







1.Python数据类型与转换
1.1 Num数字类型
①.int 有符号整数型
a = -99
a1 = 5
a2 = a1 if a1>10 else 0
# a2 = 0②.float 浮点型
b = 3.14
③.complex 复数型
c = 3 + 5i
1.2 Bool布尔类型
a = True
b = False
1.3 序列类型
①.str 字符串 ' ' / " " 不可变有序序列
str_1 = "Python_3.17"
str_2 = 'Python_3.18
- str是不可变序列
- Python默认字母和汉字都为1个字符
-
len()函数在str中默认统计 字符个数,如果经过编码后,len()函数统计的是字节个数
-
在"utf-8"编码中,一个汉字占用3~4个字节组成
-
在"gbk"编码中,一个汉字占用2个字节
-
-
下表中的所有[start]和[end]可选项在进行index时要避开str自身的index值
| 分类&返回值 | 方法 | 说明 |
|---|---|---|
| 判断&bool | 字符串.isspace() | 只包含 空格 返回True |
| 字符串.isalnum() | 至少 一个字符,都是字母或数字 返回True | |
| 字符串.isalpha() | 至少 一个字符,都是字母 返回True | |
| 字符串.isdecimal() | 只包含 数字( 返回True | |
| 字符串.isdigit() | 只包含 数字( 返回True | |
| 字符串.isnumeric() | 只包含 数字( 返回True | |
| 字符串.istitle() | 标题化(每个单词 首字母大写) 返回True | |
| 字符串.islower() | 至少一个区分大小写字符,都是 小写 返回True | |
| 字符串.isupper() | 至少一个区分大小写字符,都是 大写 返回True | |
| 查找①&bool | 字符串.startswith(str, [start], [end]) | [范围内]以str开头 返回True |
| 字符串.endswith(str, [start], [end]) | [范围内]以str结尾 返回True | |
| 查找②&index或-1 | 字符串.find(str.[start].[end]) | [范围内] 包含str 返回 (首个)index值 否则 返回 -1 |
| 字符串.rfind(str.[start].[end]) | 与 find 类似 从右边开始找 | |
| 查找② index或Error | 字符串.index(str.[start].[end]) | 与 find 类似 不包含会报错 |
| 字符串.rindex(str.[start].[end]) | 与 index 类似 从右边开始找 | |
| 替换&新值 | 字符串.replace(old_str,new_str,[num]) num=字符串.count(old_str) | old_str替换为new_str [替换不超过num次] |
| 大小写转换&新值 | 字符串.capitalize() | 把第一个字符 大写 |
| 字符串.title() | 把每个单词 首字母 大写 | |
| 字符串.lower() | 大写字符转换为小写 | |
| 字符串.upper() | 小写字符转换为大写 | |
| 字符串.swapcase() | 大小写 翻转 | |
| 拆分&tuple或list | 字符串.partition(str) | 添加 str进行分割 (str前, str, str后) 结果为3 个元素 tuple |
| 字符串.rpartition(str) | 与partition类似 从右边开始找 | |
| 字符串.split([str], [num]) | [str]以str作为分割标志 (不写默认以空格作分割标志) [num]分割次数 结果为 num+1 个元素 list | |
| 字符串.rsplit([str], [num]) | 与split类似 从右边开始找 | |
| 字符串.splitlines([True/False]) | 以换行符\n为拆分标志 True保留换行符,False去掉换行符(默认False) | |
| 拼接&新值 | 字符串+str | 拼接 将str 接入 字符串后面 形成一个 新的字符串 |
| 字符串*n | 复制 n为正整数,复制字符串n次 形成一个 新的字符串 | |
| str.join(list) | 插入 将list中的元素 通过添加str拼接 形成一个 新的字符串 | |
| 去除空白字符&新值 | 字符串.strip() | 去除字符串两边空白字符 返回结果为新值,不修改其本身 |
| 字符串.lstrip() | 去除字符串左边空白字符 返回结果为新值,不修改其本身 | |
| 字符串.rstrip() | 去除字符串右边空白字符 返回结果为新值,不修改其本身 |
②.list 列表 [ ] 可变有序序列
list_1 = [1, 2, 3, 4, 5]
list_2 = list(range(1, 5))
-
生成二维列表(列表推导式)
list_3 = [[i] for i in range(10)] #外层10个list元素,每个元素依次为range(10)的生成数 list_4 = [[random.randint(10, 100) for j in range(5)] for i in range(10)] #外层10个list元素,每个元素内含5个10~99的随机数 list_5 = [600, 400, 900, 560, 700] list_6 = [[int(i*0.9)] for i in list_5 if i >= 560]
-
创建空list
list_7 = [] list_8 = list() -
列表元素可修改
-
列表可以嵌套,可以存放不同类型数据
list_9 = [["姓名","性别","身高","年龄"], ["张三","男",1.78,25]] -
索引从0开始
-
下表有
列表.关键字 表示该方法只列表可用
| 分类 | 关键字/函数/方法 | 说明 |
|---|---|---|
| 增加 | 列表.insert(索引,数据) | 指定索引前插入数据 位置前有空元素会补位 |
| 列表.append(数据/列表2) | 在末尾追加 列表2时结果为嵌套 | |
| 列表.extend(列表2) | 将列表2的数据合并到列表 | |
| 列表+列表2 | 拼接 与extend类似 | |
| 列表*n | 复制 n为正整数,复制列表元素n次 | |
| 删除 | del 列表[索引] | 删除指定索引数据 |
| 列表.remove[数据] | 删除第一个出现的指定数据 | |
| 列表.pop() | 删除末尾数据(赋此值给变量视为弹出) 即 变量 = 列表.pop() | |
| 列表.pop(索引) | 删除指定索引数据(赋此值给变量视为弹出) 即 变量 = 列表.pop(索引) | |
| 列表.clear() | 清空列表元素 | |
| 修改 | 列表[索引] = 数据 | 修改指定索引数据 |
| 查询 | 列表[索引] 列表[start : end : step] | 获取指定索引数据 负数代表倒取 end的取值不包含,前闭后开 |
| 列表.index(数据) | 获取数据第一次出现的索引 | |
| len(列表) | 获取列表长度 | |
| 列表.count(数据) | 获取数据在列表中的出现次数 | |
| max(列表) min(列表) | 获取列表中的最值 仅适用于元素为数字型的列表 | |
| 排序 | 列表.sort() 列表.sort([key],[reverse]) | 升序排序 key=函数 忽略该函数条件 key=str.lower() 忽略大小写 reverse=True/False 降/升序,默认False升序 |
| 列表.sort(reverse=True) | 降序排序 | |
| 列表.reverse() | 逆序反转 | |
| sorted(列表,[key],[reverse]) | 全局方法 只针对迭代对象且同类型数据 结果为新值 | |
| 冒泡排序 | 两两比较,交叉赋值 |
-
增加,排序(sorted除外) 结果(在原列表基础上操作) 不返回值
- 查询 结果(为新值) 必须 表达出来,用于变量赋值或print
- 逆序反转 --
列表[::-1]与列表.reverse()都可以实现-
列表[::-1]使用查询的方法,反转结果为新值可用于赋值 -
列表.reverse()使用排序的方法修改的本身,反转结果无法用于赋值
-
-
迭代器:同时包含iter和next方法的对象,迭代器iteration可产生循环效果
-
字符串,元祖,列表,字典集合都是迭代器
l1 = [1,2,3,4,5] l1_obj = l1.__iter__() #将l1转换为iterable可迭代对象 print(l1.obj__next__()) print(l1.obj__next__()) print(l1.obj__next__()) print(l1.obj__next__()) print(l1.obj__next__()) #l1只有5个元素,只能遍历5次
-
- 判断list是否相等
- list1 == list2
- for循环遍历进行比较
- 导入operator模块进行比较
import operator operator.eq(列表1,列表2) # 判断列表1与列表二是否相等 operator.ne(列表1,列表2) # 判断列表1与列表二是否不相等 # gt/ge/lt/le -- 进行大小于比较时只能为数字类型,且只参考第一个元素
③.tuple 元祖 ( ) 不可变有序序列
-
创建只有一个元素的元祖时,需要添加逗号","
tuple_1 = (1,) -
创建空tuple
tuple_2 = () tuple_3 = tuple() -
元祖推导式
-
直接将列表推导式强制转换为元祖
tuple_4 = tuple([i] for i in range(10)) -
直接推导式生成,结果为生成器
tuple_5 = ((i,) for i in range(10)) # <generator object <genexpr> at 0x01CBBDF0> # 直接推导式生成时,结果为生成器,每层推导式都需要使用tuple()转换为元祖 tuple_6 = tuple(((i,) for i in range(10))) tuple_6 = tuple((i,) for i in range(10))
-
-
元祖元素 不可修改(不能增加,清空(可以直接删除),修改,排序),其他操作与列表list一致(只要操作对本身无影响) -- 深拷贝除外
tuple_7 = (2, 5, 9, 8, [1, 5, 8, 9]) # 元祖中的列表元素只是引用元祖的一个地址,可以修改(深拷贝) -
元祖可用于多变量赋值
tuple_8 = ("小乔", 17, "女") name, age, sex = tuple_8
④.dict 字典 {key: value} 可变无序序列
字典访问效率高于列表(因为字典也称hash,是一种散列表),所有序列中 字典 访问效率最高
-
创建空dict
dict_1 = {} dict_2 =dict() -
直接生成dict
dict_3 = {'name1': '1998' , 'name2': '1999'} # key: value dict_4 = {火锅 = "重庆", 烧烤 = "西昌", 串串 = "乐山"} # key = value 报错 -
zip()映射函数生成
list_1 = [1, 2, 3, 4] list_2 = [5, 6, 7, 8] tuple_1 = (1, 2, 3, 4) tuple_2 = (5, 6, 7, 8) dict_5 = {list_1: list_2} #报错,列表不能作为key dict_6 = {tuple_1: list_2} #成功,但不映射 # {(1, 2, 3, 4): [5, 6, 7, 8]} dict_7_1 = zip(tuple_1, tuple_2) # zip类型的生成器对象,生成器只能使用一次 # <zip object at 0x01CECB48> dict_7_2 = dict(zip(tuple_1, tuple_2)) # 生成器转换为字典后,键值对一一对应(映射) # {1: 5, 2: 6, 3: 7, 4: 8} dict_7_3 = dict(zip(list_1, list_2)) # {1: 5, 2: 6, 3: 7, 4: 8} -
字典推导式
dict_8 = {i:j for i,j in zip(list_1,list_2)} # 只遍历i时为集合set(set每个元素为两元素tuple),将该集合dict()转换亦可得到字典 -
内容由key: value(键值对)形式存储,key必须唯一,value可以有多个,一个键值对为一个元素
-
key: 非直接创建时(只有dict_3为直接创建方式)必须为iterable可迭代对象
必须唯一,即不能是 列表(dict_5),可以是 元祖(dict_6) -
value类型:可以是某单一元素,tuple,list,dict
-
-
字典是无序的
-
字典无index索引,通过键key来访问值value
| 分类 | 关键字/函数/方法 | 说明 |
|---|---|---|
| 创建 | dict.formkeys(元祖) | 创建 空值字典 key为元祖元素,value为None |
| 修改 | 字典[key] = value | key存在:修改key的value key不存在:添加 键值对 |
| 字典.setdefault(key, value) | key存在:返回key的原value key不存在:添加 键值对,返回value 返回的value可通过update进行同步修改 | |
| 字典.update(字典2) | 字典2数据合并到字典 相同key的value会被覆盖 | |
| 删除 | del 字典[key] | 删除 键值对 key不存在会报错 |
| 字典.pop(key) | 弹出 键值对,返回 value key不存在会报错 | |
| 字典.clear() | 清空字典键值对 | |
| 查询 | 字典[key] | 获取key的value key不存在会报错 |
| 字典.get(key) | 获取key的value key不存在会返回None | |
| len(字典) | 获取 键值对 数量 | |
| 字典.keys() | 获取 所有key type为dict_keys | |
| 字典.values() | 获取 所有value type为dict_values | |
| key in 字典 | key存在:返回True key不存在:返回False |
-
字典.setdefault(key,value)一般与字典.update(字典2)联合使用 -
字典.get[key]返回None时不能作为该key不存在的判定标准,可能该key本身就没有value -
生成器:一种特殊的迭代器,只能使用一次,可生成一个其他数据类型对象 zip,yield,map等
-
jsonpath -- 获取任意key的value
# 使用jsonpath获取字典中任意key(涵盖嵌套情况)的value from jsonpath import jsonpath jsonpath(字典, "$..key") # 获取的是该key的value,可以print或用于赋值,结果为list
⑤.set 集合 { } 可变序列
set_1 = {1, 2, 3, 4}
-
set与list和tuple类似,但set里的数据不能重复
-
一般用来保存 点击量数据,投票数据等
-
set分为 有序set 和 无序set
-
list 和 tuple 都是有序的,通过 index 访问, dict 是无序的,通过 key 访问
-
无序set 无法通过 index 访问
-
| 分类 | 关键字/函数/方法 | 说明 |
|---|---|---|
| 增加 | 集合.add(数据) | 向集合里添加元素 |
| 集合.update(集合1) | 将集合1元素加入集合 | |
| 删除 | del 集合 | 删除整个集合 |
| 集合.remove(数据) | 删除 指定数据 不存在会报错 | |
| 集合.pop() | 随机删除集合中的数据 集合中没有元素会报错 | |
| 集合.discard(数据) | 删除 指定数据 不存在不会报错 | |
| 集合.clear() | 清空集合元素 | |
| 查询 | 集合 & 集合1 | 获取集合和集合1的交集 |
| 集合 | 集合1 | 获取集合和集合1的并集 | |
| 集合 - 集合1 | 获取集合在集合1中的插集 |
1.4 数据类型转换
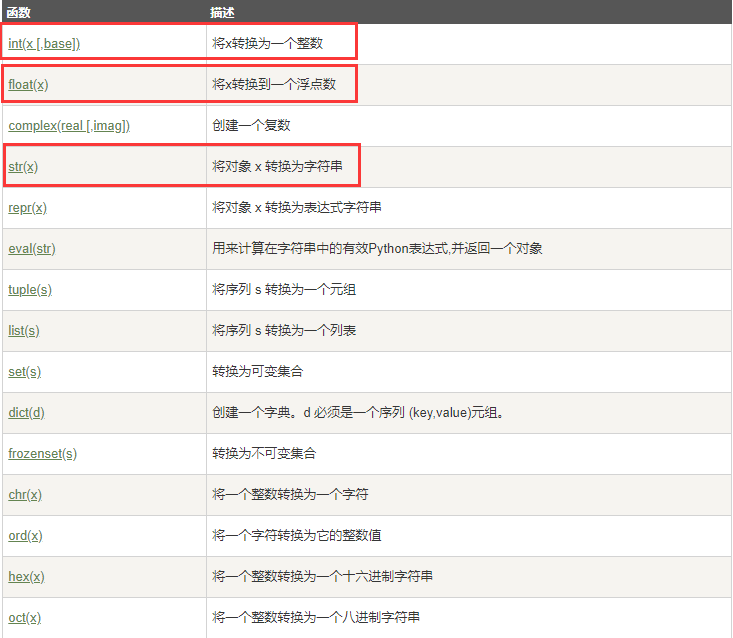
-
num 类型可强制转换为 str 类型
-
str 类型的数字无法直接转换为 num/float 类型
-
int( ) 转换时直接取整,不考虑四舍五入
-
chr( ) 将整数转换为参考对应ASCII码,与 ord( ) 相反
2.Python运算符
2.1 算数运算符
算术运算符的运算结果为数字
以下假设变量a为10,变量b为21:
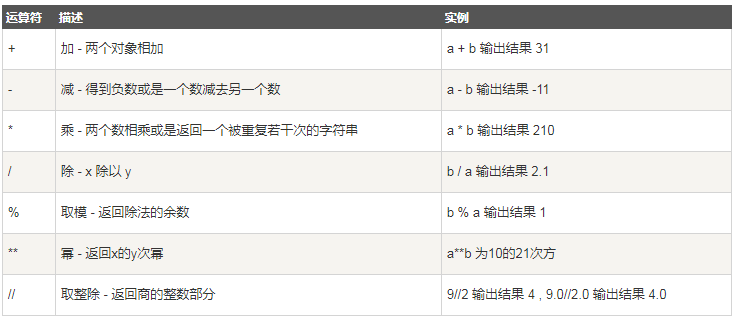
2.2 比较运算符
比较运算符的运算结果为Bool类型(True或者False)
以下假设变量a为10,变量b为20:
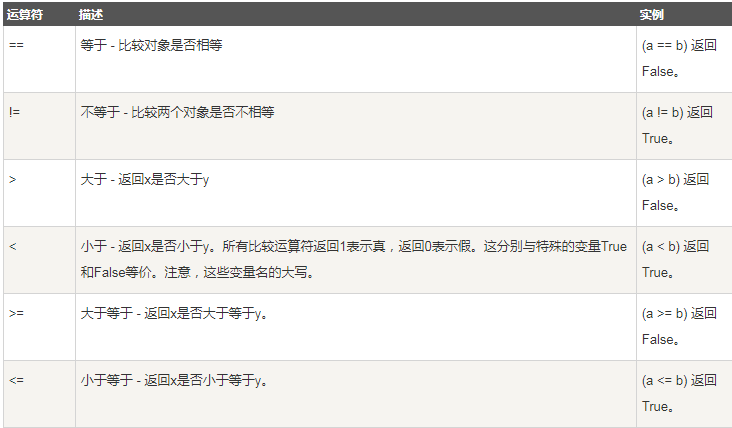
2.3 赋值运算符
以下假设变量a为10,变量b为20:

2.4 身份运算符
身份运算符用于比较两个值的存储单元(内存地址)是否为同一个

is与==- is 判断 值 和 id #判断对象的内存id地址是否相同,即是否引用同一对象
- == 判断 值 #判断对象的值是否相等,底层逻辑为 __eq__ a == b 等同于 a.__eq__(b)
2.5 逻辑运算符
如果x,y都是一个bool类型的数据

以下假设变量 a 为 10, b为 20

2.6 成员运算符
判断对象是否存在包含关系(父子关系), 返回 Bool 值
in
not in
str_1 = "djhgkgj9421"
print("8" in str_1) # False
print("a" not in str_1) # True2.7 运算符优先级
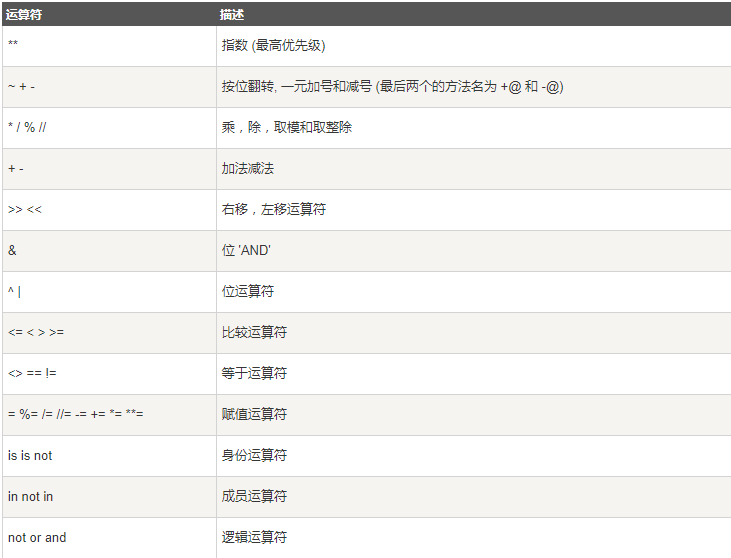
3.字符串前缀 u/r/b/f
u"字符串中有中文" 1、前缀u表示该字符串是unicode编码
2、Python2中用,用在含有中文字符的字符串前,防止因为编码问题,导致中文出现乱码
3、一般要在文件开关标明编码方式采用utf8
4、Python3中,所有字符串默认都是unicode字符串
r"adc\n\r\tdkfjkd" 1、前缀r表示该字符串是原始字符串,即\不是转义符,只是单纯的一个符号
2、常用于特殊的字符如换行符、正则表达式、文件路径
3、注意不能在原始字符串结尾输入反斜线,否则Python不知道这是一个字符还是换行符(字符串最后用\表示换行)
b"字符串是bytes类型" 1、前缀b表示该字符串是bytes类型
2、用在Python3中,Python3里默认的str是unicode类。Python2的str本身就是bytes类
3、常用在如网络编程中,服务器和浏览器只认bytes类型数据。如:send 函数的参数和 recv 函数的返回值都是 bytes 类型
4、在 Python3 中,bytes 和 str 的互相转换方式是: str.encode(‘utf-8’)
bytes.decode(‘utf-8’)
f"传入参数{parameter}进行格式化字符串" 1、Python3.6新加特性,前缀f用来格式化字符串。比format()方法可读性高且使用方便
2、而且加上 f 前缀后,支持在大括号内,运行Python表达式
3、还可以用 fr 前缀 来表示原生字符串
4.Python格式化输出
4.1 %
"str%X"%()
需配合以下格式符%X进行使用
%s 字符串格式
%d 有符号十进制整数格式
%6d 6位补空格
%06d 6位补0
%f 浮点数格式
%.2f 保留两位
%% 输出%
name = "昜"
age = 18
money = 98.5
info1 = "姓名:%s"%name
info2 = "姓名:%s,年龄:%04d,价格:%.2f"%(name, age, money)
print(info1, info2)
# 姓名:昜 姓名:昜,年龄:0018,价格:98.504.2 f
f"str{X}"
-
需要与变量
{X}配合使用
info3 = f"姓名:{name},年龄:{age},价格:{money}"
print(info3)
#姓名:昜,年龄:18,价格:98.54.3 format
"str{[index]}".format()
-
format前边需要添加".",需要配合{[index]}进行使用 -
索引时从0开始,且索引字符无法超量(分配的变量数)使用
'{[index][:[fill]align][sign][#][width][.precision][type]}{……}{……}'.format()
| 参数 | 含义 | 参数内容 |
|---|---|---|
| index | 指定匹配参数索引值(0~) 或key | 不写默认依次索引 |
| : | ||
| fill | 指定空白处的填充符 | |
| align | 指定数据的对齐方式 | < -- 左对齐 大部分对象默认 |
> -- 右对齐 数字对象默认 | ||
= -- 右对齐 只对数字类型生效 | ||
^ -- 居中对齐 数据居中,需要配合width使用 | ||
| sign | 指定有无符号数 | + 正数前面添加 ‘ + ’ ,负数前面加 ‘ - ’ |
- 正数前面添加 ‘ + ’ ,负数前面加 ‘ - ’ | ||
space 正数前面添加 ‘ 空格 ’ ,负数前面加 ‘ - ’ | ||
# -- 显示进制前缀 二进制0b,八进制0o,十六进制0x | ||
| width | 指定输出数据时所占的宽度 | |
| .precision | 保留小数的位数,与type有关 | 后面存在type参数:保留小数的位数 不存在:有效数字位数 |
| type | 指定输出数据的具体类型 | s -- 指定格式化字符串类型 |
d -- 十进制整数 | ||
b -- 十进制=>二进制 | ||
o -- 十进制=>八进制 | ||
x/X -- 十进制=>十六进制 | ||
c -- 将十进制整数自动转换成对应的 Unicode 字符 | ||
e/E -- 转换为科学计数法 | ||
f/F -- 转换为浮点数(默认小数点后6位) | ||
g/G -- 自动在科学计数和浮点数切换 | ||
% -- 显示百分比(默认小数点后6位) |
massage1 = "{}说:别吃酒;{}说:就要吃酒".format("张三", "李四")
massage2 = "{2}说:别吃酒;{0}说:就要吃酒".format("张三", "李四", "王五")
print(massage2, massage1)
# 张三说:别吃酒;李四说:就要吃酒 王五说:别吃酒;张三说:就要吃酒5.if 条件控制语句
5.1 if 单分支
if 条件表达式:
满足条件时执行的代码块 #(默认缩进4空格或1Tab)
import random # 调用随机数
num = random.randint(0, 10) # 随机生成0~10的整数
print(num)
if num > 5:
print("1111")5.2 if...else 双分支
if 条件表达式:
满足条件时执行的代码块
[else:
不满足条件时执行的代码块]
5.3 if...elif...else 多分支
if 条件表达式1:
满足条件1时执行的代码块
elif 条件表达式2:
满足条件2时执行的代码块
[...
elif 条件表达式n:
满足条件n时执行的代码块]
[else:
不满足条件时执行的代码块]
5.4 if 嵌套
if 条件表达式1:
if 条件表达式2:
条件1和2同时满足时执行的代码块
else:
满足条件1 不满足条件2时执行的代码块
else:
不满足条件1时执行的代码块
6.循环语句
6.1 for 循环
for 迭代变量 in 可迭代对象: #比较适合遍历和枚举
循环体
[else:
上诉for循环未被意外中断(break/continue)时执行的代码块]
L1 = [1, 2, 3, 4, 5]
for i in L1:
print(i)
for a in range(5):
print("I love You!")
"""
range用来生成连续整数
range(start,end,step)
start开始可省略,省略默认从0开始
step步长可省略,省略默认步长1
range(3) => [0,1,2,3) => [0,1,2]
range(1,5) => [1,2,3,4,5) => [1,2,3,4]
"""
for i in range(1,101):
if i % 3 == 2 and i % 5 == 2 and i % 7 == 2:
print(f"这个数是{i}")6.2 while 循环
while 条件判断语句:
循坏体
[else:
不满足循环条件执行代码块]
6.3 break 与 continue
-
break:
某⼀条件满⾜时,不再执⾏循环体中后续重复的代码,可以使用break让其退出循环
-
continue:
某⼀个条件满⾜后,不希望执⾏本次循环代码,但⼜不希望退出循环,可以使⽤continue
6.4 循环嵌套
九九乘法表
for i in range(1, 10):
for j in range(1, i+1):
print(f"{i}*{j}={i*j}", end="\t") # end="" 不换行
print() # 换行i = 1
while i <= 9:
j = 1
while j <= i:
print(f"{i}*{j}={i*j}", end="\t")
j += 1
i += 1
print()6.5 遍历
- for 循环遍历
-
迭代器遍历(str,list,tuple)
for value in list: print(value) # 结果为元素for i in enumerate(list): print(i) # 结果为包含index与对应value的tuplefor index,value in enumerate(list): print(index,value) - dict遍历
for i in dict: print(i) # 结果为keyfor i in dict.keys(): # 或遍历 dict.values print(i)for i in dict.items(): print(i) # 结果为包含key与对应value的tuple for key,value in dict.items(): print(key,value) for i in zip(list_1, list_2): print(i) # 结果为包含key与对应value的tuple
-
- while 循环遍历
索引 = 0 长度 = len(列表) while 索引 < 长度: print(列表[索引]) 索引 += 1
6.6 冒泡排序
- for 循环冒泡
l1 = [9, 5, 7, 6, 8, 2, 3] for i in range(1, len(l1)): # 轮次i轮 for j in range(len(l1)-i): # 每轮比较次数j if l1[j] > l1[j+1]: l1[j], l1[j+1] = l1[j+1], l1[j] print(l1) - while 循环冒泡
7.函数
-
函数 : 可以直接使用的具有特定功能的代码块,具有名字,可重复执行
函数是 代码封装 和 代码复用 的体现
-
方法 :
.方法(),方法本质上也是函数,但是需要通过object来调用,相当于实例方法 -
魔术方法 :
__XX__(),python系统自带的具有特殊功能的方法 -
参数 :
.参数,需要通过object来调用,相当于实例属性
7.1 def 自定义函数
# 创建自定义函数
def functionname([形参]): # 赋值给某形参 则为其默认值,默认值必须在所有形参最后
# 不给有默认值的形参传参时,该形参使用默认值参与运行
# 定义形参为可变object时,使用*args,**kwargs
"""定义的函数的注释说明""" # 有参数的情况下,在此处对定义的形参进行注释说明
function-body
[return 执行结果(返回值)] # 定义的函数 全部 执行成功时 才执行的代码块,非必选项
# 调用函数的时候,明确输出/打印 那就不需要返回值
# 一般需要返回某局部变量的值时,在不定义其为全局变量的情况 下,需要return返回来实现
# 调用自定义函数
自定义函数名([实参]) #当没有默认值的形参 都被赋值时,定义的函数才会执行①形式参数--定义函数的形参时,可定义其为 定长参数 和 不定长参数
-
定长参数,传入的参数确定时,函数接收 单个 或 多个 确定数量的 位置参数
-
默认参数,必需参数,关键字参数
-
默认参数:给形参设置默认值(初始值),即给某形参赋初始值,以保证函数永远可用
-
默认值必须写在所有形参的最后
-
如果不给带默认值的形参传参,则函数使用该形参的默认值参与运算
-
-
必需参数:没有默认值的形参也称为必需参数
-
关键字参数:实参作为关键字传参时,与之匹配的形参即称为关键字参数
-
-
-
不定长参数,一般用在传入的实参个数不确定时,通过给形参前加星号
*,**声明来实现-
声明带
*的形参--如*arg: 表示该函数接收任意多个位置参数(未命名参数),传入的参数在函数内部会形成一个tuple.收集所有非按关键字传入的实参,在函数内部形成tuple按位置传参的参数可以不写在最后,但其后面参数只能是通过关键字传参的(即
**之前) -
声明带
**的形参--如**kwargs:表示该函数接收任意多个关键字参数(已命名参数),传入的参数在函数内部会形成一个dict.收集所有按关键字传入的实参,在函数内部形参dict按关键字传参的参数必须写在除默认值参数以外的所有形参最后
def fun(a,b,*args): print(a)#1 print(b)#2 print(args)#(3,4,5) for i in args: print(i) fun(1,2,3,4,5)
-
-
定长参数 和 不定长参数 同时定义时
def fun(a,b,*a,**a,c=5):
②实际参数--调用函数进行传参时,根据实参的类型,可分为 值传递 与 引用传递
-
传参:直接传参,赋值传参,关键字传参
def fun(a,b):-
直接传参 传入的变量(实参)个数与位置必须与形参一一对应,名称可以不匹配
a1 = 4 b1 = 5 c1 = 6 fun(b1,c1) -
赋值传参 实参的个数与位置必须与形参一一对应
fun(5,6) -
关键字传参 实参中的关键字名称必须与形参的名称匹配,个数与位置可以不一致
fun(b=6,a=5,c=4) # c在形参列表中没有与之匹配,则不会传入函数fun内部参与运算
-
-
值传递:实参为 不可变object时(只给值不给内存id,相当于复制给函数进行运算)
-
引用传递:实参为 可变object时,引用传递可调用函数进行拆包(即*tuple/list 或 **dict)
-
拆包引用:将
tuple/list或dict进行拆解,作为实参传递给函数-
*tuple/list--实参tuple/list中的 元素个数 需与 形参个数(不可变的) 保持一致 -
**dict--实参dict中的 key名 需与 形参名称 保持一致 (不用考虑key的个数)def fun(a,b,c,d,*args): print(a) # 1 print(b) # 2 print(c) # 3 print(d) # 4 print(args) # (5,6) fun(*[1,2,3,4,5,6])
-
-
③变量作用域--全局变量 与 局部变量
-
全局变量: 在函数体内和函数体外 都可使用
-
局部变量: 函数体内生成的变量,只能在该函数体内使用,可通过global修饰为全局变量
-
global修饰局部变量→全局变量时,需要先修饰,再使用
1.global 变量名 2.return def fn1(): global name, age name = '李四' age = 20 fn1() def fn2(name): print(name, age) fn2('王五') # "王五",20 print(name, age) # "李四",20
-
④返回(值或结果)--return
-
return可以返回值(1个或多个) 或 结果
-
返回多个值时,使用逗号
,隔开,返回结果为tuple -
返回结果时,一般为函数全部执行成功时需要执行的代码块
-
-
return也表示函数的结束,函数遇到return就自动结束了,一个函数 只能有一个return
-
return 与 yield
-
yield不会导致函数结束
-
yield返回的内容为一个生成器
-
yield也可以返回函数体内的值(一个或多个) 或 结果
-
yield返回的是yield至return之前的所有内容,因而return与yield可以同时存在
-
def operation(num1, num2, num3=5):
"""
该operation函数用于运算
:param num1: 参与operation函数运算的的第1参数
:param num2: 参与operation函数运算的的第2参数
:return:定义的函数 全部 执行成功时 返回的结果
"""
print("加法运算:", num1+num2)
print("减法运算:", num1-num2)
print("乘法运算:", num1*num2)
print("除法运算:", num1/num2) # 实际参数为0时,该行代码会报错,后面的代码都不执行
return print("执行成功!")
a1 = 6
b1 = 5
operation(a1, b1) # 赋值传参operation(6, 5),限定位置
# 关键字传参operation(b=5,a=6),限定关键字
# 执行结果
加法运算: 11
减法运算: 1
乘法运算: 30
除法运算: 1.2
执行成功!- 递归
函数嵌套过程中,函数直接或间接调用了本身,会导致内存崩溃,python默认最大递归次数1000次
import os
def fun_mkdir(path):
if not os.path.isdir(path):
dir_1 = os.path.split(path)[0]
fun_mkdir(dir_1)
else:
return
os.mkdir(path)- 闭包
函数嵌套过程中,外部函数传了变量给内部函数使用,并且返回内部函数的引用名,则称内函数为闭包函数 -- 可使(外函数的)局部变量长久保存
"""例1"""
num = 10
def outer():
num = 5
def inner():
nonlocal num # 声明使用局部变量num = 5
# global num # 声明使用全局变量num = 10
num += 1
print(num)
return inner
out_er = outer()
out_er()
"""例2"""
def fun_1():
l1 = list()
def fun_2(a):
l1.append(a)
print(l1)
return fun_2
fun = fun_1() # fun==fun_2
fun(5) # [5]
fun(7) # [5, 7]- 装饰器@
本质上是一种闭包,使用@关键字修饰函数.装饰器可以在不修改原函数的代码和调用方式的情况下,对原函数功能进行扩展加强
def log_commit(fun):
def inner():
print("登录成功!")
fun()
return inner
# @log_commit:将commit()函数转为一个名称为commit的参数,并传入log_commit函数中,再返回到commit
@log_commit
def commit():
print("发表评论成功!")
commit()7.2 lambda 匿名函数
用于创建匿名函数,创建的函数可以调用,使用lambda创建时,所有代码必须在一行
-
lambda是作为实参使用
-
没有函数名
-
在函数体中不需要手动返回,会自动返回运算的结果,也就是不需要写retur
# 创建匿名函数
[变量(匿名函数名) =] lambda [形参(可以多个)]:功能代码
# 调用匿名函数
变量([实参]) # 调用赋值的变量
lambda [形参(可以多个)]:功能代码 # 直接调用本体,作为变量参与运算7.3 pass 占行语句
pass是一个空的语句,不做任何事情,一般用做占位语句,以保持程序结构的完整性
if True:
pass
def info():
pass
info()
while True:
pass7.4 input()
用于从外部获取数据的函数,默认获取所有数据为str类型
input("请输入一个数据:")
a1 = input('请输入第一个数字:')
a2 = input('请输入第二个数字:')
b = float(a1) + float(a2)
print('两个数字的和为:', b)7.5 print() 打印/输出
用于输出打印 变量内容 或 "需要注释的内容"
同时输出多个变量内容,使用逗号","或加号"+"拼接,以及星号"*"
- "," 建议用于不同类型数据拼接
- "+" 建议用于同类型数据拼接 ","和"+"输出结果有空格差异
- "*" 字符串和整数拼接时,"*"结果为重复拼接相同的字符串
- "\" 转义符," " 引号外的 \ 一般在代码行使用,代表转行符
- ""内 \n 与 \t 代表 换行 与 制表位
- end=" " 同一轮循环中,所有输出结果不换行,通过""引号里的内容连接排列显示,使用时用逗号与主体隔开
name = input('请输入姓名:')
sex = input('请输入性别:')
age = input('请输入年龄:')
print('姓名为' + name , '性别为' + sex , '年龄为' + age)
print("你" * 10) # 你你你你你你你你你你7.6 type()
获取数据类型
a = input('请输入一个数据:')
print(type(a))7.7 id()
获取某一对象在内存的id值(随机分配的)
a = 15
print(id(a))7.8 len()
获取对象长度
a = [15,19,17]
print(len(a))7.9 range()
用于生成连续整数
range(start,end,step) # 前闭后开
- start 开始 可省略,省略时默认 从0开始
- end 结束 不可省略,生成结果不包含该值
- step 步长 可省略,省略时默认 步长1
range(3) => [0,1,2,3) => [0,1,2]
range(1,5) => [1,2,3,4,5) => [1,2,3,4]
list_1 = list(range(3)) # 生成list [0,1,2]- 通常与list切片查询进行比较
列表[start:end:step] # 前闭后开
- start 索引开始 可为负数,可省略,省略时 必须跟上":" 默认 从索引0开始取
- end 索引结束 可为负数,可省略,省略时 默认 取完start索引后的所有数据
不省略时,取值结果不包含该索引
- step 索引步长 可为负数(表示倒取),可省略,省略时 默认 步长为1
list_1 = ["小乔", 19, "女"]
list_2 = list_1[1:] # [19, "女"]
list_2 = list_1[1:2] # [19,]7.10 import 导入函数
用于导入模块供函数使用,1个.py文件可视作1个模块,简洁同时提高代码复用性
- 导入 -- path层级用"."隔开
# 直接导入(整个模块) import module_[path.]name as 别名 # 同时导入多个模块时用逗号","隔开 # 指定导入(模块内部对象) from module_name(path) import module_object(name) # 对象可用"*"表示导入模块内除私有成员"__xxx"限制的对象 或 "if __name__ == '__mian__':"外即非主程序运行的对象-
导入后模块内的object(class/class_object/函数/变量)都可引用
-
python内部每个文件都有一个
__name__属性用于保存当前文件名字-
在主程序运行时(即当前文件下) =>
__name__=='__main__' -
在import导入时(非主程序运行) =>
__name__!='__main__' -
if __name__ == '__mian__':内的语句只在主程序内运行
-
-
文件或自定模块命名时尽量不要与自带模块重名
-
直接导入--可避免 不同模块 重名对象 覆盖异常
-
指定导入--可避免 模块重名 异常(或 import...as 别名 也可解决)
-
-
from ... import *指定导入全部-
表示导入模块内 除私有成员"
__xxx"限制的对象 或 "if__name__ == '__mian__':"外即非主程序运行的对象 或 "__all__"函数包含的对象 -
指定导入全部内容时会将所有运行的对象(如函数调用,类对象创建等)都导入,导致代码多次重复运行
-
-
-
引用
# 直接导入import...as...时 module_name(或别名).module_object # 使用别名避免重名module异常 #指定导入from...import...时 module_object # 直接使用,但object重名时会覆盖 -
模块定位path
-
内置模块(sys.modules)
-
系统标准模块(/lib文件夹中)
-
当前目录
-
第三方安装模块(/lib/site-packages)
-
使用system模块自定义查找路径
import sys sys.path.append(目录路径)
7.11 open() 文件操作
文件操作函数,用于打开/创建并打开某个文件
-
所有文件都是二进制文件(包含文本文件)
-
二进制文件不需要指定编码,只有文本文件需要指定编码
-
二进制文件没有行的概念,所有不能够按行读取,所以在read中只能按指定的字节读取
open(file,mode,[buffering],[encoding])
\file--文件路径,"文件/文件路径" 或 file="文件/文件路径"
\mode--运行方式,"r"=>读 "w"=>写 "a"=>追加,"r/w/a" 或 mode="r/w/a"
\buffering--设置文件缓冲大小,"0"=>无缓冲 "1"=>行缓冲 "n"=>全缓冲(n>1)
\encoding--编码方式,文本文件必须指明该项,"utf-8/gbk" 或 encoding="utf-8/gbk"
mode=>
\\r--只读,指针在文件开头,默认模式 \\rb二进制模式\\r+/rb+可读写
\\w--只写,指针在文件开头.无=>创建 有=>覆盖(替换) \\wb二进制模式\\w+/wb+可读写
\\a--追加,指针在文件末尾.无=>创建 可使用seek读取 \\ab二进制模式\\a+/ab+可读写
"""---关闭文件---"""
文件对象名.close() # 关闭对应文件
"""---检查文件是否关闭---"""
文件对象名.closed() # 检查文件是否关闭
"""---文件写入内容---"""(二进制文件没有行的概念,无法按行写入)
文件对象名.write("写入内容") # 写入内容至文件,执行后文件并未被关闭
文件对象名.writelines("第一行","第二行","第三行") # 按行写入,执行后文件并未被关闭
"""---文件读取---"""(二进制文件没有行的概念,无法按行读取)
文件对象名.read([num]) # 默认读取整个文件内容,[num]指定读取该文件前num个字符,读取完成后光标停留在读取位置.读取结果为string
文件对象名.readline([num])# 默认读取1行,[num]指定读取该行前num个字符,读取完成后光标在该行的行尾.读取结果为string
文件对象名.readlines() # 读取所有行.读取结果为一个list,每行为该list的每个元素.文件过大时读取速度很慢,可能会导致内存崩溃
文件对象名.seek(offset,[whence]) # 偏移读取(字节单位)
\offset--指针偏移字节数,与编码有关(1个汉字 utf-8=>3~4个字节 gbk=>2个字节)
\whence--指针开始位置(0=>文件开头(默认) 1=>当前位置开头 2=>文件末尾)with expression as filename: # with语句内的操作结束后,文件会自动关闭
with-body
with open("./dir/1.txt","a+",encoding=utf-8) as file:
file.write("此内容写入后文件会被关闭")
"""审核文件"""
def fun_check(path):
import datetime
with open(path, "r+", encoding="utf-8") as file:
with open(f"./data_check {str(datetime.date.today())}.txt", "w", encoding="utf-8") as new_file:
read = file.readline()
while len(read) != 0:
read = read.replace("抢劫", "*")
read = read.replace("偷盗", "*")
read = read.replace("杀人", "*")
print(read)
new_file.write(read)
read = file.readline()
file.write(f"\n已审核 {str(datetime.date.today())}")
new_file.write(f"\n已审核 {str(datetime.date.today())}")
return print("审核结束!")8.异常与断言
8.1 处理异常
提高脚本稳定性,节省内存资源
try:
maybeError_block
except [Error_type [as othername]]: # Exception as EC 所有异常
afterError_block
[except...] # except语句可以有多个
[else: # try未报错else才执行
notError_block]
[finally: # finally强制执行(无论是否出现错误)
enforce_block]
try:
print(str_1.index("g")) # 可能报错的代码
except ValueError as Error1: # 指定Error类型,Error名称非必填
print(f"{Error1}类型错误,字符串未找到,但不影响程序运行") # 报错后执行的代码
except... # except可以有多个8.2 抛出异常
人为强制抛出自定义异常
raise Error_type([Error_reason]) # 抛出异常后程序会强制中断
raise Exception()
raise Exception('手动致错')8.3 断言语句
expression为False时(断言失败,比如有bug)会提醒,True时(断言通过)不提醒
多用于判断 预期结果 是否与 实际结果 相符合,经常与operator模块配合使用
assert expression[, False_reason] # expression为False即断言失败时,后续程序会中断
9.面向对象
-
类<class>:一种相似事物的统称(集合,但不同于set,此处为class)
-
对象<object>:类的实例化,python中一切皆对象
9.1 创建类 class
# 创建Class,创建的Class无法直接使用,需要单独创建object进行引用
class Classname([基类]): # <Classname>类名称采用驼峰式命名法,其每个单词首字母均要大写
# 默认会有一个object主类
"""创建的类注释"""
class-body_1
class-body_2
# 引用Class,创建实例object,多个object引用则需创建多个object,单独引用该Class
objectname_1 = Classname()
objectname_2 = Classname()
# 选择调用class-body中定义的 属性 或 方法/函数
objectname_1.class-body_2
objectname_2.class-body_19.2 面向对象三大特征
-
封装:将一组内容封闭在一个class中,可以规范的对其进行管理,同时提高了其安全性
-
继承:class之间可以相互引用,通过引用使其公共内容复用性提高
-
多态:通过继承后,使class最终实现的效果更加多样化和复杂化
9.3 class 类的组成
# 添加属性
对象.新属性名 = 新属性值
# 修改属性
对象.属性名 = 新值
# 删除属性
del 对象.属性名称
# 判断属性是否存在
hasattr(对象,"属性名称")-
class 属性 -- class中的位于所有函数/方法外的变量 -- 静态特征
-
class属性保存在class空间中
-
class属性可以为所有实例提供属性,所有实例方法都可使用
-
调用
-
class 外部使用classname调用时,
classname.class属性,通过classname修改其初始值会对所有object生效 -
class 外部使用objectname调用时,
objectname.class属性,通过objectname修改其初始值只对该object生效 -
实例方法内 调用class属性时必须以
self.或classname.声明
-
-
-
实例 方法 -- class中的函数(方法) -- 动态特征
-
动态特征 => class中的函数/方法
-
第一个形参(必须有且)为
self,以用于区分不同对象 -
调用
-
不支持 class 外部使用classname调用
-
class 外部使用objectname调用时,
objectname.实例方法() -
在其他方法内(含继承时)可以相互引用(调用),必须以
self.声明
-
-
-
实例 属性 -- class中的位于所有函数/方法内的变量 -- 动态特征-静态特征
-
实例属性可以在所有实例方法中共享
-
在实例方法内部必须以
self.声明,以与局部变量作区分,即self.实例属性 -
调用
-
不支持 class 外部使用classname调用
-
class 外部使用objectname调用时,
objectname.实例属性,前提是objectname.实例方法()(该object已调用其实例方法),无法直接调用,通过objectname修改其初始值只对该object生效.也可objectname.实例方法().实例属性调用 -
在其他实例方法内可以相互引用(调用),必须以
self.实例方法().声明
-
-
-
魔术 方法 --
__XXX__(),python系统自带的具有特殊功能的方法-
__init__()-- 构造(初始化) 函数/方法--实现class中的变量由外部动态传入,即在实例方法运行前传入成功-
__init__定义的除self外的形参需要在创建实例object时一并传参 -
在实例化object时会自动执行(不需要单独调用)且优先于实例方法
-
__init__方法中不能返回值(可以return结束),必须返回值时需要单独定义实例方法来实现(返回) -
一般用于给class属性动态传入初始值
-
-
__str__()-- 对象信息描述方法--打印输出实例object时,输出该方法返回的return结果-
打印实例object时会自动执行
-
直接print(object)打印对象 => 打印该对象内存地址
-
定义了
__str__()再print(object)打印对象 => 打印该方法定义的对象信息描述(即return结果)
-
-
__del__()-- 析构函数/方法--python对实例对象空间进行回收时,该方法会自动执行-
__del__()分析对象何时销毁 -
__init__()与__del__()是相对立的,一个开始时执行,一个结束时执行
-
-
__new__()-- 单例模式--创建object空间并返回其地址id--实质上是object基类的重写-
实例化object时,先创建一个实例化空间,再返回当前实例object的id地址
-
__new__()执行之后才会生成实例object,之后再执行__init__(),即执行优先于init -
第一个形参为
cls(必须),而不是self -
核心为
super().__new__(cls),返回new生成的内存空间地址,用于存放objectclass MusicPlayer(object): instance=None # 实现只创建一个object空间 init_flag=False # 实现__init__只执行一次 def __new__(cls, *args, **kwargs): if MusicPlayer.instance is None: cls.instance=super().__new__(cls) return cls.instance def __init__(self): if MusicPlayer.init_flag: return print("播放器初始化") MusicPlayer.init_flag=True play1=MusicPlayer() print(play1) play2=MusicPlayer() print(play2) # 播放器初始化 # <__main__.MusicPlayer object at 0x00D9E090> # <__main__.MusicPlayer object at 0x00D9E090>
-
-
-
class 方法 -- 通过装饰器
@classmethod修饰 -- 可选构造方法-
通过装饰器
@classmethod修饰,第一个形参为cls -
可在不生成object的前提下,直接被classname调用,在init前执行
-
与class属性一样,存放在class空间中
-
class方法无法访问实例属性,可以访问class属性
-
class方法在未实例化object时也可以直接调用,
classname.class方法() -
可通过该方式可在class中实现多个构造方法
-
调用
-
class 外部使用classname调用时,
classname.class方法(),该方式在__init__之前执行.此时因未生成实例对象,init暂不执行. -
class 外部使用objectname调用时,
objectname.class方法(),该方式在__init__之后执行
-
-
-
静态 方法 -- 通过装饰器
@staticmethod修饰 -- class中的1个函数,一般存放与当前class没有联系的内容-
通过装饰器
@staticmethod修饰,不需要指定cls或self关键字形参 -
也存放在class空间中,一般用于存放与当前class没有联系的内容
-
也可通过该方式可在class中实现多个构造方法,但不建议
-
调用
-
class 外部使用classname调用时,
classname.静态方法(),该方式在__init__之前执行 -
class 外部使用objectname调用时,
objectname.静态方法(),该方式在__init__之后执行
-
-
-
动态方法→class属性 -- 通过装饰器
@property修饰-
将1个动态方法转变为1个class属性
-
一般用于实例方法(本身内容比较固定)比较重要不允许被修改时
-
9.4 访问限制
通过_class成员与__class成员达到设置访问限制的效果
-
_class成员-- 受保护成员--允许class本身,子class和实例object访问和修改'_'修饰的变量不允许from 模块名 import *(*表示导入所有) 导入 -
__class成员-- 私有成员--只允许class本身访问,或通过objectname._classname()__class成员访问
9.5 class 继承
- 被继承的class -- 父(基)类
- 新生成的class -- 子(派生)类
- 所有class都有继承--object是所有class的父(基)类
- 单继承:一个子类继承一个父类
- 多继承:一个子类同时继承多个父类(除object外的无其他继承的基类)
- class继承 -- 调用 -- supper() -- 多用于多个父类方法重名时使用
# 调用父类的方法 1.super([classname1,self]).方法() # 指定调用的是classname1后的调用的基类中的方法 # super()括号里不填时,默认调用第一个 2.self.方法() # 调用父类的class属性 1.super([classname1,self]).class属性 2.self.class属性 # 调用父类的实例属性 1.super([classname1,self]).方法().实例属性 2.self.方法().实例属性 - 派生类 重写 基类 方法 -- 派生类方法与基类方法重名(覆盖)
-
仅作用于当前派生类本身,不会对其他基类的继承造成影响
-
无法使用
self.方法(),只能通过super().方法()实现 -
多态
-
10.深浅拷贝
可变object: list,dictionary,set
不可变object: number,string,tuple
-
对于可变对象来说,深拷贝和浅拷贝都会开辟新地址,完成对象的拷贝
-
而对于不可变对象来说,深浅拷贝都不会开辟新地址,只是建立引用关联,等价于赋值
-
对于复合对象来说,浅拷贝只考虑最外层的类型,复合类型数据中的元素仍为引用关系;而深拷贝对复合对象会递归应用前两条规则















 1738
1738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









