






介绍
支持向量机(Support Vector Machine, SVM)是一类强大的监督学习算法,用于进行二元或多元分类以及回归分析。它通过寻找一个最大边距超平面来进行分类,这个超平面能够将不同类别的数据点分隔开,并且具有对未知样本泛化能力强的特点。
SVM使用铰链损失函数(hinge loss)来计算经验风险,并引入正则化项来优化结构风险,从而在求解过程中避免过拟合,具有稀疏性和稳健性。此外,SVM还可以通过核方法(kernel method)来处理非线性分类问题,将数据映射到高维空间中进行分类,因此被称为一种常见的核学习(kernel learning)方法之一。
算法概述
支持向量机(Support Vector Machine, SVM)是一种二分类模型,其目的是寻找一个超平面来对样本进行分割,分割的原则是间隔最大化。基本上,SVM可以根据训练数据的特性以及线性可分性来分为不同的模型:
- 当训练样本线性可分时,SVM通过硬间隔最大化来学习一个线性可分支持向量机。
- 当训练样本近似线性可分时,SVM通过软间隔最大化来学习一个线性支持向量机,这允许一些样本出现在间隔边界内部。
- 当训练样本线性不可分时,SVM利用核技巧和软间隔最大化来学习一个非线性支持向量机,通过将数据映射到高维空间来实现非线性分类。
总的来说,SVM算法在处理不同性质的数据时具有很强的灵活性,并且通过间隔最大化和支持向量的概念,能够在不同情况下取得良好的分类效果。
线性可分支持向量机
支持向量机(Support Vector Machine, SVM):
给定线性可分训练数据集,SVM通过最大化分类间隔或等价地求解相应的凸二次规划问题来学习得到的分离超平面为:
其中,是法向量,[ b ] 是偏置项。这个超平面能够将不同类别的样本完全分隔开。
相应的分类决策函数为:
这被称为线性可分支持向量机。
在间隔最大化的过程中,支持向量是离超平面最近的那些样本点,它们决定了分离超平面的位置。因此,支持向量机的分类决策仅仅依赖于支持向量,而不依赖于其他训练样本,这也是支持向量机的一个重要特点。
通过最大化间隔,线性可分支持向量机能够找到一个最优的分割超平面,并且具有对未知样本泛化能力强的特点
间隔最大化和支持向量
首先,函数间隔(functional margin)用于表示分类预测的确信程度。对于给定的训练数据集和超平面 ( w^* x + b = 0 ),其中 ( w^* ) 是超平面的法向量, ( b ) 是偏置项,函数间隔定义为 ( y(w^*x + b) ),其中 ( y ) 是样本点的类标记。这个函数间隔能够表示样本点距离超平面的远近以及分类的正确性和确信度。
然后,为了确定最大间隔,引入了几何间隔(geometric margin),即将超平面 ( w^* x + b ) 的函数间隔加上对法向量 ( w^* ) 的约束,如规范化(( ||w^*||=1 ))。这样得到的几何间隔表示了样本点距离超平面的几何意义上的远近。
支持向量机的学习策略就是要最大化这个几何间隔,可以形式化为一个求解凸二次规划问题。具体地,最大化几何间隔等价于最小化 ( ||w^*||^2 ),即法向量的范数的平方。
因此,支持向量机的基本型是要找到具有最大间隔的划分超平面,其学习过程可以被形式化为一个凸二次规划问题。
算法实现
数据集处理
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.model_selection import learning_curve, GridSearchCV
from mlxtend.plotting import plot_decision_regions
# 加载数据集
iris = datasets.load_iris()
X = iris.data[:, :2] # 只取前两个特征,便于可视化
y = iris.target
划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)训练模型
svm_classifier = SVC(kernel='rbf', gamma=0.7)
svm_classifier.fit(X_train, y_train)输出准确率
print("训练集准确率:", svm_classifier.score(X_train, y_train))
print("测试集准确率:", svm_classifier.score(X_test, y_test))
绘制曲线
输入的数值
estimator:要评估的模型,title:图表的标题,X:特征数据,y:标签数据,ylim:y轴的取值范围,cv:交叉验证参数,n_jobs:并行工作的数量,train_sizes:训练集大小的数组。
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None, n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)):用于生成学习曲线的训练样本的相对或绝对数量在函数内部,首先创建一个新的图表,设置标题和坐标轴标签。如果给定了 ylim 参数,就设置 y 轴的取值范围。
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("Training examples")
plt.ylabel("Score")调用 learning_curve 函数,该函数会返回不同训练样本数量下的训练集得分和交叉验证集得分。这些得分分别存储在 train_sizes、train_scores 和 test_scores 中。
train_sizes, train_scores, test_scores = learning_curve(estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes)
计算平均训练集得分和标准差,以及平均交叉验证集得分和标准差。
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()使用 fill_between 函数填充训练集得分和测试集得分的标准差区域,以展示得分的方差范围。
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,train_scores_mean + train_scores_std, alpha=0.1,color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,test_scores_mean + test_scores_std, alpha=0.1, color="g")使用 plot 函数绘制平均训练集得分和平均交叉验证集得分,并添加对应的标签。
plt.plot(train_sizes, train_scores_mean, 'o-', color="r", label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g", label="Cross-validation score")最后,使用 legend 函数添加图例,并返回绘制好的图表对象。
plt.legend(loc="best")
return plt调用 plot_learning_curve 函数,传入了模型 svm_classifier、标题 "Learning Curve"、特征数据 X、标签数据 y 和交叉验证折数 cv=5,从而绘制出学习曲线图表。
plot_learning_curve(svm_classifier, "Learning Curve", X, y, cv=5)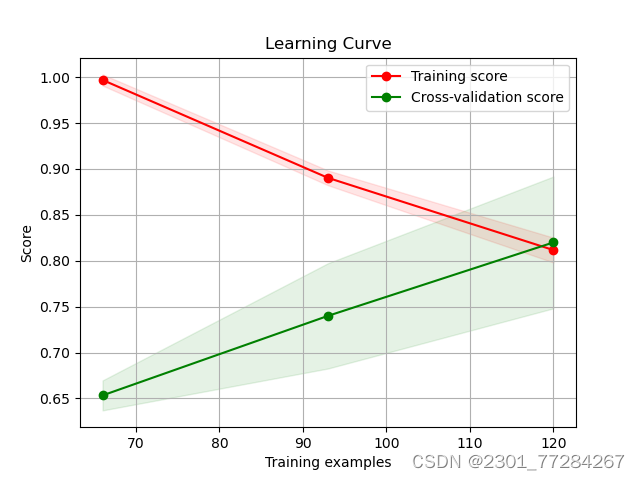
这个函数的主要作用是绘制训练集大小与模型得分(训练集得分和交叉验证集得分)之间的关系,以帮助分析模型的学习情况和过拟合程度。
寻找gamma值
在参数网格中进行交叉验证网格搜索得到最合适的gamma值
param_grid = {'gamma': [0.001, 0.01, 0.1, 1, 10, 100]}
grid_search = GridSearchCV(SVC(kernel='rbf'), param_grid, cv=5)
grid_search.fit(X, y)
print("最佳gamma值:", grid_search.best_params_['gamma'])
绘制决策边界
使用plot_decision_regions函数绘制支持向量机(SVM)模型的决策边界
plot_decision_regions(X, y, clf=svm_classifier, legend=2)
plt.xlabel(iris.feature_names[0])
plt.ylabel(iris.feature_names[1])
plt.title('SVM Decision Boundary')
plt.show()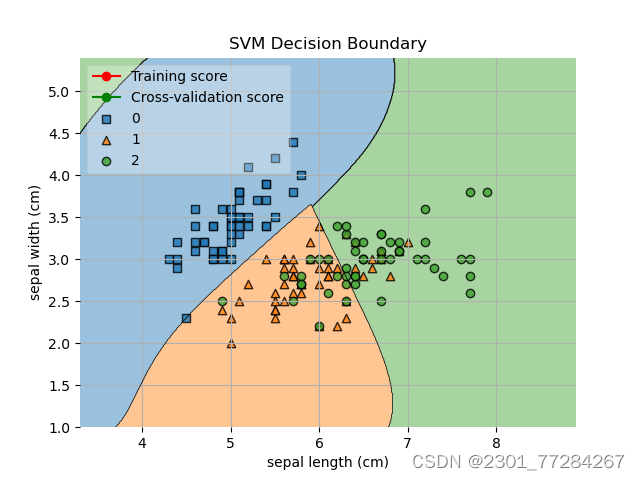
总结
主要实现了加载鸢尾花数据集,并使用支持向量机(SVM)模型进行训练和测试,输出训练集和测试集的准确率。绘制学习曲线函数plot_learning_curve,展示模型在不同训练样本数量下的训练得分和交叉验证得分。使用网格搜索GridSearchCV寻找最佳的gamma值,优化SVM模型的参数。最后,通过plot_decision_regions函数绘制SVM模型的决策边界,并对图形进行一些设置。
SVM模型中的参数对模型性能影响很大,特别是核函数中的参数。通过网格搜索(GridSearchCV)方法,可以系统地搜索最佳参数组合,从而提高模型的性能。















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









