







记录:在哪个主题,哪个分区下,消费到了哪个位置,这个值就是偏移量。
Kafka0.9版本之前,consumer默认将offset 保存在Zookeeper中,从0.9版本开始,consumer默认将offset保存在Kafka一个内置的topic中,该topic为__consumer_offsets ,我们用的kafka是 3.0版本。
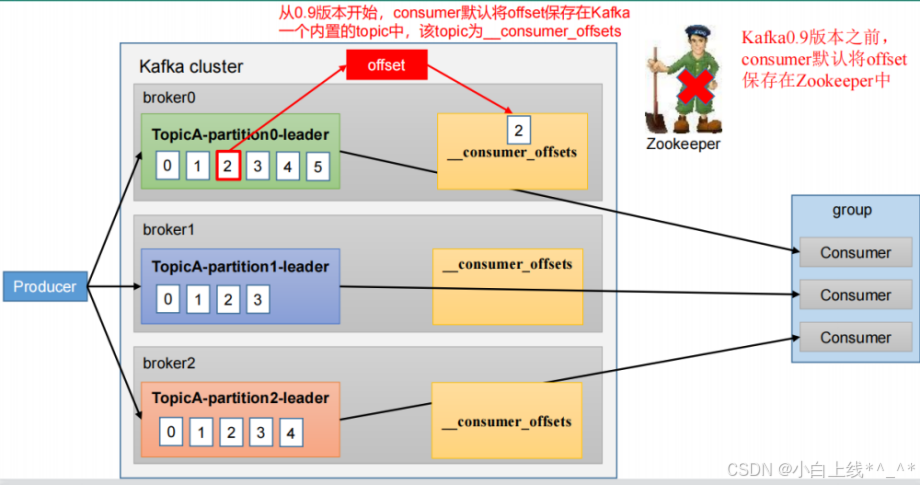
为什么要把消费者的偏移量从zk中挪到 kafka中呢?原因是避免Conusmer频发跟zk进行通信。
1.1 自动提交 offset
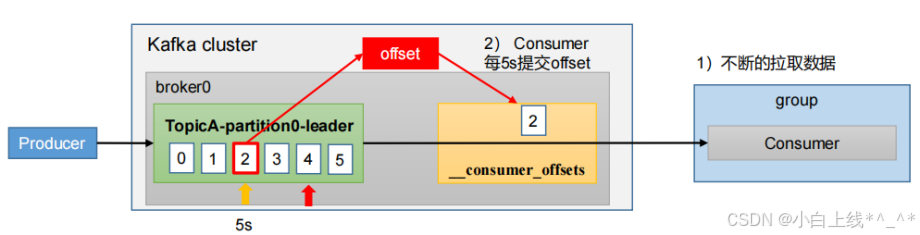
为了使我们能够专注于自己的业务逻辑,Kafka提供了自动提交offset的功能。
自动提交offset的相关参数:
enable.auto.commit:是否开启自动提交offset功能,默认是true.
auto.commit.interval.ms:自动提交offset的时间间隔,默认是5s.
代码演示:
1)消费者自动提交 offset
// 是否自动提交 offset 通过这个字段设置
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,true);
// 提交 offset 的时间周期 1000ms,默认 5s
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,1000);1.2指定 Offset 消费 【重要】
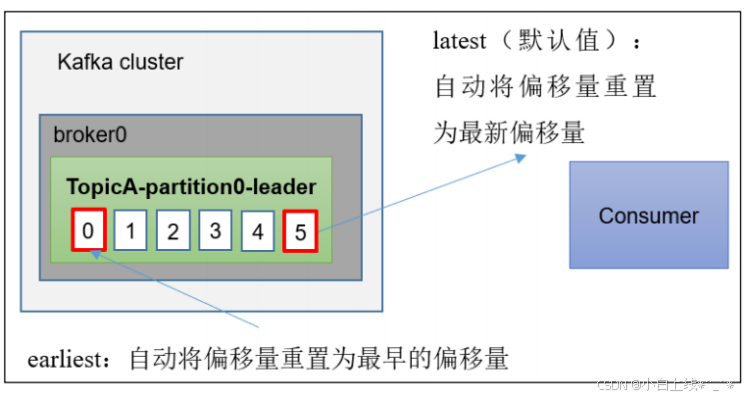
auto.offset.reset = earliest | latest | none 默认是 latest。
当 Kafka 中没有初始偏移量(消费者组第一次消费)或服务器上不再存在当前偏移量时(例如该数据已被删除),该怎么办?
(1)earliest:自动将偏移量重置为最早的偏移量,--from-beginning 从头开始
(2)latest(默认值):自动将偏移量重置为最新偏移量。 --最新位置
(3)none:如果未找到消费者组的先前偏移量,则向消费者抛出异常 --不指定
这个参数的力度太大了。不是从头,就是从尾。有没有一种方法能我们自己选择消费的位置呢?有。kafka提供了seek方法,可以让我们从分区的固定位置开始消费。seek (TopicPartition topicPartition,offset offset)。
TopicPartition这个对象里有2个成员变量。一个是Topic,一个是partition。再结合offset,完全就可以定位到指定的偏移量。
package com.bigdata.consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Properties;
import java.util.Set;
/*
* 1.创建一个kafka消费者的对象
* 2.properties.put放置相关参数
* 3.指定消费者主题
* 4.拉取kafka数据开始不停循环消费*/
public class Consumer02 {
public static void main(String[] args) {
Properties properties = new Properties();
// 连接kafka
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"bigdata01:9092");
// 字段反序列化 key 和 value
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
// 配置消费者组(组名任意起名) 必须
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test1");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties);
ArrayList<String> list = new ArrayList<>();
list.add("first");
kafkaConsumer.subscribe(list);
// 执行计划
// 此时的消费计划是空的,因为没有时间生成
Set<TopicPartition> assignment = kafkaConsumer.assignment();
while (assignment.size()==0){
// 这个本身是拉取数据的代码,此处可以帮助快速构建分区方案出来
kafkaConsumer.poll(Duration.ofSeconds(1));
// 一直获取它的分区方案,什么时候有了,就什么时候跳出这个循环
assignment = kafkaConsumer.assignment();
}
//调用seek方法
kafkaConsumer.seek(new TopicPartition("first",2),2);
while (true){
ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord record:records
) {
System.out.println(record);
}
}
}
}注意:每次执行完,需要修改消费者组名;
1.3消费计划(分区计划)
本次消费任务的计划是如何制定的?凭什么老爹买西瓜?
1、一个consumer group中有多个consumer组成,一个 topic有多个partition组成,现在的问题是,到底由哪个consumer来消费哪个partition的数据。
2、Kafka有四种主流的分区分配策略: Range、RoundRobin(轮询)、Sticky(粘性)、CooperativeSticky(配合的粘性)。
默认策略是Range + CooperativeSticky。
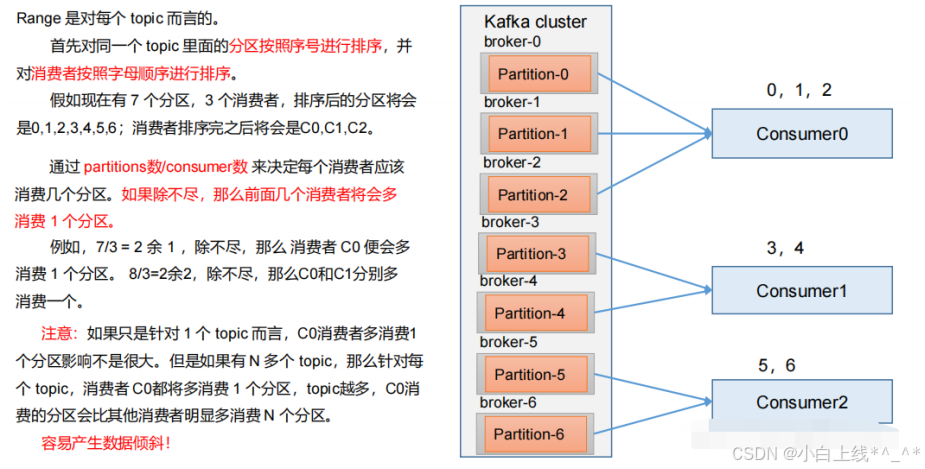
1)Range 分区策略原理
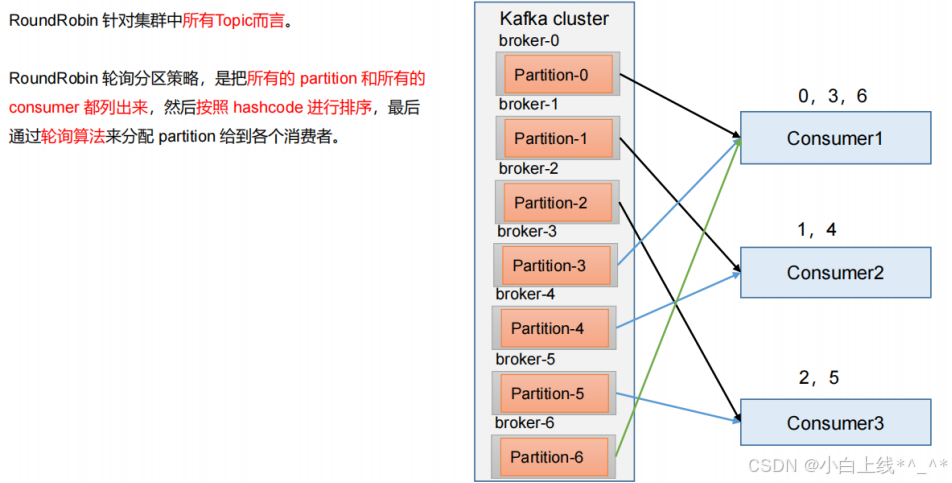
2)RoundRobin (轮询)分区策略原理
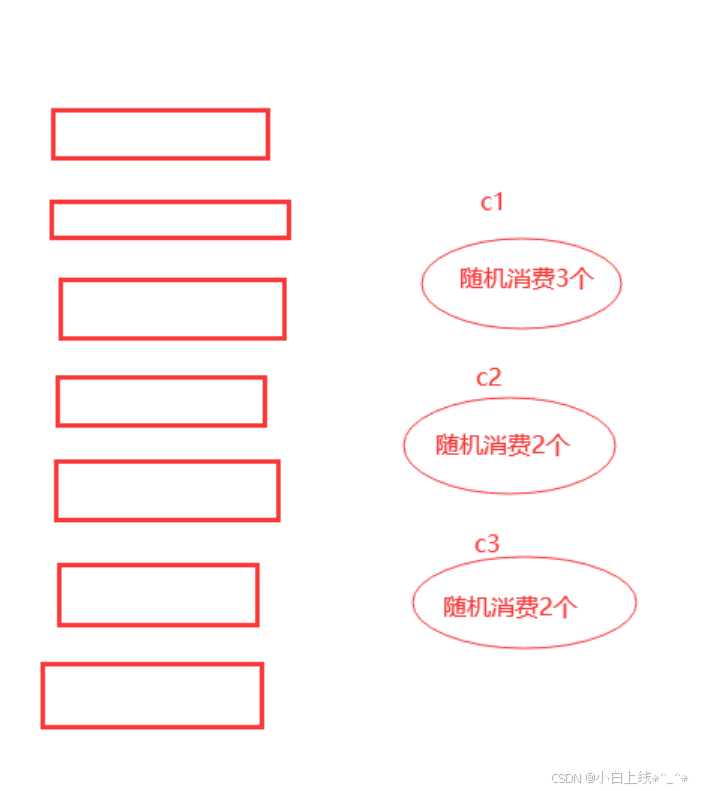
3) Sticky (粘性)
比如分区有 0 1 2 3 4 5 6
消费者有 c1 c2 c3
c1 消费 3个 c2 消费2个 c3 消费2个分区
跟以前不一样的是,c1 消费的3个分区是随机的,不是按照 0 1 2 这样的顺序来的。
4) CooperativeSticky (配合的粘性)
在消费过程中,会根据消费的偏移量情况进行重新再平衡,还会根据消费的实际情况重新分配消费者,直到平衡为止。
好处是:负载均衡,不好的地方是:多次平衡浪费性能。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











