。
numpy中的快速排序
numpy中的排序相对Python的更加高效,默认情况下np.sort的排序算法是 快速排序,也可以选择 归并排序 和 堆排序。
类型 速度 最坏情况 工作空间 稳定性
快速排序 1 O(n^2) 0 否
归并排序 2 O(nlog(n)) ~n/2 是
堆排序 3 O(nlog(n)) 0 否
np.sort()函数返回排序后的数组副本,只能是升序。
a=np.array([5,9,1,15,3,10])
np.sort(a) #升序排序
'''
输出:array([ 1, 3, 5, 9, 10, 15])
'''
np.argsort()函数返回排序后数组值从小到大的索引,可以通过这些索引值创建有序的数组。
a=np.array([4,5,9,1,3])
b=np.argsort(a) #对a使用argsort函数
print(b)
'''
输出:array([3, 4, 0, 1, 2], dtype=int64)
第一个数是最小的值的索引,第二个数是第二小的值的索引,以此类推
'''
b1=[]
for i in b: #循环获取索引对应的值
b1.append(a[i])
print(b1)
'''
输出:[1, 3, 4, 5, 9]
'''
沿行或列进行排序,通过axis参数实现对数组的行、列进行排序,这种处理是将行或列当作独立的数组,任何行或列的值之间的关系将会丢失。
a=np.array([[8,1,5,9],[5,4,9,6],[7,1,5,3]])
np.sort(a,axis=1) #沿行排序
'''
输出:array([[1, 5, 8, 9],
[4, 5, 6, 9],
[1, 3, 5, 7]])
'''
np.sort(a,axis=0) #沿列排序
'''
输出:array([[5, 1, 5, 3],
[7, 1, 5, 6],
[8, 4, 9, 9]])
'''
np.partition()函数为给定一个数,对数组进行分区,区间中的元素任意排序。
a=np.array([8,9,2,3,1,6,4])
np.partition(a,5) #比5小的在左边,比5大的在右边
'''
输出:array([1, 3, 2, 4, 6, 8, 9])
'''
其他排序函数:
函数 描述
msort() 数组按第一个轴排序,返回排序后的数组副本
sort_complex() 对复数按先实部后虚部的顺序进行排序
argpartition() 通过关键字指定算法沿指定轴进行分区
where函数
np.where() 函数返回输入数组中满足给定条件的元素的索引,可以利用该函数进行 条件筛选。
a=np.array([19,5,16,22,17])
np.where(a>15) #应用where函数
'''
输出:(array([0, 2, 3, 4], dtype=int64),)
'''
a[np.where(a>15)] #获取满足条件索引的元素
'''
输出:array([19, 16, 22, 17])
'''
编程要求
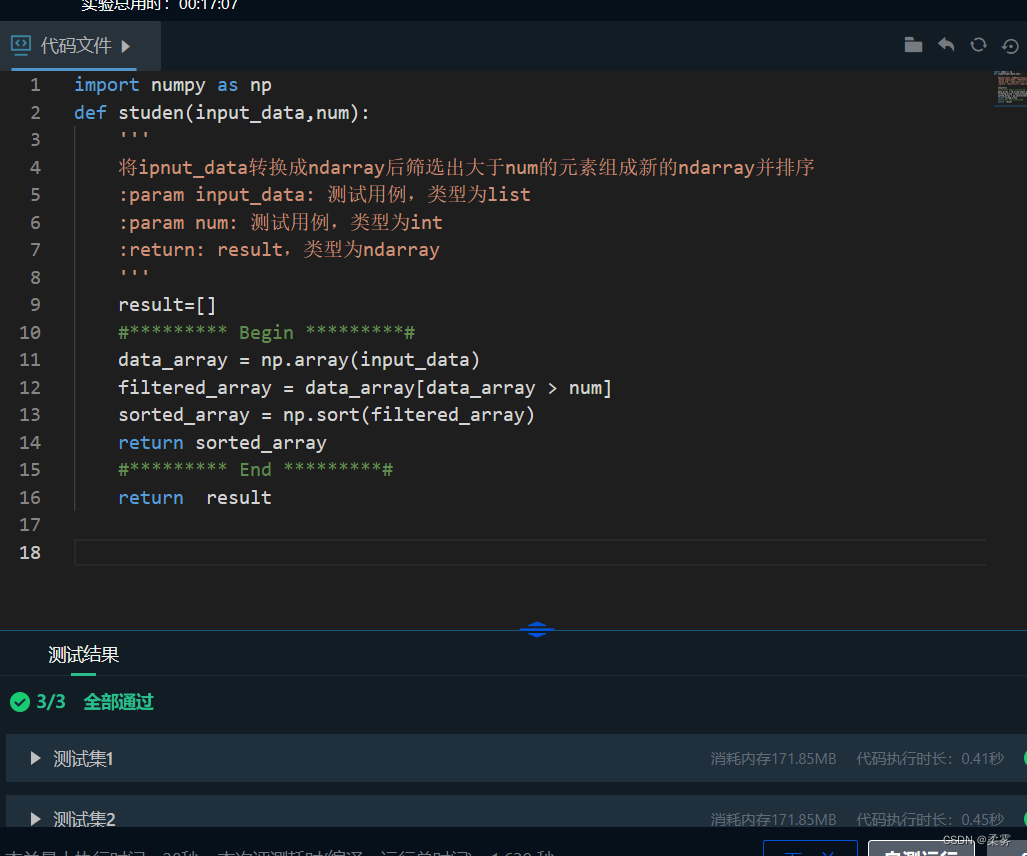
请在右侧编辑器Begin-End处补充代码,先过滤数组中大于num的值,再对这些值进行排序。
具体要求请参见后续测试样例。
请先仔细阅读右侧上部代码编辑区内给出的代码框架,再开始你的编程工作!
测试说明
平台会对你编写的代码进行测试,对比你输出的数值与实际正确的数值,只有所有数据全部计算正确才能进入下一关。
测试输入:
[[55, 110, 20, 1, 34, 0, 69],[9,21,33,68,16,71,80]]
66
预期输出:
[ 68 69 71 80 110]
示例代码如下:
import numpy as np
def studen(input_data,num):
'''
将ipnut_data转换成ndarray后筛选出大于num的元素组成新的ndarray并排序
:param input_data: 测试用例,类型为list
:param num: 测试用例,类型为int
:return: result,类型为ndarray
'''
result=[]
#********* Begin *********#
data_array = np.array(input_data)
filtered_array = data_array[data_array > num]
sorted_array = np.sort(filtered_array)
return sorted_array
#********* End *********#
return result
第2关:Numpy的结构化数组
任务描述
本关任务:掌握numpy的结构化数组,并通过读取文件内容转换结构化数组操作。
相关知识
有的时候通过异构类型值组成的数组无法完全的表示我们的数据,这时候就需要numpy的结构化数组,它是复合的,异构的数据提供了非常有效的存储。
结构化数组
结构化数组其实就是ndarrays,其数据类型是由组成一系列命名字段的简单数据类型组成的,在定义结构化数据时需要指定数据类型。
构建结构化数组的数据类型有多种制定方式,如字典、元组列表:
a=np.array([(b’Rex’, 9, 81.), (b’Fido’, 7, 77.)],
dtype=[(‘name’, ‘<S10’), (‘age’, ‘<i4’), (‘score’, ‘<f4’)]) #通过字典定义数据类型
a=np.array([(b’Rex’, 9, 81.), (b’Fido’, 7, 77.)],dtype={‘names’😦“name”,“age”,“score”),“formats”😦“<S10”,“<i4”,“<f4”)}) #通过元组定义数据类型
print(a)
‘’’
两种方式结果都是一样的
输出:array([(b’Rex’, 9, 81.), (b’Fido’, 7, 77.)],
dtype=[(‘name’, ‘<S10’), (‘age’, ‘<i4’), (‘score’, ‘<f4’)])
‘’’
上面案例中的S10表示“长度不超过10的字符串”,i4表示“4个字节整型”,f4表示“4字节浮点型”。
numpy的数据类型如下:
数据类型 描述 示例
b 字节型 np.dtype(‘b’)
i 有符号整型 np.dtype(‘i4’)==np.int32
u 无符号整型 np.dtype(‘u’)==np.uint8
f 浮点型 np.dtype(‘f8’)==np.int64
c 复数浮点型 np.dtype(‘c16’)==np.complex128
S、a 字符串 np.dtype(‘SS’)
U Unicode字符串 np.dtype(‘U’)==np.str_
V 原生数据 np.dtype(‘V’)==np.void
通过文件构造结构化数组
numpy通过loadtxt()函数读取文件内容,假设有以下文件内容,需要读取文件构造结构化数组:
name age score
amy 11 70
kasa 10 80
baron 9 66
a=np.loadtxt(“data.txt”,skiprows=1,dtype=[(“name”,“S10”),(“age”,“int”),(“score”,“float”)]) #读取文件并设置数据类型,其中skiprows为跳过第一行
print(a)
‘’’
输出:[(b’amy’, 11, 70.) (b’kasa’, 10, 80.) (b’baron’, 9, 66.)]
‘’’
结构化数组常规操作
结构化数组的方便之处在于,你可以通过索引或名称查看相应的值,并且可以进行快速的数据处理。
a=np.array([(b’Rex’, 10, 81.), (b’Fido’, 7, 77.),(b’kasr’, 9, 55.)],
dtype=[(‘name’, ‘S10’), (‘age’, ‘<i4’), (‘score’, ‘<f4’)]) #构造结构化数组
print(a[0]) #查看第一行
‘’’
输出:(b’Rex’, 10, 81.)
‘’’
print(a[“age”]>=10) #查看是否有大于等于10岁的
‘’’
输出:[True False False]
‘’’
print(a[“score”]<60) #查看是否有小于60的
‘’’
输出:[False False True]
‘’’
print(a[a[“age”]>=10]) #查看大于等于10岁的信息
‘’’
输出:[(b’Rex’, 10, 81.)]
‘’’
print(a[a[“score”]<60][“name”]) #查看小于60的人的姓名
‘’’
输出:[b’kasr’]
‘’’
注意:尽管这里列举的模式对于简单的操作非常有用,但是这些操作场景也可以用pandas的DataFrame来实现,并且DataFrame更加强大。
编程要求
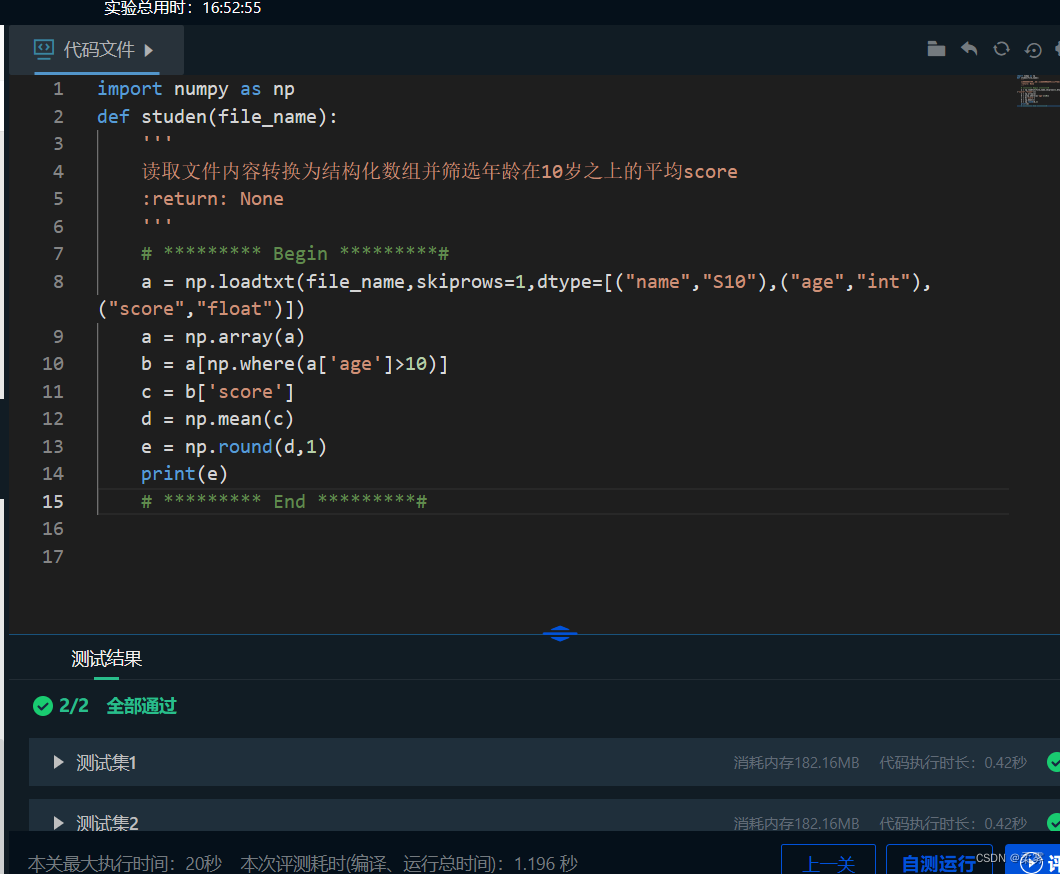
请在右侧编辑器Begin-End处补充代码,读取def studen(file_name)函数中file_name文件的内容,将其转换为结构化数组并筛选年龄在10岁之上的平均score,要求结果保留一位小数位即可。
file_name文件的 格式如下(数据并非下表中展示数据):
name age score
Emma 11 70
Edith 12 80
具体要求请参见后续测试样例。
请先仔细阅读右侧上部代码编辑区内给出的代码框架,再开始你的编程工作!
测试说明
平台会对你编写的代码进行测试,对比你输出的数值与实际正确的数值,只有所有数据全部计算正确才能进入下一关。
测试输入:
Task2/data.txt
预期输出:
75.7
示例代码如下:
import numpy as np
def studen(file_name):
'''
读取文件内容转换为结构化数组并筛选年龄在10岁之上的平均score
:return: None
'''
# ********* Begin *********#
a = np.loadtxt(file_name,skiprows=1,dtype=[("name","S10"),("age","int"),("score","float")])
a = np.array(a)
b = a[np.where(a['age']>10)]
c = b['score']
d = np.mean(c)
e = np.round(d,1)
print(e)
# ********* End *********#















 9071
9071

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









