






数据集:{西瓜一,西瓜二,西瓜三……}
样本/示例:西瓜一
属性/特征:色泽
西瓜一={色泽一,敲声一,根蒂一}
西瓜二={色泽二,敲声二,根蒂二}}
属性值/特征值:乌黑
样本空间/属性空间/输入空间:色泽、敲声、根蒂为三个坐标轴张成的空间,用来描述西瓜
特征向量:该空间的每个点对应一个坐标向量,这个坐标就是特征向量
样例:有被设定的预测结果即标记的样本
(色泽=青绿,根蒂=绵软,敲声=浑浊;好瓜)
标记:好瓜
标记空间/输出空间:{好瓜,坏瓜}
分类:预测的是离散值,比如好瓜、坏瓜
回归:预测的是连续值,比如西瓜的甜度
二分类:分为正类和反类共两类
多分类:
训练数据:
测试数据:
聚类:本地西瓜、外地西瓜;浅色瓜、深色瓜。且这些概念事先并不知道
监督学习:有标记
代表:分类、回归
无监督学习:无标记
代表:聚类
泛化:从训练数据中得到模型,这个模型适用于测试数据的能力。从特殊到一般
独立同分布:用英文理解比较容易,independent and identically distributed,假设样本空间各样本均服从某个特定分布,所有样本都是独立地从这个分布上采样获得的
归纳:特殊到一般
演绎:一般到具体情况
广义的归纳学习:从样例中学习
狭义的归纳学习:从训练数据中学得概念,又叫概念学习,但是现实中的技术大多是黑箱
版本空间:所有能够拟合训练集的模型构成的集合是版本空间
假设空间:各个特征的所有可能的取值形成的空间
模型学习过程可以看作是在所有可能性组成空间中进行搜索的过程,目标是找到与训练集匹配的可能性。
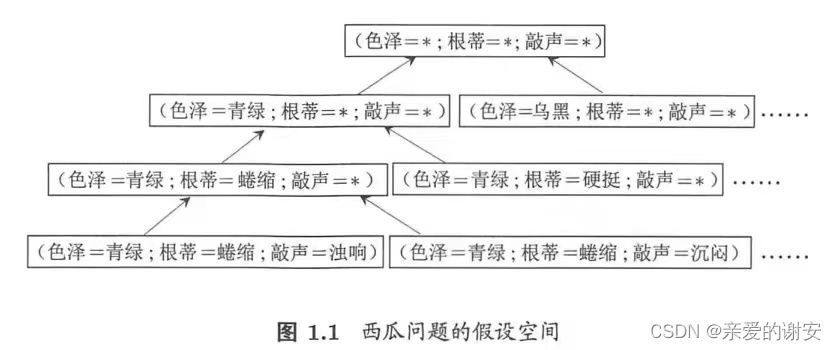
归纳偏好:模型对某个特征的可能性具有偏好,叫做归纳偏好
数学中学的线性回归方程,就是让直线经过尽可能多的样本点(其实不是,但是为了类比),那么归纳也是让曲线经过所有训练数据点,这样的曲线有很多条。为了得到最终结果只有一条,模型就必定具有某种偏好,才能输出模型认为正确的唯一曲线。
一般而言,如果有多种可能性与训练数据拟合,就选择最简单的一种,反映在几何上就是选择更平滑的曲线——奥卡姆剃刀原则。当然它并不是唯一可行的原则。不同的原则带来不同的结果。
对于算法A,如果它在某些问题上比算法B表现好,那么必然存在另一些问题,在那里算法B表现更好。这个结论对任何算法均成立。换句话说,总误差与学习算法无关。

这个结论的前提是,所有问题出现的机会相同(所有问题等同重要),但实际生活中并不是这样,我们只关心某个特定问题的解决方案,并不关心这个解决方案在其他问题上的实用性。所以判断算法的优劣,必须要指定特定问题。
这个很好理解,类比一下,就是每个人都有自己擅长的领域。有的人擅长打篮球,那不擅长打篮球的人很可能擅长下棋。对于所有潜在领域来说,没有人是一无是处,一事无成的。但是对于某个特定领域来说,比如数学,那就是有人学的更通透一些。
数据决定模型的上限,算法让模型无限逼近上限,逼近真相。
数据量大,积累的经验越多,那么找到的规律/得到的模型就越有利于预测未来。
找到一个好算法,比如一元线性回归or多项式回归,看哪个能更好地学习这个规律。
参考:
周志华,《机器学习》(西瓜书)
二次元的Datawhale,爱敲代码的异步社区,www.bilibli.com,BV1Mh411e7VU,【吃瓜教程】《机器学习公式详解》(南瓜书)与西瓜书公式推导直播合集

















 1027
1027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









