






今年与朋友一起参与了全国市场调研分析大赛并获得国家三等奖,本人在团队中主要负责《哪吒2》电影的爬虫、情感分析、情感预测、相关性分析及岭回归分析、延伸热门电影预测的模块,以此开源供大家一起学习交流。
目录
一、爬虫篇
我们主要对各个媒体平台进行《哪吒2》电影的影评进行爬虫,由于我们非常看重影评的数量和质量,因此从豆瓣、b站、音符等多平台进行爬取影评信息。在爬虫部分,本人负责对豆瓣和b站的影评内容进行爬取。使用的python版本为3.11,详细的数据、库版本、代码集详见本人的github中的博客(稍后进行更新)。
1.b站爬虫
首先找到《哪吒2》电影短评的入口:b站入口,通过观察可知,b站的评论不是以翻页的形式进行浏览,而是以滚动的形式进行浏览,因此,考虑使用selenium库进行短评内容的滚动加载。本人电脑默认的浏览器是edge,因此这里使用edge的滚动浏览(现在网络上大多关于selenium滚动加载的示例浏览器都是chrome,因此本博客对edge浏览器的用户可提供一定的参考)。
由于要用selenium模拟浏览器滚动加载的行为,需要显示浏览器,为了方便,使用无头模式,即浏览器界面不显示,后台运行:
edge_options = Options()
edge_options.add_argument('--headless')
edge_options.add_argument('--disable-gpu')
edge_options.add_argument('--no-sandbox')
driver = webdriver.Edge(options=edge_options)接下来进行模拟滚动,设置滚动次数为 20 次,设置每次滚动后等待的时间为 2 秒,等待页面加载新内容,循环滚动20 次(因为在此项目中不需要对一个平台收取全部的数据,原因是b站越往后的评论点赞数及浏览数不高,参考价值不太大):
try:
driver.get(url)
scroll_times = 20 # 假设滚动加载5次
scroll_interval = 2 # 每次滚动间隔2秒
# 模拟滚动加载
for i in range(scroll_times):
# 执行 JavaScript 代码,将页面滚动到底部
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(scroll_interval)
# 获取网页的 HTML 内容
html = driver.page_source
finally:
driver.quit() # 确保退出浏览器
return html然后,对想要爬取的内容进行选择,本文使用正则表达式进行爬取特定内容。首先F12进入开发者模式,目标是爬取每条评论的内容、时间、点赞数、用户名、评价星级,爬取的思路是,先找到每个评论的整个框,再运用循环依次找每个评论的内容、时间、点赞数、用户名、评价星级。先找每个评论的整个框:
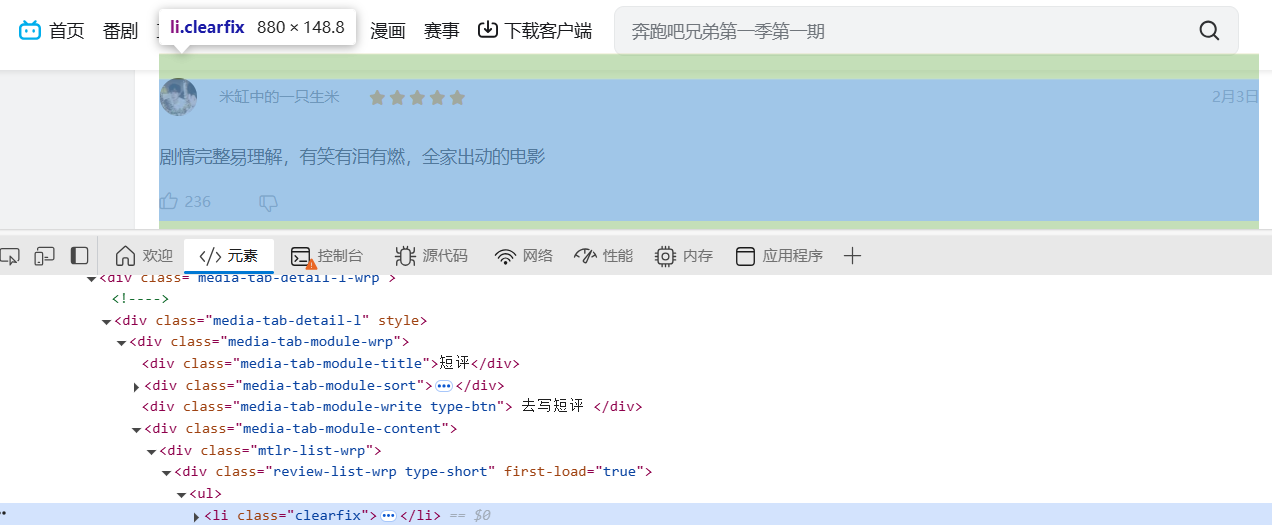
由图可知,每个框的标签都是clearfix,因此锁定—找寻带有class="clearfix"的表达式。对于用户名,可以找到是在div标签下的class="review-author-name"中:
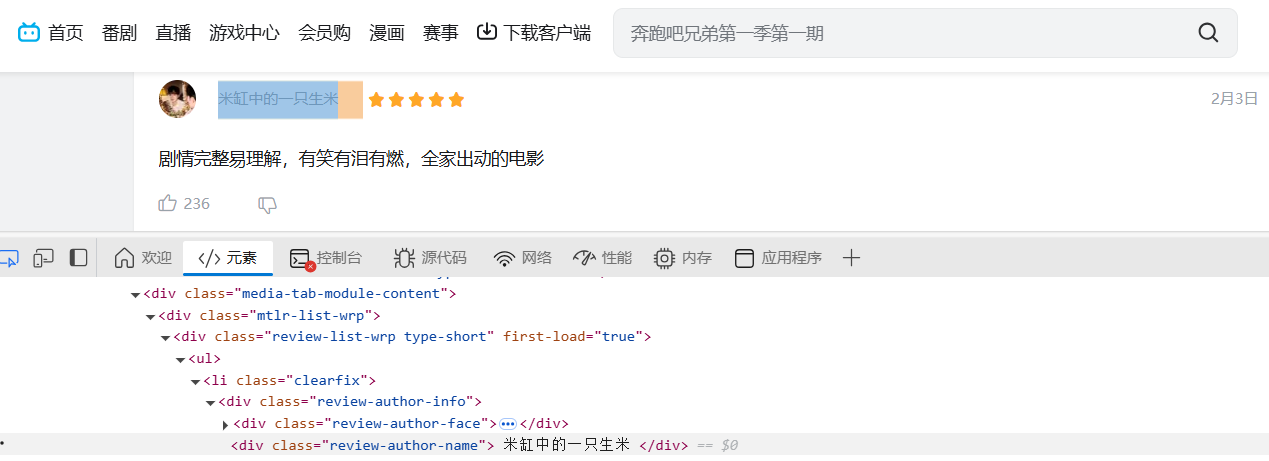
对于影评内容,在div标签中的class="review-content"里:
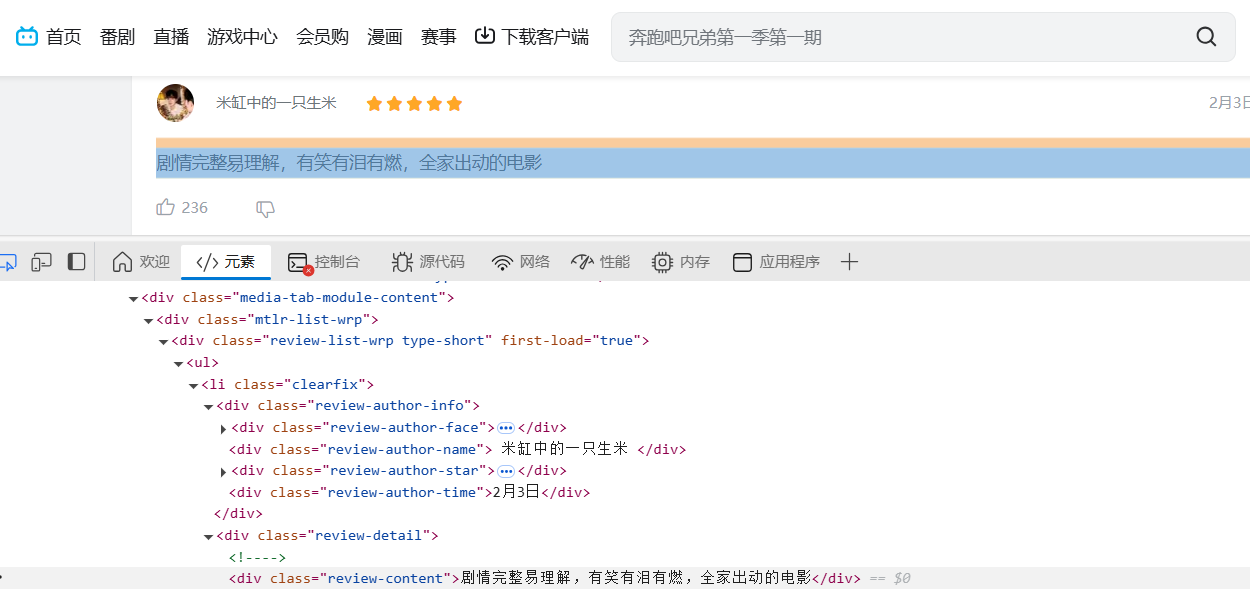
对于点赞数,由下图可知,要获取的是236,即先找到是隶属于div标签下的class="review-data-like"中,并且取[-1],即最后一个文本,对应的就是"236 ";只要取数字,则使用正则表达式的\d+来获取一段连续数字:
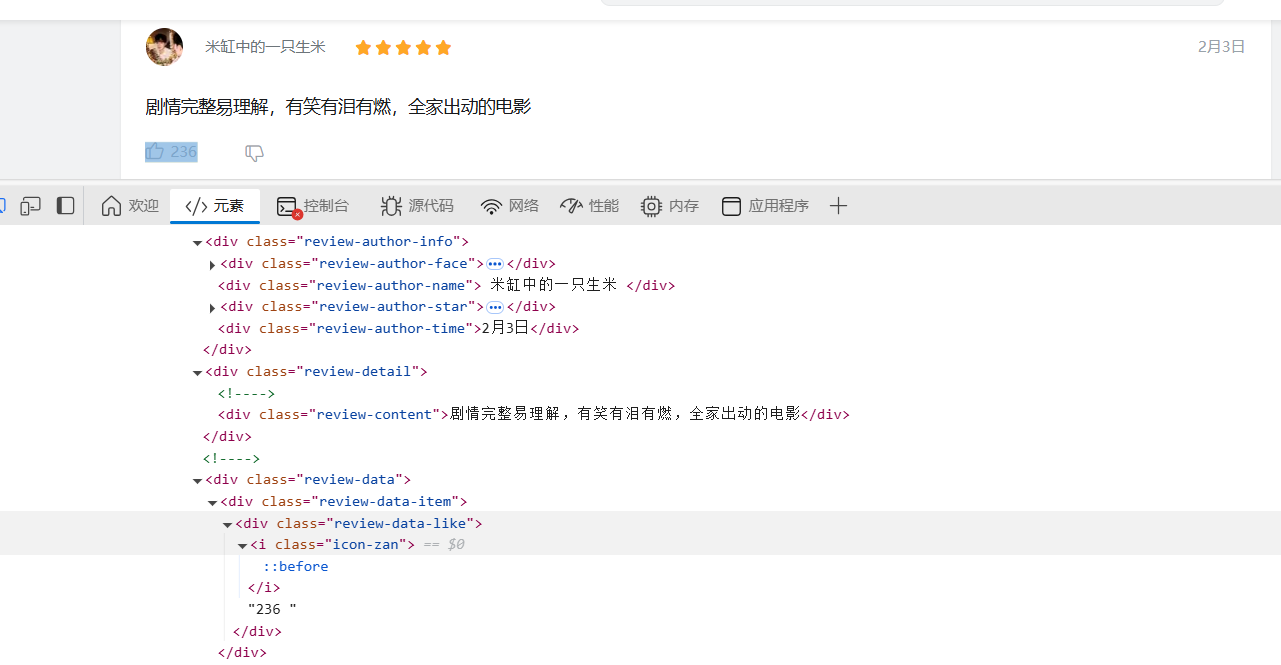
对于时间,在div标签中的class="review-author-time"里:
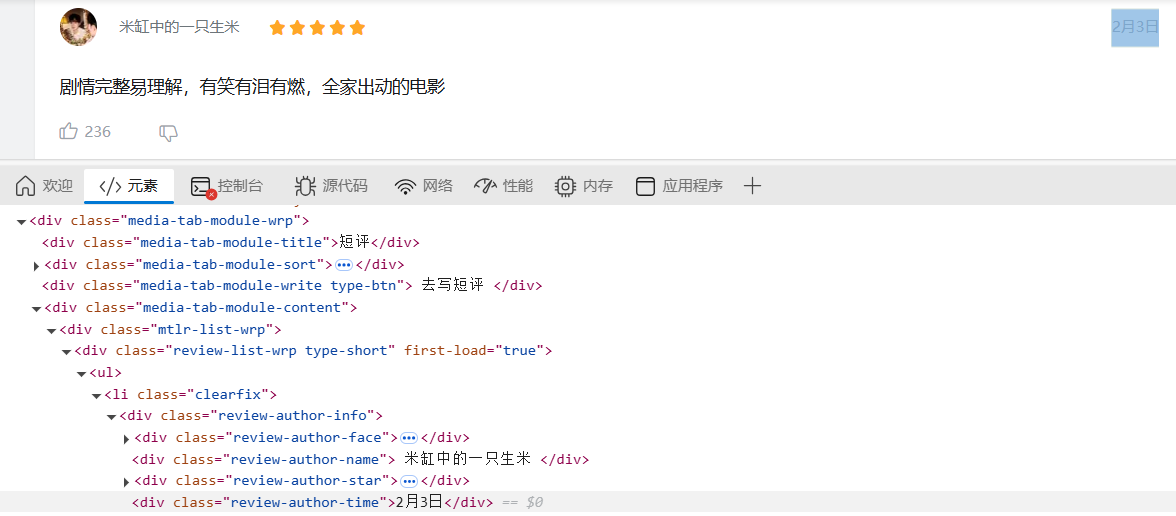
对于评论星级,可以从下面两张图看到,如果评了星,则所属的class为"icon-star icon-star-light",如果该星没有评,则class为"icon-star",所以,只需统计span标签下的class="review-stars"下的包含”icon-star-light“的数量即可:
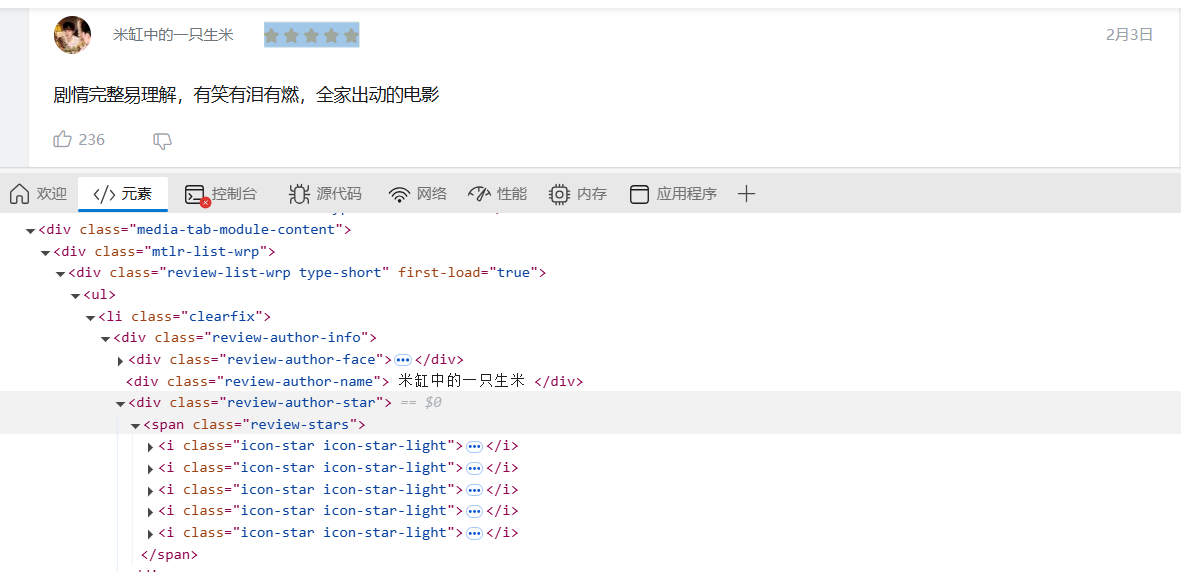
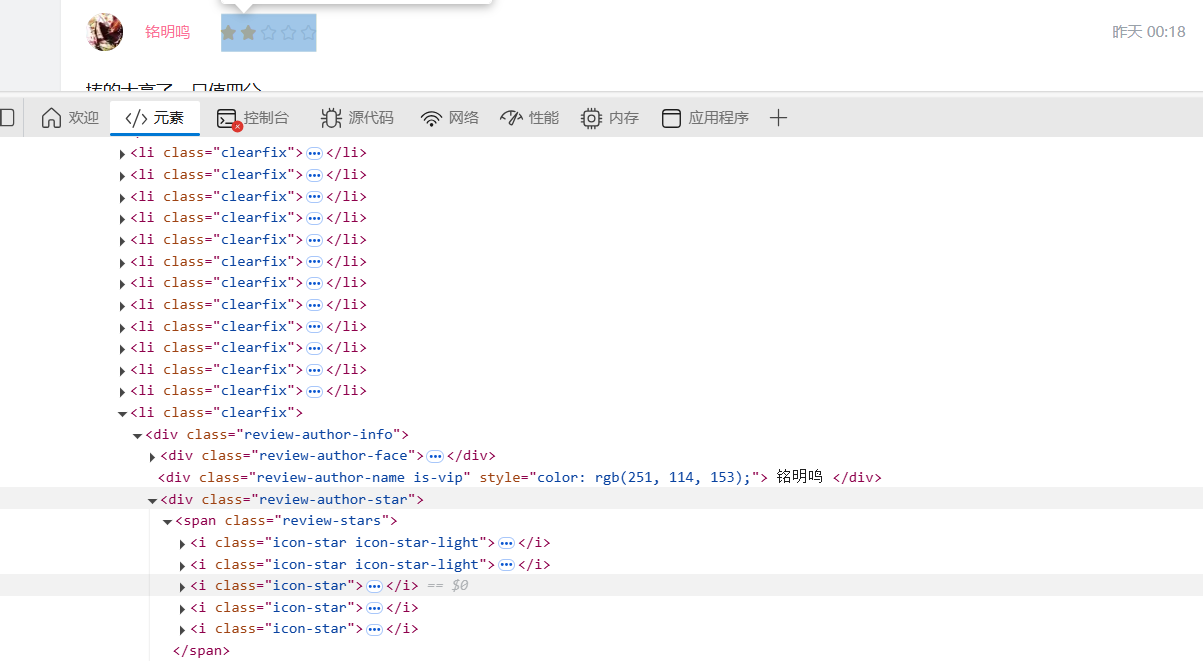
对想要爬取的内容进行选择的总代码为:
def get_movie_review_by_url(url):
comments_dict = []
tree = etree.HTML(get_html_edge(url))
comment_list = tree.xpath('//li[@class="clearfix"]')
if len(comment_list) == 0:
return comments_dict
for comment_div in comment_list:
try:
name = comment_div.xpath('.//div[contains(@class, "review-author-name")]/text()')[0].strip()
except:
name = ''
try:
content = comment_div.xpath('.//div[@class="review-content"]/text()')[0].strip()
except:
continue
try:
# 点赞数提取(通过正则获取数字)
upvote_text = comment_div.xpath('.//div[@class="review-data-like"]/text()')[-1].strip()
upvote = re.search(r'\d+', upvote_text).group()
except:
upvote = '0'
time = comment_div.xpath('.//div[@class="review-author-time"]/text()')[0]
try:
# 星级计算(统计包含icon-star-light的i标签数量)
stars = len(comment_div.xpath('.//span[@class="review-stars"]/i[contains(@class, "icon-star-light")]'))
except:
stars = 0
comments_dict.append({
'name': name,
'content': content,
'upvote': upvote,
'time': time,
'stars': stars
})
return comments_dict由于还会爬取其他平台的数据,所以对一个平台不用爬太多,主要爬一些较热门的评论,设置总评论数为400,设置爬取等待时间:t.sleep(random.uniform(1, 3)),时间最好设置一下,不然有些网站如果太频繁爬取的话可能会触发反爬机制。最后将结果保存在excel中,b站爬虫的全部代码如下:
from lxml import etree
import re
import time as t
import random
import os
import pandas as pd
from selenium import webdriver
from selenium.webdriver.edge.options import Options
import time
def get_html_edge(url):
# 配置 Edge 使用无头浏览器
edge_options = Options()
edge_options.add_argument('--headless')
edge_options.add_argument('--disable-gpu')
edge_options.add_argument('--no-sandbox')
driver = webdriver.Edge(options=edge_options)
try:
driver.get(url)
scroll_times = 20 # 假设滚动加载5次
scroll_interval = 2 # 每次滚动间隔2秒
# 模拟滚动加载
for i in range(scroll_times):
# 执行 JavaScript 代码,将页面滚动到底部
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(scroll_interval)
# 获取网页的 HTML 内容
html = driver.page_source
finally:
driver.quit() # 确保退出浏览器
return html
def get_movie_review_by_url(url):
comments_dict = []
tree = etree.HTML(get_html_edge(url))
comment_list = tree.xpath('//li[@class="clearfix"]')
if len(comment_list) == 0:
return comments_dict
for comment_div in comment_list:
try:
name = comment_div.xpath('.//div[contains(@class, "review-author-name")]/text()')[0].strip()
except:
name = ''
try:
content = comment_div.xpath('.//div[@class="review-content"]/text()')[0].strip()
except:
continue
try:
# 点赞数提取(通过正则获取数字)
upvote_text = comment_div.xpath('.//div[@class="review-data-like"]/text()')[-1].strip()
upvote = re.search(r'\d+', upvote_text).group()
except:
upvote = '0'
time = comment_div.xpath('.//div[@class="review-author-time"]/text()')[0]
try:
# 星级计算(统计包含icon-star-light的i标签数量)
stars = len(comment_div.xpath('.//span[@class="review-stars"]/i[contains(@class, "icon-star-light")]'))
except:
stars = 0
comments_dict.append({
'name': name,
'content': content,
'upvote': upvote,
'time': time,
'stars': stars
})
return comments_dict
def get_movie_review(url):
comments_dict = []
max_comments = 400
t.sleep(random.uniform(1, 3)) # 随机等待时间是0.5秒和1秒之间的一个小数
tmp_comments_dict = get_movie_review_by_url(url)
for comment in tmp_comments_dict:
if len(comments_dict) < max_comments:
comments_dict.append(comment)
else:
break
print("==================影评获取完毕===================")
print(f'共获取{len(comments_dict)}条影评')
return comments_dict
def save_movie_review(comments_dict):
dir_path = f'./data/nezha2'
os.makedirs(dir_path, exist_ok=True)
df = pd.DataFrame(comments_dict) # 将字典转换为 DataFrame
df.to_excel(os.path.join(dir_path, 'comments2.xlsx'), index=False)
def main():
url = f'https://www.bilibili.com/bangumi/media/md22638046#short'
comments_dict = get_movie_review(url)
save_movie_review(comments_dict)
if __name__ == '__main__':
main()2.豆瓣爬虫
豆瓣爬虫这部分由于做项目时时间太赶,主要参考了github上的一篇文章:豆瓣爬虫(感恩),该作者还整理了一个查询功能,可以输入电影名称进行查询,比较方便。该代码实现的整体思路与我上面写的b站爬虫差不多,都是用正则+标签进行查找。本人使用此代码时,由于直接使用作者自己的headers爬不了,所以主要就改了headers的cookies和user-agent,都是改为自己电脑上的,并且爬之前先登录了豆瓣,本人发现,如果不登陆豆瓣的话,只能爬120条,登录后即可爬取400条左右,该网站有反爬机制,所以无法再进一步获取后面的评论。对于更改headers,本人的更改方式如下:
先在该网站的《哪吒2》界面点击F12打开开发者模式,点击网络,在筛选器筛选条件中点击文档,按F5刷新,一般点击第一个文档即可看到:
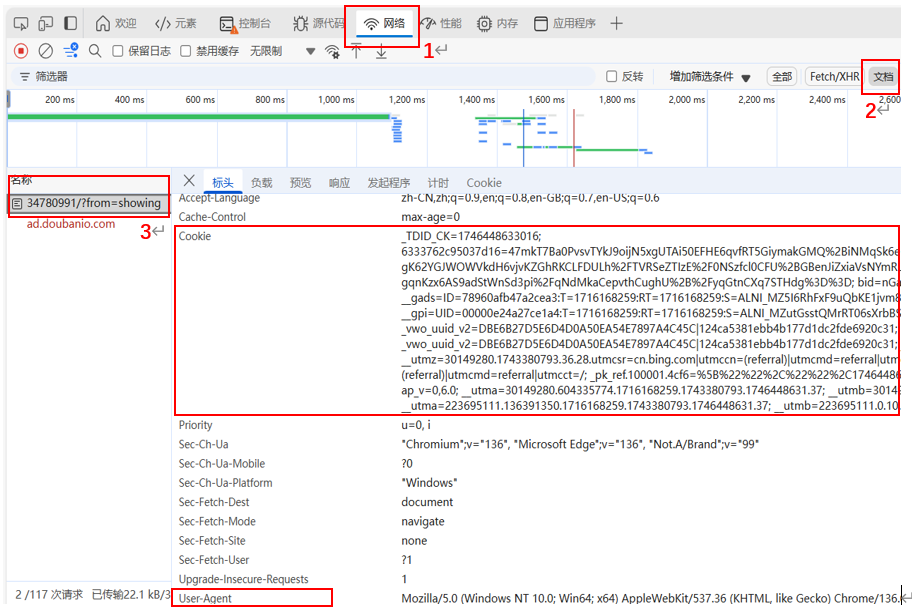
豆瓣爬虫的完整代码如下,仅修改了cookies和user-agent,user-agent这里采用的是另一个,如果使用自己电脑上显示的不行的话,可以尝试使用这个user-agent,本人使用这个user-agent时百分之70的不可爬的都可以进行爬取,有奇效。完整的代码介绍、疑问解答可访问原作者的github,这里就不详细展开说了:
import requests
from lxml import etree
import re
import time as t
import random
import os
import json
import pandas as pd
def get_html(url):
cookies = {
'bid': '1gMxgR_xU5U',
'll': '"118282"',
'Hm_lvt_19fc7b106453f97b6a84d64302f21a04': '1733372099',
'_ga_PRH9EWN86K': 'GS1.2.1733372100.1.0.1733372100.0.0.0',
'_pk_id.100001.8cb4': 'b471986e3f50b77b.1733372155.',
'_vwo_uuid_v2': 'D8DB7696A3F6AD5AF442F89BBAA685C83|ba3269f7a883157ff71737fd00d2c8c0',
'_ga': 'GA1.1.857826835.1733372040',
'_ga_Y4GN1R87RG': 'GS1.1.1735141304.2.1.1735141359.0.0.0',
'dbcl2': '"224267170:eEXqtpqkCjk"',
'push_noty_num': '0',
'push_doumail_num': '0',
'ck': 'N56a',
'ap_v': '0,6.0',
'_pk_ref.100001.8cb4': '%5B%22%22%2C%22%22%2C1742305309%2C%22https%3A%2F%2Fsearch.douban.com%2Fmovie%22%5D',
'_pk_ses.100001.8cb4': '1',
'frodotk_db': '"5321b30168c70291f96519043a5507b3"',
'__yadk_uid': 'gOqlfIhhHdGTu9Q4DmnXxqLQBNZrSMFz',
'__utma': '30149280.857826835.1733372040.1740574756.1742305312.7',
'__utmc': '30149280',
'__utmz': '30149280.1742305312.7.5.utmcsr=search.douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/movie',
'__utmv': '30149280.22426',
'__utmb': '30149280.8.10.1742305312',
}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
return requests.get(url=url, cookies=cookies, headers=headers).text
def get_movie_id(movie_name):
url = f'https://search.douban.com/movie/subject_search?search_text={movie_name}'
response_text = get_html(url)
# 使用正则表达式提取 "id" 和 "title"
pattern = r'"id":\s*(\d+).*?"title":\s*"([^"]+)"'
matches = re.findall(pattern, response_text)
# 将结果转换为字典
result = {int(match[0]): match[1].encode().decode('unicode_escape') for match in matches}
return result
def get_movie_review_by_url(url):
comments_dict = []
tree = etree.HTML(get_html(url))
comment_list = tree.xpath('//div[@class="comment-item"]')
if len(comment_list) == 0:
return comments_dict
for comment_div in comment_list:
try:
name = comment_div.xpath('.//span[@class="comment-info"]/a/text()')[0].strip()
except:
name = ''
try:
content = comment_div.xpath('.//p[@class="comment-content"]/span/text()')[0].strip()
except:
continue
upvote = comment_div.xpath('.//span[@class="votes vote-count"]/text()')[0].strip()
time = comment_div.xpath('.//span[@class="comment-time"]/@title')[0]
try:
location = comment_div.xpath('.//span[@class="comment-location"]/text()')[0].strip()
except:
location = ''
try:
star_attribute = comment_div.xpath('.//span[contains(@class,"rating")]/@class')[0]
stars = re.search(r'\d+', star_attribute).group()[0]
except:
stars = 0
comments_dict.append({
'name': name,
'content': content,
'upvote': upvote,
'time': time,
# 'location': location,
'stars': stars
})
return comments_dict
def get_movie_review(movie_id):
comments_dict = []
page = 0
limit = 20
while True:
url = f'https://movie.douban.com/subject/{movie_id}/comments?start={page}&limit={limit}&&sort=new_score&status=P'
print(url)
tmp_comments_dict = get_movie_review_by_url(url)
if len(tmp_comments_dict) == 0:
break
comments_dict.extend(tmp_comments_dict)
page += limit
t.sleep(random.uniform(1, 3)) # 随机等待时间是0.5秒和1秒之间的一个小数
print("==================影评获取完毕===================")
print(f'共获取{len(comments_dict)}条影评,影评文件已保存在桌面')
return comments_dict
def save_movie_review(movie_name, comments_dict):
dir_path = f'./data/{movie_name}'
os.makedirs(dir_path, exist_ok=True)
df = pd.DataFrame(comments_dict) # 将字典转换为 DataFrame
df.to_excel(os.path.join(dir_path, 'comments2.xlsx'), index=False)
def main():
movie_name = input("请输入电影名称:")
movie_id_dict = get_movie_id(movie_name)
for index, movie_id in enumerate(movie_id_dict):
print(f"{index + 1}. {movie_id_dict[movie_id]}")
movie_index = int(input("请输入电影ID:"))
movie_id = list(movie_id_dict.keys())[movie_index - 1]
comments_dict = get_movie_review(movie_id)
save_movie_review(movie_name, comments_dict)
if __name__ == '__main__':
main()本次爬虫部分介绍到这,后续还会更新本人负责的其他模块,欢迎各位一起讨论交流!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









