







欢迎来到博主的专栏——c++编程
博主ID:代码小豪
前言
博主目前的水平还不能很明确的描述allocator(空间配置器)的作用和行为,因此在模拟实现vector模板的时候不会模拟实现allocator。但是会尽可能的模拟vector常用的行为以及迭代器原理。
本博客模拟实现的vector参考了SGI版本的STL库,如果大家想要STL的源码,可以私信博主。
vector的模拟实现
vector是一个顺序表的数据结构,因此STL为vector设计插入,删除等顺序表常用的操作,由于篇幅原因,博主不会详细的介绍这些操作使用的算法原理,毕竟重点在于vector模板的模拟实现,目的在于让大家对vector的使用更加得心应手,而且对泛型编程可以有更多的理解。
vector的成员对象
如果你对顺序表的数据结构非常了解,那么你大概会认为vector当中的成员至少有以下三种:
(1)管理资源的指针
(2)表示元素个数的size
(3)表示容量的capacity
template<class T>
class vector
{
T* vals;//管理资源的指针
size_t size;//表示元素个数的size
size_t capacity;///表示容器容量的capacity
};
实际上用这三个成员来模拟实现一个vector模板也是可行的,但是SGI版本的STL源码使用了更为精妙的方式。我们不再需要使用抽象的下标size和capacity来观察顺序表的使用状况,而是使用了三个vector模板生成迭代器分别指向顺序表的三个位置:表头,表尾,存储空间的末尾。
class vector
{
template<class T>
typedef T value_type;
typedef value_type* iterator;
typedef const value_type* const_iterator;
private:
iterator _start=nullptr;//表头
iterator _finish=nullptr;//表尾
iterator _end_of_storage=nullptr;//存储空间的末尾
};
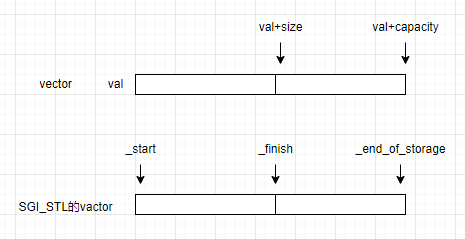
但如果你打开c++在线文档查查,可以发现c++标准当中是设计了size()和capacity()这两个接口来返回vector对象的元素个数个容量大小的。但是我们的vector的成员是三个迭代器,如果让迭代器体现出vector的size和capacity呢?
我们观察上图,可以发现一个规律,如果让_finish - _start,得到的值就是size,如果让_end_of_storage -_start,得到的值就是capacity。那么迭代器能与迭代器进行加法计算吗?当然可以了,因为vector当中的迭代器实际上就是一个T*的指针(查看上面代码的定义)。那么到此为止,我们已经可以设计c++标准当中的四个接口。分别是begin(),end(),size(),和capacity()。
iterator begin()
{
return _start;
}
const_iterator begin()const//begin的重载函数
{
return _start;
}
iterator end()
{
return _finish;
}
const_iterator end()const//end的重载函数
{
return _finish;
}
size_t size()const
{
return _finish - _start;
}
size_t capacity()const
{
return _end_of_storage - _start;
}
插入、删除、扩容
既然vector的数据结构是一个顺序表,那么它是需要进行数据的插入、删除这两个操作的。插入分为头插、尾插、任意位置的插入这三种方式、而删除也可以分为头删、尾删、和任意位置的删除这三种方式、但是头删和头插由于效率比较低,因此STL当中并没有规定要vector要实现头删和头插这两种操作。但是我们可以通过insert和erase这两个成员函数来进行头插、头删(当然,也可以进行尾插和尾删,之所以保留这两个操作的原因在于:这两个插入方式的效率很高,使用次数也很频繁)。
但是既然要插入数据,那么肯定会遇到容量不够的问题。此时就需要进行扩容了。我们先来实现扩容这个操作。
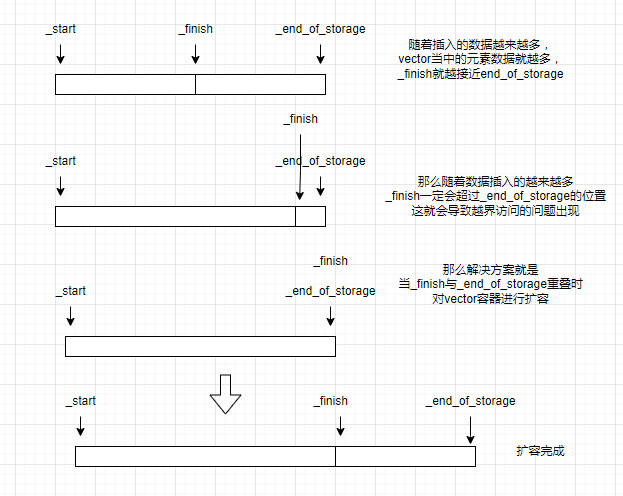
在c++标准当中,vector的扩容接口的函数名是reserve。我们也按照c++的标准将模拟实现的vector扩容接口命名为reserve。不过要注意的是,STL当中的vector是用空间配置器(allocator)来进行空间分配的。而博主模拟实现的vector则是用new和delete来管理空间。
void reserve(size_t n)
{
if (n > capacity)//reserve的作用是扩容,而不能用来缩容
{
size_t olesize = size();
iterator tmp = new value_type[n];
if (_start != nullptr)
{
memcpy(tmp, _start, sizeof(value_type) * size());//将原来的数据拷贝到新的地址
delete[] _start;//释放旧空间
}
_start = tmp;//接手新空间
_finish = _start + oldsize;
_end_of_storage = _start + n;
}
}
博主在扩容这方面使用的是异地扩容(原地扩容需要用到allocator),但是这个扩容函数在逻辑上看起来没问题,实际上存在一个bug,这个bug等待文章的后面再说明吧。我们先用这个reserve来为vector容器进行扩容。
那么接下来我们来实现一下头插和尾插。头插和尾插的原理非常简单,就是在表尾_finish的位置插入或删除一个元素,然后修改_finish,除此之外就是要注意扩容的问题。
void push_back(const value_type& val)
{
if (_finish == _end_of_storage)//扩容
{
size_t newcapacity = capacity() == 0 ? 4 : 2 * capacity();
reserve(newcapacity);
}
*_finish = val;//尾插元素
_finish++;
}
void pop_back()
{
assert(_finish > _start);
_finish--;//只需要让_finish往前一格就好了
//后面插入元素时会将原数据覆盖掉
}
任意位置的插入和删除的函数名字为insert和erase。我们要注意这插入算法和尾插算法实际上是存在一些区别的,主要的区别在于需要让数据发生挪动(这也是尾插和尾删的效率高的原因)。
我们先来看看c++标准中定义的insert原型
single element (1)
iterator insert (iterator position, const value_type& val);
可以发现c++标准中的insert函数的参数其实是用迭代器来作为position的原型。也就是说我们模拟实现的insert函数需要在position这个位置插入val。注意扩容
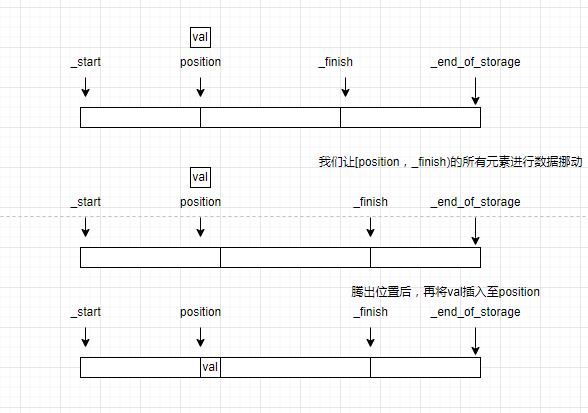
我们仔细观察c++标准中制定的insert函数原型,可以看到insert函数的返回值是一个迭代器,这个迭代器实际上就是position。为什么这个操作需要返回position呢?一个函数竟然要返回用户传入的参数,这可真是奇了怪了。
实际上此position非彼position,我们想想扩容函数reserve干了什么?没错,如果vector容器发生了扩容,这有可能会导致异地扩容。如果异地扩容一旦发生,就会导致迭代器失效的问题(迭代器指向了不再使用的空间,这不就是失效了?),所以c++标准规定insert函数需要返回position的真实位置(即无论发不发生扩容,这个position都是有效的迭代器)。
void pop_back()
{
_finish--;//只需要让_finish往前一个就好了
}
iterator insert(iterator position, const value_type& val)
{
assert(position <= _finish);//检测position合法性
assert(position >= _start);
size_t oldpos = position - _start;
if (_start == _finish)//扩容
{
size_t newcapacity = capacity() == 0 ? 4 : 2 * capacity();
reserve(newcapacity);
}
position = _start + oldpos;//更新position
iterator end = _finish - 1;
while (end >= position)//挪动数据
{
*(end + 1) = *end;
end--;
}
*position = val;//在position位置插入val
_finish++;
return position;
}
erase为了防止迭代器失效也有类似的设计。
iterator erase (iterator position);
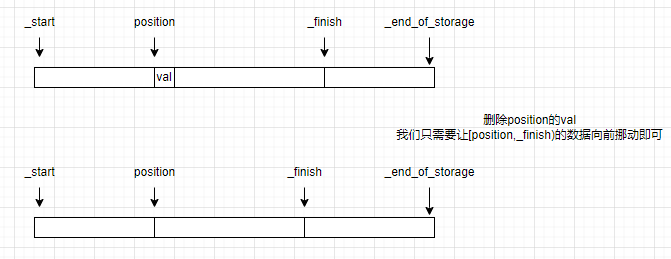
iterator erase(iterator position)
{
assert(position >= _start);//检测position的合法性
assert(position < _finish);
iterator begin = position+1;
while (begin <= _finish)//挪动数据
{
*(begin - 1) = *begin;
begin++;
}
_finish--;
if (position >= _finish)
{
return _finish - 1;
}
return position;
}
访问vector元素
我们已经简单的写好了vector的部分模块,那么我们现在最好先测试一下这些模块能否正常工作。请注意一个问题,当我们编写与模板相关的程序时,请多测试一下这些写好的模块,因为模板出现bug是很麻烦的。(博主就是在vector模拟实现的时候写错了一个标识符,找bug找了半小时qwq)。
既然要测试vector能不能好好使用,我们肯定是要遍历一下vector来查看这些函数能不能正常使用。那么写一个用来访问vector元素的函数就至关重要了。
博主这里将operator[] 模拟实现一下,因为这个函数是vector当中最常用的mumber access函数。
value_type& operator[](size_t pos)
{
return _start[pos];
}
const value_type& operator[](size_t pos)const
{
return _start[pos];
}
测试案例我就不放出来了,大家也请放心这些源码都是通过测试案例的(我的测试案例哈哈哈,不知道博主有没有天赋去测试岗位--!)。大家如果感兴趣,可以去我的代码仓库看看,博主最近计划将这个专栏写的源代码放进代码仓库里。
构造函数
构造函数一般不是最先写的吗?是的,但是由于博主在模板中对成员对象使用了缺省值,因此编译器的默认构造会将成员对象初始化成缺省值写的那样。这就是在前期我们可以不写构造函数,但是编译器不报错的原因。
为什么将构造函数放在最后面讲解。这是因为博主在设计这部分的时候遇到很有意思的事情,所以像放在后面讲解。实际上,这部分的内容应该本博客最核心的部分。
我们先来看看c++标准当中的constructor是怎样的吧。
default (1)
explicit vector (const allocator_type& alloc = allocator_type());
fill (2)
explicit vector (size_type n, const value_type& val = value_type(), const allocator_type& alloc = allocator_type());
range (3)
template <class InputIterator>
vector (InputIterator first, InputIterator last, const allocator_type& alloc = allocator_type());
copy (4)
vector (const vector& x);
我们忽略掉哪些allocator。
default构造很简单,甚至不需要写任何东西。因为我们在设计成员对象的时候就为其设计了缺省值。
vector() = default;//这个default的意思是,函数体内什么都不写,但是这个类是有默认构造的
填充(fill)构造则是为vector填充n个val,而缺省值value_type()则是一个匿名对象。(关于匿名对象,博主将其放在c++杂谈当中说明)
vector(size_t n, const value_type& val = value_type())//fill
{
while (n--)
{
push_back(val);
}
}
范围(range)构造,就是将这个迭代区间内的所有元素按照顺序放置进vector容器中。
template<class inputiterator>
vector(inputiterator first,inputiterator last)
{
while (first != last)
{
push_back(*first);
first++;
}
}
这部分的内容也非常好理解,我们将送入构造函数的迭代器的数据插入至vector当中,整个代码的逻辑是没有问题的。但是编译器偏偏就报错。
error C2100 非法的间接寻址 myvector D:\code\test-c123\myvector\vector.h 30
博主这是一顿冥思苦想啊,这个指针不是空指针,也不是野指针,怎么就非法寻址了呢?最后上网搜了一下导致的原因,恍然大悟了。
非法的间接寻址这个报错其实挺常见的。当初在C语言写scanf的时候就会看到这么一种情况
char ch;
scanf("%c",ch);//error,非法的间接寻址
这是什么原因。ch漏了一个取地址符号。一个char类型的变量是不能当做指针来用的。
但是这是一个构造函数啊,inputiterator其实就是一个迭代器,绝对是一个指针啊。但是别忘了,这是模板,是泛型编程,编译器可不管这个inputiterator到底是不是指针,只要有类型对的上,编译器就把模板套用了,还记不记得我们写的fill构造。
vector(size_t n, const value_type& val = value_type())//fill
{
while (n--)
{
push_back(val);
}
}
这个构造函数也没有什么问题啊,逻辑和类型都是正确的,但还是那句话,这是一个类模板,是泛型编程,在这个领域,我们要时刻主要调用函数时传入的类型。比如我们使用fill构造时。如果这么调用fill构造
vector<int> v3(4, 5);//fill构造
这样调用没问题啊。真的吗?我们再来看看range构造的模板
template<class inputiterator>
vector(inputiterator first,inputiterator last)
哦,原来是编译器把

解释成调用range构造了。因为类型很正确嘛。把inputiterator解释成int。很符合模板。但如此一来,就造成非法的间接寻址了。
那么解决方法是什么?
(1)将函数参数的类型强制转换成(size_t,int),这样编译器就不会解释为(int,int)。

但是记住一个原则,那就是不要让使用者去考虑太多。如果STL库需要使用者顾忌这个顾忌那个的,那么STL也不会被这么多人使用。
于是就考虑解决方法(2)了,那就是暴力的重载多个fill构造,把可能导致错误解释的情况考虑进去
vector(size_t n, const value_type& val = value_type())//fill
{
while (n--)
{
push_back(val);
}
}
vector(int n, const value_type& val = value_type())//重载版本
{
while (n--)
{
push_back(val);
}
}
这样子编译器会调用重载版本的构造函数(因为编译器会优先选择类型匹配的,虽然inputiterator解释成int也很匹配。但是他毕竟要先解释了再用,那么不需要解释就匹配的函数编译器会更加青睐)。
OK,问题(1)就这么解决了。
最后让我们解决copy赋值函数
vector(const vector& v)
{
for (auto& e: v)
{
push_back(e);
}
_end_of_storage = _start + v.capacity();
}
拷贝构造的原理很简单,遍历待拷贝的对象v,将对象v的所有元素尾插到vector当中。完成拷贝构造。
有人也许会感到疑惑,因为在拷贝构造当中我们是可以是memcpy将v中的元素进行拷贝的。但是为什么我不这样做呢?不知道大家还记不记得博主在reserve函数提到过这个实现存在一个bug。造成bug的原因就在于这个memcpy函数上。
填坑:为什么拷贝vector类元素的时候不能用浅拷贝
这里简单的说说什么是浅拷贝。
浅拷贝:也称为值拷贝,指的是将某个内存空间中的所有位(bit),拷贝到另外一个空间上去,显然memcpy就是一个典型的浅拷贝,而浅拷贝会带来数据隐患。
我们先来分析一下为什么vector的元素不能浅拷贝。实际上更准确的描述是,vector的部分类型的元素是不能浅拷贝的。比如string类。我们可以尝试一下让vector<string>发生扩容。
vector<string>v1;
v1.push_back("1111111111111111111111111");
v1.push_back("1111111111111111111111111");
v1.push_back("1111111111111111111111111");
v1.push_back("1111111111111111111111111");
cout << "第一次遍历元素的结果:" << endl;
for (auto& e : v1)
{
cout << e << ' ';
}
cout << endl;
v1.push_back("1111111111111111111111111");//这次尾插扩容
cout << "第二次遍历元素的结果:" << endl;
for (auto& e : v1)
{
cout << e << ' ';
}
我们多次尾插string元素,让v1发生扩容,然后运行这段程序,我们会看到一个非常奇怪的结果。

可以发现,vector<string>的部分元素变成了乱码。我们打开监视窗口看一看。
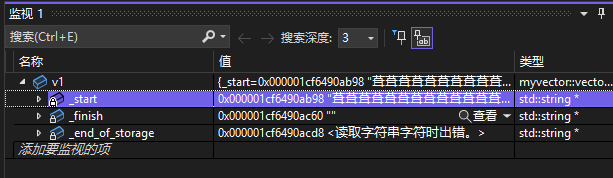
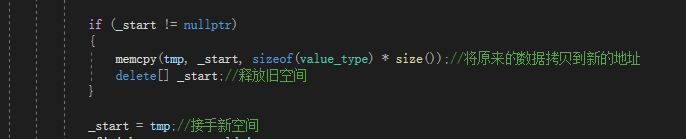
v1的内存似乎失效了。这其实就是因为浅拷贝vector元素导致的。我们可以画图分析一下reserve函数的核心代码(即执行扩容操作的那部分)。
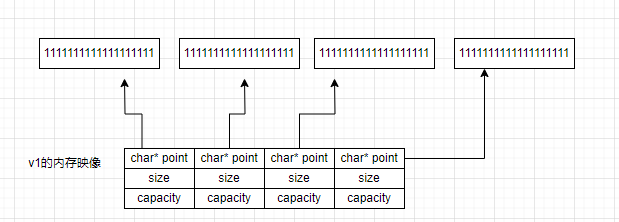
一个string对象可以认为具有以下成员
(1)管理资源的指针(char*)
(2)元素个数size
(3)容量capacity

那么v1在扩容前的内存映像应该是这样:
现在开始扩容了,我们执行第一条语句,让tmp开辟一个更大的空间

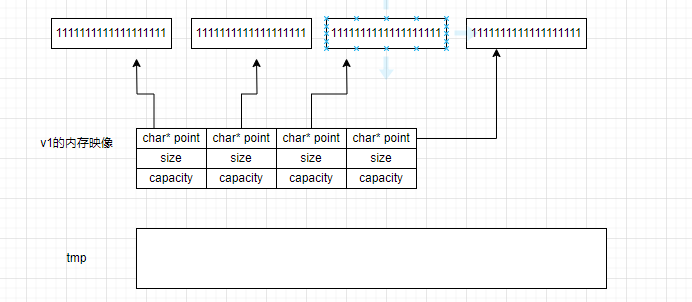
然后使用memcpy进行浅拷贝

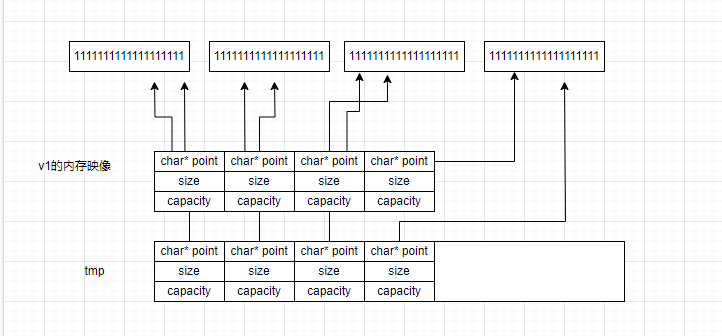
最后释放旧的空间,让_start接手新的空间·。
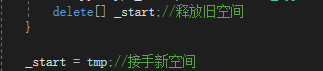
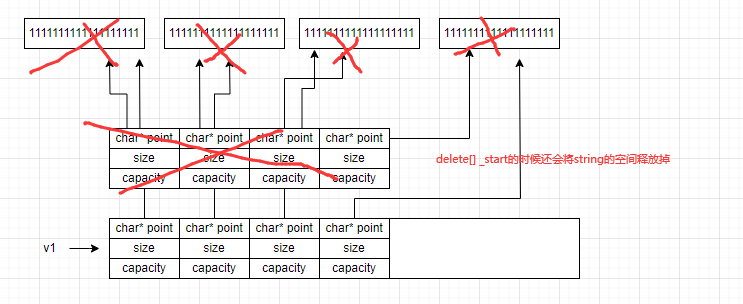
这就导致了很尴尬的情况,扩容的时候竟然将元素的内容丢失了,这肯定不是符合逻辑的使用效果,既然浅拷贝不适合vector的元素,那么就考虑用深拷贝。
深拷贝的原理是这样:深拷贝不是单纯的拷贝元素的值(bit),而是使用元素的副本。达到拷贝的效果
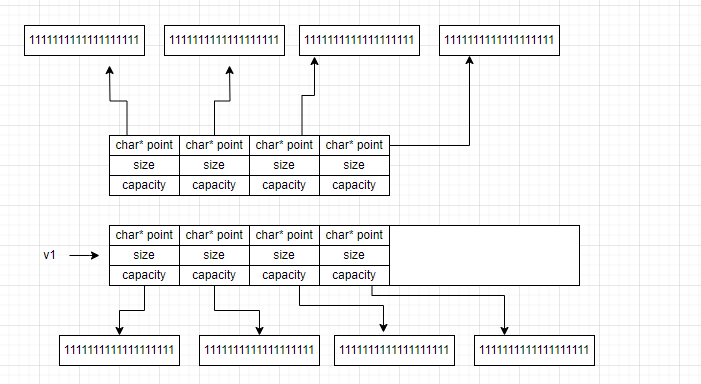
这样即使释放掉原来的空间,也不会导致扩容后的元素内容发生丢失。
所以最好的解决方法就是深拷贝vector的元素。
void reserve(size_t n)
{
if (n > capacity())//reserve的作用是扩容,而不能用来缩容
{
size_t oldsize = size();
iterator tmp = new value_type[n];
if (_start != nullptr)
{
//memcpy(tmp, _start, sizeof(value_type) * size());
//不再使用memcpy的浅拷贝,转而使用下面这种深拷贝
int i = 0;
for (auto& e : *this)
{
tmp[i++] = e;
}
delete[] _start;//释放旧空间
}
_start = tmp;//接手新空间
_finish = _start + oldsize;
_end_of_storage = _start + n;
}
}
实际上不止reserve函数不能用到浅拷贝,而是整个vector容器当中都不能使用浅拷贝。这也是博主在拷贝构造、或者其他与拷贝有关的函数时,博主宁愿使用push_back都不适用memcpy。
其他容器的模拟实现也会出现这种场景,但是博主不会再详细的解释不能浅拷贝的原因了。
末尾源代码:
博主将源代码和测试案例放到代码仓库当中了,博主会创建一个单独的仓库来放置这些博客当中的源码。
代码小豪的仓库
















 688
688

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











